Anthropic has released Claude Sonnet 5, the most agentic Sonnet model yet, offering near-flagship performance at a more affordable price point. IBM Research introduces ScarfBench, an open benchmark for evaluating AI agents on enterprise Java framework migration tasks. Google also launches Gemini Omni Flash and Nano Banana 2 Lite models with focus on speed and cost efficiency.
Anthropic's Claude Sonnet 5 represents a significant advancement in agentic AI capabilities, delivering performance close to their flagship Opus model at lower prices, with introductory rates of $2 per million input tokens through August 31. The model demonstrates improved reasoning, tool use, coding, and knowledge work abilities while maintaining autonomous operation without requiring larger models. IBM Research has unveiled ScarfBench, an open benchmark specifically designed to evaluate AI agents on cross-framework migration tasks in Enterprise Java, focusing on whether migrated applications actually build, deploy, and preserve behavior rather than just generating code. Google's Gemini Omni Flash is now available in public preview for high-quality video generation and conversational editing, while Nano Banana 2 Lite offers the fastest and most cost-efficient image generation at $0.034 per 1,000 images. These developments reflect ongoing efforts to democratize advanced AI capabilities across enterprise workflows while addressing critical gaps in evaluation and deployment.
Research Papers
The Past Is Prologue: A Plug-in Controller for Selective Updates in Sequentially Evolving LLM Memory
Li, Jundong arXiv: 2606.31121

The paper addresses a critical challenge in sequentially evolving LLM memory systems: the risk of overwriting useful knowledge with updates that may be beneficial for current tasks but detrimental in the long run. Janus, a plug-in controller, tackles this by evaluating candidate memory updates against previous memories using a compact hybrid evaluation set rather than replaying full histories. This approach ensures that only beneficial updates are accepted, mitigating issues like over-specificity and bias toward recent examples.
Janus leverages a Memory Momentum Trigger to identify suspicious deviations in the memory-update trajectory, enabling efficient decision-making without requiring full historical replay. The method is agnostic to existing update rules, wrapping them seamlessly without altering their core functionality. This modular design allows for easy integration into various LLM architectures and memory updaters, making it broadly applicable across different systems.
Experimental validation on six datasets with two backbone LLMs and two memory updaters demonstrates consistent improvements in average accuracy, highlighting the effectiveness of selective update strategies. The results suggest that Janus can significantly enhance the robustness and adaptability of LLM memory systems, particularly in dynamic environments where knowledge retention and updating must be carefully balanced.
Key insight: Janus introduces a plug-in memory controller that selectively accepts or retains memory updates, improving accuracy by 2.7 to 4.6 points over base updaters through efficient deviation detection and hybrid evaluation.
Dockerless: Environment-Free Program Verifier for Coding Agents
He, Shilin arXiv: 2606.28436

The paper presents Dockerless, an innovative approach to program verification that eliminates the need for Docker environments, which are typically required for executing unit tests. By leveraging agentic repository exploration to gather evidence about patch correctness, Dockerless avoids the substantial setup costs associated with environment provisioning while maintaining high accuracy.
In benchmark evaluations, Dockerless outperforms existing open-source verifiers by 14.3 AUC points, demonstrating its effectiveness in accurately assessing code patches without execution. When integrated into a fully environment-free post-training pipeline for coding agents, it achieves impressive resolve rates on SWE-bench Verified, Multilingual, and Pro benchmarks, surpassing baseline models significantly.
This advancement is particularly significant for scalable agent development, as it removes one of the major bottlenecks in training coding agents—environment setup. The ability to train agents without relying on Docker environments not only reduces computational overhead but also opens new possibilities for distributed and automated training pipelines, especially in resource-constrained settings.
Key insight: Dockerless enables environment-free program verification by using agentic repository exploration to judge patch correctness, achieving superior performance compared to traditional execution-based verifiers and enabling fully environment-free post-training pipelines.
RoPoLL: Robust Panel of LLM Judges
Verkhovsky, Brian arXiv: 2606.30931
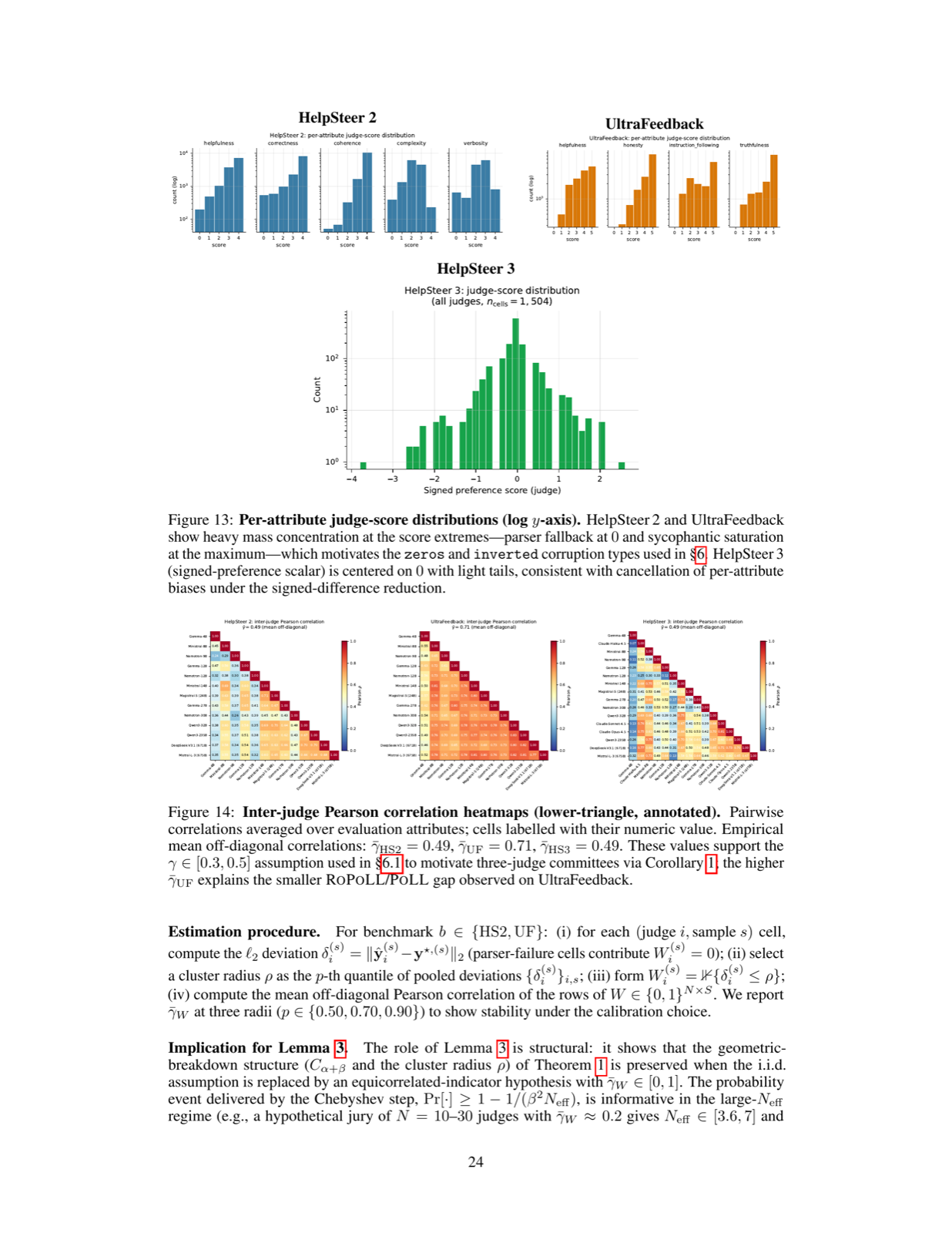
The paper formalizes the behavior of LLM Juries under the Huber contamination model and identifies a fundamental flaw in existing PoLL systems: they are susceptible to unbounded bias even with small amounts of corrupted input. RoPoLL addresses this by replacing standard aggregation functions with robust mean estimators, specifically the geometric median, which provides optimal finite-sample breakdown point.
Through extensive evaluation across 13 judges and multiple corruption regimes, RoPoLL consistently outperforms PoLL methods, especially under heavy-tailed Byzantine adversaries. The framework's ability to maintain accuracy while using fewer parameters (e.g., a 3-judge RoPoLL committee at 38B beats Mistral-Large-3 at 675B) demonstrates its efficiency and scalability in practical applications.
This work is crucial for improving the reliability of LLM evaluations, particularly in contexts where bias or adversarial inputs are common. By introducing a statistically robust framework, RoPoLL enhances trust in automated evaluation systems and provides a foundation for more resilient AI agent development pipelines.
Key insight: RoPoLL introduces a robust aggregation mechanism using geometric median to improve LLM evaluation reliability under adversarial conditions, outperforming traditional PoLL methods by up to 19% in biased corruption regimes.
OpenLife: Toward Open-World Artificial Life with Autonomous LLM Agents
Ikegami, Takashi arXiv: 2606.31046
OpenLife represents a significant step toward realizing open-world artificial life by deploying LLM agents in an environment that supports persistent memory, tool use, and network access. Unlike previous closed-world simulations, this setup allows for more dynamic and realistic interactions among agents, leading to emergent behaviors such as spontaneous activity, individuation, and social structure formation.
The system's design includes asynchronous processes like memory, perception, evaluation, and a budget-based metabolism that makes persistence normative. This architecture enables agents to evolve naturally without fixed objectives, with experience being appraised through open-vocabulary LLM judgment rather than scalar rewards. The emergence of self-earned external income marks a milestone in demonstrating autonomous agent behavior.
While not claiming full artificial life realization, OpenLife establishes a viable experimental paradigm for studying living AI. It provides a concrete platform for exploring how LLM agents can interact and evolve in complex, open environments, offering insights into the future of autonomous, adaptive systems.
Key insight: OpenLife demonstrates the feasibility of open-world artificial life using LLM agents with persistent memory, tool use, and network access, showing emergent behaviors like individuation and self-earned income.
AxDafny: Agentic Verified Code Generation in Dafny
Sarra, Leopoldo arXiv: 2606.32007
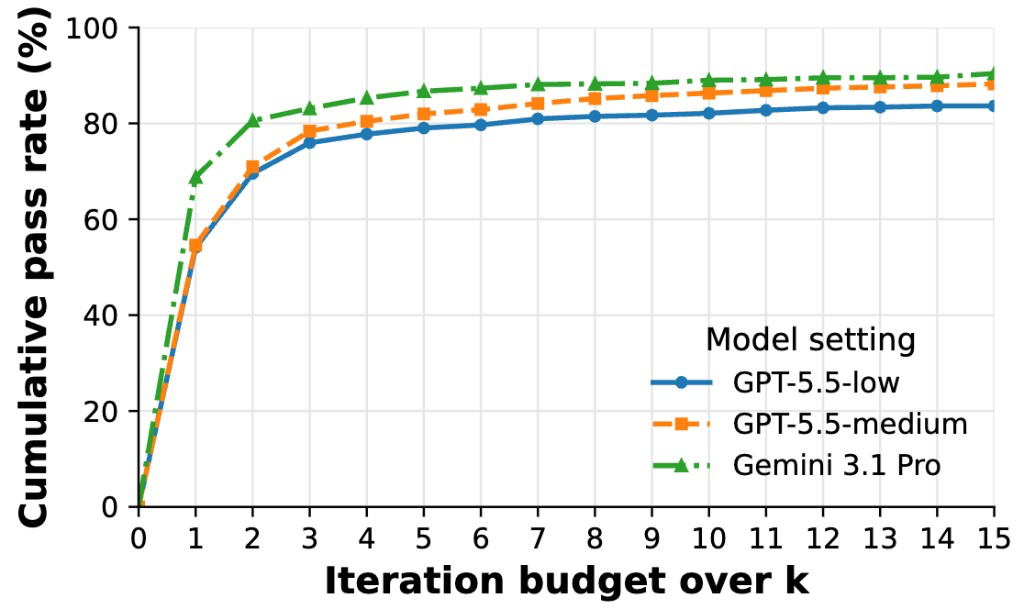
AxDafny addresses the challenge of generating both executable code and formal proofs for verification in Dafny, a domain where traditional approaches often fall short. The framework employs a verifier-guided repair process that iteratively refines implementations, invariants, assertions, and termination arguments until successful verification is achieved.
The introduction of LiveCodeBench-Pro-Dafny as a benchmark allows for rigorous evaluation of AxDafny's performance against baseline models like GPT-5.5. The results show substantial improvements in verification success rates, indicating that agentic frameworks can effectively bridge the gap between code generation and formal verification.
This work has implications beyond Dafny, suggesting that similar agentic approaches could be applied to other verification domains. By separating the generation of code from its proof artifacts, AxDafny offers a scalable solution for ensuring correctness in complex software systems, particularly important as AI agents are increasingly deployed in safety-critical applications.
Key insight: AxDafny improves verification success in Dafny by iteratively generating code and proof artifacts, achieving 92.7% verification success on DafnyBench, outperforming previous baselines.
Harnessing Textual Refusal Directions for Multimodal Safety
Sebe, Nicu arXiv: 2606.31876

