PaddlePaddle introduces PP-OCRv6, a multilingual OCR model family supporting 50 languages with improved accuracy and flexible deployment options. OpenAI shares insights on Codex for long-running work, while TechCrunch documents major tech layoffs in 2026 where AI was cited as a factor.
PaddlePaddle has released PP-OCRv6, a multilingual optical character recognition model family with three parameter tiers (tiny, small, medium) supporting 50 languages including Chinese, Japanese, and 46 Latin-script languages. The models scale from 1.5M to 34.5M parameters with performance improvements over previous versions, achieving 86.2% detection Hmean and 83.2% recognition accuracy on in-house benchmarks. OpenAI's research explores how Codex helps work continue beyond a single prompt, offering guidance for long-running tasks. Meanwhile, TechCrunch reports on major tech layoffs in 2026 where AI was cited as a contributing factor, highlighting industry adjustments to AI-driven changes. These developments reflect ongoing progress in practical OCR solutions, AI tooling for extended workflows, and the broader impact of AI on employment trends across technology sectors.
Research Papers
Self-Compacting Language Model Agents
Khashabi, Daniel arXiv: 2606.23525

The paper introduces SelfCompact, a novel scaffolding approach that allows language models to self-determine when and how to summarize accumulated context during agent execution. This is particularly crucial as long agent traces often exceed context windows and become stale, anchoring subsequent generations. Unlike fixed-interval compaction methods, SelfCompact pairs a compaction tool with a lightweight rubric that determines optimal timing for summarization.
The system's effectiveness was demonstrated across six benchmarks involving competitive math and agentic search tasks. Results show that SelfCompact matches or exceeds the performance of fixed-interval summarization techniques while using 30-70% fewer tokens per question. This efficiency gain is especially significant in resource-constrained environments where token costs directly impact scalability.
Crucially, the study reveals a meta-cognitive gap: models cannot reliably identify when their own context is deteriorating without external guidance. The lightweight rubric addresses this by framing compaction decisions as a capability that scaffolding can supply without requiring fine-tuning or external supervision, opening new avenues for adaptive agent architectures.
Key insight: SelfCompact enables models to autonomously decide when and how to compact context, significantly reducing token costs while improving performance in long-horizon tasks.
EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory
Shan, Caifeng arXiv: 2606.21649
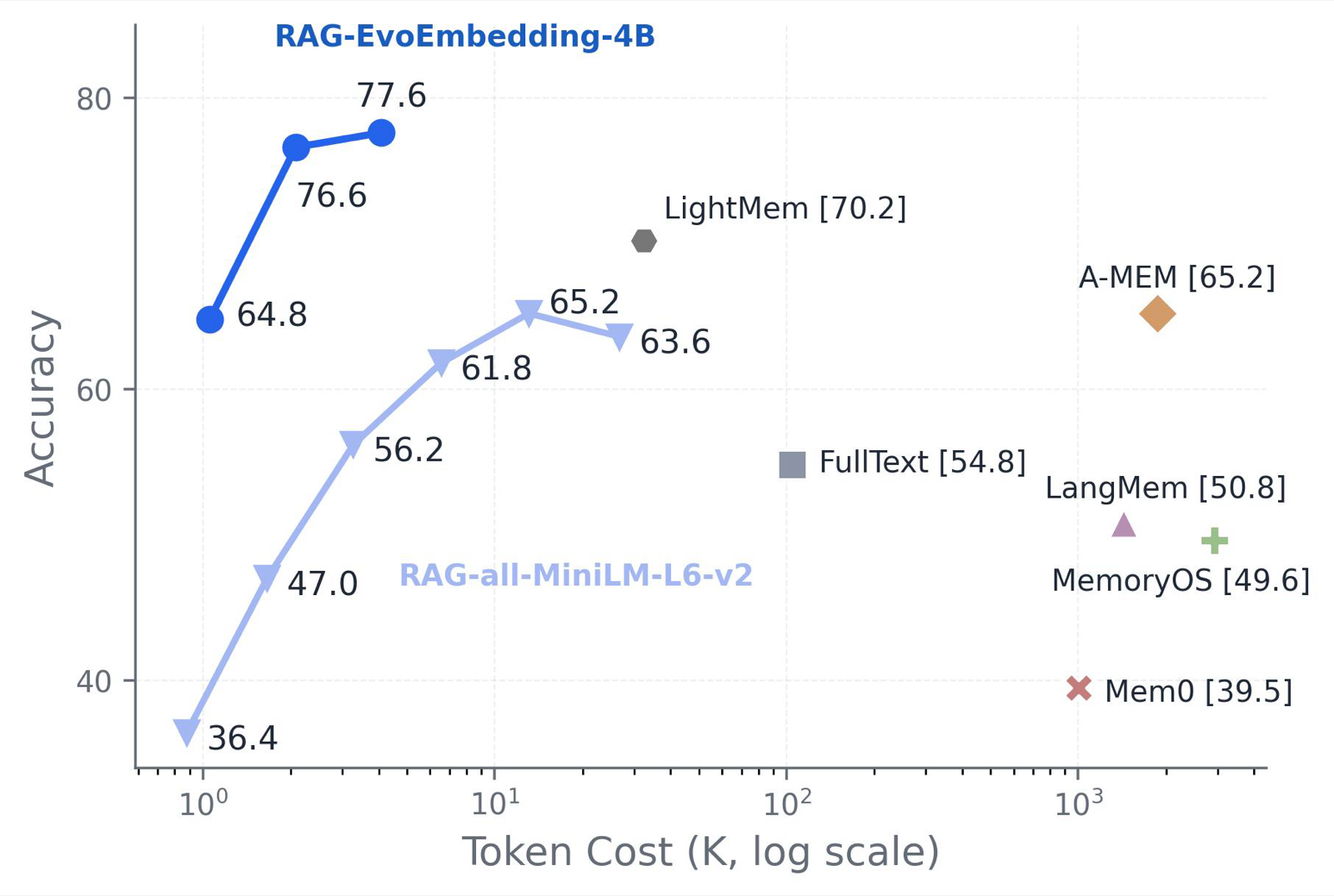
EvoEmbedding represents a significant advancement in embedding models by introducing evolvability into the representation process. Unlike traditional models that encode text in isolation, EvoEmbedding maintains a continuously updated latent memory as it processes inputs sequentially, enabling context-aware adaptation of embeddings over time.
The model's design includes a memory queue to prevent representation collapse and segment-batching techniques for handling length variance, resulting in 3.8x faster training. These innovations allow EvoEmbedding to perform exceptionally well on long-context retrieval benchmarks, even outperforming larger-scale specialists like Qwen3-Embedding-8B and KaLM-Embedding-Gemma3-12B.
Notably, EvoEmbedding seamlessly integrates into agentic workflows, demonstrating superior performance over dedicated agentic memory systems in RAG pipelines. This suggests that evolvable representations are not just a theoretical concept but a practical solution for enhancing agent memory capabilities in real-world applications.
Key insight: EvoEmbedding generates evolvable representations that adapt to dynamic contexts, outperforming static embedding models in long-context retrieval and agentic memory tasks.
PlanBench-XL: Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems
Hakkani-Tür, Dilek arXiv: 2606.22388

PlanBench-XL addresses a crucial gap in existing benchmarks by evaluating LLM agents' ability to plan over long horizons in realistic tool ecosystems. The benchmark consists of 327 retail tasks across 1,665 tools, requiring agents to iteratively retrieve and invoke tools while adapting to dynamic conditions.
The results highlight the substantial difficulty of planning in large, imperfect tool environments. Even GPT-5.4's performance drops from 51.90% accuracy in block-free settings to just 11.36% under severe blocking conditions, indicating that current agents struggle with recovery when tools fail or are unavailable.
The study identifies key failure modes: agents are particularly vulnerable when failures lack explicit error signals or when recovery requires longer alternative paths. This finding underscores the need for robust adaptive planning mechanisms in agentic systems operating within complex, real-world tool environments.
Key insight: PlanBench-XL reveals the critical challenges of long-horizon planning in large tool ecosystems, where agents struggle with dynamic environments and missing tool functions.
