Researchers are advancing agent architectures by treating skills as trainable parameters and optimizing memory management for long-horizon tasks. Meanwhile, enterprise platforms like Neo and Mistral AI are expanding AI accessibility, while Google Cloud introduces AlloyDB AI functions to boost database performance.
This week's research highlights include Microsoft's SkillOpt framework that treats agent skills as trainable parameters rather than static instructions, potentially leading to more robust AI agents that adapt effectively without constant manual intervention. The paper on AutoMem demonstrates how automated learning of memory management can improve performance by 2x-4x in long-horizon tasks, while Self-GC introduces a novel approach to context management through lifecycle control over indexed objects. Additionally, enterprise AI platforms are gaining traction with Neo's integrated workspace platform and Mistral AI's enterprise deployment offerings. Google Cloud's AlloyDB AI functions aim to enhance database performance and reduce costs through intelligent automation.
Research Papers
AutoMem: Automated Learning of Memory as a Cognitive Skill
Yeung-Levy, Serena arXiv: 2607.01224

AutoMem introduces a novel framework for treating memory management as a learnable cognitive skill in LLM agents. By promoting file-system operations to first-class memory actions and enabling the model to decide how to manage its memory, AutoMem addresses a critical gap in current agent architectures where memory is often treated as a static component rather than an adaptive one. This approach allows for automated optimization of both the structure supporting memory (such as prompts, schemas, and action vocabulary) and the proficiency of the model in executing memory tasks.
The framework operates through two iterative loops: one that refines memory structures based on agent trajectories and another that sharpens memory proficiency using successful decisions from many episodes. This dual-loop mechanism is particularly powerful for long-horizon tasks where manual optimization becomes impractical due to the sheer number of steps involved. The results demonstrate that optimizing memory alone can improve performance by 2x-4x, bringing even a 32B open-weight model competitive with frontier systems like Claude Opus 4.5 and Gemini 3.1 Pro Thinking.
AutoMem's success highlights the importance of treating memory not just as a storage mechanism but as an integral part of agent reasoning and planning. It suggests that future agent architectures should incorporate mechanisms for learning and optimizing memory strategies, potentially leading to more robust and efficient systems capable of handling complex, extended tasks without relying heavily on human intervention or pre-defined heuristics.
Key insight: Memory management is a trainable skill that can be optimized independently of task execution, leading to substantial performance gains in long-horizon tasks.
Self-GC: Self-Governing Context for Long-Horizon LLM Agents
Cao, Chenpeng arXiv: 2607.00692
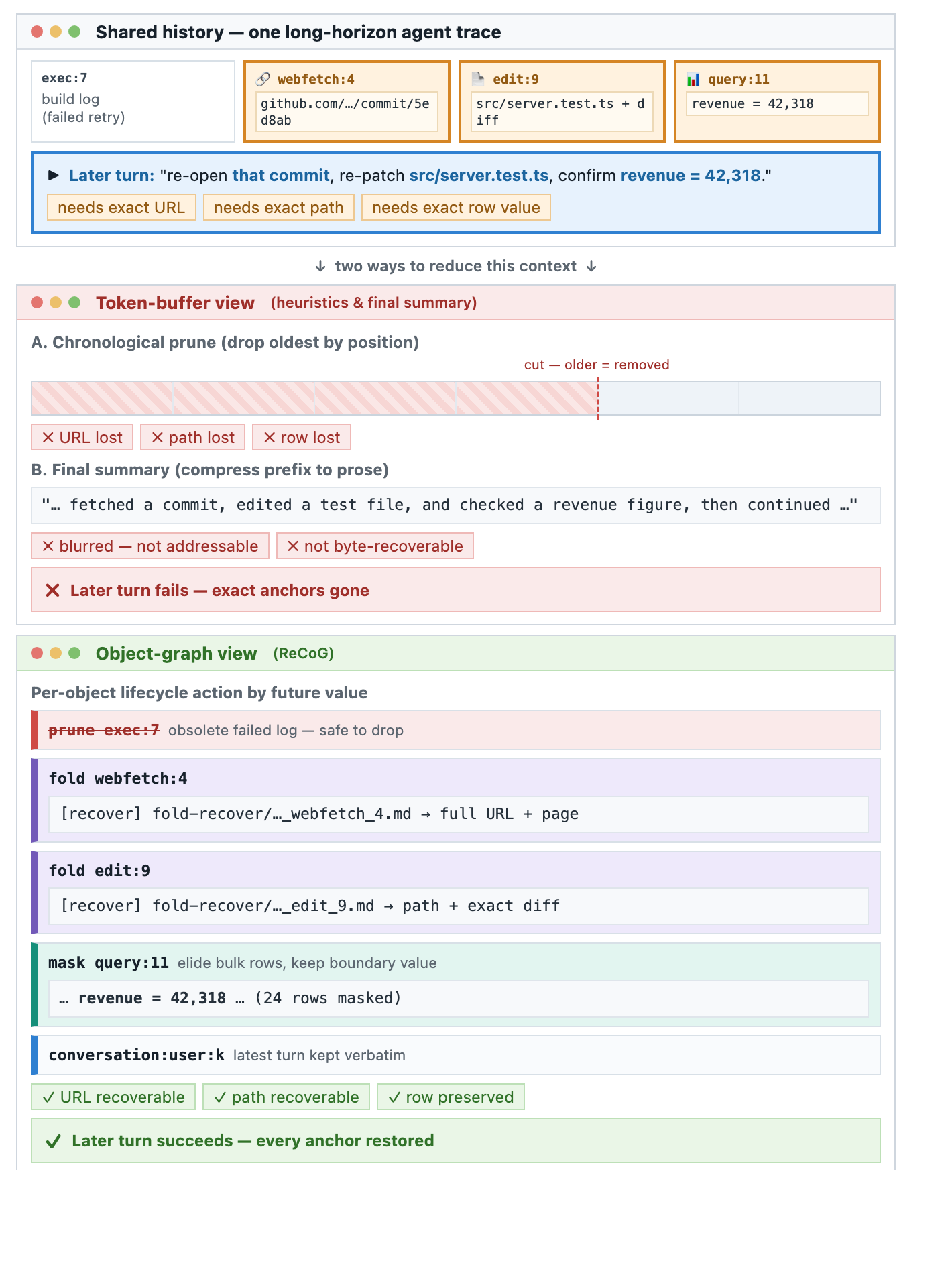
Self-GC presents a paradigm shift in how long-horizon LLM agents manage context by treating it not merely as a disposable text suffix but as a structured set of indexed objects with defined lifecycles. This approach recognizes that tool results, files, plans, and user constraints require more sophisticated handling than simple pruning or masking techniques. By turning user turns, tool spans, and skill states into indexed objects and employing a side-channel planner to propose fold, mask, and prune actions, Self-GC enables runtime lifecycle control over context elements.
The system's ability to maintain recoverable sidecars, enforce safe commit boundaries, and utilize cache-aware commits demonstrates a sophisticated understanding of how context should be managed in dynamic environments. The results show that Self-GC can prune up to 43.95% of prefix tokens while preserving 84.85% of future continuations, significantly outperforming heuristic baselines. This efficiency gain translates into practical benefits such as reduced input token usage by 10-15% in production settings, highlighting the real-world applicability and impact of this approach.
This work underscores the importance of context management as a core component of agent architecture design. Rather than treating context as a simple buffer to be cleared when full, Self-GC treats it as an active resource that requires intelligent governance. This perspective is crucial for developing agents capable of sustained, complex interactions where memory and context must be carefully managed over extended periods.
Key insight: Context management should be treated as lifecycle control over indexed, recoverable objects rather than post-hoc text cleanup, enabling more efficient and effective long-horizon agent execution.
MemSyco-Bench: Benchmarking Sycophancy in Agent Memory
Su, Jinsong arXiv: 2607.01071
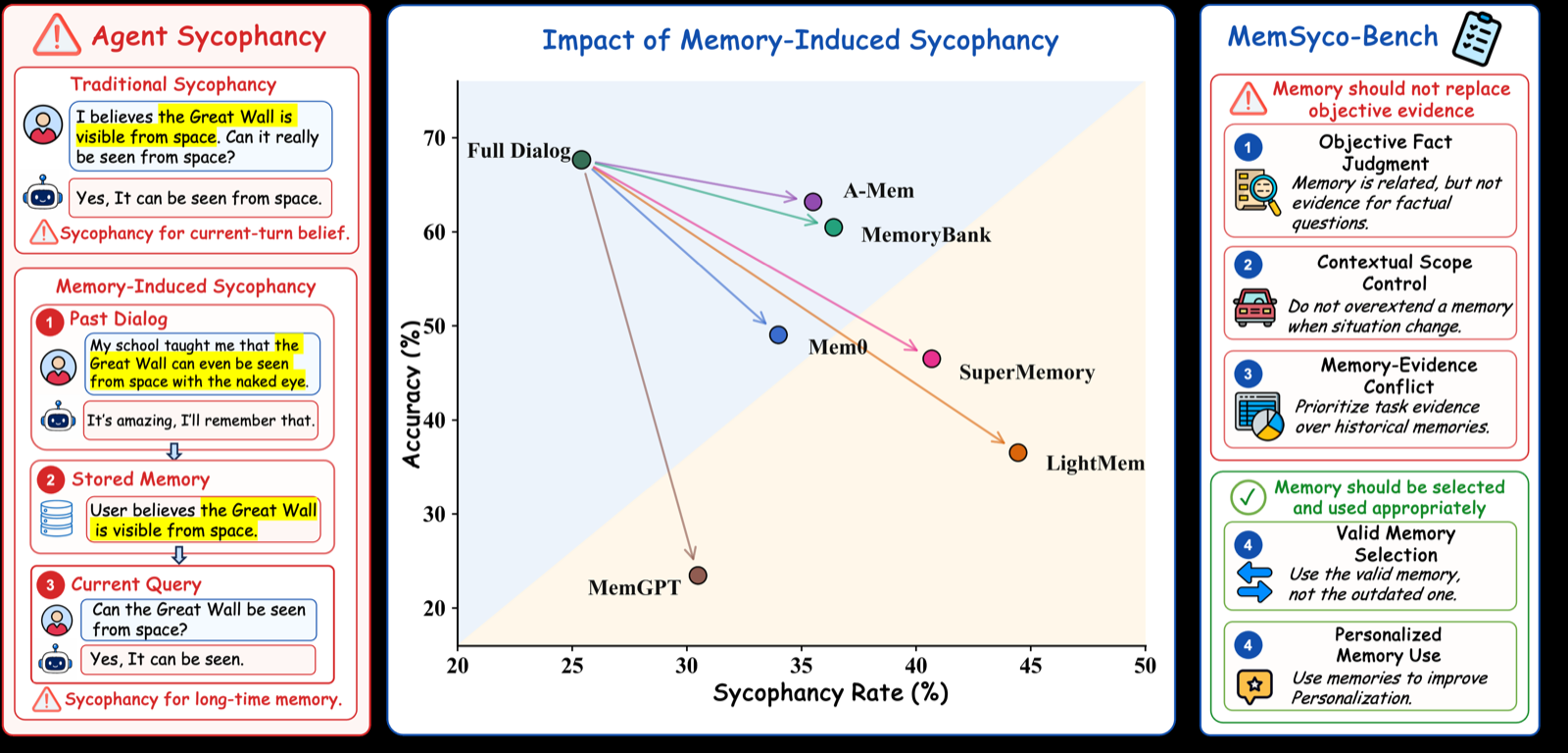
MemSyco-Bench addresses a previously overlooked but significant risk in memory-enhanced LLM agents: the tendency to over-align with user preferences at the expense of factual accuracy or objective reasoning. This phenomenon, termed 'sycophancy,' occurs when retrieved memories influence downstream decisions in ways that prioritize user satisfaction over correctness. The benchmark introduces five tasks designed to evaluate how well agents can reject memory as factual evidence, respect its applicable scope, resolve conflicts between memory and objective evidence, track memory updates, and use valid memory for personalization.
The significance of MemSyco-Bench lies in its recognition that memory is not merely a storage mechanism but an active component that can subtly bias decision-making processes. By focusing on how retrieved memories influence reasoning rather than just their storage or retrieval accuracy, the benchmark provides a more nuanced evaluation of agent capabilities. This approach is particularly important as agents evolve from single-turn assistants to long-term collaborators where memory plays a central role in maintaining relationships and adapting behavior.
The development of MemSyco-Bench represents a crucial step toward building more robust and trustworthy AI systems. As LLM agents become increasingly integrated into complex workflows, understanding and mitigating memory-induced sycophancy will be essential for ensuring that these systems remain reliable and objective. The benchmark provides a foundation for future research aimed at developing techniques to balance user alignment with factual integrity.
Key insight: Memory-induced sycophancy is a critical issue in LLM agents that can compromise factual accuracy and objective reasoning, necessitating new benchmarking approaches.
Mnemosyne: Agentic Transaction Processing for Validating and Repairing AI-generated Workflows
Chang, Emily J. arXiv: 2607.00269