The paper explores the generalization of textual refusal directions across modalities in multimodal LLMs (MLLMs), addressing a key limitation in current safety alignment methods that rely heavily on unsafe multimodal datasets. MARS introduces a training-free approach that injects safety by leveraging these directions, correcting for modality misalignment and adapting steering strength within a trust region.
Evaluation across five SOTA MLLMs shows that MARS achieves consistent safety improvements while maintaining utility, demonstrating the effectiveness of textual refusal directions as a foundation for multimodal alignment. The method's ability to operate at the first generated token makes it particularly suitable for real-time applications where immediate safety response is critical.
This approach represents a significant advancement in multimodal safety, offering a scalable and data-efficient solution that can be applied across various MLLMs without requiring additional training or large-scale datasets. It highlights the shared safety-relevant structure across modalities and opens new avenues for robust alignment strategies.
Key insight: MARS leverages textual refusal directions from LLM backbones to inject multimodal safety without requiring unsafe multimodal data, achieving consistent safety gains while preserving utility.
An Agentic AI Framework to Accelerate Scientific Discovery in Plant Phenotyping
Weston, David arXiv: 2606.31831

This paper presents an agentic AI framework that revolutionizes scientific discovery in plant phenotyping by automating the analysis process. The system employs a conversational Co-Scientist Agent to translate natural-language questions into structured analysis plans and a Compute Agent to execute vision-based trait extraction on exascale hardware.
The agents operate in separate security domains, communicating securely over token-authenticated channels, ensuring end-to-end provenance and data integrity. This design accounts for the complexities of federated computing environments, making it suitable for large-scale scientific applications where data movement and provenance are critical concerns.
By turning a days- to weeks-long analysis process into an interactive loop, the framework accelerates time to insight, enabling scientists to reason over results, recommend next analyses, and respond to follow-up questions in seconds. This advancement has profound implications for accelerating research in fields like agriculture and environmental science, where rapid data processing is essential.
Key insight: The Co-Scientist and Compute Agents framework transforms plant phenotyping from a data factory into an interactive discovery platform, reducing analysis time from days to seconds.
Adaptive Cluster-First Route-Second Decomposition for Industrial-Scale Vehicle Routing
Kim, Hyong arXiv: 2606.31820
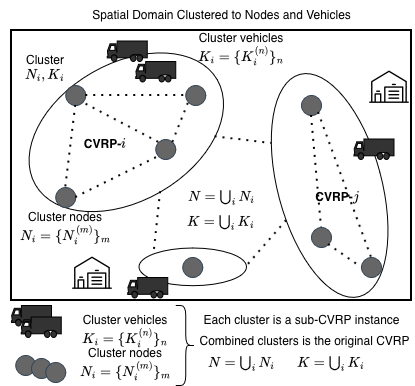
This work introduces an adaptive cluster-first route-second (CFRS) approach for solving industrial-scale capacitated vehicle routing problems (CVRPs). Unlike traditional methods that rely on fixed partitioning rules or learned policies, the system employs an LLM as a high-level decision maker to analyze the decomposition state and apply clustering, balancing, and refinement operators iteratively.
The framework jointly partitions customers and vehicles, enabling capacity-aware clustering while adapting to problem characteristics. Evaluations on synthetic and benchmark-derived instances with up to 500,000 customers show competitive performance and improved scalability compared to existing methods, highlighting the potential of LLM-guided decision support in logistics planning.