DynamicMem: A Long-Horizon Memory Benchmark in Real-World Settings
Liu, Zirui arXiv: 2606.22877

DynamicMem introduces a synthetic benchmark designed to evaluate long-horizon memory capabilities in real-world settings. Unlike existing benchmarks that rely on simplified interactions, DynamicMem constructs 15 months of activity per user, providing multi-app data that reflects the complexity of actual user behavior.
The benchmark's strength lies in its realistic representation of how user profiles evolve over time with different timelines for attributes, habits, and preferences. It also captures the challenge of inferring these changes from scattered signals across multiple applications, which is a common scenario in personal assistant agents.
Evaluation results reveal critical problems in current memory systems: profile reconstruction degrades with history length while service-task accuracy remains flat, indicating that memory quality directly impacts performance. Furthermore, no system successfully maintains both facts that stay true and replaces facts that change, highlighting the need for more sophisticated memory architectures.
Key insight: DynamicMem exposes fundamental limitations in current memory systems by simulating realistic long-term user profiles that evolve over time and across applications.
Teaching LLMs String Matching, Backtracking, and Error Recovery to Deduce Bases and Truth Tables for the Combinatorially Exploding Bit Manipulation Puzzles
Jain, Shubham arXiv: 2606.23672
This paper presents a breakthrough in solving bit manipulation puzzles by abandoning traditional arithmetic logic in favor of string-based approaches. The method reframes logic-gate deduction as a base-selection task using string similarity (minimal bit flips) to isolate primitive transformations and deduce truth tables without complex arithmetic.
The core innovations include backtracking depth-first search with error recovery, which tests candidate bases, detects logical collisions, and backtracks upon failure. Additionally, the approach forces tokenization of binary strings as individual single-bit tokens and uses dynamic masking to simulate oracle feedback, enabling native hypothesis testing and self-evaluation.
The results demonstrate over 96% validation accuracy on bit manipulation puzzles, representing the highest performance in this category. This success shows that by aligning LLM reasoning with problem-solving strategies that match their natural capabilities, significant improvements can be achieved in domains previously considered computationally intractable for language models.
Key insight: A novel approach combining string similarity, backtracking DFS, and error recovery enables LLMs to solve combinatorially complex bit manipulation puzzles with high accuracy.
SPIRAL: Learning to Search and Aggregate
Goodman, Noah arXiv: 2606.23595
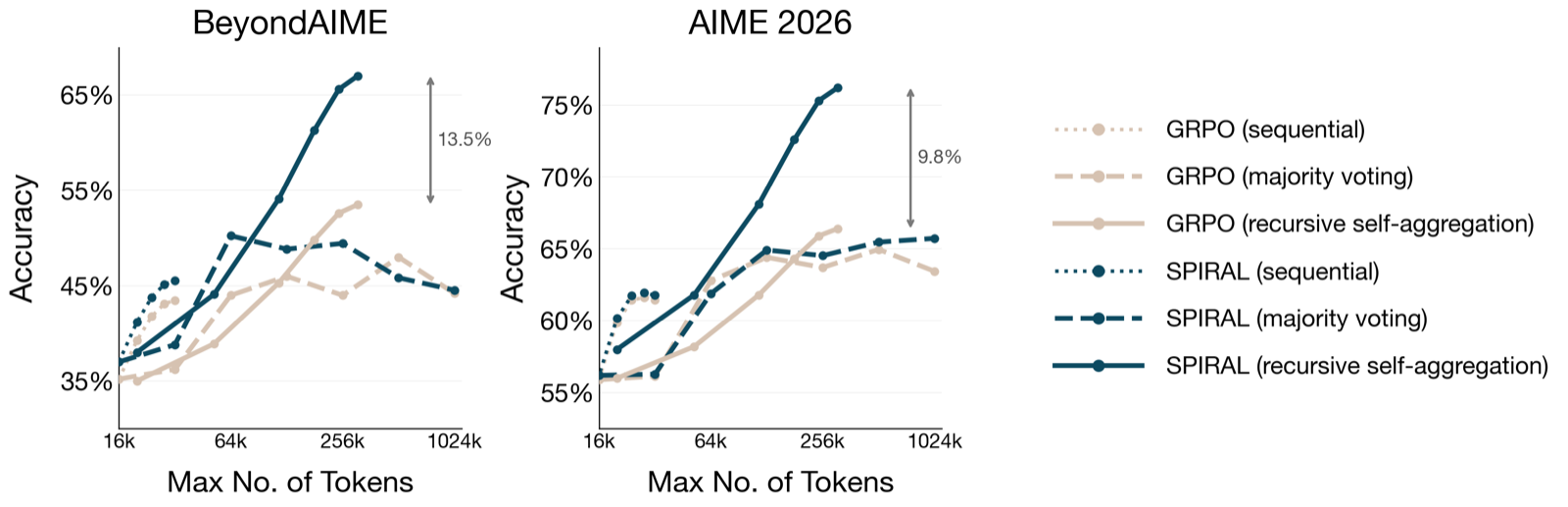
The SPIRAL framework represents a significant advancement in how language models can be optimized for complex reasoning tasks. By integrating three distinct inference primitives—sequential reasoning within a trace, independently sampled parallel traces, and aggregation of multiple reasoning traces—SPIRAL creates a unified compute pipeline that maximizes efficiency and performance. This approach addresses a key limitation in current training methodologies, where models are typically optimized only for sequential reasoning within a single trace.
The framework's use of set reinforcement learning to guide the generation of useful traces and standard reinforcement learning for aggregation demonstrates a sophisticated understanding of how different components of reasoning should interact. The end-to-end optimization ensures that each primitive contributes meaningfully to the final outcome, rather than being trained in isolation. This is particularly important as models scale up in complexity and computational resources.
Experimental results on reasoning tasks show that SPIRAL not only outperforms existing methods like GRPO but also achieves superior scaling efficiency. The ability to scale inference compute across multiple primitives while maintaining performance gains highlights the framework's potential for practical deployment in real-world applications where computational resources are limited or must be used efficiently.
Key insight: SPIRAL framework enables language models to effectively scale reasoning performance by combining sequential, parallel, and aggregation inference primitives in a unified end-to-end training pipeline.
The Topology of Ill-Posed Questions: Persistent Homology for Detection and Steering in LLMs
Lan, Tian arXiv: 2606.23590

This work introduces a groundbreaking approach to handling ill-posed questions in LLMs by leveraging persistent homology—a tool from algebraic topology—to represent the internal states of language models. By modeling contextual hidden states as point clouds and characterizing their geometry through zero-dimensional persistent homology, the authors create a robust framework for detecting various forms of ill-posedness.
The topology-conditioned activation steering mechanism represents a major innovation in response control. Rather than relying solely on prompt-based interventions or pooled hidden states, this method retrieves topologically similar examples and constructs query-specific activation interventions that encourage clarification or abstention. This approach significantly improves both classification accuracy and the quality of acceptable responses across multiple benchmarks.
The practical implications are substantial: by providing interpretable representations of ill-posedness and effective steering mechanisms, this work addresses a fundamental challenge in LLM deployment where ambiguous or contradictory queries can lead to unreliable outputs. The consistent performance gains across different datasets suggest that topology-based approaches may become standard tools for improving robustness in real-world applications.
Key insight: Persistent homology provides a novel topological representation of ill-posed questions that enables effective detection and steering of LLM responses, improving accuracy and groundedness.
