Google unveiled a whimsical commercial imagining the Founding Fathers using modern AI tools to draft the Declaration of Independence, while researchers advance critical papers on long-context reasoning and agent safety. These developments highlight both the creative marketing of AI tools and significant technical progress in how language models process complex information and maintain safety.
Google's latest commercial presents a tongue-in-cheek vision of historical figures collaborating with contemporary AI tools like Google Docs, Calendar, and Meet, with Gemini assisting in document management and visualization. This ad positions Google's AI suite as an essential productivity tool for creative collaboration. Meanwhile, academic research advances key areas including evidence-state rewards for long-context reasoning, a training-free guardrail approach using kNN on LLM hidden activations, and coding agents that can replicate scientific machine learning papers with structured validation. These papers demonstrate significant progress in agent architectures, safety mechanisms, and reproducibility in AI systems. Additionally, researchers explore automated grading of Linux/bash examinations using large language models with cognitive taxonomies, showing promising results for educational applications and agent evaluation systems.
Research Papers
Evidence-State Rewards for Long-Context Reasoning
Marttinen, Pekka arXiv: 2607.02073

The paper introduces Maven, a reinforcement learning framework designed specifically for long-context reasoning tasks. Unlike traditional methods that reward only final answers or static evidence extraction, Maven focuses on action-level rewards tied to how intermediate steps modify the model's evidence state. This approach allows for more nuanced feedback during reasoning, particularly in complex scenarios where evidence is distributed across lengthy inputs.
By defining answer-conditioned evidence-state values and assigning rewards based on marginal gain, evidence synergy, and improved answer support after dropping misleading evidence, Maven enables models to dynamically adjust their reasoning process. The framework uses GRPO (Generalized Reward Policy Optimization) to train these action-level transitions, resulting in more sufficient evidence sets and lower retention of distractors across multiple benchmarks including LongBench v2, LongReason, and RULER.
This work is particularly relevant for agent architectures that require extended memory and reasoning capabilities. It suggests that future agents should not only focus on generating correct outputs but also on managing internal representations in a way that supports iterative refinement of evidence, which aligns with broader goals in multi-agent systems and planning.
Key insight: Reinforcement learning for long-context reasoning can be significantly improved by rewarding state transitions in an editable evidence memory rather than just final outcomes, leading to better evidence synthesis and reduced distractor retention.
kNNGuard: Turning LLM Hidden Activations into a Training-Free Configurable Guardrail
Garraghan, Peter arXiv: 2607.02072

kNNGuard presents a novel, training-free method for implementing guardrails in large language models by leveraging the activation space of pre-trained models. Instead of relying on expensive fine-tuning processes, it uses a small bank of labeled prompts to extract hidden activations and perform k-nearest neighbor classification across multiple layers.
The technique demonstrates strong performance across six domains, achieving competitive or superior F1 scores compared to state-of-the-art fine-tuned guardrails, while running 2.7x faster than the best comparable method and 10x faster than a typical fine-tuned classifier. This efficiency is crucial for real-time deployment in production pipelines where latency and resource usage are critical factors.
This approach has significant implications for agent safety and robustness, especially in multi-agent systems or environments requiring dynamic guardrail configuration. The ability to quickly adapt to new domains by updating only the labeled prompt bank makes kNNGuard a promising tool for scalable and configurable safety mechanisms in AI agents.
Key insight: A training-free guardrail approach using kNN on LLM hidden activations achieves competitive performance with fine-tuned classifiers while offering significantly faster inference and easier domain adaptation.
Coding-agents can replicate scientific machine learning papers
Bilionis, Ilias arXiv: 2607.02134