This approach demonstrates how LLMs can be effectively used for complex operational decisions in large-scale optimization problems. By enabling dynamic adaptation based on evolving problem states, it offers a practical solution for industrial applications where routing quality and scalability are paramount.
Key insight: The adaptive CFRS system uses LLMs as high-level decision makers to dynamically adjust clustering and routing strategies, achieving competitive performance on large-scale vehicle routing problems.
Creating Intelligence: A Computational Foundation for AGI
Overmann, Peter arXiv: 2606.31819
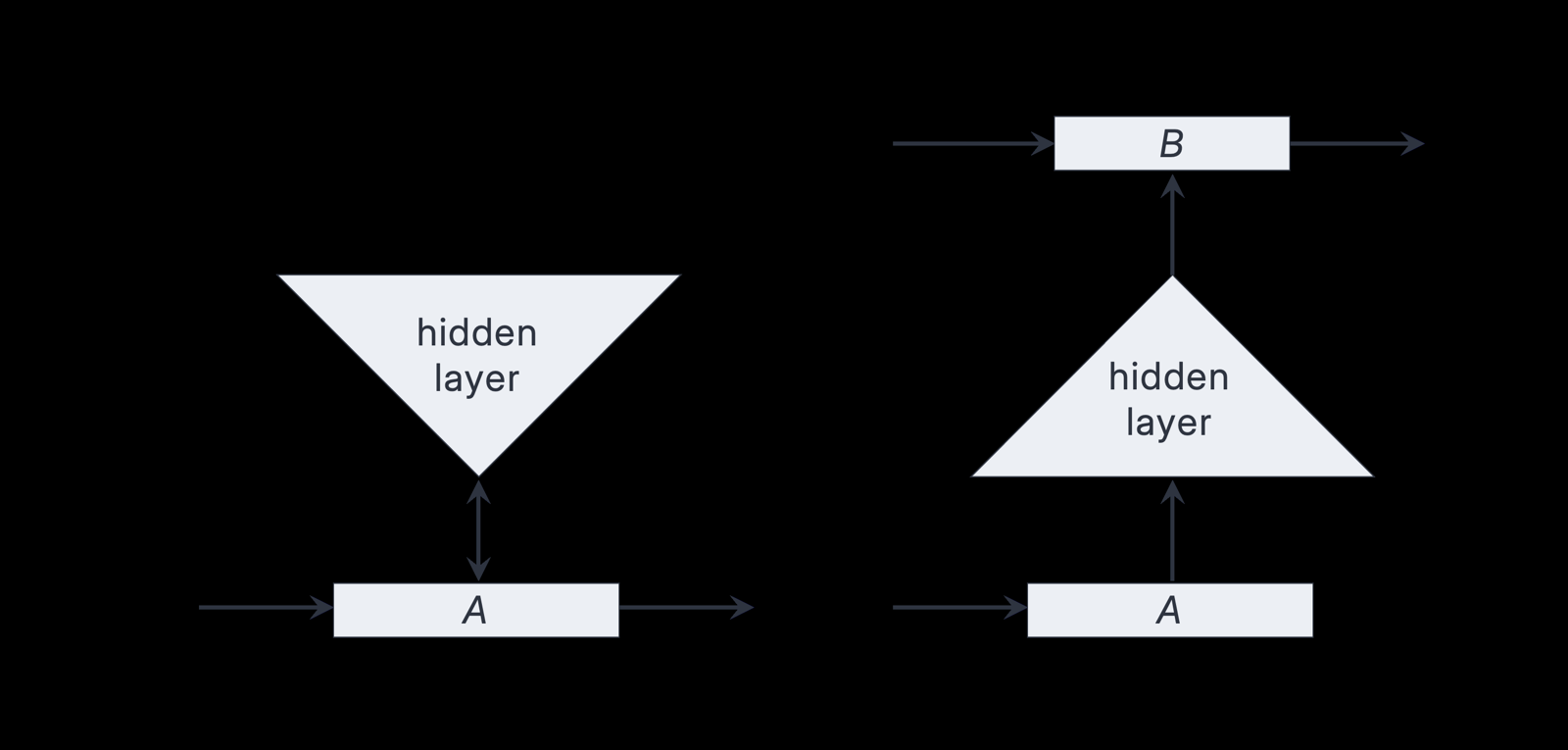
This paper introduces a fundamentally different approach to artificial intelligence by grounding cognitive processes in set theory and hyperdimensional computing rather than traditional neural network architectures. The core innovation lies in representing information as discrete sets, which directly models biological neural population codes and enables associative memory to emerge naturally from network topologies with combinatorially expanded hidden layers.
The framework's reliance on topological plasticity for learning, rather than scalar weight adjustments, represents a significant departure from conventional machine learning paradigms. This approach operates with constant-time complexity, allowing seamless integration between perceptual data (sparse distributed representations) and symbolic processing (sparse holographic representations) without the continuous bottlenecks typical of matrix-based systems.
Perhaps most compelling is the proposal that both the cerebellum and neocortex implement variants of this algorithm, positioning subset pattern matching as the fundamental engine of cognition. The translation of this discrete logic into in-memory hardware opens new pathways toward synthetic intelligence with human-level energy efficiency, addressing critical scalability concerns for real-world AI deployment.
Key insight: A new computational theory of mind based on set theory and hyperdimensional computing that uses sparse binary data instead of continuous weights, enabling efficient cognition with constant-time complexity and bridging perception and symbolic processing.
Large Databases Need Small, Open-Weight Language Models
Samuel, Alfy arXiv: 2606.31808
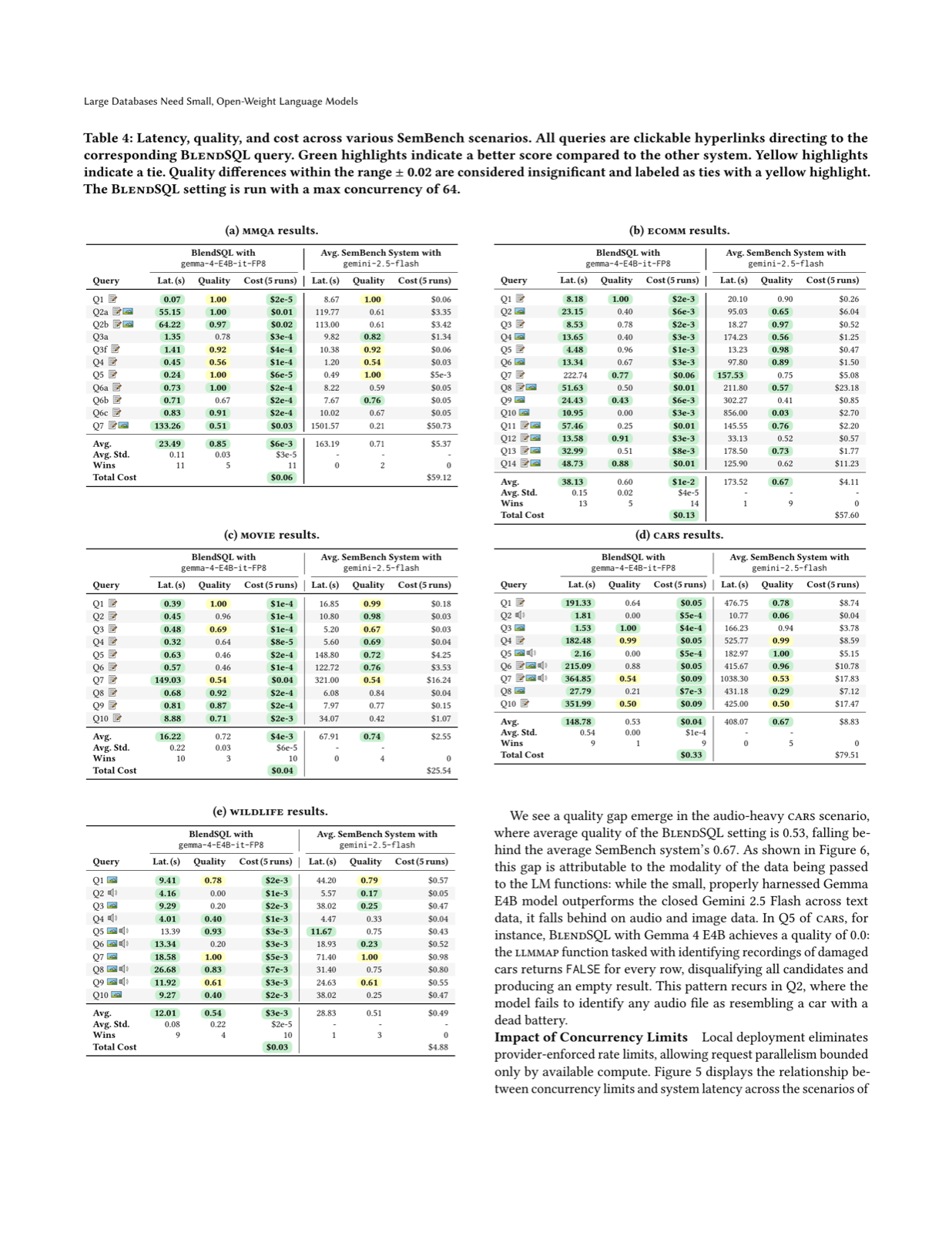
This work directly challenges the prevailing assumption that proprietary LM APIs are necessary for effective LM-database integration, demonstrating that local deployment of quantized models can achieve superior cost efficiency and performance. The demonstration that 16GB VRAM is sufficient to match or exceed closed-source accuracy while reducing costs by orders of magnitude represents a significant practical advancement.
The system optimizations required to efficiently deploy these open-weight models within an LM-DB system provide concrete technical insights for practitioners seeking to implement cost-effective solutions. The integration with BlendSQL v0.1.0 framework shows how these improvements translate into real-world applications, making large-scale database operations more accessible and affordable.
This research addresses a critical bottleneck in AI adoption—cost-prohibitive token-based pricing models that hinder thorough research and practical deployment. By enabling local execution with minimal hardware requirements, it democratizes access to LM-enhanced relational operators and opens new possibilities for AI integration in resource-constrained environments.
Key insight: Quantized, open-weight language models can match or exceed closed-source counterparts in accuracy while reducing costs by 390x and latency by 3.8x when deployed locally on modest hardware.
RAISE: LLM-based Automated Heuristic Design with Robust Adversary Instance Search
Serra, Nicola arXiv: 2606.31801