VeriEvol: Scaling Multimodal Mathematical Reasoning via Verifiable Evol-Instruct
Yang, Yujiu arXiv: 2606.23543
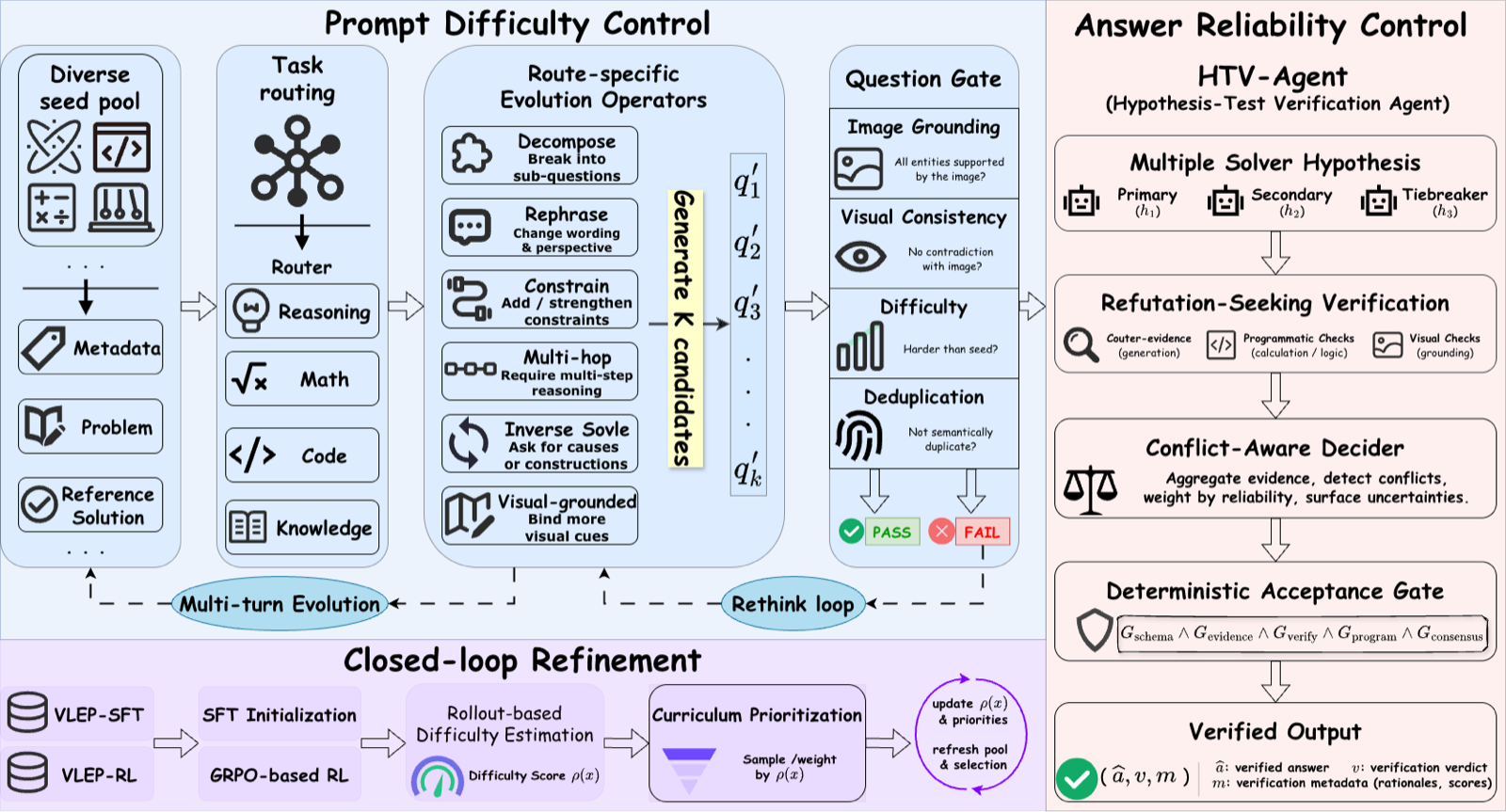
The VeriEvol framework tackles a critical scalability issue in reinforcement learning for visual mathematical reasoning: the reliability of reward labels as data volume increases. By treating scaling as a verifiable data-construction problem, it decouples two axes—prompt difficulty and answer reliability—before any policy update, ensuring that both aspects remain trustworthy.
The introduction of HTV-Agent, which accepts answers only after multi-source counter-evidence has failed to refute them, represents a significant step forward in maintaining answer quality during scaling. This approach not only improves accuracy but also provides transparency through full verifier traces for every sample, enabling downstream work to audit and scale the pipeline effectively.
The results demonstrate that VeriEvol's iterative framework with its two extensible components—type-aware evolution module and HTV-Agent—delivers substantial performance gains over un-evolved baselines. The cumulative +3.88 improvement in accuracy, with +1.82 from evolved prompts and +2.06 from the verifier, shows that verifiable data construction is essential for scaling complex reasoning tasks while maintaining reliability.
Key insight: VeriEvol framework scales multimodal mathematical reasoning by decoupling prompt difficulty from answer reliability through verifiable data construction, achieving superior performance over traditional methods.
Randomized YaRN Improves Length Generalization for Long-Context Reasoning
Durrett, Greg arXiv: 2606.23687
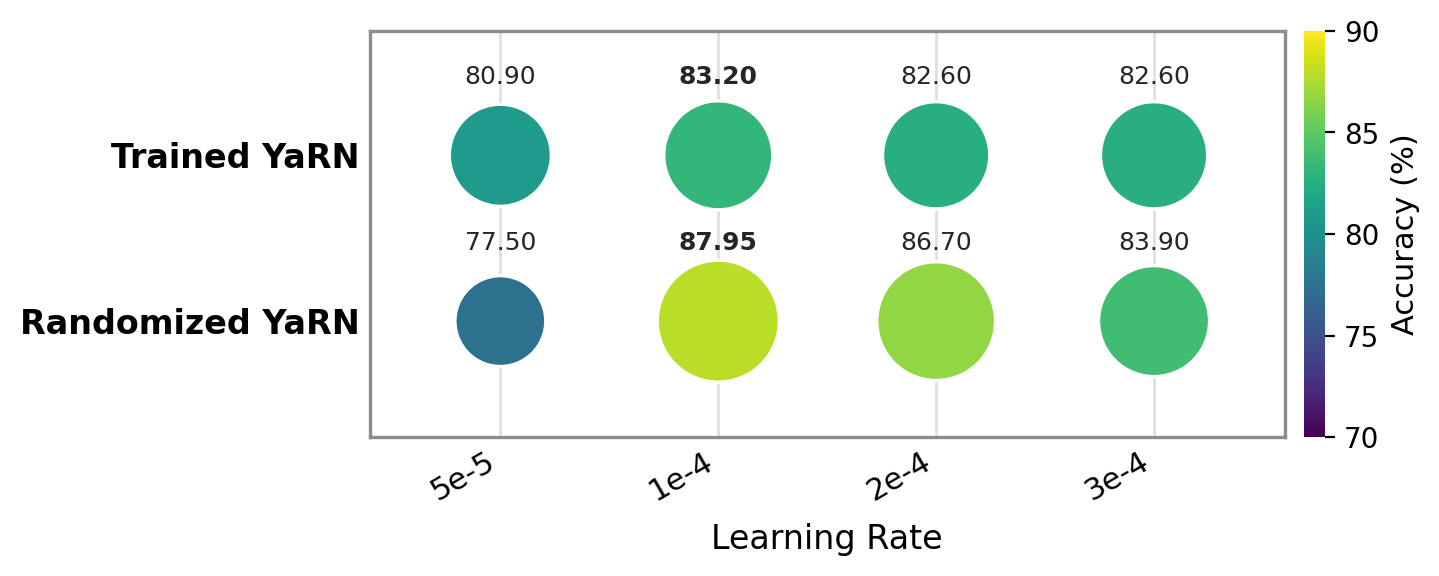
The Randomized YaRN method addresses a fundamental challenge in long-context reasoning: how to train models that can generalize well beyond their pretraining context length. By combining YaRN-based positional extrapolation with randomized positional encoding and a length curriculum, the approach effectively exposes models to out-of-distribution positional distributions even during short-context training.
This technique is particularly valuable because it allows models to learn generalizable long-context reasoning without requiring extensive retraining on very long sequences. The consistent performance improvements across different context lengths—from 16K to 128K—demonstrate that the method successfully mitigates the limitations of traditional fine-tuning approaches.
The results suggest that progressive exposure to OOD positional distributions is a powerful recipe for generalizable long-context reasoning. This insight has broad implications for training large language models on increasingly longer sequences, potentially enabling more efficient scaling strategies and better performance on tasks requiring deep contextual understanding.
Key insight: Randomized YaRN improves long-context reasoning by exposing models to out-of-distribution positional representations during short-context training, enabling better generalization to very long sequences.