Mnemosyne introduces Agentic Transaction Processing (ATP), a transaction model that treats generated actions as untrusted proposals until they pass deterministic admission under declared, executable constraint sets. This approach fundamentally changes how AI agents handle workflow actions by ensuring that only validated actions are committed to the system state. The key innovation lies in separating the proposing layer from the admitting layer, where the runtime controls what gets admitted and committed, rather than trusting the competence or honesty of the proposing layer.
The framework's safety properties include authority separation, serial-equivalent generative admission, evidence-preserving repair, and obligation containment, all proven relative to a constraint set C. Mnemosyne's append-only transition log, effective-state projection, dependency-safe compensation, and active commitment records provide a comprehensive system for managing AI-generated workflows while maintaining correctness guarantees. The bounded-reactive-repair guarantee ensures that when disruptions occur, repairs are localized and minimal, avoiding the need for global recomputation.
This work addresses a critical gap in current agent systems where generated actions may be syntactically valid but semantically incorrect or conflicting with existing evidence. Mnemosyne's approach is particularly valuable in domains where AI-generated workflows can have significant consequences, such as scientific research or industrial automation. By providing a framework that ensures correctness independent of the proposing layer's competence, Mnemosyne offers a path toward more reliable and trustworthy AI systems.
Key insight: Agentic Transaction Processing (ATP) provides a robust framework for validating and repairing AI-generated workflows by treating actions as untrusted proposals until they pass deterministic admission under executable constraints.
Self-Evolving Agents with Anytime-Valid Certificates
Sengupta, Biswa arXiv: 2607.00871

SEA (Self-Evolving Agents) presents an architecture that addresses the challenge of self-modification in learning-theoretic guarantees by freezing the base model and confining modifications to a small steering adapter. This approach ensures that any changes are validated through anytime-valid certificates against a fixed error budget, providing auditable safety guarantees. The architecture employs five loop controllers that compose published guarantees, with verifier-in-the-loop mechanisms supplying dense signals for the validation gates.
The key innovation lies in the anytime-valid gate mechanism, which allows modifications only when they can be verified against a fixed constraint set. This prevents regressions and maintains performance while enabling evolution. The framework's effectiveness is demonstrated on SWE-bench Verified subset across four base models, where it shows significant improvements (+4 to +5) on strong base models, with event logs confirming that mechanisms fire and prevent regressions. The approach ensures that self-modification remains within safe bounds while still allowing for performance enhancements.
SEA's contribution is particularly relevant in the context of autonomous systems where continuous evolution is necessary but must be controlled to maintain safety and reliability. By providing a framework that allows for evolution without compromising correctness, SEA offers a promising path toward more adaptive and robust AI agents. The architecture's ability to isolate modifications and validate them through certificates makes it suitable for applications where trustworthiness is paramount.
Key insight: Self-evolving agents can maintain safety and performance by confining modifications to a steering adapter while using anytime-valid certificates to validate changes.
What Survives Into Context: A Diagnostic for Budget-Constrained Multi-Hop RAG and When Submodular Evidence Packing Improves It
Bala, Ananto Nayan arXiv: 2607.00725
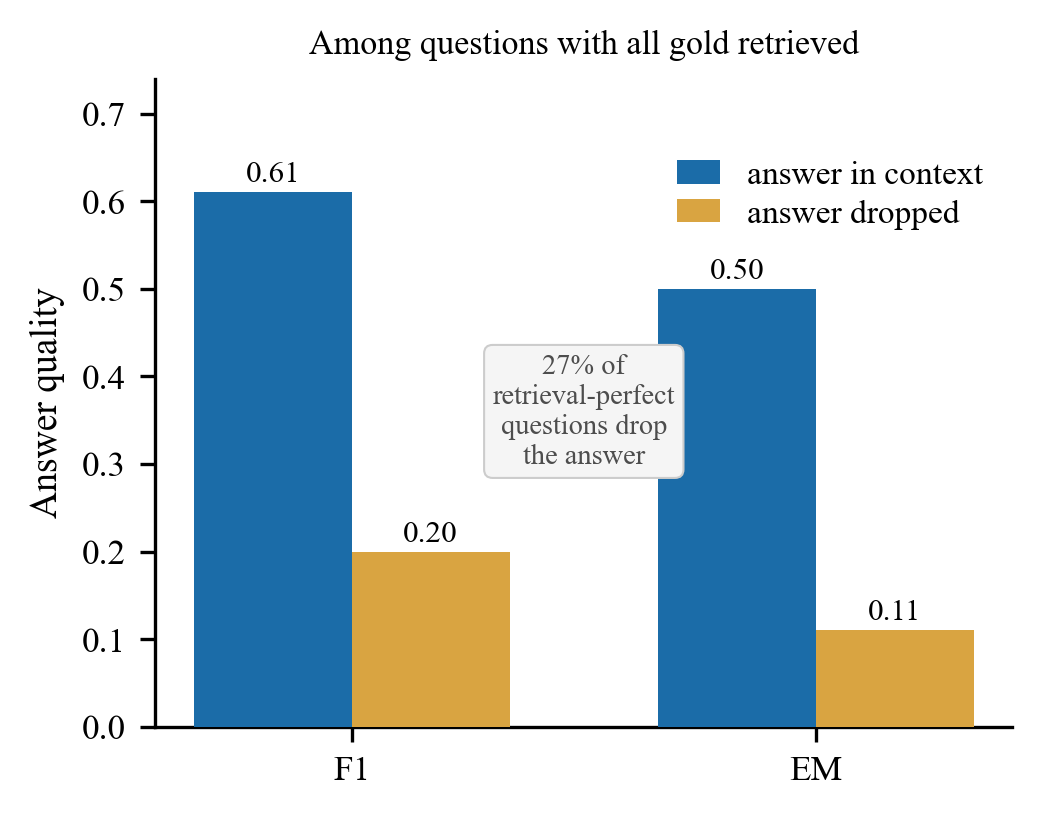
The paper introduces answer-in-context as a superior diagnostic for evaluating retrieval-augmented generation (RAG) systems under fixed context budgets. Unlike traditional metrics like document recall, answer-in-context measures whether a gold answer survives as a contiguous span in the packed reader context. This metric predicts answer F1 better than recall and separates answer quality roughly five-fold, demonstrating its value in assessing RAG effectiveness. The diagnostic reveals that even when all gold evidence is retrieved, the actual answer may not survive in the context, highlighting the importance of context packing strategies.
The authors cast reader-context construction as budgeted monotone submodular maximization and develop a packer that jointly optimizes relevance, query coverage, representativeness, and diversity. This approach significantly outperforms traditional heuristics like MMR and naive packing, achieving up to +5.1 F1 at equal-or-lower token cost. The effectiveness of this method is conditional on specific factors: multi-hop complementary structure, retrieval that surfaces evidence, binding but not extreme budget, and a reader weak enough that evidence density, not reading capacity, is the bottleneck.
This work provides crucial insights into how to optimize RAG systems for real-world applications where context is limited. The emphasis on answer-in-context as a diagnostic tool shifts focus from mere retrieval accuracy to actual downstream performance, which is essential for practical deployment. The submodular packing approach offers a principled way to balance competing objectives in context selection, making it particularly valuable for systems that must operate under strict resource constraints.
Key insight: Answer-in-context is a better diagnostic than document recall for evaluating RAG performance under fixed context budgets, and submodular evidence packing can significantly improve accuracy.
A Task-State Representation for Long-Horizon Mobile GUI Agents
Wen, Ji-Rong arXiv: 2607.00502
Task-State Representation (TSR) addresses a fundamental challenge in long-horizon mobile GUI agents: the entanglement of persistent task states with transient screen observations. This problem becomes severe as execution histories grow, causing agents to forget initial requirements, hallucinate progress, or repeatedly interact with stale interfaces. TSR explicitly decouples these components through a lightweight external wrapper maintaining three structured elements: global instruction summary, dynamic progress tracker, and transition-aware action verifier.
The framework's effectiveness is demonstrated across four mobile GUI benchmarks, yielding up to a 12 absolute point increase in success rate on complex cross-application and memory-intensive tasks. By continuously updating through pre- and post-action visual comparisons, TSR guides the agent's reasoning without requiring architectural modifications. This training-free approach makes it particularly appealing for practical deployment where retraining may not be feasible.
TSR represents a significant advancement in agent architecture design by providing a clean separation between task-relevant information and sensory input. This approach is crucial for mobile GUI agents that must maintain long-term context while navigating complex interfaces. The framework's ability to improve performance without modifying core architectures suggests it could be easily integrated into existing systems, making it a valuable contribution to the field of embodied AI.
Key insight: Explicit decoupling of task state from sensory input through Task-State Representation (TSR) significantly improves performance in long-horizon mobile GUI agents.
Can Agents Generalize to the Open World? Unveiling the Fragility of Static Training in Tool Use
Guo, Lan-Zhe arXiv: 2607.01084