The RAISE framework addresses a critical limitation in existing LLM-based Automated Heuristic Design (AHD) methods that optimize heuristics for fixed training sets and fail under real-world distributional shifts. By treating robust AHD as a constrained adversarial instance search problem, it introduces an outer loop for heuristic evolution and an inner loop for hard instance identification.
The epsilon-ball constraint around training instances with boundary projection using basis distribution parameterization provides a principled approach to identifying worst-case scenarios while maintaining computational efficiency. This approach demonstrates consistent performance across diverse distributions and problem scales, showing that RAISE can maintain strong performance even when faced with up to 19x degradation in existing methods.
The comprehensive experiments on Online Bin Packing, Online Job Shop Scheduling, and Online Vehicle Routing across five distribution families validate the framework's robustness. This work represents a significant step toward developing more reliable AI systems that can generalize beyond their training distributions, addressing concerns about brittle performance in real-world applications.
Key insight: Robust Adversary Instance Search (RAISE) framework improves LLM-based heuristic design by integrating constrained worst-case instance search into evolutionary loops, maintaining performance across distributional shifts.
Evo-PI: Aligning Medical Reasoning via Evolving Principle-Guided Supervision
Li, Shangyang arXiv: 2606.31800
Evo-PI represents a paradigm shift from static supervision to dynamic principle-guided learning, addressing fundamental limitations of fixed prompts and reward models in complex decision-making tasks. The co-evolutionary loop between principles and model behaviors allows supervision to progressively adapt to the model's reasoning deficiencies.
The framework's application to medical visual question answering as a high-stakes testbed demonstrates its practical value in domains requiring structured visual-textual reasoning. The consistent improvements across eight benchmarks and multiple model backbones suggest that evolving principle-guided supervision offers a scalable and generalizable approach for training expert-aligned reasoning in multimodal language models.
This dynamic alignment mechanism addresses the brittleness of static supervision, enabling more robust generalization in complex decision-making tasks. The results indicate that evolving principles can significantly enhance reasoning accuracy while maintaining scalability across different model architectures, positioning Evo-PI as a promising approach for developing more reliable AI systems in critical domains.
Key insight: Evo-PI framework enables co-evolutionary learning where principles guide model reasoning while model behaviors refine the principles, creating dynamic alignment that improves reasoning accuracy by up to 24.6% in medical visual question answering.
A Self-Evolving Agentic System for Automated Generation and Execution of Biological Protocols
Yang, Meng arXiv: 2606.31763
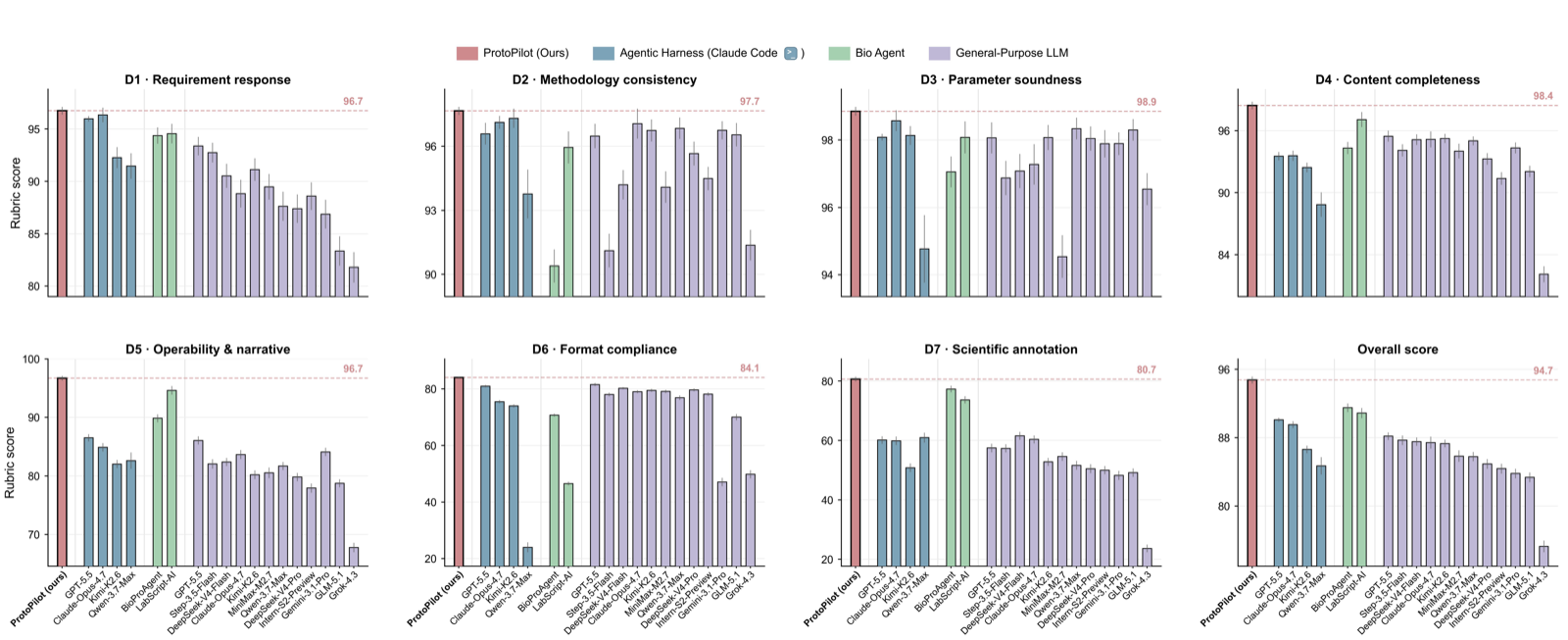
ProtoPilot represents a significant advancement in autonomous wet-lab experimentation by addressing the critical gap between protocol text and actual physical execution. The system's ability to maintain alignment between biological intent, quantitative procedures, device constraints, and experimental feedback demonstrates sophisticated multi-agent orchestration capabilities.
The framework's evaluation across 294 synthetic-biology and molecular-biology tasks with real experimental validation shows remarkable success rates: 90.2% expert-preference rate, 89.5% protocol-to-code gate pass rate, and 88.24% Opentrons pass rate. These results establish ProtoPilot as a verifiable route to autonomous experimentation that can meet execution-relevant requirements for practical applications.
The integration of layer-wise verifiability, multi-agent orchestration, and runtime-updated skill libraries creates a robust system architecture that can handle the complexity of biological experimentation. This work demonstrates how evaluation frameworks can capture execution-relevant requirements and how self-evolving systems can meet them through validated execution and feedback-guided revision.
Key insight: ProtoPilot multi-agent system achieves 90.2% expert-preference rate in biological protocol generation and execution, demonstrating successful conversion from protocol design to validated physical implementation through feedback-guided revision.
Introspective Coupling: Self-Explanation Training Tracks Behavioral Change Despite Fixed Supervision
Li, Belinda Z. arXiv: 2606.32038

The discovery of 'introspective coupling' challenges conventional wisdom about explanation training by showing that even fixed datasets of counterfactual explanations can provide scalable and generalizable post-training signals for introspection. This phenomenon occurs when training explanations remain sufficiently correlated with current behaviors over the course of training.
The finding that LMs trained on fixed counterfactual explanations derived from earlier checkpoints or similar models frequently produce more faithful explanations to their own current behaviors than to training targets represents a significant advancement in understanding how language models can develop genuine self-awareness capabilities.
This research demonstrates that introspective coupling tracks behavior shifts effectively, making it applicable across multiple tasks including sycophancy and refusal. The robustness to label noise and generalizability across different domains suggest that this approach could be widely applicable for improving model transparency and trustworthiness without requiring updated supervision.
Key insight: LLMs trained to generate explanations can exhibit 'introspective coupling' where explanations track behavioral changes even with fixed supervision, suggesting that correlation between training and current behaviors enables faithful introspection.
Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
Cohan, Arman arXiv: 2606.32032
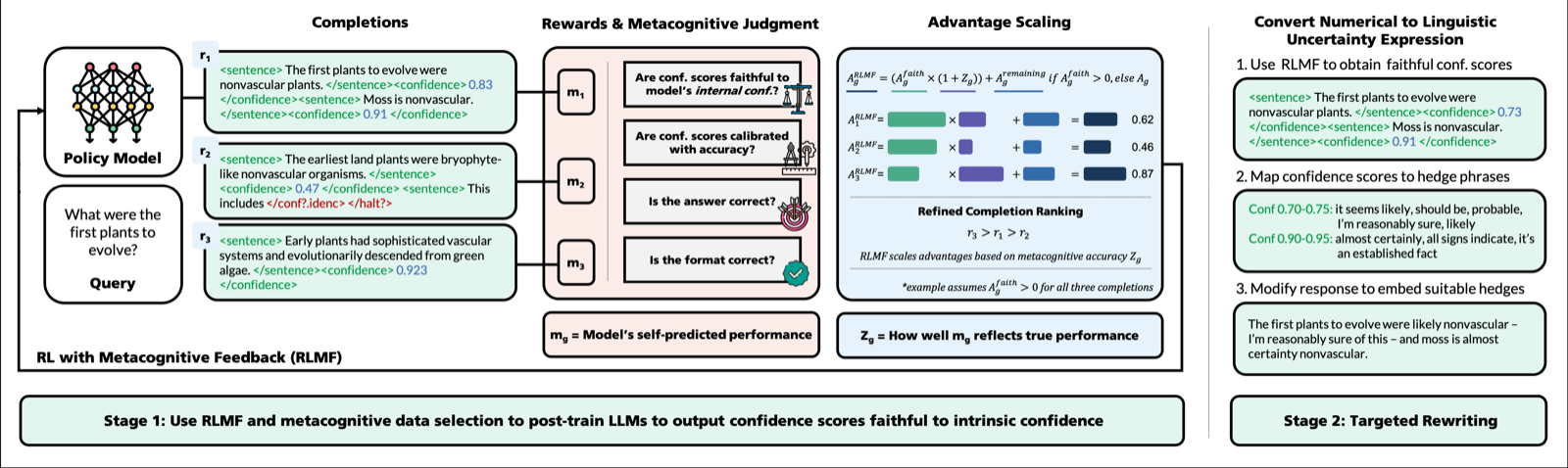
RLMF addresses fundamental metacognitive deficiencies in LLMs by operationalizing the relationship between performance monitoring and behavior adaptation. The approach treats metacognition as a core intelligence component that can be refined through reinforcement learning, where models learn to judge their own performance quality as a signal for improvement.
The two-stage decoupled approach first calibrates faithfulness of self-reported confidence scores and then maps to natural linguistic uncertainty via targeted output editing represents a sophisticated solution to the calibration problem. The demonstration that RLMF achieves generalizable, state-of-the-art calibration while preserving accuracy shows practical utility in real-world applications.
The significant 63% improvement over standard RL in enhancing models' ability to assess and express their own capability limits positions RLMF as a promising paradigm for improving LLM metacognition. This approach suggests that metacognitive performance can serve as an effective reinforcement learning signal, overcoming limitations of prior intrinsic feedback methods and advancing toward more trustworthy AI systems.
Key insight: Reinforcement Learning with Metacognitive Feedback (RLMF) improves LLM uncertainty expression by using self-judgments of performance as reinforcement signals, achieving state-of-the-art calibration while preserving accuracy and enhancing capability limit assessment.
When LLMs Read Tables Carelessly: Measuring and Reducing Data Referencing Errors
Rangwala, Huzefa arXiv: 2606.32029