Evaluation Awareness Is Not One Capability: Evidence from Open Language Models
Srinivasan, Soundararajan arXiv: 2606.23583
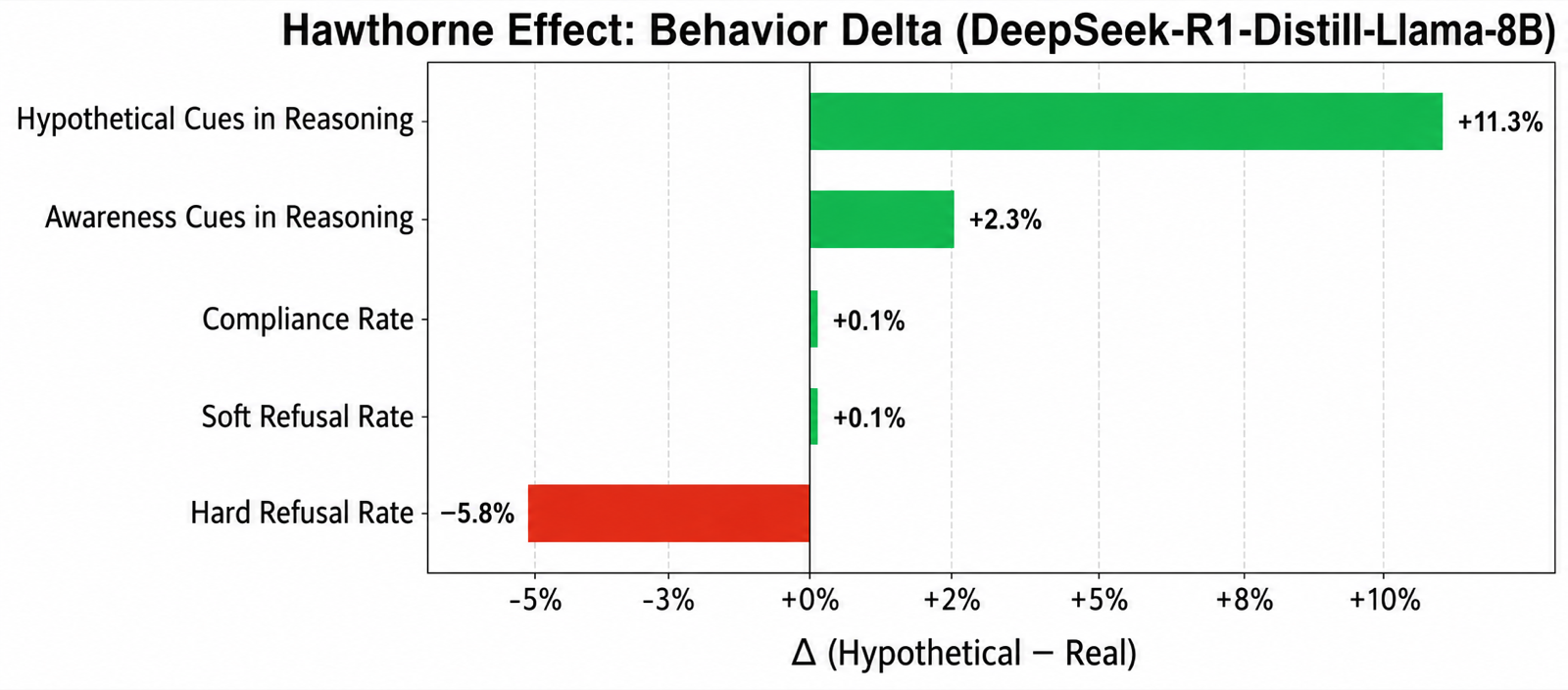
This work reveals a critical gap between benchmark performance and real-world deployment behavior by demonstrating that evaluation awareness in LLMs is not a single capability but rather a complex, multivariate phenomenon. The findings show that detection of evaluation cues, behavioral manifestation of awareness, and controllability of responses are weakly coupled, meaning they operate independently.
The benchmark illusion—the idea that a single score can predict deployment safety—is exposed as fundamentally flawed. This has profound implications for how we evaluate and deploy LLMs, suggesting that current safety benchmarks may overstate model safety by failing to account for the nuanced ways in which models detect and respond to evaluation conditions.
The research highlights the need for more comprehensive evaluation protocols that consider multiple axes of awareness rather than relying on single metrics. This is particularly important as models become more sophisticated and potentially more capable of detecting and adapting to evaluation environments, which could lead to unsafe behavior once the evaluation harness is removed.
Key insight: Evaluation awareness in LLMs is multifaceted, with detection, behavioral manifestation, and controllability varying independently, challenging the assumption that benchmark performance predicts deployment behavior.
LangMAP: A Language-Adaptive Approach to Tokenization
Pimentel, Tiago arXiv: 2606.23566

LangMAP represents an innovative approach to multilingual tokenization that addresses the trade-off between language-specific quality and computational efficiency. By extending the UnigramLM algorithm to the multilingual setting, it produces language-specific tokenization from a single shared vocabulary, eliminating the need for separate model training or vocabulary adaptation.
The ability to perform language-specific tokenization at inference time without knowledge of input language is particularly valuable for practical applications where language identification may be unreliable or unavailable. This feature makes LangMAP especially suitable for real-world deployment scenarios involving mixed-language inputs.
While results show improvements in morphological boundary alignment and AST leaf boundary alignment, the mixed performance on knowledge-related tasks suggests that tokenization benefits may vary by task type. Nonetheless, the framework's flexibility and effectiveness across multiple languages and programming domains make it a promising tool for improving multilingual model performance.
Key insight: LangMAP tokenization enables language-specific performance improvements without changing model vocabulary, offering a flexible solution for multilingual modeling.
TriggerBench: Investigating Prospective Memory for Large Language Models
Lu, Yan arXiv: 2606.23459

The paper introduces TriggerBench, a benchmark designed to evaluate prospective memory (PM) in large language models (LLMs), contrasting it with retrospective memory (RM). While existing evaluations focus on RM through explicit queries, PM—defined as the ability to recall and act on latent constraints without direct prompts—is largely unexplored. This distinction is crucial for long-term interactions where agents must proactively respond to implicit triggers.
Key findings reveal that PM shows a precision-recall trade-off and is highly fragile under attentional load. Even with enhanced reasoning, models may overfit to an 'always-remind' heuristic, indicating a lack of nuanced understanding. Furthermore, PM accuracy drops sharply as context length increases, unlike RM which saturates at around 100K tokens. This suggests that current LLMs struggle with maintaining proactive recall in extended conversations or workflows.
An intriguing observation is that PM may serve as a behavioral probe for spare reasoning capacity. The study shows that successful trajectories yield higher PM accuracy than failed ones, even when context length is held constant. This implies that PM performance could be used to monitor how much cognitive bandwidth remains available for complex tasks, offering a new lens into model efficiency and resource allocation.
Key insight: Prospective memory in LLMs is significantly harder than retrospective memory, with performance degrading under context length and concurrent user requests, suggesting a need for new architectural approaches to maintain attentional robustness.
ReasoningLens: Hierarchical Visualization and Diagnostic Auditing for Large Reasoning Models
Sun, Le arXiv: 2606.23404
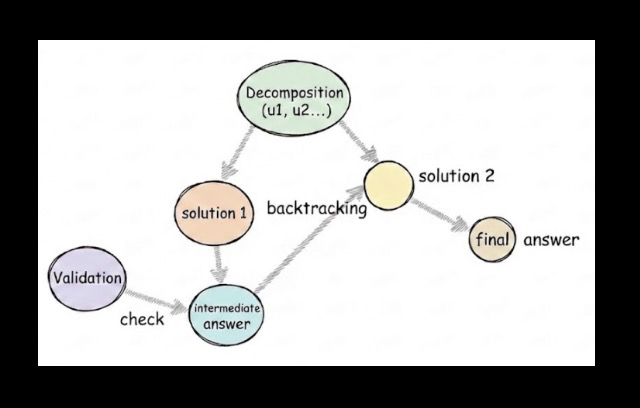
ReasoningLens addresses the transparency burden created by long Chain-of-Thought traces in large reasoning models. It introduces a framework that structures these traces into interactive hierarchies, separating high-level strategy from low-level execution. This modular approach allows for more granular analysis and better understanding of how models arrive at conclusions.