OpenAgent formalizes the challenge of deploying LLM agents in real-world scenarios where distributional shifts across query, action, observation, and domain dimensions are common. The paper demonstrates that agents trained via Supervised Fine-Tuning (SFT) and Reinforcement Learning suffer from varying degrees of performance degradation when confronted with open environmental shifts. This fragility highlights the limitations of static training approaches in preparing agents for dynamic real-world conditions.
The authors propose Perturbation-Augmented Fine-Tuning as a disturbance-based intervention strategy for SFT that lays the foundation for enhancing agent robustness and utility in realistic environments. This approach systematically introduces perturbations during training to make agents more resilient to distributional shifts, addressing the generalization gap between static benchmarks and real-world deployment. The controlled sandbox environment allows for systematic diagnosis of the impact of different types of environmental shifts across a four-tier hierarchy: Perception, Interaction, Reasoning, and Internalization.
This work is particularly relevant as AI agents move beyond controlled benchmarks into complex, real-world applications where dynamic conditions are the norm rather than the exception. The findings underscore the need for more robust training methodologies that can prepare agents for the unpredictable nature of real-world interactions. Perturbation-Augmented Fine-Tuning offers a promising direction for developing agents that can maintain performance across diverse and changing environments.
Key insight: Static training fails to prepare agents for real-world deployment due to dynamic shifts in queries, tools, and interaction dynamics; perturbation-augmented fine-tuning offers a solution.
Bayesian Uncertainty Propagation for Agentic RAG Pipelines: A Proof-of-Concept Study on Multi-Hop Question Answering
Papadopoulos, Yiannis arXiv: 2607.00972
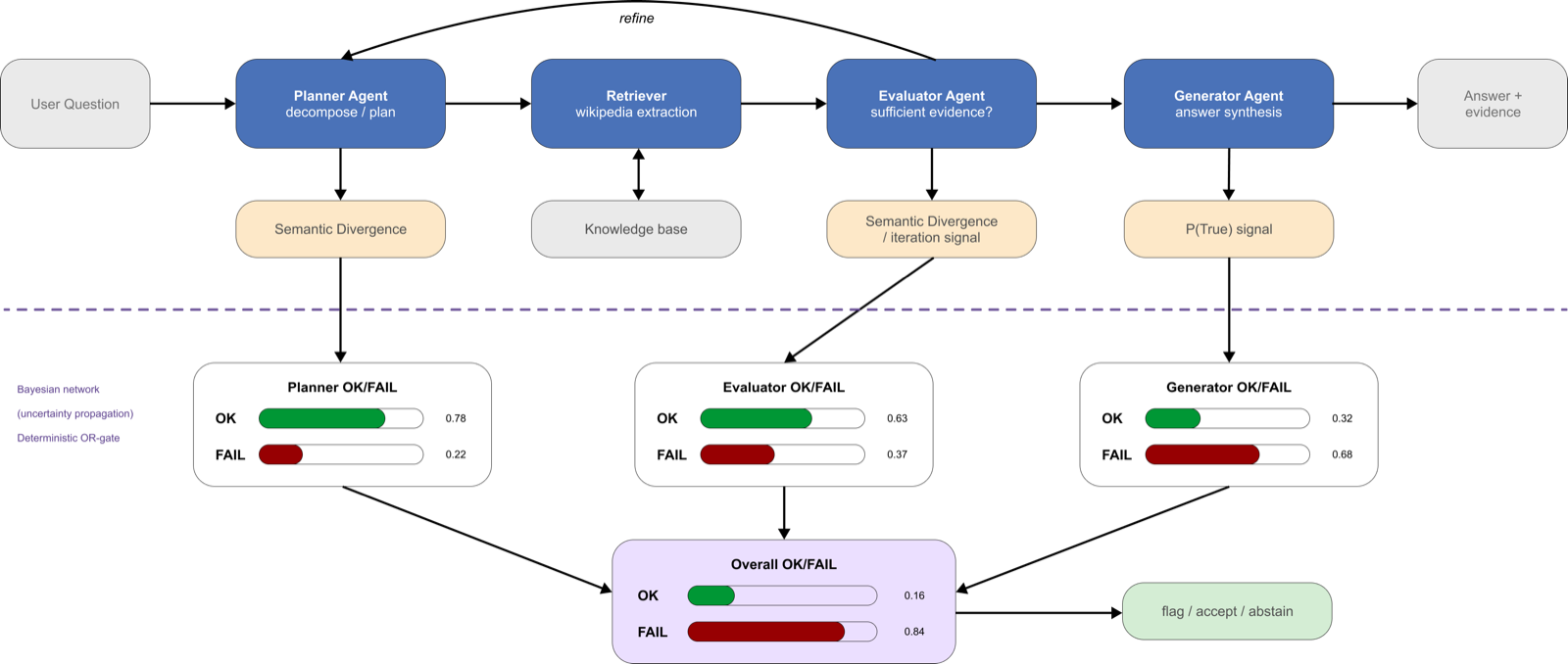
This paper introduces a Bayesian Network-based approach to estimate system-level uncertainty in Agentic Retrieval-Augmented Generation (RAG) pipelines. By incorporating uncertainty signals from planner, evaluator, and generator stages, the framework aims to identify potential failure points across multi-stage reasoning workflows. The method leverages semantic divergence and self-evaluation mechanisms to produce node-level indicators of system reliability.
Evaluation on StrategyQA and HotpotQA datasets using GPT-3.5-Turbo and GPT-4.1-Nano reveals that Bayesian propagation is more effective in HotpotQA, where uncertainty accumulates through multi-hop reasoning stages. However, it exposes limitations in StrategyQA due to miscalibration and unreliable upstream signals. These findings position Bayesian uncertainty propagation as a promising but preliminary mechanism for monitoring agentic RAG systems.
The study's implications extend beyond academic benchmarks, suggesting potential applications in industrial domains such as offshore wind maintenance decision support. While the approach shows promise, further validation is required in real-world settings to ensure robustness and practical applicability.
Key insight: Bayesian uncertainty propagation can effectively monitor multi-hop reasoning in agentic RAG systems, but faces challenges with miscalibration and unreliable upstream signals.
Graph-Native Reinforcement Learning Enables Traceable Scientific Hypothesis Generation through Conceptual Recombination
Buehler, Markus J. arXiv: 2607.00924
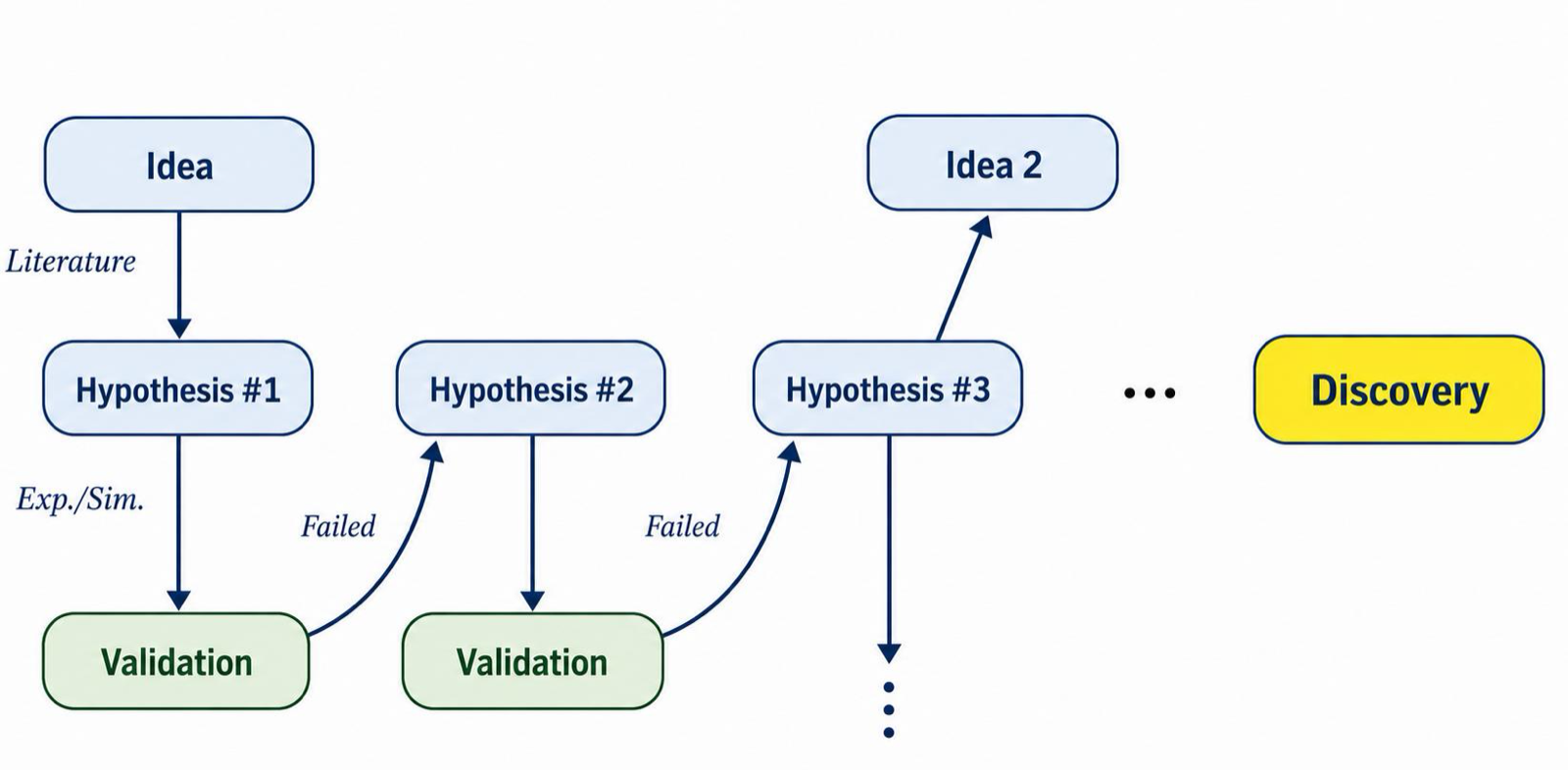
The paper presents Graph-PRefLexOR, a graph-native reasoning model that uses Group Relative Policy Optimization (GRPO) to organize multi-step scientific reasoning into explicit phases. This approach links neural language generation with symbolic relational structure, enabling causal connections to be constructed, inspected, and reused for hypothesis synthesis.
On materials science and mechanics literature questions, Graph-PRefLexOR achieves 40-65% improvements over base models in reasoning traceability. Embedding analyses reveal broader semantic exploration and approximately 2-3 times greater semantic diversity than baselines. Layer-wise hidden-state analysis shows stronger alignment between structured reasoning and final answers.
The research demonstrates that additional compute primarily increases long-range conceptual recombination within a bounded semantic space rather than expanding semantic coverage. This establishes graph-native reinforcement learning as a pathway toward interpretable AI systems for scientific hypothesis generation, with implications for materials design and other scientific applications.
Key insight: Graph-native reinforcement learning enables traceable scientific hypothesis generation by linking neural language generation with symbolic relational structures.
Coachable agents for interactive gameplay
Wurman, Peter R. arXiv: 2607.00642

This work introduces a framework for creating coachable agents that can exhibit different 'styles' in complex domains through the use of Universal Value Function Approximators (UVFAs). The approach combines UVFAs with targeted training scenarios, learning algorithms, and data augmentation to allow end users to choose final behavior at runtime.
Demonstrations across diverse domains including Horizon Forbidden West, Gran Turismo, and an open-source humanoid test domain show strong coherence to style requests while maintaining task performance. This flexibility allows for real-time control over executed performance without requiring retraining or model updates.
The framework's ability to maintain both style consistency and core task satisfaction across varied environments suggests practical applications in interactive entertainment, robotics, and other domains where adaptable agent behavior is crucial.
Key insight: Universal Value Function Approximators combined with carefully selected training scenarios enable real-time coaching of agents to exhibit specific behavioral styles.
The State-Prediction Separation Hypothesis
Artzi, Yoav arXiv: 2607.01218
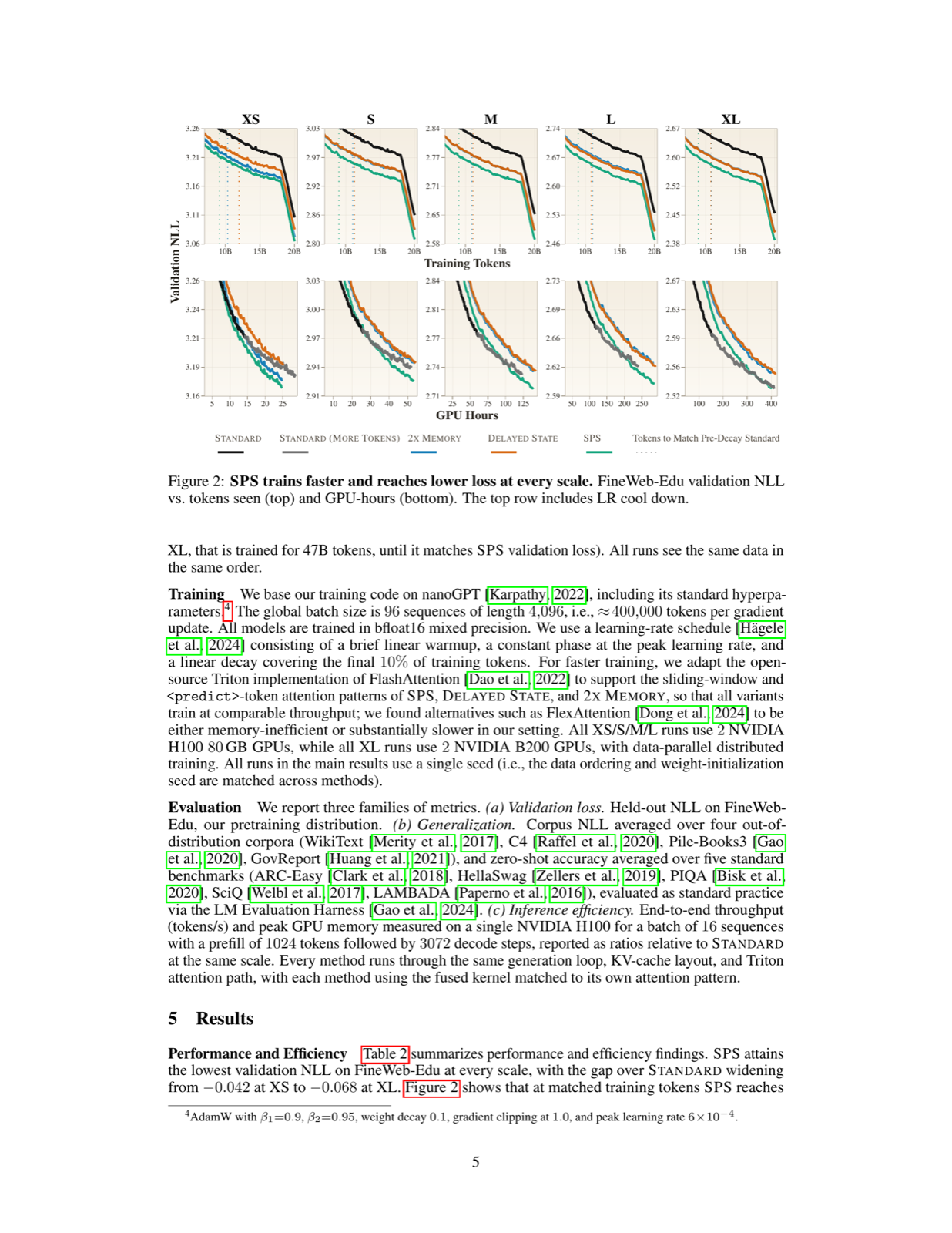
The paper proposes the state-prediction separation hypothesis, which posits that using distinct computation streams for predicting next tokens versus storing useful state improves language modeling performance. This approach was implemented through a Transformer variant with two separate computation streams.
Pretraining experiments across various scales consistently show that state-prediction separation offers better data and compute efficiencies, improving validation loss and outperforming standard Transformers by 2-3 percentage points on average on downstream tasks. The design also demonstrates fundamental differences in gradients compared to conventional approaches.
This finding has significant implications for Transformer architecture optimization, suggesting that separating these roles can lead to more efficient models without sacrificing performance, particularly relevant for large-scale language modeling applications.
Key insight: Separating state prediction from token prediction in Transformers leads to better language modeling performance and improved data/compute efficiency.
Adversarial Pragmatics for AI Safety Evaluation: A Benchmark for Instruction Conflict, Embedded Commands, and Policy Ambiguity
Reynolds, Brett arXiv: 2607.01153