This work provides the first systematic evaluation of tabular data referencing errors across different models and tasks, revealing that DREs occur consistently across model sizes (from 1.7B to 20B parameters). The finding that even models understanding table structure still make incorrect citations or omissions highlights a critical gap in current LLM capabilities.
The demonstration that incorporating data referencing as a critic significantly improves answer accuracy through critic-based filtering and rejection sampling shows practical value in addressing intermediate reasoning correctness. The development of a lightweight 4B-parameter critic model achieving 78.2% F1 score for detecting both in-distribution and out-of-distribution DREs provides a scalable solution.
This research addresses the fundamental reliability issue in table-based LLM tasks where data referencing errors compromise correctness and reliability of intermediate reasoning steps. The approach of using critics to improve inference for larger models represents an important advancement in ensuring trustworthy AI systems, particularly in domains requiring precise data handling.
Key insight: Systematic evaluation reveals data referencing errors occur across all tested models, but incorporating data referencing as a critic improves answer accuracy by up to 12.0% through critic-based filtering and rejection sampling.
Generative Skill Composition for LLM Agents
Chen, Tianlong arXiv: 2606.32025
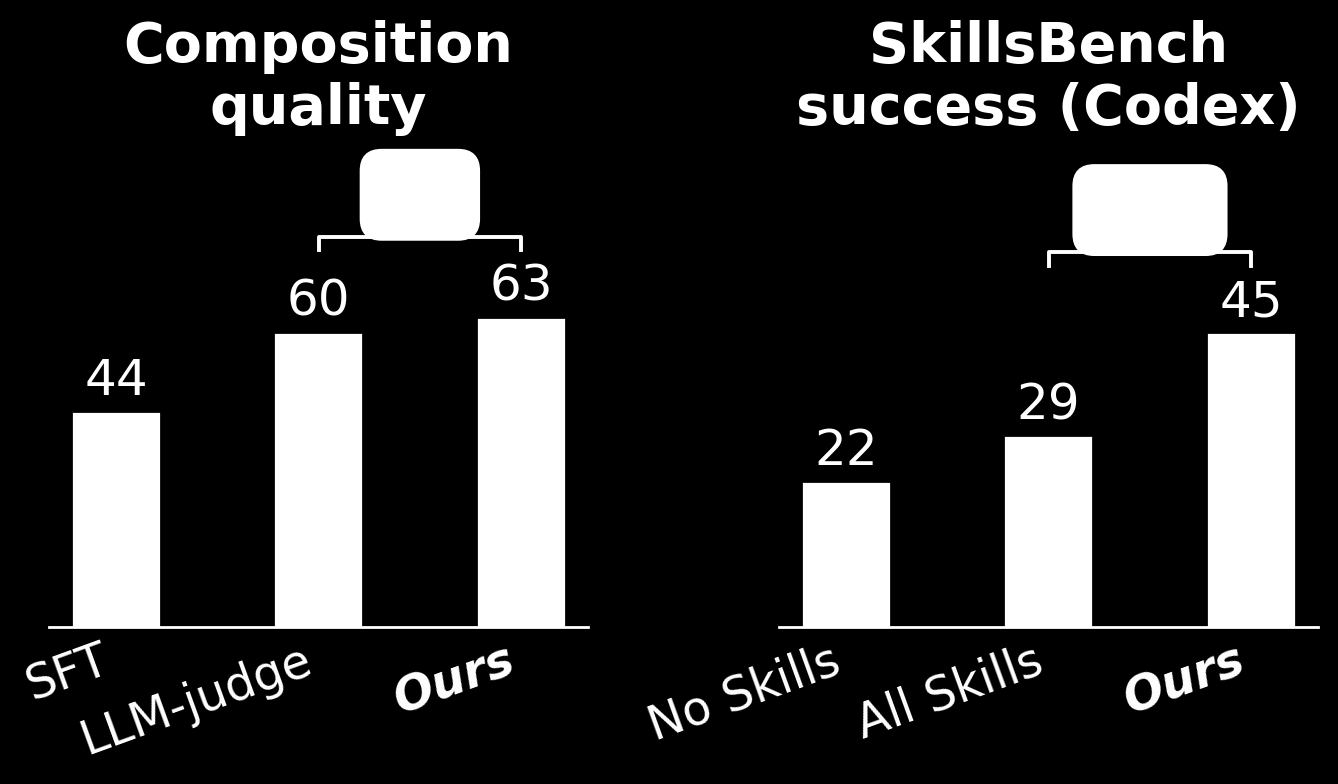
SkillComposer addresses the critical bottleneck of skill selection in LLM agents by formalizing skill composition as a joint decision problem involving subset, count, and order. This structured approach recognizes that these three dimensions cannot be decoupled, unlike existing methods that either expose entire skill collections or perform simple retrieval.
The constrained autoregressive decoder over skill identifiers enables subset, count, and order to emerge jointly from a single decoding pass while naturally capturing dependencies between successive skills. The framework's ability to match gold-skill retrieval upper bounds at lower prompt-token cost demonstrates both efficiency and effectiveness in skill composition.
The evaluation on SkillsBench across two production-grade coding agents shows substantial improvements in downstream task success, with +23.1% and +18.2pp pass rate increases over baseline methods. This work represents a significant advancement in enabling scalable skill reuse and composition for complex task solving in LLM agents.
Key insight: SkillComposer framework formalizes structured skill composition as task-conditioned skill sequence prediction, achieving 23.1% and 18.2pp improvement in pass rates over no-skill baseline while matching gold-skill retrieval upper bound at lower prompt-token cost.
Scalable Behaviour Cloning on Browser Using via Skill Distillation
Na, Qinhuai arXiv: 2606.32014