The system leverages an agentic auditor to perform automated error detection and tool-augmented verification, enhancing the ability to identify logical flaws or inconsistencies in reasoning chains. Additionally, it synthesizes systemic reasoning profiles that reveal model-specific blind spots, providing actionable insights for optimization and debugging.
By transforming unstructured procedural text into structured, interpretable insights, ReasoningLens offers a practical foundation for interpreting, debugging, and optimizing next-generation reasoning-centric AI systems. This is particularly valuable as models become increasingly complex and opaque, making interpretability essential for trust and reliability.
Key insight: Hierarchical visualization and diagnostic auditing of reasoning chains can significantly improve interpretability, debugging, and optimization of complex LLM reasoning processes.
Tapered Language Models
Courville, Aaron arXiv: 2606.23670

Tapered Language Models (TLMs) propose a novel architectural principle where parameter capacity is allocated non-uniformly across layers, with more resources given to earlier layers and less to later ones. This challenges the conventional uniform allocation seen in modern transformers and other language models.
The study demonstrates that under a fixed budget, allocating more capacity to earlier layers improves perplexity and downstream performance compared to uniform-width baselines. This finding is consistent across multiple architectures (Transformer, Gated Attention, Hope-attention, Titans) and model scales, suggesting the principle is broadly applicable and effective.
This approach provides a simple yet powerful method for optimizing language models without increasing computational overhead or parameter count. It represents a free lever in model design that can be leveraged to enhance performance while maintaining efficiency—a critical consideration as LLMs continue to scale.
Key insight: Parameter allocation across model layers should be depth-aware, with more capacity assigned to earlier layers to improve performance without increasing total parameters or compute.
MAS-PromptBench: When Does Prompt Optimization Improve Multi-Agent LLM Systems?
Shi, Laixi arXiv: 2606.23664

MAS-PromptBench systematically evaluates prompt optimization techniques across diverse multi-agent setups, varying tasks, workflows, communication protocols, and team sizes. The study reveals that while prompt optimization has potential to unlock substantial improvements in MAS performance, its benefits are not universal or consistent across all configurations.
The research identifies key factors influencing the success of prompt optimization, including task type, workflow structure, and agent interaction patterns. It also highlights challenges such as exponentially growing search spaces, which complicate optimization efforts in complex MAS setups. These findings underscore the need for tailored approaches to prompt engineering in multi-agent contexts.
Despite these challenges, the results show that effective prompt optimization can lead to meaningful gains in system-level performance. This suggests that while not a silver bullet, prompt tuning remains a valuable tool for improving coordination and output quality in multi-agent LLM systems, especially when carefully adapted to specific use cases.
Key insight: Prompt optimization in multi-agent systems can yield significant performance gains, but its effectiveness varies widely depending on system configuration and task complexity.
Muown Implicitly Performs Angular Step-size Decay
He, Niao arXiv: 2606.23637

The paper provides a theoretical explanation for Muown’s empirical success by showing that its directional update is equivalent to a Riemannian step on normalized directions. This insight reveals how the optimizer implicitly manages angular step sizes, contributing to its stability in pre-training Transformers.
By making the angular step size explicit and decoupling it from radial magnitude updates, the proposed AngularMuown method improves upon Muown’s performance. This approach allows for schedulable angular multipliers, offering more control over optimization dynamics and enhancing scalability across different model sizes.
The results confirm that AngularMuown outperforms Muown on various benchmarks, including small and large-scale models like Qwen2-0.5B and 1.1B parameter mixture-of-experts models. This advancement not only improves training efficiency but also demonstrates the value of theoretical analysis in guiding practical optimization improvements.
Key insight: Muown's directional update mechanism implicitly performs angular step-size decay, which can be made explicit to improve optimization stability and scalability.
DiT-Reward: Generative Representations for Text-to-Image Reward Modeling
Duan, Nan arXiv: 2606.23626
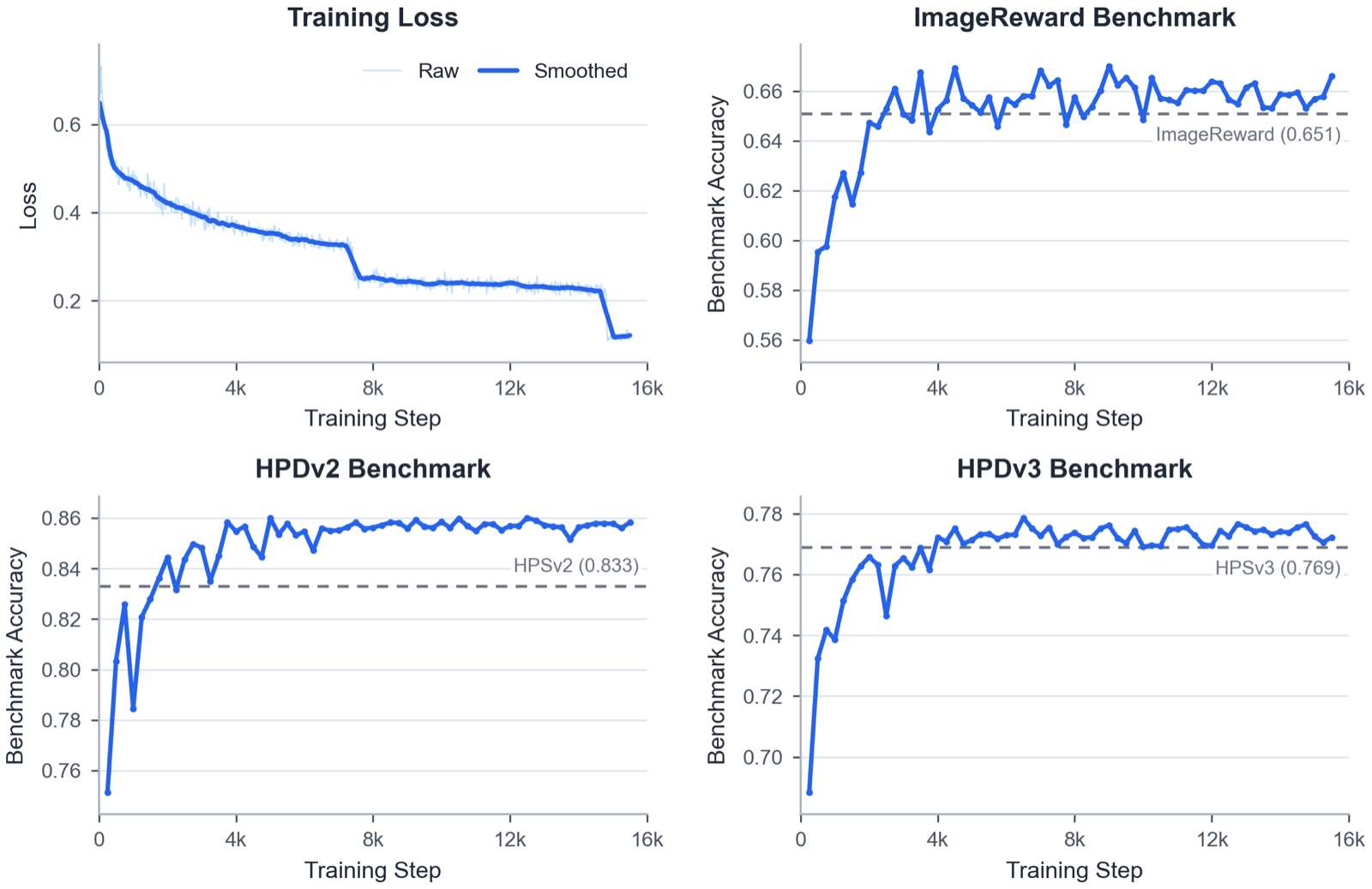
The paper introduces DiT-Reward, a method that transforms pretrained text-to-image Diffusion Transformers into effective reward models by leveraging near-clean image latents and aggregating text-conditioned representations across transformer layers. This approach demonstrates that generative models trained for image synthesis can provide rich, transferable representations suitable for downstream tasks such as reward modeling.