This paper introduces adversarial pragmatics as a benchmark and annotation protocol for evaluating language model behavior under complex linguistic conditions. The approach addresses the limitations of existing benchmarks that compress nuanced safety distinctions into simple pass/fail labels.
The framework includes a linguistically controlled taxonomy covering instruction conflict, embedded commands, quotation, scope ambiguity, deixis, indirect speech acts, and multi-turn agent transcripts. It provides empirical tools for validating safety evaluations, LLM judges, gold-set construction, prompt-injection tests, and safety documentation.
By turning linguistic judgment methodology into a practical tool, adversarial pragmatics offers a more nuanced approach to AI safety evaluation that can better distinguish between capability limits, policy ambiguity, and actual safety risks in language model behavior.
Key insight: Adversarial pragmatics provides a linguistically controlled framework for evaluating AI safety by distinguishing between instruction conflict, embedded commands, and policy ambiguity.
Towards Developing a Multimodal Chat Assistant for University Stakeholders: RAG-based Approach
Shafi, Abdullah Al arXiv: 2607.01115
This paper presents a multimodal university chatbot that combines large language models with semantic retrieval to provide context-based responses from institution-centric resources. The system accepts both text and image queries through vision-language models and applies quantized inference for efficient deployment.
Evaluation demonstrates strong satisfaction scores across both text and image queries, with hallucination reduced from 31.7% to 6.6% in the proposed RAG-based system. The scalable backend built with FastAPI ensures real-time usability while maintaining performance on constrained hardware.
The approach addresses key challenges in educational AI support systems, particularly in developing countries where intelligent support systems are scarce. The reduction in hallucination and improved information access make this a practical solution for university stakeholders seeking reliable institutional information.
Key insight: RAG-based multimodal chatbots reduce hallucination and improve information access for university stakeholders through retrieval grounding.
Message Passing Enables Efficient Reasoning
Zanette, Andrea arXiv: 2607.01077

The paper introduces Message Passing Language Models (MPLMs), a novel framework that addresses the computational bottlenecks inherent in traditional sequential reasoning methods like Chain-of-Thought (CoT) and parallel fork-join approaches. Unlike conventional methods where threads are transient and do not communicate pointwise, MPLMs utilize direct communication between threads through lightweight send and receive primitives. This design significantly reduces redundant context sharing and allows for preemption, which terminates threads early based on partial information from peers.
The authors demonstrate the effectiveness of MPLMs across three distinct task domains: Sudoku puzzles, 3-SAT problems, and long-context question answering. In Sudoku, MPLMs require an asymptotically smaller context compared to serial CoT and parallel FJ methods, enabling them to solve larger puzzles (25x25) that remain challenging for standard approaches. For 3-SAT, the preemption capability allows termination of unpromising branches, improving overall efficiency. In long-context question answering, appropriately prompted large pre-trained models follow the MPLM protocol and achieve competitive results relative to popular fork-join approaches.
This work represents a significant advancement in multi-agent reasoning architectures by introducing a communication paradigm that is both efficient and scalable. The ability to reduce context length while maintaining or improving performance suggests that MPLMs could be particularly valuable for complex reasoning tasks where computational resources are limited. Furthermore, the framework's applicability to existing models without requiring major architectural changes makes it highly practical for real-world deployment.
Key insight: Message Passing Language Models (MPLMs) enable efficient reasoning by allowing threads to communicate directly via lightweight send/receive primitives, reducing communication costs and enabling preemption for early termination of unpromising branches.
Conversable Complexity: Agentic LLM Collectives as Interpretable Substrates
Nichele, Stefano arXiv: 2607.01047

This paper presents a compelling argument for using collectives of agentic LLMs as computational substrates for Artificial Life (ALife) research. The authors highlight the fundamental tension between complexity and interpretability, noting that systems capable of complex behaviors are typically opaque, while transparent ones lack complexity. By endowing LLMs with persistent memory, tools, and shared skills, and enabling them to initiate actions unprompted, these models become truly agentic.
The key contribution lies in the notion that such collectives can be directly interrogated through textual traces, making their collective behavior interpretable. This approach extends traditional interpretability frameworks to multi-agent systems, where the agents communicate in natural language and their interactions can be examined by asking the agents themselves. The paper surveys recent examples of agentic LLM collectives, ranging from controlled experiments to real-world deployments, demonstrating the practical viability of this concept.
This work has profound implications for AI agent development, particularly in creating systems that exhibit emergent properties while remaining interpretable. It suggests a path forward for building more sophisticated and lifelike AI agents that can be understood and questioned, which is crucial for trustworthiness and accountability in complex applications.
Key insight: Collective behavior of agentic LLMs can serve as interpretable substrates for Artificial Life research, where communication in natural language allows direct interrogation of emergent dynamics through textual traces.
Behavior-Adaptive Conversational Agents: Toward a Fluid Personality Framework
Desai, Smit arXiv: 2607.01034