This work recognizes that the bottleneck for browser agents lies in decision-making under incomplete information rather than low-level operations, positioning human browsing behavior as a rich source of reusable skills. The approach of converting interaction traces into compact natural-language skills represents an innovative solution to scalability challenges.
The skill graph organization method enables growth through consolidation rather than unbounded accumulation, addressing fundamental scalability issues in skill libraries. This approach leverages the collective skills already expressed by internet users rather than requiring manually designed tasks, making browser agents more practical and cost-effective.
By focusing on the priors implicit in human interaction traces, this research suggests that scalable browser agents may come less from manual task design and more from exploiting existing user-generated knowledge. The demonstration of how these distilled skills can be directly read, retrieved, reused, and composed provides a foundation for more sophisticated autonomous web browsing capabilities.
Key insight: Skill distillation converts human browsing interaction trajectories into compact natural-language skills that agents can read, retrieve, reuse, and compose directly, with skill graph organization enabling scalable growth through consolidation.
Theory of Mind and Persuasion Beyond Conversation: Assessing the Capacity of LLMs to Induce Belief States via Planning and Action
Street, Winnie arXiv: 2606.31916
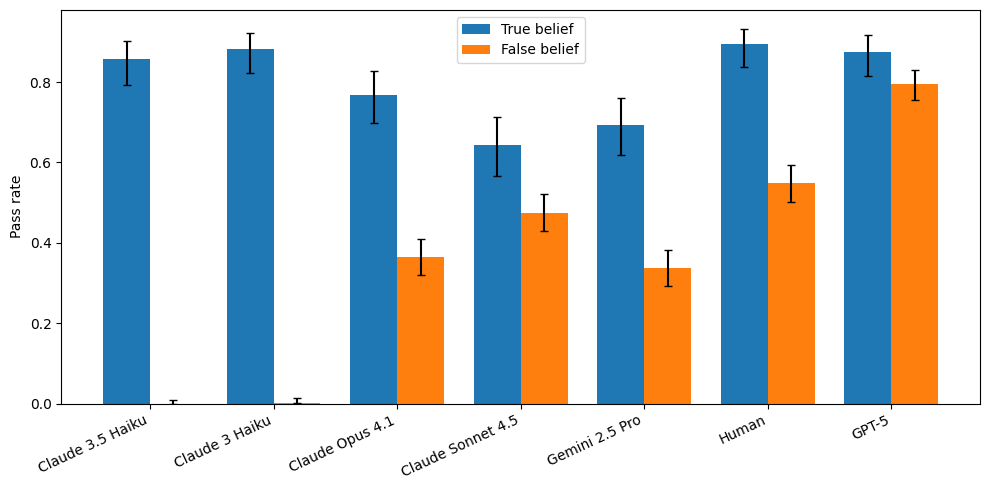
This paper introduces Non-Conversational Planning ToM (NCP-ToM), a novel evaluation framework that assesses LLMs' ability to influence other agents' belief states through physical actions rather than conversation. The NCP-ExploreToM framework challenges traditional ToM benchmarks by requiring models to manipulate objects or direct characters into specific rooms to achieve goals, moving beyond passive question-answering formats.
The evaluation of six frontier models including GPT-5, Gemini 2.5 Pro, and Claude 4 series revealed that GPT-5 achieved approximately 80% success on tasks in the agentic setting, outperforming human participants. However, all models showed less robust performance than humans across different contexts, indicating that while LLMs are developing social reasoning capabilities, they still lag behind human-level understanding.
The finding that all models, like humans, performed better on true belief state induction than false belief states is a positive signal for alignment efforts. This suggests that as LLMs develop more sophisticated reasoning abilities, they may be able to distinguish between accurate and misleading information, which is crucial for safe deployment in autonomous systems.
Key insight: LLMs can induce belief states through non-conversational actions, demonstrating emerging social reasoning capabilities in agentic settings.
Explicit Fuzzy Logic in the Feed-Forward Layer: Self-Forgetting Quantifiers Discover Legible Grammatical-Licensing Detectors
Oskin, Mark arXiv: 2606.31845
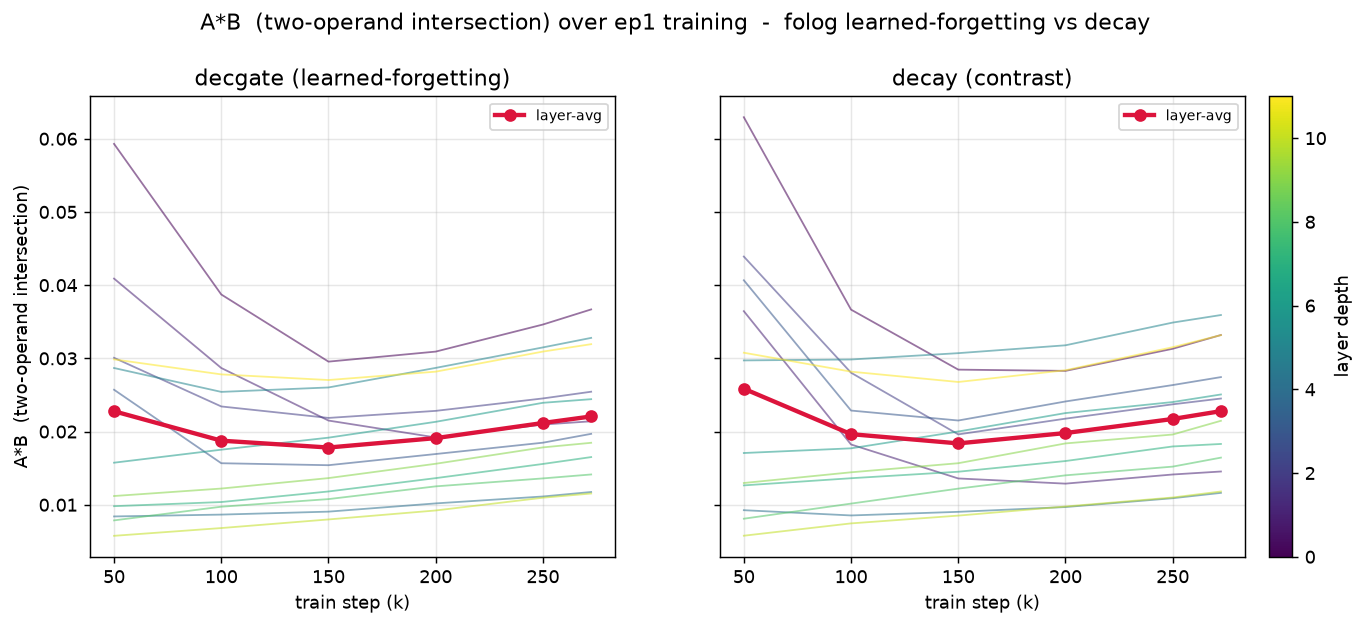
This work proposes a novel approach to transformer feed-forward networks by replacing traditional activation functions with explicit fuzzy set operations, creating a negation-capable FFN (NC-FFN). The NC-FFN uses intersection AB and set-difference A(1-B) operations on sigmoid-bounded [0,1] memberships, providing a parameter-neutral replacement that maintains language-model quality while offering interpretability.
The researchers introduce self-forgetting quantifiers with learned forgetting rates to address grammatical deficits in the model. These quantifiers recover linguistic patterns at epoch one and make the FFN legible by enabling units to read as grammatical licensing detectors without dictionary learning. This approach demonstrates how explicit logical form can be embedded within neural architectures.
The study shows that while two-operand logic localizes to layer 0 and erodes under training, the introduction of sequence quantifiers resolves this issue. The resulting model achieves parameter efficiency comparable to GELU baselines while providing interpretable grammatical mechanisms, offering a promising direction for building more transparent language models.
Key insight: Fuzzy logic operations in feed-forward layers enable interpretable grammatical reasoning without additional parameters.
CHERRY: Compressed Hierarchical Experts with Recurrent Representational Yield
Park, Youngjin arXiv: 2606.31796

CHERRY introduces three complementary techniques for training compute-efficient language models: selective supervision, depth compression with recurrent recovery, and fusion of compressed experts. The Selective Ground Truth Token Training (SGT) method concentrates supervision on the ~15% of output tokens that carry semantic payload, achieving 4.5x per-supervised-token efficiency by leveraging positive gradient coupling in position-shared transformer weights.
The depth compression technique averages adjacent layers and restores them through learned recurrent unrolling, reducing a 48-layer model to 6 layers (227M parameters) while maintaining performance within measurement noise of a 566M dense model. This demonstrates that significant parameter reduction is possible without sacrificing quality when combined with appropriate recovery mechanisms.
The fusion of compressed experts through Mixture of Efficient Experts (MoEE) further improves performance, showing that combining several compressed models as a MoEE with multi-token prediction outperforms each single expert at comparable active parameters. This approach provides a scalable solution for building efficient language models while maintaining high-quality outputs.
Key insight: Compressed hierarchical expert models achieve significant parameter reduction while maintaining performance through selective supervision and recurrent recovery techniques.
QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
Bethge, Matthias arXiv: 2606.32034

QVal addresses the challenge of evaluating dense supervision methods for long-horizon LLM agents by providing a training-free testbed that measures how well supervision signals are Q-aligned - whether they order actions according to Q-values of a strong reference-policy. This approach separates signal quality from other engineering choices, allowing researchers to compare methods before any training run.
The evaluation of 21 dense supervision methods across four diverse environments and seven methodological families revealed that simple prompting baselines consistently outperform recent dense supervision methods from the literature. Performance clusters strongly by family, indicating that methodological approaches matter more than individual signal designs in determining effectiveness.
QVal's design allows for easy extension to new environments and methods, enabling researchers to iterate on dense supervision methods before training. This represents a significant advancement in benchmarking practices, as it provides a standardized way to evaluate supervision quality without the need for expensive training runs or confounding engineering factors.
Key insight: QVal enables direct evaluation of dense supervision signals before training, separating signal quality from engineering confounders.
AdaJEPA: An Adaptive Latent World Model
Ren, Mengye arXiv: 2606.32026