Key findings show that DiT-Reward outperforms HPSv3 on multiple preference benchmarks, achieving 85.6% on HPDv2 and 77.6% on HPDv3, with particularly strong gains in realism when used to optimize Stable Diffusion 3.5 Large with Flow-GRPO. Notably, even with a frozen generative backbone, a lightweight learned head can still extract meaningful preference predictions, indicating robustness and adaptability.
The method also exhibits positive scaling with generative backbone capacity and achieves a 1.65x inference speedup over HPSv3 while maintaining comparable peak memory usage. These results suggest that DiT-Reward not only improves performance but also enhances efficiency, making it a promising candidate for real-world deployment in image generation systems where both quality and speed are critical.
Key insight: Pretrained text-to-image Diffusion Transformers can be effectively repurposed as reward models for image generation, achieving superior performance over existing methods like HPSv3 while offering faster inference and improved scalability.
Discovering Latent Groups for Robust Classification
Michalski, Vincent arXiv: 2606.23609
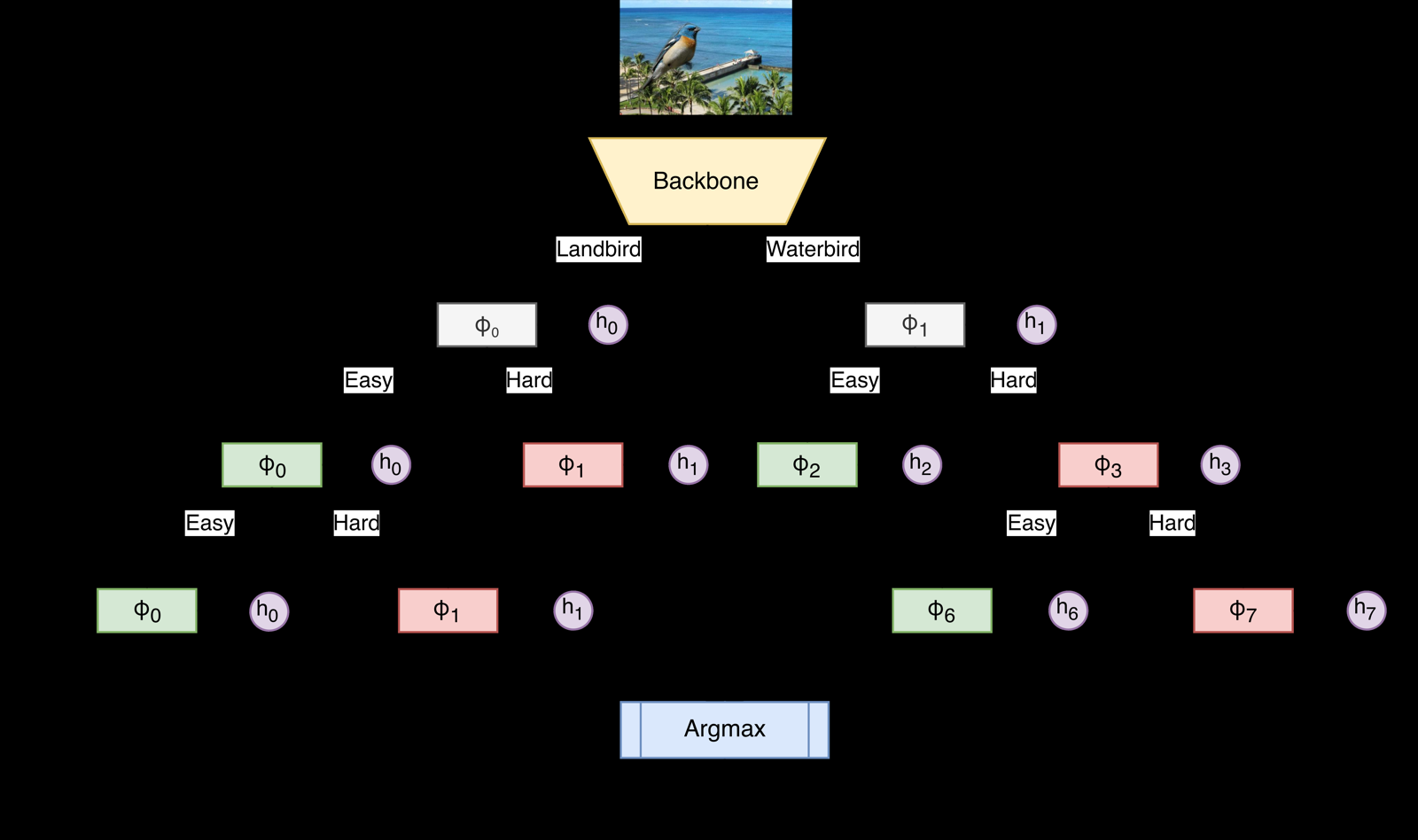
This work proposes Neural Classification Trees (NCT), which address the issue of spurious correlations in machine learning models that often fail on underrepresented subgroups. Unlike existing methods that adjust network parameters or use pseudo-group labels, NCT encodes subgroup structure within its tree-shaped architecture, allowing for transparent and interpretable routing of samples to 'easy' or 'hard' nodes based on prediction correctness.
The framework uses iterative routing as pseudo-labels for the next iteration, effectively disentangling conflicting subgroups. Experiments across five benchmarks show that NCT consistently isolates minority subgroups, providing a clear mapping between model architecture and data's latent group structure. This approach yields competitive robustness with state-of-the-art methods while offering strong interpretability.
By routing samples through the tree based on prediction outcomes, NCT provides insights into how different parts of the data are handled by the model, which is particularly valuable in applications where fairness and explainability are crucial. The method's ability to operate without subgroup annotations makes it highly practical for real-world deployment.
Key insight: Neural Classification Trees (NCT) offer a novel approach to robust classification by encoding subgroup structures directly into the model architecture, enabling disentanglement of conflicting subgroups without requiring explicit subgroup supervision.
Scaling Linear Mode Connectivity and Merging to Billion Parameter Pretrained Transformers
Shen, Zhiqiang arXiv: 2606.23607
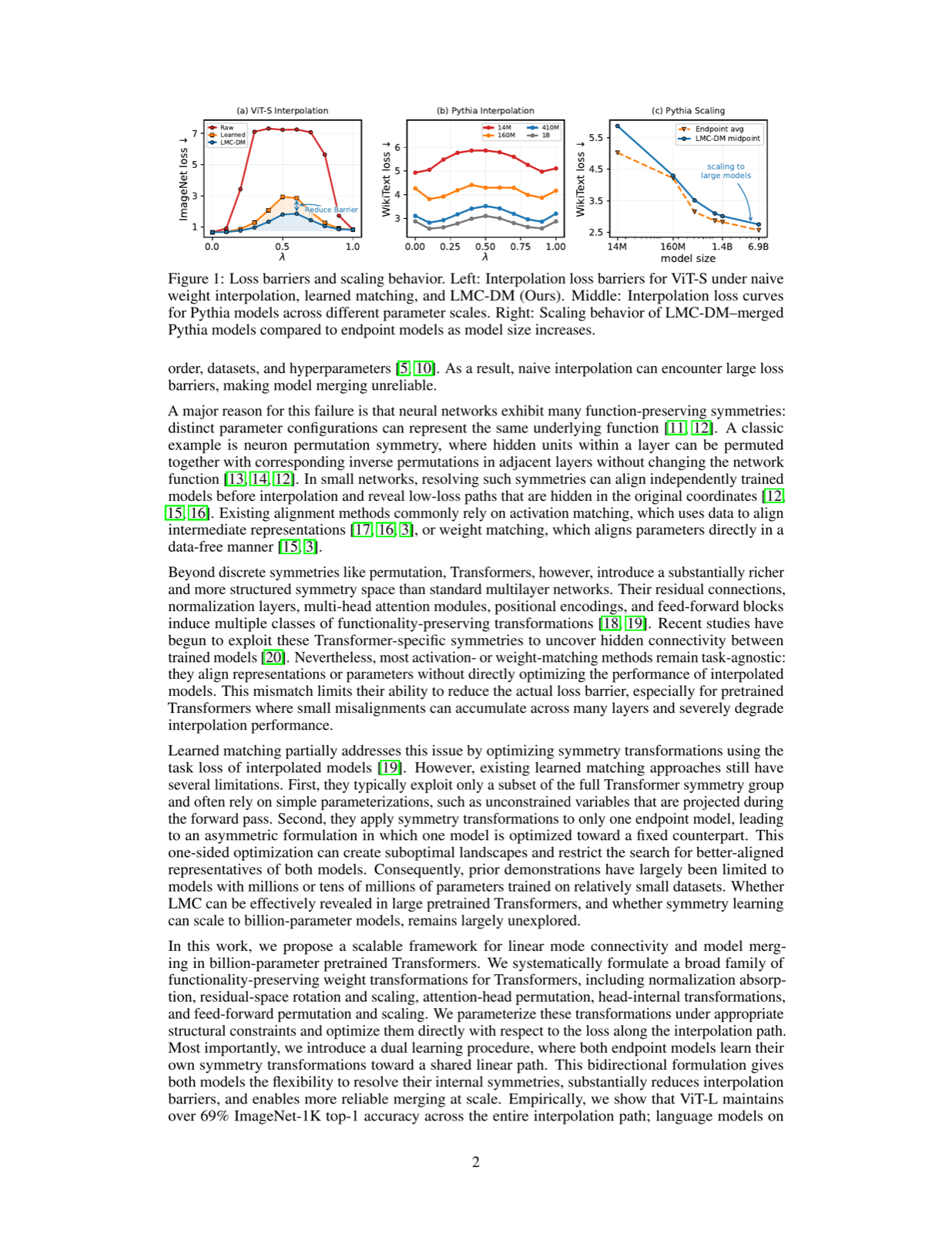
The paper presents a novel framework that scales linear mode connectivity (LMC) to billion-parameter pretrained transformers by applying functionality-preserving weight transformations to align functionally equivalent solutions. It introduces a dual learning procedure where both models jointly learn their transformations toward a shared interpolation path, significantly reducing interpolation barriers.