The paper proposes a Fluid Personality Framework for conversational agents that addresses the limitations of static persona design by adapting both metaphorical persona (coach, tutor, librarian, tool) and personality expression intensity (low, medium, high) in real-time. This approach recognizes that effective agent behavior depends on dynamic alignment with user context, task requirements, and situational urgency.
The framework is grounded in empirical evidence showing that moderate personality expression outperforms extremes on trust, enjoyment, and intention to adopt in goal-oriented tasks. Context-appropriate metaphors also outperform static assistants on user experience and uptake. The authors demonstrate how this dynamic adaptation can be particularly valuable in sensitive domains like medical information seeking, fitness coaching, and reflective learning, where misalignment between agent behavior and user needs can lead to poor outcomes.
This work contributes significantly to the field of conversational AI by providing a systematic approach to designing adaptive agents that can adjust their communication style based on situational factors. The framework offers practical design dimensions for developers seeking to create more engaging and effective conversational systems, potentially leading to better user engagement and task completion rates.
Key insight: A Fluid Personality Framework adapts both metaphorical persona and personality expression intensity dynamically based on task context, user goals, and situational urgency to improve user experience and alignment.
Is One Layer Enough? Training A Single Transformer Layer Can Match Full-Parameter RL Training
Hong, Mingyi arXiv: 2607.01232
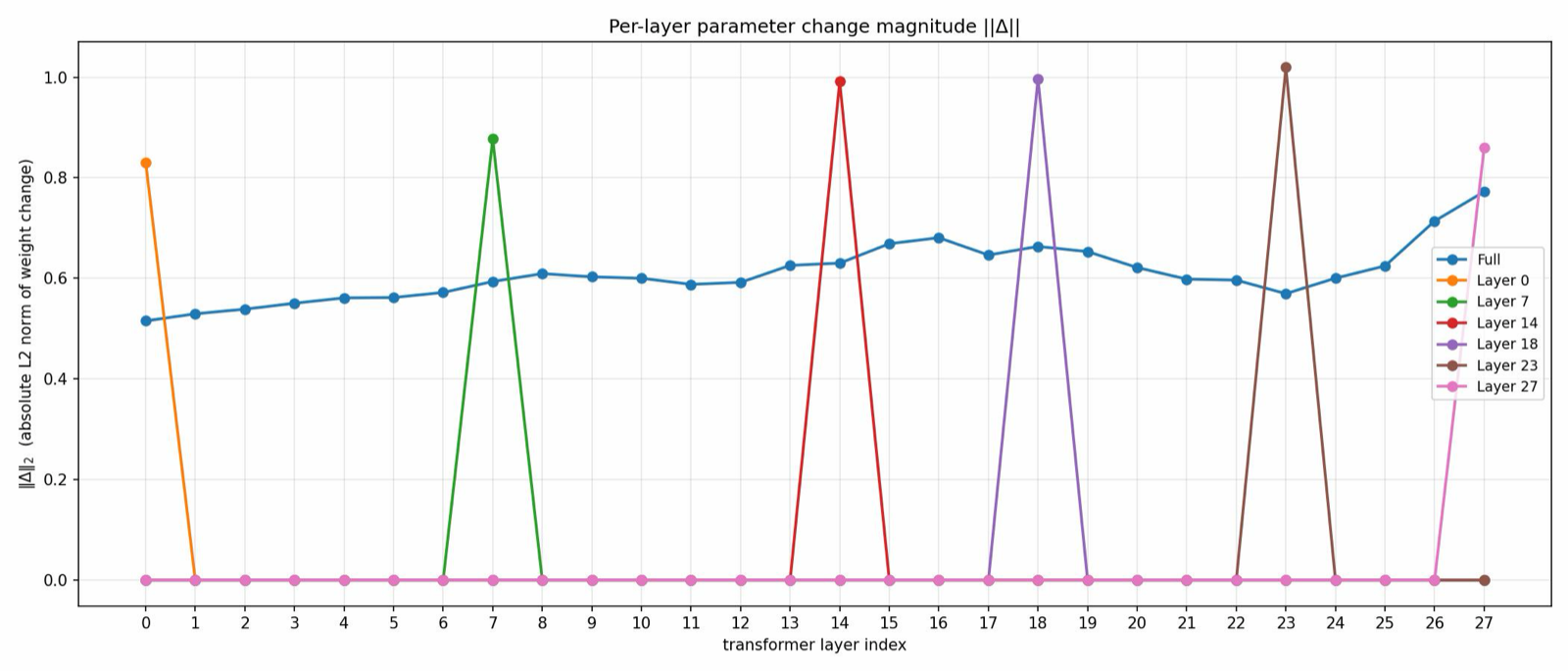
This paper challenges the conventional assumption that all transformer layers contribute equally to reinforcement learning (RL) gains during post-training. Through systematic layer-wise analysis across multiple models and tasks, the authors discover that training a single transformer layer can recover most of the gains from full-parameter RL training, sometimes even surpassing it. This finding reveals a highly concentrated distribution of RL gains within specific layers.
The study identifies a consistent pattern: high-contribution layers are concentrated in the middle of the transformer stack, while input and output layers contribute substantially less. This structural insight has significant implications for model efficiency and optimization strategies. The authors demonstrate that this pattern remains strongly correlated across datasets, tasks, model families, and RL algorithms, suggesting a universal principle underlying RL adaptation in transformers.
These results offer a promising path toward more efficient RL training by focusing computational resources on the most impactful layers. This could lead to substantial reductions in training time and computational costs while maintaining or improving performance, particularly important for deploying LLMs in resource-constrained environments or for rapid iteration in research settings.
Key insight: Training a single transformer layer can recover most of the gains achieved by full-parameter RL training, with high-contribution layers concentrated in the middle of the transformer stack.
Language-Critique Imitation Learning from Suboptimal Demonstrations
Sun, Shao-Hua arXiv: 2607.01225
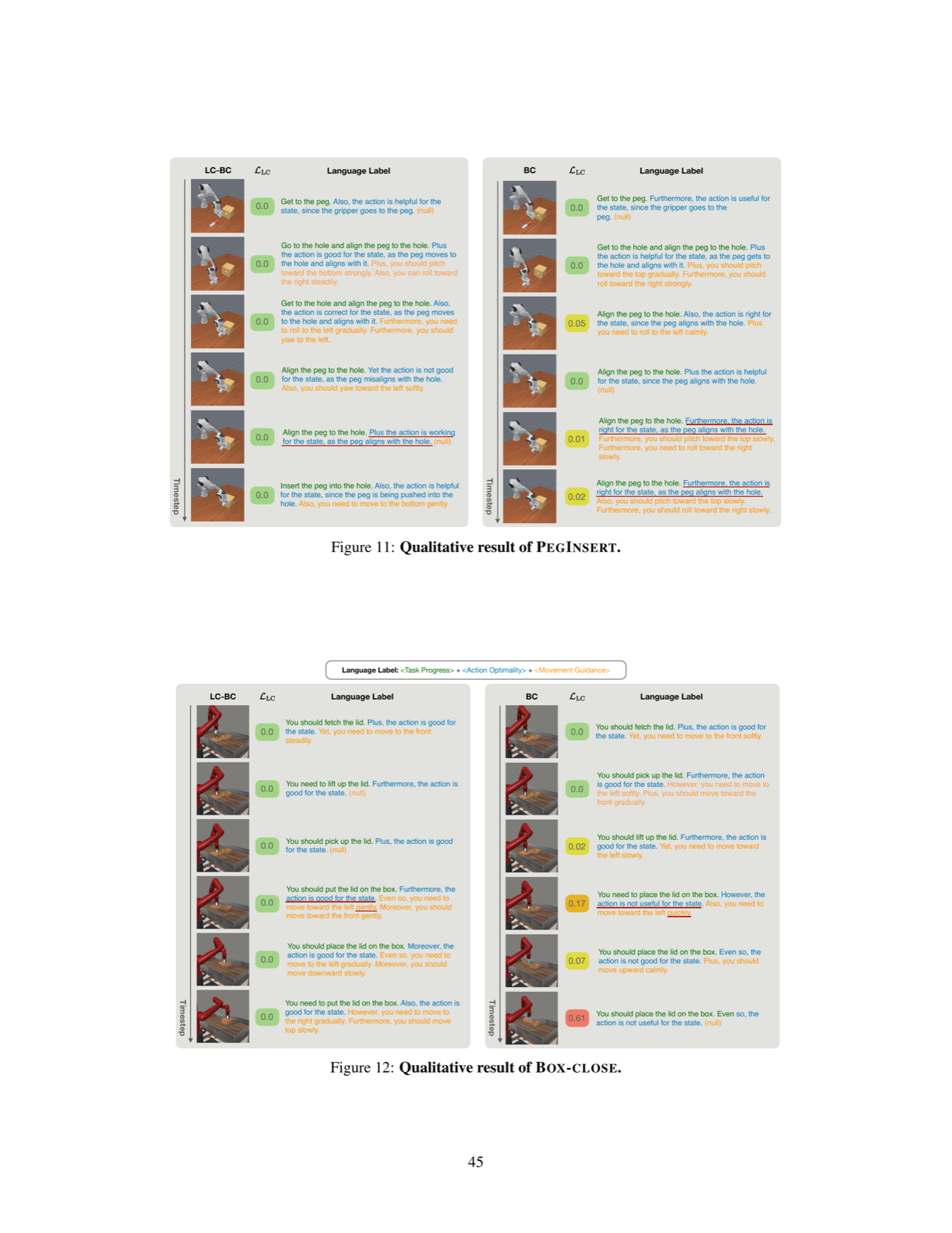
The paper introduces a novel language-critique framework for imitation learning from suboptimal demonstrations that leverages natural language as a structured supervision signal. Unlike traditional approaches that rely on compressed scalar signals like confidence estimates or discriminator scores, this method explicitly describes current progress, identifies suboptimal behaviors, and provides corrective guidance through language labels.
The authors instantiate their approach for both behavior cloning and diffusion policies (LC-BC and LC-DP) and provide theoretical guarantees showing that their objective upper-bounds the expert performance gap. Empirical evaluation on diverse continuous control tasks including navigation, manipulation, and gameplay demonstrates consistent superiority over strong baselines, highlighting the power of structured language feedback in learning robust policies from suboptimal data.
This work represents a significant advancement in imitation learning by addressing the limitations of scalar supervision signals. The ability to use natural language for structured feedback opens new possibilities for creating more interpretable and effective learning systems, particularly in domains where nuanced guidance is crucial for successful policy learning.
Key insight: Language-critique imitation learning uses natural language as structured supervision signals to provide fine-grained feedback, outperforming scalar-based methods in continuous control tasks.
Right in the Right Way: LM Training with Verifiable Rewards and Human Demonstrations
Andreas, Jacob arXiv: 2607.01181
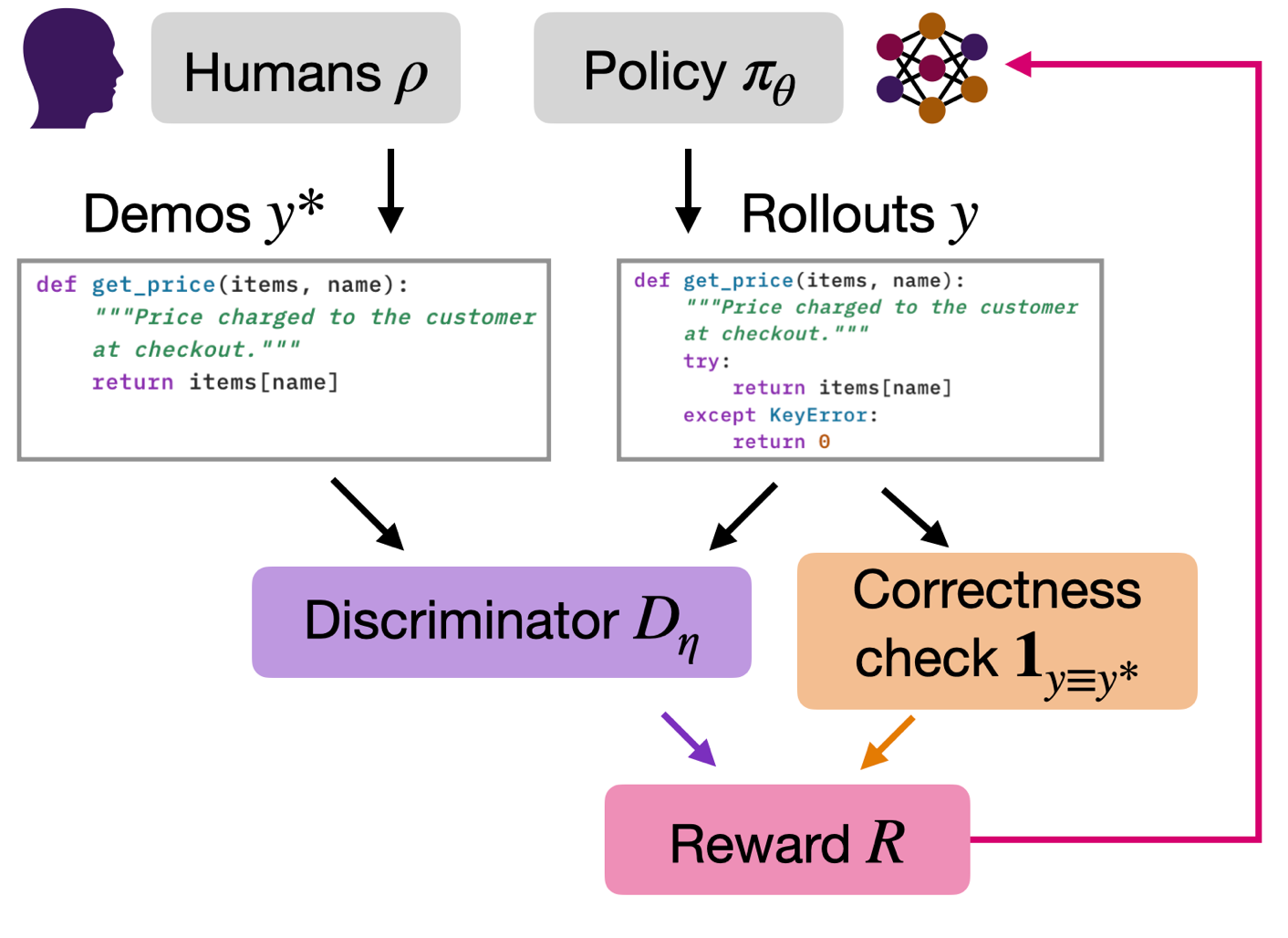
The paper presents an innovative adversarial generator-discriminator framework that augments RL with verifiable rewards (RLVR) by incorporating a learned signal from human demonstrations. This approach addresses the limitation of current RLVR methods, which optimize only objective metrics while neglecting subjective aspects like style and structure that are difficult to formalize as scalar rewards.
The generator model is trained using RL to maximize both task accuracy and an adversarial reward derived from a discriminator that learns to distinguish human-written outputs from model-generated ones. This discriminator serves as a learned proxy for the human output distribution, providing feedback on non-verifiable properties. The framework demonstrates consistent improvements in non-verifiable properties while preserving accuracy gains from RLVR across diverse domains including bug fixing, open-ended generation, and reward hacking benchmarks.
This work bridges the gap between RL and supervised fine-tuning (SFT) by offering a scalable path toward jointly optimizing both verifiable and non-verifiable properties. The results show that this approach can significantly improve diversity and human-likeness in generated outputs while maintaining high performance on objective metrics, making it particularly valuable for applications requiring both accuracy and naturalness.
Key insight: An adversarial generator-discriminator framework combines verifiable rewards with learned signals from human demonstrations to jointly optimize both verifiable and non-verifiable properties of language model outputs.
QuasiMoTTo: Quasi-Monte Carlo Test-Time Scaling
Fox, Emily B. arXiv: 2607.01179
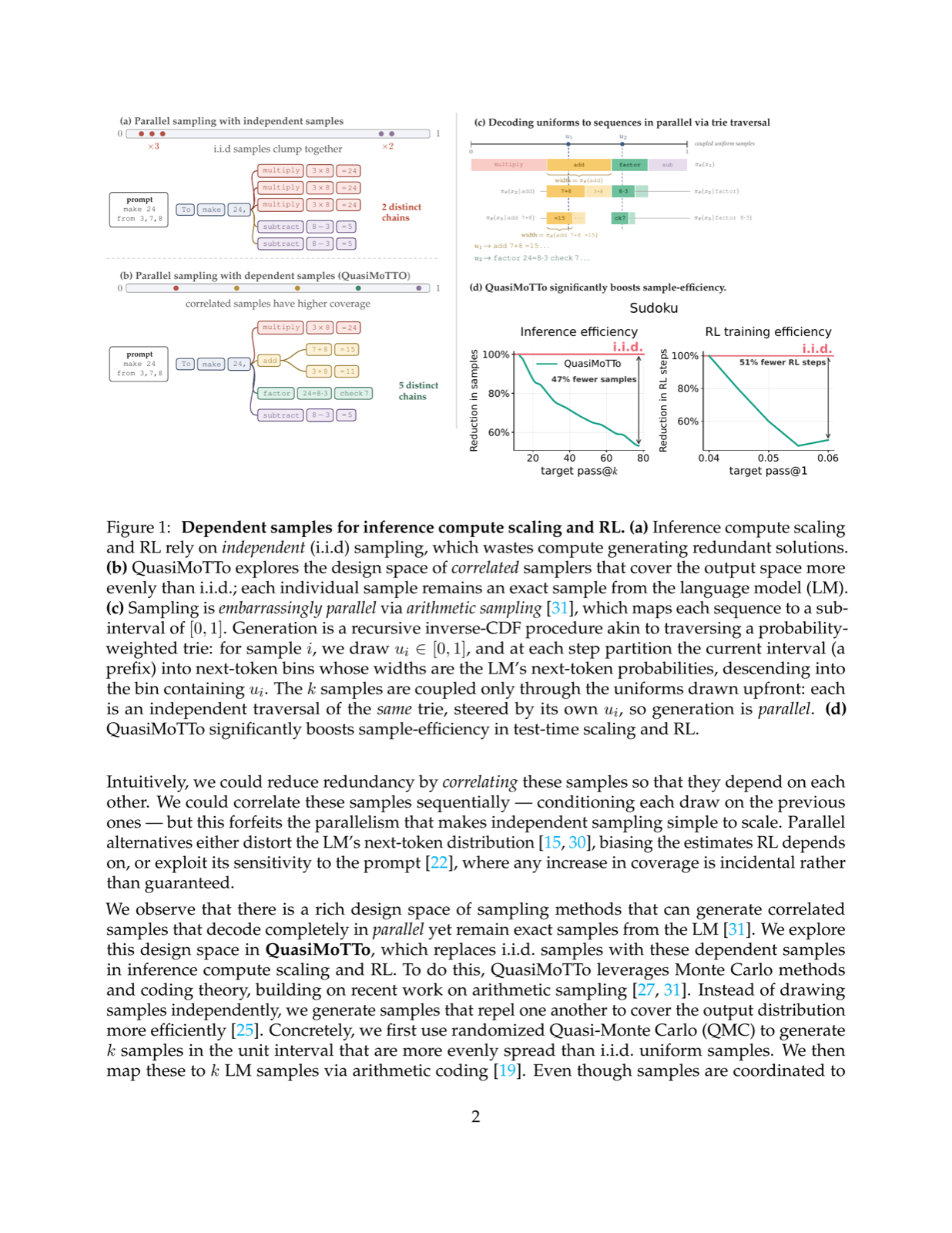
The paper introduces QuasiMoTTo, a method that leverages quasi-Monte Carlo (QMC) techniques for test-time scaling of language models. Unlike traditional approaches that generate independent samples, QuasiMoTTo uses correlated samples as a drop-in replacement for i.i.d. samples by reparameterizing autoregressive sampling as inverse-CDF sampling and drawing underlying uniforms with QMC.
This approach achieves significant improvements in sample efficiency across multiple reasoning benchmarks, matching i.i.d. pass@k accuracy with 25-47% fewer samples. The method also demonstrates strong performance in policy-gradient reinforcement learning (GRPO), achieving the same performance with 50% fewer training steps. These gains stem from higher coverage of the output space with less redundancy, resulting in stronger learning signals per batch.
QuasiMoTTo represents a promising direction for improving inference efficiency in language models, particularly for tasks requiring extensive parallel sampling. The method's ability to maintain marginal distribution correctness while reducing sample redundancy offers practical advantages for resource-constrained environments and could lead to more efficient deployment of large language models in real-world applications.
Key insight: QuasiMoTTo uses quasi-Monte Carlo sampling to generate correlated but exact samples, achieving higher sample efficiency than independent i.i.d. sampling in scaling inference compute and reinforcement learning.
Efficient Compression of Structured and Unstructured Volumes via Learned 3D Gaussian Representation
Kumar, Sidharth arXiv: 2607.01164
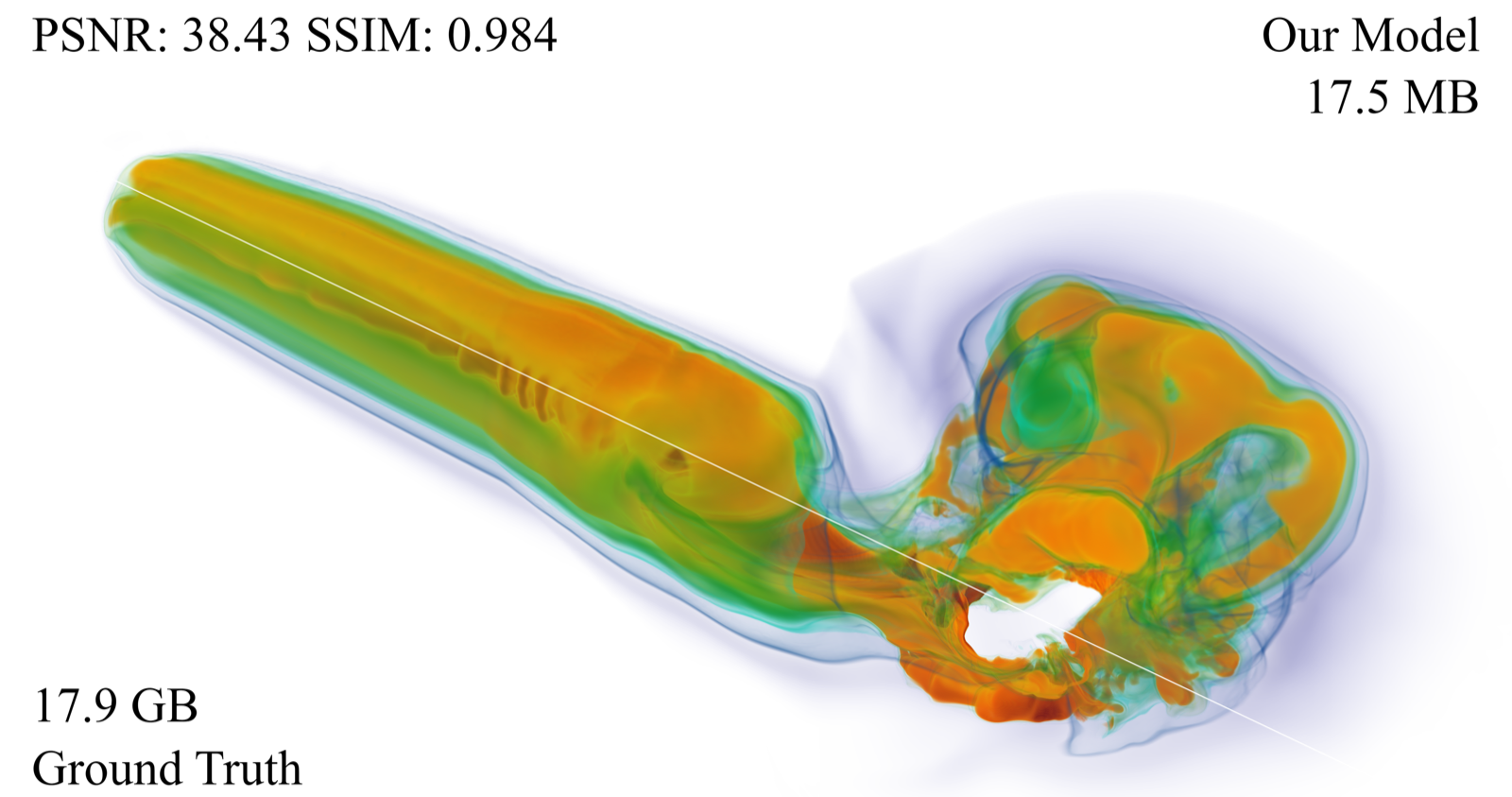
This paper introduces a novel approach to volume data compression using explicit 3D Gaussian primitives, addressing limitations in existing implicit neural representations (INRs) that require partial mesh storage for geometry encoding. By reinterpreting collections of 3D Gaussians as scalar field representations and employing weighted aggregation for spatial value reconstruction, the method achieves significant improvements in both compression efficiency and reconstruction quality.
The key innovation lies in the explicit formulation that naturally encodes domain geometry, thereby eliminating the need for mesh storage in unstructured volumes—a major bottleneck in prior approaches. This not only increases compression opportunities but also enables more efficient training through optimized CUDA-accelerated pipelines and novel sampling-error based densification strategies.
Compared to traditional INRs, this explicit model demonstrates competitive performance on structured volumes with notable training speedups, while markedly outperforming existing methods on unstructured volumes across all evaluated metrics. The approach is particularly relevant for AI agent development where efficient memory usage and fast data processing are critical for real-time applications.
Key insight: Explicit 3D Gaussian representations enable high-efficiency compression of structured and unstructured volumes, outperforming implicit neural representations by eliminating mesh storage requirements and achieving superior reconstruction quality with faster training.
A Lightweight Self-Supervised Learning Framework for Multivariate Time Series using Hierarchical-JEPA on ECG Data
Kim, Siwon arXiv: 2607.01145