This paper introduces Paper-replication, a workflow that transforms the process of replicating scientific claims into a structured coding-agent skill. Rather than relying on agent-generated messages alone, the system records targets, reconstructs methods, runs experiments, and links outputs to provenance for validation.
The evaluation across twelve independent runs on four scientific machine learning papers shows high success rates—158 recorded targets were matched with report coverage, and all workspaces passed completion gates. This indicates that structured workflows can make agent-driven replication more reliable and reproducible than ad-hoc prompting approaches.
This research contributes to the broader field of reasoning & planning by demonstrating how agents can be guided through complex tasks using evidence-based validation rather than just final outputs. It also supports advancements in memory & tool use, as it requires agents to maintain and manage structured records of their work throughout the process.
Key insight: Coding agents can effectively replicate scientific machine learning papers by structuring tasks into targets with recorded evidence, enabling validation checks and improving reproducibility.
Automated grading of Linux/bash examinations using large language models: a four-level cognitive taxonomy approach
Otero-Cerdeira, Lorena arXiv: 2607.02432
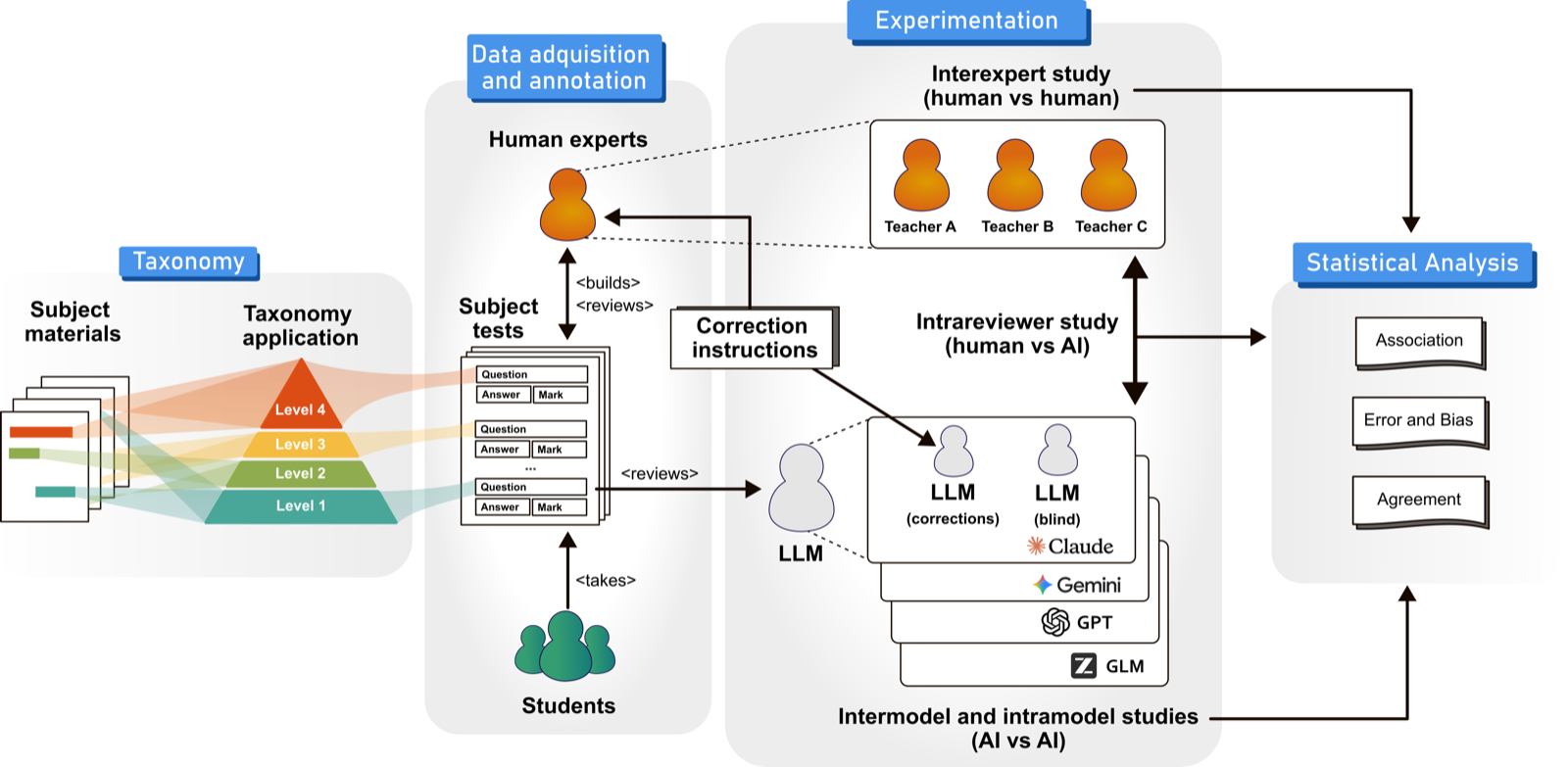
This study evaluates the use of LLMs for grading Linux/bash command-line examinations, applying a four-level cognitive taxonomy that ranges from basic file manipulation to advanced system management. The results show that Gemini 3.0 Pro with rubric-guided prompting achieved high human-AI agreement (ICC = 0.888), indicating strong alignment with expert judgment.
The research highlights the importance of prompt design and taxonomy-based question categorization in achieving accurate grading. Rubric quality had a larger impact than model choice, suggesting that structured prompts are key to leveraging LLMs for educational applications. The findings also reveal that question complexity is a reliable predictor of grading difficulty for LLMs.
While this work primarily focuses on education, its implications extend to agent evaluation and validation systems where automated scoring and feedback are needed. It provides a framework for determining which tasks can be handled by AI and which require human oversight, contributing to the broader goal of efficient and scalable LLM deployment in real-world settings.
Key insight: Large language models can approximate expert grading of Linux/bash command responses using a four-level cognitive taxonomy, with rubric-enhanced prompts improving agreement and accuracy.
AI Tooling

New Google commercial imagines a Declaration of Independence written with help from AI | TechCrunch
Google released a commercial imagining the Founding Fathers using Google Workspace tools to draft the Declaration of Independence. The ad shows Jefferson collaborating via Google Docs, scheduling meetings with Google Calendar, conducting remote sessions via Google Meet, and using AI for visualization tasks. Gemini is depicted taking meeting notes and providing advice on document access requests. The commercial highlights Google's AI capabilities while maintaining a tongue-in-cheek tone about historical collaboration.
Why it matters: This ad represents Google's strategic positioning of AI tools in creative and collaborative workflows, potentially influencing how enterprises view AI integration. The historical framing also signals Google's attempt to establish AI as a natural evolution of human productivity tools rather than a disruptive force.