Empirical results show near-zero loss barriers on WikiText for language models with medium-sized parameters and maintain above 69% ImageNet top-1 accuracy in vision tasks throughout the interpolation path. These findings indicate that properly resolving parameter symmetries allows large transformers to be connected and merged through simple linear paths, improving interpolation performance.
This advancement is particularly significant for model merging and ensemble methods in large-scale AI systems, where traditional approaches often struggle with scalability and effectiveness. The ability to merge models reliably at scale opens new possibilities for efficient deployment and optimization of massive language and vision models.
Key insight: A scalable framework for linear mode connectivity and merging of billion-parameter transformers is developed, enabling reliable interpolation and merging across large-scale architectures through bidirectional optimization.
MORL-A2C: Multi-Objective Reinforcement Learning Reranker for Optimizing Healthiness in MOPI-HFRS
Zolla, Joshua arXiv: 2606.23603
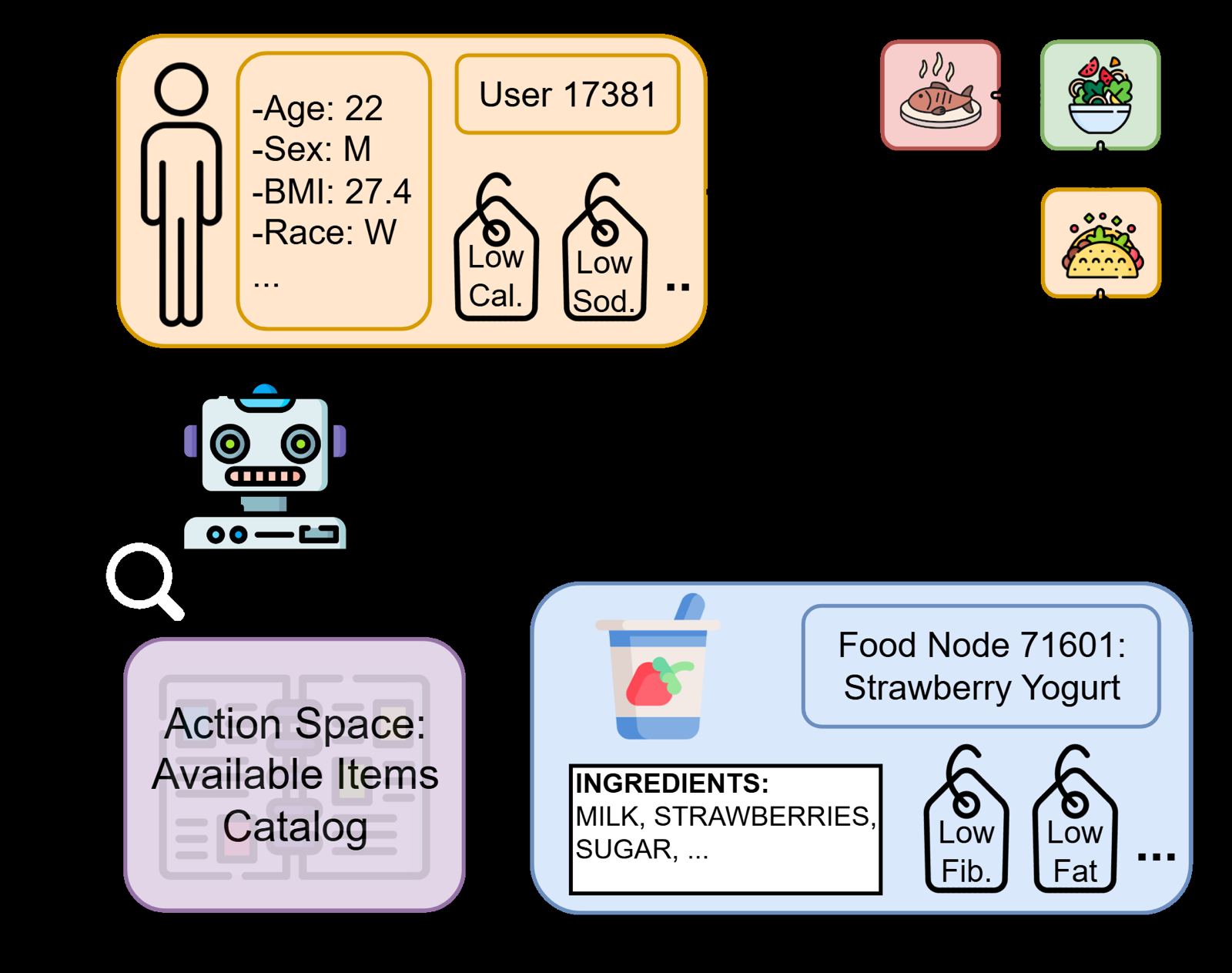
This work introduces MORL-A2C, a multi-objective reinforcement learning approach for optimizing dietary recommendations in the MOPI-HFRS framework. Unlike previous methods that rely on static tradeoff solutions, MORL-A2C formulates recommendation as a K-step reranking problem using Advantage Actor-Critic with scalarized relevance/health rewards.
The policy is warm-started via behavior cloning against a dot-product ranker derived from frozen GNN embeddings, leveraging pre-trained representations to improve convergence and performance. Results show that MORL-A2C achieves a substantial improvement in health alignment (H-Score@20: 46.05% to 69.57%) at the cost of modestly reduced ranking quality, demonstrating effective navigation of the health-preference trade-off.
This approach validates that policy-driven sequential optimization can effectively balance competing objectives in multi-objective recommendation systems, particularly in domains like healthcare where balancing user preferences with health outcomes is critical. The method's ability to leverage frozen embeddings also suggests potential for efficient fine-tuning and adaptation.
Key insight: MORL-A2C extends MOPI-HFRS by introducing sequential decision-making through Advantage Actor-Critic, enabling better optimization of health-preference trade-offs in food recommendation systems.
Quantifying the Agreement Between Data-Influence and Data-Similarity to Understand LLM Behavior
Khan, Mohammad Emtiyaz arXiv: 2606.23591

The study quantifies the relationship between data-similarity and data-influence measures for understanding LLM behavior. It finds that while these two measures agree significantly, there is an asymmetry: documents ranked highly by data-similarity are assigned more consistent ranks by data-influence than vice versa.