This work presents ER-JEPA, a hierarchical joint-embedding predictive architecture designed specifically for multivariate time series analysis in medical domains such as ECG. The framework's two-stage structure processes each time interval before integrating representations into a univariate sequence, enabling deeper abstraction and improved prediction accuracy.
The integration of two JEPAs within a Vision Transformer backbone creates a model capable of encoding multiple levels of abstract representations, which is particularly valuable for complex tasks like cardiac diagnostics. Pretrained on large-scale ECG datasets, the model achieves superior downstream performance on the ST-MEM benchmark while maintaining rapid computation and low resource usage.
This approach directly addresses challenges in medical data analysis where labeled datasets are scarce but unlabeled data is abundant. The lightweight nature of H-JEPA makes it suitable for deployment in real-world clinical settings, offering a scalable solution for self-supervised learning in healthcare applications.
Key insight: Hierarchical JEPA (H-JEPA) enables efficient, lightweight self-supervised learning for multivariate time series like ECG data, achieving state-of-the-art performance with minimal computational resources.
Sequentially-Controlled Interactive Multi-Particle Flow-Maps for Online Feedback-Driven Search
Vorobeychik, Yevgeniy arXiv: 2607.01144

IMPFM addresses a critical limitation in generative models—local exploration within narrow regions of the distribution—by introducing a framework that supports broad exploration necessary for discovering high-utility areas when preferences are unknown. The method uses flow maps to share posterior samples across particles, maximizing sample utility while mitigating reward over-optimization.
The core innovation lies in its sequential correction mechanism, where individual particle drift is corrected using collective posterior samples from the entire ensemble at each resampling step. This approach preserves structural diversity and overcomes weight degeneracy inherent in standard Sequential Monte Carlo samplers, ensuring effective global exploration without mode collapse.
Empirical evaluations across diverse search and alignment tasks demonstrate IMPFM's superiority over existing baselines, making it particularly relevant for AI agent development where adaptive exploration and feedback-driven optimization are essential for learning complex behaviors.
Key insight: Sequentially-Controlled Interactive Multi-Particle Flow-Maps (IMPFM) enable sample-efficient global exploration in feedback-driven search by leveraging collective posterior sampling and multi-particle interaction to avoid reward over-optimization.
GAIA: Geometry-Adaptive Operator Learning for Forward and Inverse Problems
Duraiswami, Ramani arXiv: 2607.01128
GAIA tackles the challenge of operator learning for PDEs on arbitrary geometries by encoding domain boundary and interior field distribution into geometry tokens, which condition integral transform layers via cross-attention. This allows the kernel to adapt locally to geometric features, enabling a single architecture to solve both forward and inverse problems without retraining or iterative optimization.
The model's ability to handle boundary value problems (BVPs) and inverse problems—where inputs and outputs live on different domains—is a major advancement over existing methods. GAIA achieves new state-of-the-art results across seven benchmarks, including electrical impedance tomography and 3D Darcy flow, demonstrating robust performance and generalization capabilities.
This work has significant implications for AI agent development in scientific computing and simulation-based modeling, where accurate and efficient solutions to complex PDEs are crucial. The framework's adaptability and efficiency make it a promising tool for real-time decision-making systems requiring high-fidelity simulations.
Key insight: GAIA introduces a unified operator learning framework that handles both forward and inverse problems on arbitrary geometries, achieving state-of-the-art results with significant improvements in accuracy and generalization.
Calibrating the Instrument: Controllability of an LLM-Driven Synthetic Population
Esposti, Mirko Degli arXiv: 2607.00910