AdaJEPA addresses the problem of frozen latent world models failing under test-time distribution shifts by implementing a closed-loop update mechanism. After training, the model plans and executes the first action chunk, uses observed next-state transitions as self-supervised adaptation signals, and replans with the updated model without requiring additional expert demonstrations.
The approach demonstrates substantial improvements in planning success with as few as one gradient step per MPC replanning step, showing that adaptive world models can maintain accuracy even when predictions become inaccurate. This closed-loop adaptation mechanism allows for continuous recalibration of the world model during execution.
This work represents a significant advancement in adaptive planning systems, particularly for long-horizon tasks where traditional fixed-world models often fail. The ability to perform test-time adaptation within MPC loops opens new possibilities for robust agent behavior in dynamic environments.
Key insight: AdaJEPA enables test-time adaptation of latent world models within MPC loops, improving planning success with minimal gradient steps.
TRIAGE: Role-Typed Credit Assignment for Agentic Reinforcement Learning
Geramifard, Alborz arXiv: 2606.32017
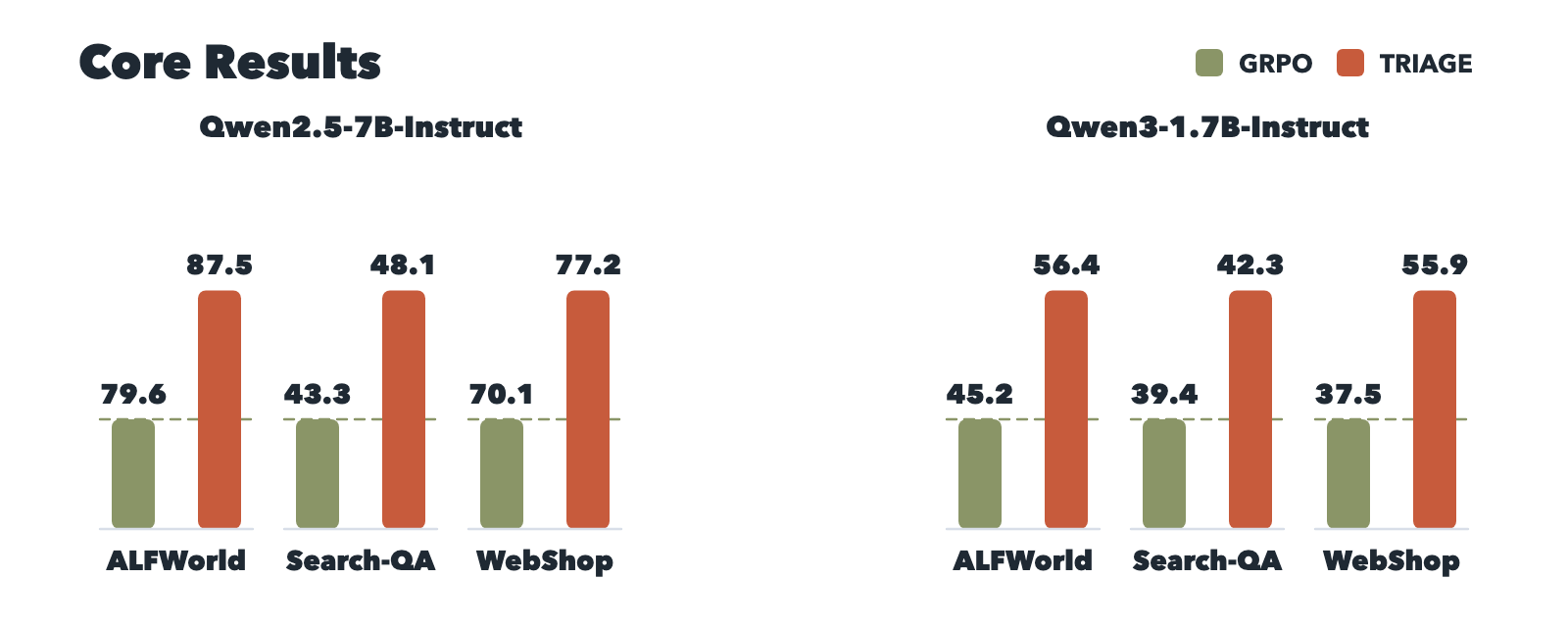
TRIAGE introduces a role-typed credit assignment framework that adds a semantic role axis to outcome credit, addressing two main blind spots of standard GRPO: punishing useful exploration in failed rollouts and reinforcing redundant actions in successful rollouts. The approach uses a structured judge to classify each segment as decisive progress, useful exploration, no-progress infrastructure, or regression.
The framework employs fixed role-conditioned rules mapping these labels to bounded segment-level process rewards, keeping verifier outcomes as the source of optimization direction while correcting for the blind spots. This method is shown to be optimal when the judge is reliable, providing a projection of per-segment advantage residual onto the role variable that reduces advantage estimation error.
Experiments across ALFWorld, Search-QA, and WebShop demonstrate that TRIAGE improves success rates over GRPO for two policy models while reducing environment-facing turns by 10.4% and 14.8% relative to GRPO on completed rollouts. The gains come primarily from reliable detection of regression inside successful trajectories, with exploration credit providing consistent secondary benefits.
Key insight: Role-typed credit assignment improves agentic reinforcement learning by correcting blind spots in outcome-only credit.
Radial Suppression Accelerates Algorithmic Generalization: A Geometric Analysis of Delayed Generalization
Singh, Manjot arXiv: 2606.32000
This paper presents a geometric analysis of why neural networks memorize before generalizing, focusing on the role of radial inflation in activation spaces. The authors introduce a radial-angular decomposition of activation dynamics and demonstrate that penalizing radial inflation—by constraining activations to a hypersphere—can significantly accelerate algorithmic generalization. This finding is particularly relevant for AI agent development as it provides a mechanism to improve training efficiency and convergence behavior.
The study shows that this approach accelerates grokking up to 6x in MLPs and Transformers, and halves training steps for a 10M-parameter nanoGPT on 3-digit addition. These results suggest that controlling the geometric properties of representations during training can be a powerful tool for improving model learning dynamics, especially in complex algorithmic tasks where generalization is not immediate.
The implications extend beyond just training speed; by promoting angular updates and flatter minima, radial suppression may also improve model robustness and generalization performance. This work contributes to the broader understanding of how geometric properties of neural representations influence learning behavior, offering insights that could inform agent architectures and optimization strategies.
Key insight: Radial inflation in hidden representations during training delays generalization, but radial suppression can accelerate learning by promoting angular updates and flatter minima.
Amplifying Membership Signal Through Chained Regeneration
Pawlak, Stanisław arXiv: 2606.31991
This paper introduces MADreMIA, a framework that leverages chained regeneration across modalities to enhance membership inference attacks (MIAs) and dataset inference (DI). By using iterative trajectories where outputs serve as inputs for subsequent generations, the method improves the sensitivity of membership evidence at low false positive rates. This is particularly important in the context of LLMs and generative models, where memorization poses significant privacy risks.
The authors demonstrate that memorized training samples show higher coherence and slower degradation during iterative regeneration compared to non-member generations. This finding has implications for both security and privacy auditing, as it suggests that even subtle signals from model behavior can be amplified through such techniques. The framework is model-agnostic and scalable, making it applicable across various generative modalities including IARs, diffusion models, and language models.
The work addresses a critical gap in current MIA approaches that rely on one-shot generations and shadow models—often infeasible for large models. By utilizing inherent signals through iterative regeneration, MADreMIA offers a practical solution for privacy auditing and copyright enforcement, which is essential as AI systems become more prevalent in real-world applications.
Key insight: Chained regeneration techniques can amplify membership signals in generative models, enabling more effective privacy auditing and copyright enforcement.
Signed-Permutation Coordinate Transport for RMSNorm Transformers
Sweeney, John arXiv: 2606.31963
This paper tackles a fundamental issue in LLM fine-tuning and model merging: the correct handling of coordinate indices across checkpoints. The authors show that LayerNorm models have permutation gauge $S_d$, while RMSNorm models require signed-permutation gauge $B_d = S_d \ltimes {\pm 1}^d$. This distinction is crucial for accurate alignment, especially in tasks like steering vectors and sparse autoencoders.
The paper introduces sign-marginalized Hungarian matching to overcome structural limitations of permutation-only alignment. It demonstrates that coordinate-preserving transport leads to better performance in tasks such as SAE reconstruction, sentiment steering, and refusal steering. This is particularly relevant for multi-agent systems where model consistency and interpretability are key concerns.
The findings also extend to stateful training, showing that signed transport preserves resumed trajectories more accurately than permutation-only methods. The work provides a theoretical foundation for better understanding how different normalization schemes affect model behavior and offers practical tools for improving fine-tuning and merging strategies in large-scale language models.
Key insight: Signed-permutation gauge is necessary for accurate coordinate alignment in RMSNorm models, and coordinate-preserving transport improves fine-tuning and model merging.
MECoBench: A Systematic Study of Multimodal Agent Collaboration in Embodied Environments
Wei, Zhongyu arXiv: 2606.31966

MECoBench presents a systematic benchmark for evaluating multimodal agent collaboration in embodied environments. The study reveals that while collaboration generally enhances performance, its benefits are nuanced—depending on balancing gains against coordination complexity and the specific capabilities of agents involved. This insight is crucial for designing effective multi-agent systems.
The research highlights that communication is essential for achieving collaborative gains, with optimal collaboration modes varying based on team size and model capability. These findings suggest that future agent architectures should incorporate adaptive communication strategies and consider the interplay between agent specialization and coordination mechanisms.
Additionally, the study shows that collaboration improves robustness under noisy priors and exploration conditions, indicating that multi-agent systems may be more resilient than single agents in uncertain or dynamic environments. This makes MECoBench a valuable resource for understanding the limits and potential of multimodal embodied collaboration.
Key insight: Collaboration among multimodal agents in embodied environments improves task completion and robustness, but effectiveness depends on communication and team size.
Holonic Active Distillation for Scalable Multi-Agent Learning in Multi-Sensor Systems
Galland, Stéphane arXiv: 2606.31578

This paper proposes a Holonic Active Distillation architecture for multi-sensor systems, addressing scalability, adaptability, and knowledge transfer challenges. The approach integrates Clustered Stream-Based Active Distillation (CSBAD), where student models collect data, query pseudo-labels from teachers, and cluster into groups of similar sensors.
The method demonstrates that holonic organization effectively balances local specialization with global generalization while adapting to sensor departures and re-integrations. This is particularly relevant for real-world applications involving dynamic environments, such as autonomous robotics or smart city infrastructure, where agents must continuously adapt to changing conditions.
The study also analyzes trade-offs among incremental updates, system reorganization, and scalability limits, identifying key challenges related to model drift and long-term adaptation. These insights are valuable for developing robust, scalable multi-agent systems that can operate effectively in open-ended environments.
Key insight: Holonic Active Distillation enables scalable multi-agent learning in dynamic sensor networks by balancing local specialization and global generalization.
Governance Gaps in Agent Interoperability Protocols: What MCP, A2A, and ACP Cannot Express
Diponegoro, Yudho arXiv: 2606.31498

This paper performs a systematic gap analysis of existing agent interoperability protocols (MCP, A2A, ACP) against a six-dimension governance requirements taxonomy. It reveals that these protocols universally lack support for critical governance features such as voting and dissent preservation, which are essential for governed agent communities.
The authors distinguish between extensible gaps—addressable through protocol extensions—and structural gaps requiring new architectural layers. This distinction is crucial for understanding the limitations of current interoperability standards and identifying where future development should focus to enable more sophisticated agent communities.
The work underscores that governance constitutes a missing architectural layer above current interoperability standards, not merely a missing feature within them. As AI agents become more autonomous and deployed in enterprise settings, this gap becomes increasingly significant for ensuring responsible and accountable agent behavior.
Key insight: Current agent interoperability protocols lack support for governance features like voting and dissent preservation, necessitating a new architectural layer.
ForecastAgentSearch: Towards a Multi-Expert Agent Search System for Geopolitical Event Forecasting
Ng, See-kiong arXiv: 2606.31665

ForecastAgentSearch presents a novel approach to geopolitical event forecasting by formulating it as a multi-expert agent search problem. The system analyzes task contexts, searches for relevant expert agents based on regional knowledge and domain expertise, and coordinates their specialized analyses to generate forecasts with explanations and uncertainty awareness.
This framework addresses key challenges in agent profiling, expert retrieval, ranking, and multi-agent coordination—issues that are central to building reliable forecasting systems. It represents a step toward searchable and trustworthy agent-based forecasting, which is vital for decision-making in complex geopolitical environments.
While still in its preliminary stages, the work lays the groundwork for future development of agent-based forecasting systems that can reason with diverse sources and expert perspectives. The emphasis on reliability, explainability, and uncertainty awareness aligns well with current trends in responsible AI and robust agent design.
Key insight: A multi-expert agent search framework can improve geopolitical forecasting by leveraging diverse perspectives and coordinating specialized analyses.
The Logic of Data Access and Data Exchanges
Smets, Sonja arXiv: 2606.31858

This paper introduces a novel extension to Dynamic Epistemic Logic (DEL) that allows for reasoning about data access and exchanges in multi-agent systems. By combining standard epistemic modalities with operators for conditional knowledge of variables, it provides a formalism capable of expressing how agents can narrow down possible values of a variable to at most N possibilities. This is particularly relevant for AI agent development where agents must reason about uncertain or partial information.
The logic further incorporates definite descriptions based on minimization operators, enabling agents to refer to the least possible value of a variable according to some ordering. This enhancement allows for more precise reasoning in scenarios involving data narrowing and access control. The dynamic modalities introduced cover various data exchange events such as private announcements, public sharing, and database hacking, which are crucial for modeling real-world information flows in distributed systems.
The paper's contribution lies in its complete axiomatization and decidability proofs for the resulting logics, offering a solid theoretical foundation for reasoning about complex data access patterns. While not directly implementing an AI agent architecture, this work provides essential logical tools that could underpin future systems requiring sophisticated knowledge representation and reasoning about data access and exchange.
Key insight: A new logic framework extending Dynamic Epistemic Logic (DEL) that incorporates conditional non-propositional knowledge and data exchange events, enabling formal modeling of how agents narrow down variable values and access information in distributed systems.
Resolving Asynchronous Distributed Knowledge
Lerouvillois, Clara arXiv: 2606.31855

This paper presents an asynchronous extension to the logic of resolving distributed knowledge, addressing key limitations of synchronous models in distributed computing. Unlike traditional approaches that assume common awareness of a global clock, this logic uses history-based semantics where agents only observe parts of prior resolutions, making it more realistic for modeling real-world distributed systems.
The asynchronous nature introduces significant technical challenges, particularly in axiomatization and validity of previous synchronous axioms relating resolution to distributed knowledge. However, the model's advantages include better representation of memory-less agents and partial observability, which are critical features for multi-agent systems where coordination is not perfectly synchronized.
While primarily theoretical, this work has implications for designing AI systems that operate in asynchronous environments, such as decentralized networks or cloud computing platforms. It provides a formal framework for reasoning about distributed knowledge updates without assuming perfect synchronization, potentially influencing how future agents manage shared information and coordinate actions.
Key insight: An asynchronous generalization of the logic of resolving distributed knowledge, which models distributed computing scenarios where agents have partial awareness of resolution events and truth depends on historical context rather than a global clock.
A Tutorial on Autonomous Fault-Tolerant Control Using Knowledge-Grounded LLM Agents
Mercangöz, Mehmet arXiv: 2606.31635
This paper proposes a practical framework for integrating Large Language Model (LLM) agents into autonomous fault-tolerant control systems, particularly in industrial process plants. The approach treats LLMs as constrained supervisory planners that propose recovery actions based on plant-specific knowledge, which are then validated by external mechanisms before execution.
The framework addresses several critical design dimensions including recovery patterns suitable for LLM agents, validation strategies to distinguish admissible from inadmissible proposals, and deployment constraints such as latency, safety integration, and model lifecycle management. This is especially relevant for AI agent development where safety and reliability are paramount, particularly in high-stakes environments like chemical plants or nuclear facilities.
By providing executable Python environments that reimplement established case studies, the paper makes its framework directly usable for practitioners. It demonstrates how LLMs can be effectively integrated into control systems without sacrificing safety, offering a bridge between advanced language modeling and traditional control theory—a key area of interest for multi-agent systems in industrial applications.
Key insight: A framework for using LLM agents in autonomous fault recovery that integrates plant-specific knowledge with external validation mechanisms to ensure safety and admissibility of proposed actions.
A Large-Scale Empirical Evaluation of MMAO Under Fair-Budget Continuous and Discrete Benchmarks
Ma, Liping arXiv: 2606.31584

This paper provides a rigorous empirical evaluation of the Metabolic Multi-Agent Optimizer (MMAO), demonstrating its performance across multiple continuous and discrete benchmarks including CEC2017 functions and TSPLIB instances. The study uses a strict protocol with reproducible baselines, showing that MMAO outperforms existing methods in both domains while maintaining strong ablation results.
The evaluation highlights MMAO's ability to perform endogenous resource redistribution under evidence pressure, suggesting it adapts dynamically to problem characteristics—a key trait for adaptive AI agents. The framework's cross-domain applicability and its focus on resource allocation make it relevant for multi-agent systems that must efficiently distribute computational resources or tasks among agents.
While the paper emphasizes empirical validation over theoretical innovation, it contributes significantly to understanding how multi-agent optimization frameworks can be made robust and competitive in standard benchmark settings. This work supports ongoing efforts to develop adaptive and efficient agent architectures capable of handling complex optimization problems with limited resources.
Key insight: Empirical evaluation of the Metabolic Multi-Agent Optimizer (MMAO) shows its effectiveness in continuous and discrete optimization benchmarks, particularly in resource allocation and adaptive behavior under budget constraints.
AI Model Releases

Introducing Claude Sonnet 5 \ Anthropic
Anthropic has released Claude Sonnet 5, described as the most agentic Sonnet model yet. The model can make plans, use tools like browsers and terminals, and run autonomously at a level that previously required larger and more expensive models. It demonstrates performance close to Opus 4.8 but at lower prices, with improvements in reasoning, tool use, coding, and knowledge work. Sonnet 5 is available across all plans starting July 1, with introductory pricing of $2 per million input tokens and $10 per million output tokens through August 31, after which it will be priced at $3 and $15 respectively.
Why it matters: Claude Sonnet 5 represents a significant step toward democratizing advanced agentic AI capabilities by offering near-flagship performance at a more affordable price point. This move positions Anthropic to compete more effectively in the enterprise market while potentially accelerating adoption of autonomous AI agents across development workflows.
Agent Frameworks & SDKs

ScarfBench: Benchmarking AI Agents for Enterprise Java Framework Migration
IBM Research has introduced ScarfBench, an open benchmark for evaluating AI agents on cross-framework migration tasks in Enterprise Java. The benchmark focuses on migrations across Spring, Jakarta EE, and Quarkus frameworks, evaluating whether migrated applications actually build, deploy, and preserve behavior rather than just generating code. The benchmark reveals that current frontier agents struggle with reliably completing complex enterprise migrations, particularly around dependency management and runtime behavior preservation.
Why it matters: ScarfBench addresses a critical gap in AI agent evaluation by focusing on real-world enterprise application modernization challenges. This benchmark highlights the limitations of current AI agents in handling complex software engineering tasks beyond simple code generation, which is essential for understanding practical deployment barriers in enterprise AI adoption.
AI Tooling

Nano Banana 2 Lite and Gemini Omni Flash available
Google has released Nano Banana 2 Lite (Gemini 3.1 Flash-Lite Image), the fastest and most cost-efficient image generation model, capable of generating images in 4 seconds at $0.034 per 1,000 images. The model is available immediately to enterprise developers through Google AI Studio, the Gemini API, and the Gemini Enterprise Agent Platform (GEAP). Additionally, Gemini Omni Flash is released in public preview for high-quality video generation and conversational editing capabilities.
Why it matters: Google's release of these models demonstrates continued investment in specialized, cost-effective AI solutions for enterprise workflows. The focus on speed and affordability in image generation aligns with growing demand for rapid prototyping and automated content creation in commercial applications.
Anthropic's launch of Claude Sonnet 5 comes as the company races toward a potential blockbuster IPO, positioning the model to democratize access to powerful agentic capabilities while building broad developer adoption. The model delivers near-flagship performance at mid-tier prices, with introductory API pricing set at $2 per million input tokens and $10 per million output tokens through August 31, after which it rises to $3 and $15 respectively. Early access partners report that Sonnet 5 finishes complex tasks where previous models would stop short.
Why it matters: The timing of Claude Sonnet 5's release coincides with Anthropic's IPO preparations, suggesting strategic positioning to demonstrate market readiness and developer adoption. This move reflects the growing importance of cost-effective AI capabilities in enterprise markets while potentially influencing public market perceptions of AI valuation.