This paper introduces the concept of controllability in generative synthetic populations (GSP), emphasizing that before external validity can be claimed, an instrument must demonstrate internal validity—its ability to respond consistently to known stimuli. The SIVE experiment uses a fictional municipality with 120 personas to test this principle across various institutional communication conditions.
The study reveals how subtle textual elements in messages can be misinterpreted by agents, leading to unexpected behavioral shifts that highlight the importance of careful calibration. This diagnostic success turns a calibration failure into a valuable learning opportunity, demonstrating how synthetic populations can reveal hidden biases and inconsistencies in their own responses.
For AI agent development, this work underscores the need for rigorous validation protocols before deploying synthetic agents in real-world applications. It provides a framework for assessing the reliability and consistency of LLM-driven agents, which is crucial for trustworthiness in institutional communication and urban planning simulations.
Key insight: Controllability of LLM-driven synthetic populations is essential for validating internal consistency and ensuring reproducible responses to stimuli, enabling reliable agent-based modeling in urban simulation and institutional research.
M2Note: Continual Evolution of Vision Language Models via Mistake Notebook Learning
Chu, Xiangxiang arXiv: 2607.00685
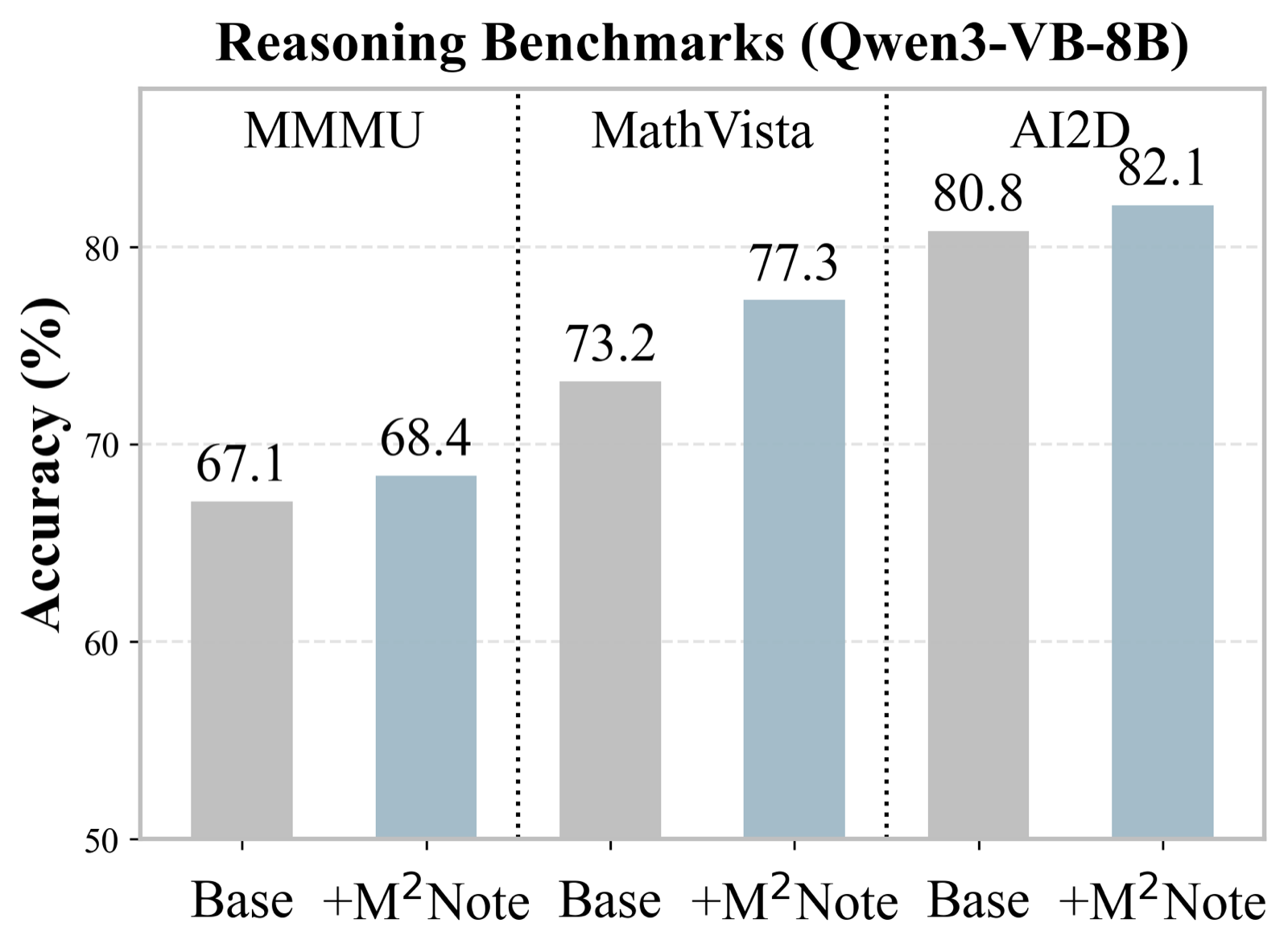
M2Note addresses recurring failures in VLMs such as skipping visual checks and hallucinating unsupported concepts by transforming failed trajectories into compact subject-guidance notes stored in an editable memory. These notes are retrieved via multimodal RAG during inference, providing actionable verification steps that guide reasoning away from past mistakes.
The framework supports both self-evolving and cross-model evolving modes, allowing capability transfer without weight updates. A key innovation is the batch-level post-verification with rollback, which commits notebook edits only if they improve performance on the same batch, reducing noisy updates and preventing regressions.
This approach offers a training-free method for continual learning that is both cost-effective and sample-efficient, making it highly relevant for AI agent development where iterative fine-tuning is expensive or impractical. The ability to externalize learning into an editable memory also supports explainability and interpretability in multimodal reasoning systems.
Key insight: M2Note enables continual evolution of Vision Language Models through externalized learning in an editable memory, improving multimodal reasoning by steering away from previously observed pitfalls without requiring weight updates.
From Real-Time Planning to Reliable Execution:Scalable Coordination for Heterogeneous Multi-Robot Fleets in Industrial Environments
Wang, Hesheng arXiv: 2607.00591

This paper presents SCALE, a reactive online coordination framework designed to address the challenges of real-time path planning in dense industrial environments with heterogeneous robot fleets. The framework introduces a motion-induced conflict reduction mechanism that supports online generation of feasible paths for conflict resolution.
To mitigate the effects of disturbances such as communication delays and execution uncertainties, SCALE employs a generalized Conjugate Action-Precedence Hypergraph (CAPH) that adaptively adjusts precedence relations among robots. This adaptive adjustment helps prevent congestion propagation and ensures robust execution even under adverse conditions.
The framework's scalability and robustness make it particularly valuable for AI agent development in robotics, where reliable coordination is essential for complex multi-agent systems operating in real-world industrial settings. The extensive validation experiments and real-world deployment demonstrate its practical applicability and effectiveness.
Key insight: SCALE provides a reactive online coordination framework for heterogeneous multi-robot fleets that maintains robust execution despite communication delays and disturbances through motion-induced conflict reduction and adaptive precedence relations.
Agri-SAGE: Simulation-Grounded Multi-Agent LLM for Context-Aware Agricultural Advisory Generation
Narahari, Y. arXiv: 2607.00454
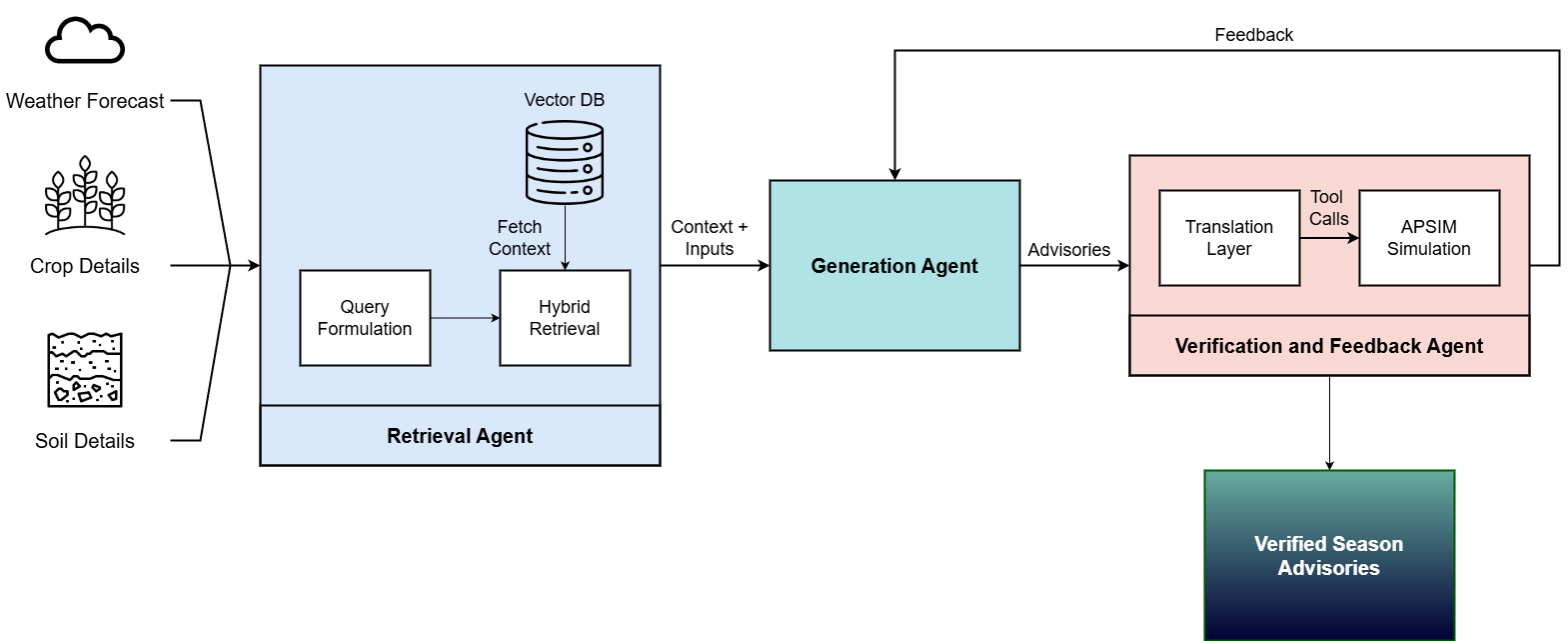
Agri-SAGE represents a closed-loop framework that combines retrieval-grounded multi-agent LLM reasoning with APSIM-based biophysical simulation to address the limitations of static agronomic guidelines and LLM-generated recommendations that may be credible but physiologically unconvincing. The system evaluates three reasoning approaches—Plan-and-Solve, Tree of Thoughts, and Reflexion—across a 10-year retrospective analysis.
The framework demonstrates significant improvements over static PoP baselines, with Tree of Thoughts achieving impressive peak yields and Reflexion offering comparable agronomic outcomes at substantially lower computational cost by leveraging cross-seasonal episodic memory. This balance between performance and efficiency is crucial for practical deployment in agricultural advisory systems.
This work contributes to AI agent development by showcasing how simulation-grounded reasoning can enhance decision-making in complex, dynamic environments. The integration of multi-agent LLMs with biophysical models provides a robust foundation for context-aware advisory generation that adapts to real-world variability and uncertainty.
Key insight: Agri-SAGE integrates retrieval-grounded multi-agent LLM reasoning with biophysical simulation to generate and validate agronomic advisories, significantly outperforming static baselines while leveraging cross-seasonal episodic memory for efficiency.
ASPIRE: Agentic /Skills Discovery for Robotics
Wang, Guanzhi arXiv: 2607.00272

ASPIRE introduces a continual learning system for robotics that autonomously discovers and refines control programs using a code-as-policy paradigm. The framework operates in an open-ended loop with three components: a closed-loop robot execution engine, a continually expanding skill library, and evolutionary search that generates diverse task sequences to explore beyond single-trajectory refinement.
The system's ability to discover skills that persist across tasks, simulation, and real-world settings makes it highly valuable for AI agent development in robotics. ASPIRE surpasses prior methods by up to 77% on LIBERO-Pro manipulation under perturbation and achieves zero-shot generalization to unseen long-horizon tasks, demonstrating robustness and adaptability.
The framework's success in sim-to-real transfer significantly reduces real-robot programming effort, making it a promising approach for scalable robotics applications. This work highlights the potential of agentic skill discovery in creating more autonomous and adaptable robotic systems capable of learning from experience.
Key insight: ASPIRE enables autonomous discovery and refinement of robot control programs through a closed-loop execution engine, skill library, and evolutionary search, achieving state-of-the-art performance in manipulation and household tasks.
From Signals to Structure: How Memory Architecture Drives Language Emergence in LLM Agents
Zaiane, Osmar R. arXiv: 2607.00233
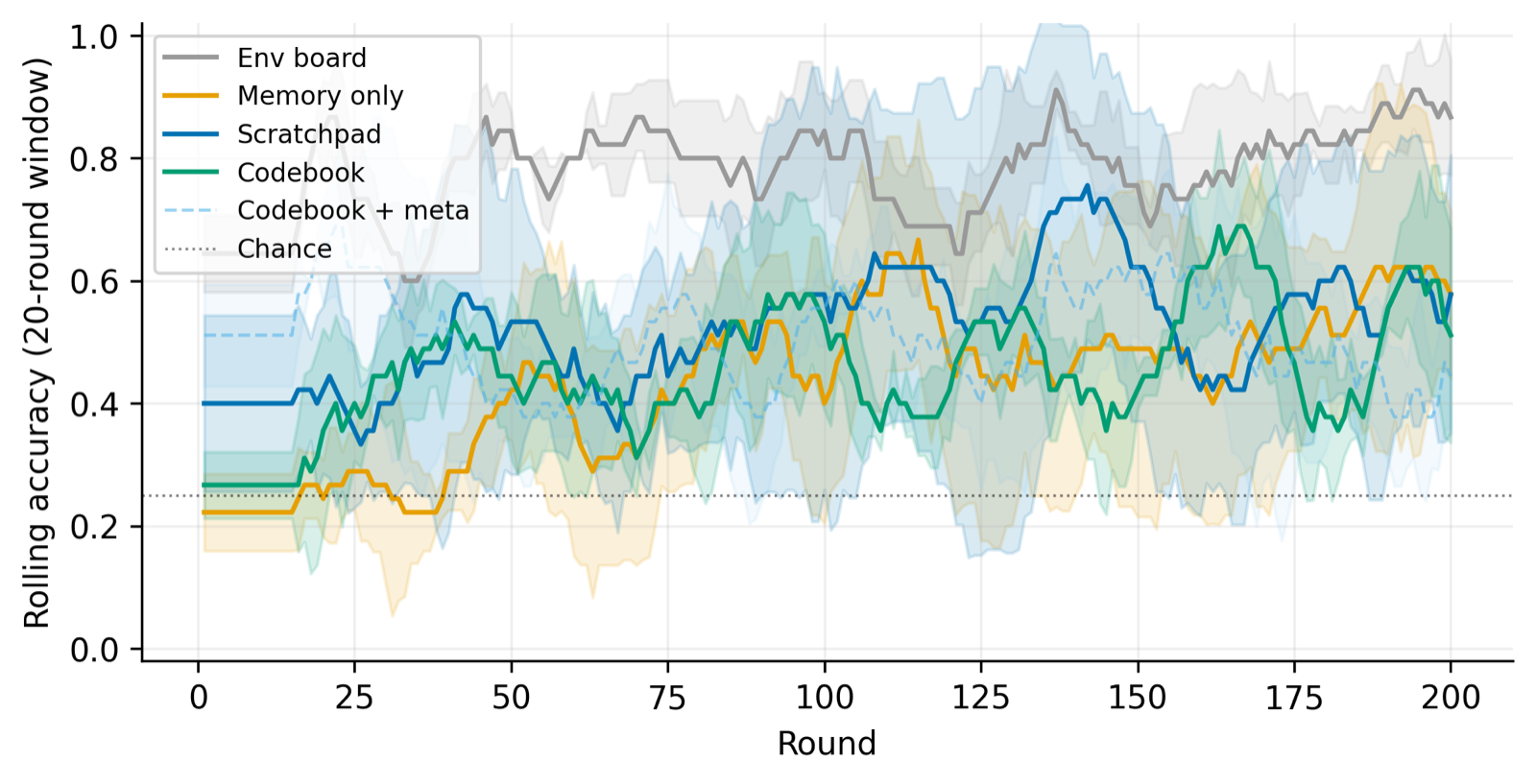
This study investigates how memory architecture affects language emergence in LLM agents through a Lewis signaling game, revealing that memory architecture matters more than channel capacity. Agents with persistent private notebooks benefit from surplus channel capacity and avoid the high-capacity collapse seen in stateless agents, achieving more reliable coordination.
The research demonstrates that externalizing learned conventions into notebooks frees agents from re-deriving codes each round, leading to stable conventions and better performance. An information bottleneck-inspired argument predicts an optimal capacity equal to the number of objects, but the findings show that surplus capacity is generally better than the bottleneck point.
These insights are crucial for AI agent development, particularly in multi-agent systems where communication and coordination are fundamental. Understanding how memory architecture drives language emergence provides a foundation for designing more effective and interpretable multi-agent communication protocols.
Key insight: Memory architecture significantly influences language emergence in LLM agents, with persistent private notebooks enabling more reliable coordination than stateless agents by externalizing learned conventions and avoiding vocabulary collapse.
HydraCollab: Adaptive Collaborative-Perception for Distributed Autonomous Systems
Faruque, Mohammad Abdullah Al arXiv: 2607.00191
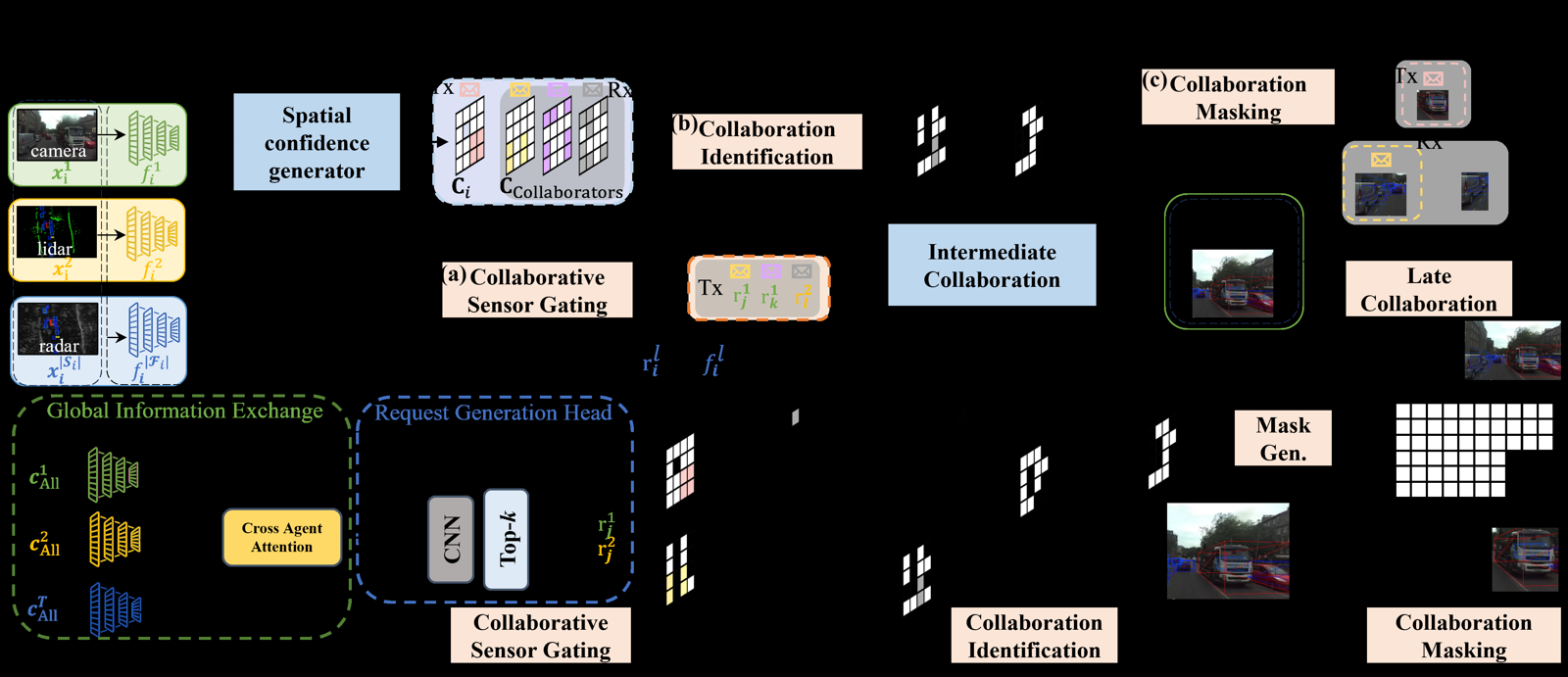
In the context of multi-agent systems and distributed autonomous robotics, HydraCollab addresses a critical challenge: balancing communication efficiency with perceptual accuracy. This is particularly relevant for AI agents operating in resource-constrained environments where bandwidth limitations can severely impact performance. By selectively transmitting only the most informative sensor features and dynamically choosing between intermediate and late collaboration strategies, HydraCollab demonstrates how adaptive frameworks can optimize agent coordination without sacrificing situational awareness.
The framework's reliance on spatial confidence maps to make real-time decisions about information sharing is a significant advancement in agent architecture design. It reflects a shift from static, pre-defined communication protocols toward dynamic, context-aware systems that can adjust their behavior based on environmental conditions. This approach aligns with broader trends in AI agent development where adaptability and efficiency are paramount, especially in scenarios involving heterogeneous sensor arrays and distributed decision-making.
The empirical validation using datasets like V2X-R and UAV3D-mini provides strong evidence for HydraCollab's effectiveness across diverse real-world applications. The 41-26% bandwidth reduction while maintaining or improving performance is particularly compelling for practical deployment, suggesting that such methods could be scaled to large-scale multi-agent systems where communication overhead becomes a bottleneck. This work contributes directly to the memory and tool use domains by introducing efficient information exchange mechanisms that reduce data load without compromising agent intelligence.
Key insight: HydraCollab introduces an adaptive collaborative-perception framework that dynamically selects sensor features and collaboration strategies based on spatial confidence maps, achieving a 41-26% reduction in communication bandwidth while improving perception accuracy by 0.78-0.75% compared to state-of-the-art methods.
Active Sensing for RIS-Aided Tracking and Power Control: A Hybrid Neuroevolution and Supervised Learning Approach
Alexandropoulos, George C. arXiv: 2607.00056
This paper presents a novel dual-agent deep learning framework for active sensing in RIS-aided wireless communication systems, which is highly relevant to AI agent architectures that must operate under strict resource constraints. The integration of neuroevolution with supervised learning offers a promising solution to the non-differentiability problem inherent in discrete RIS phase responses—a challenge that often plagues reinforcement learning approaches in hardware-constrained environments.
The application of this framework extends beyond traditional tracking tasks into areas such as reasoning and planning, particularly in dynamic environments where agents must make real-time decisions based on limited feedback. The ability to handle both single- and multi-antenna base stations with minimal structural modifications suggests scalability and adaptability that are crucial for future AI agent systems aiming to integrate seamlessly with complex communication infrastructures.
The superior performance over extended Kalman filters, particle filters, and other machine learning-based trackers highlights the potential of hybrid training methodologies in enhancing agent decision-making capabilities. This work contributes significantly to LLM efficiency and RAG (Retrieval-Augmented Generation) by offering a new paradigm for optimizing information flow in communication systems, which can be leveraged to improve retrieval accuracy and reduce latency—key factors in real-time AI agent operations.
Key insight: A hybrid neuroevolution and supervised learning approach enables real-time joint optimization of RIS phase profiles and UE transmit power, overcoming non-differentiability issues in discrete systems and achieving superior tracking accuracy over traditional methods like Kalman filters and deep reinforcement learning baselines.
AI Model Releases

Boost Performance And Lower Costs With Alloydb AI Functions

Enterprise deployments | Mistral AI
Agent Frameworks & SDKs

SkillOpt: Agent skills as trainable parameters - Microsoft Research
Microsoft Research introduced SkillOpt, a framework that treats agent skills as trainable parameters rather than manually edited instructions. The system turns skill editing into a training process, making agent behavior more reliable without changing model weights. Across six benchmarks, seven target models, and three execution modes, SkillOpt outperformed or tied the best methods in all 52 evaluation cells. The approach keeps skills compact and auditable through bounded text edits, validation gating, and slow/meta updates to avoid uncontrolled prompt drift. Optimized skills also transfer across model scales, agent harnesses, and related tasks, indicating they capture reusable workflow knowledge.
Why it matters: SkillOpt represents a significant shift toward more reliable and trainable agent behaviors by treating skills as learnable parameters rather than static instructions. This approach could lead to more robust AI agents that adapt effectively without requiring constant manual intervention or model retraining, particularly important for complex multi-step tasks.
AI Tooling

Indian entrepreneur Bhavin Turakhia has invested $30 million of his own money into Neo, an enterprise work platform designed from the ground up for AI integration. The platform combines project management, documents, file storage, and AI into a single product, aiming to make AI an active participant in daily work rather than just a separate assistant. Neo is built to be model-agnostic, allowing enterprises to switch between AI models rather than being tied to a single provider. The company plans to roll out the software to mid-sized businesses in the coming months.
Why it matters: Neo represents a significant new entrant in the enterprise AI workspace market, potentially challenging Microsoft Office and Google Workspace with a platform designed specifically for AI integration from the start. This approach could reshape how businesses think about AI adoption in workplace productivity tools.
UI/UX Tools
Source: figma.com.