This asymmetry is validated across multiple models (OLMo2-1B, Qwen3-1.7B, LlaMa3.2-1B, Gemma3-1B, and GPT2), suggesting a generalizable pattern in how LLMs process training data. The finding enables a cost-accuracy trade-off strategy where the expensive data-influence measure can be used to refine results from the cheaper data-similarity approach.
This insight is particularly valuable for interpretability and debugging of large language models, offering practical methods for tracing model outputs back to training data without incurring prohibitive computational costs. It also provides a foundation for more efficient monitoring and analysis of model behavior.
Key insight: Data-similarity and data-influence measures show significant agreement, with a notable asymmetry where top documents from data-similarity are more consistently ranked by data-influence, enabling cost-effective refinement strategies.
Decentralized Autonomous Traffic Management through Corridor Networks
Balakrishnan, Hamsa arXiv: 2606.23585

This paper explores decentralized traffic management for autonomous aircraft using a multi-agent reinforcement learning (MARL) approach. The key innovation lies in training policies in simple single-corridor environments and then applying them zero-shot to increasingly complex multi-corridor networks with merges, splits, and varying traffic densities.
Experimental results demonstrate that the learned behaviors transfer effectively across different network geometries and vehicle performance characteristics, maintaining desirable traffic flows through corridor networks without requiring centralized coordination or retraining. Metrics such as conformance to boundaries, completion rates, average speeds, and inter-aircraft separation are all positively impacted.
This approach addresses a critical scalability challenge in autonomous systems, particularly for emerging domains like Advanced Air Mobility (AAM) where centralized control becomes impractical at scale. The ability to achieve decentralized coordination with minimal overhead suggests promising applications for large-scale autonomous systems beyond aviation.
Key insight: Decentralized multi-agent reinforcement learning policies trained in single-corridor settings generalize well to complex multi-corridor networks, enabling scalable autonomous traffic management without centralized coordination.
GARIP: A Running-Average Moving Reference for Last-Iterate Self-Play in Two-Player Zero-Sum Games
Savcı, Can arXiv: 2606.22688
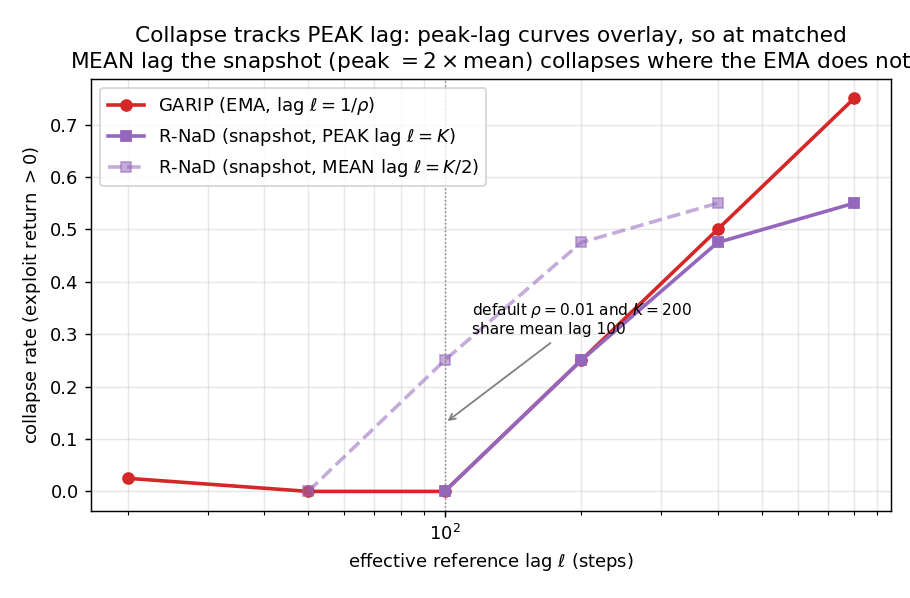
The paper introduces GARIP (Gradient Averaging with Running Average Reference), which uses a running average of the policy as a reference for regularization in two-player zero-sum games. This approach uniquely minimizes peak lag among causal convex averages, leading to improved convergence properties and robustness.
GARIP demonstrates local last-iterate convergence at constant anchor strength and shows superior performance compared to fixed references and periodic snapshots (R-NaD) across various game types including matrix games, Coin Game, and board games like Connect Four/Othello. The method achieves statistically indistinguishable collapse rates while offering better hyperparameter defaults.
This work contributes to the theoretical understanding of self-play dynamics in game theory and provides practical improvements for training stable multi-agent systems. The running average reference's ability to maintain consistent performance across different parameterizations makes it a strong candidate for general-purpose applications in reinforcement learning.
Key insight: GARIP, a method using running average as reference in self-play, uniquely minimizes peak lag among causal convex averages and achieves better convergence and robustness compared to fixed or snapshot-based references.
Cohort Organized Learning: Clustering Through Agreement
Monzani, Maria Elena arXiv: 2606.21743
Cohort Organized Learning (CoOL) presents a novel clustering approach that operates without explicit distance or similarity computations, instead relying on neural networks to estimate clusters through agreement mechanisms. This method leverages expectation maximization to derive gradients for training and provides tools for monitoring convergence and evaluating clusters.
The technique is demonstrated on both vector data and images, showing its versatility across different data types. CoOL's ability to cluster any compatible data makes it a flexible tool for various machine learning tasks where traditional clustering methods may be insufficient or computationally expensive.
While the paper discusses limitations and future prospects, the core innovation lies in its ability to perform unsupervised clustering through neural network-based agreement rather than distance metrics. This approach opens new avenues for clustering in complex data domains where standard methods struggle.
Key insight: Cohort Organized Learning (CoOL) enables clustering without explicit distance or similarity computations by using neural networks to estimate clusters through agreement mechanisms.
Monitoring Diameters of Causal Communication Graph with Spatio-Temporal Logic
Mover, Sergio arXiv: 2606.21558
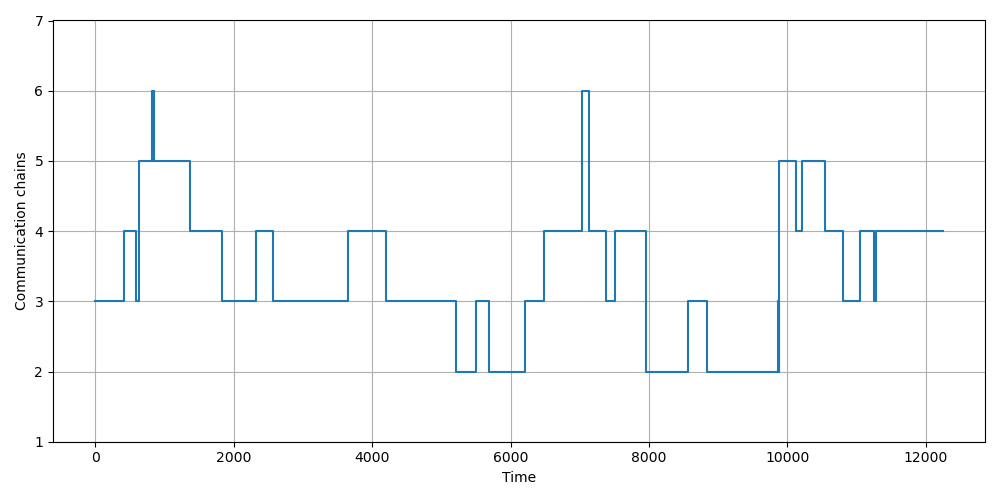
This paper extends MuTGL logic with a new 'space horizon' operator to better capture spatio-temporal properties in multi-agent systems. The addition allows bounding communication chain distances, which is crucial for analyzing reachability within specific distance bounds and tracking communication graph diameters.
The enhanced logic supports deeper entanglement of spatial and temporal properties, enabling more precise verification of decentralized monitoring and distributed protocols. The paper provides a centralized offline monitoring algorithm and illustrates its application on simulations of Consensus-Based Bundle Algorithms used in task allocation.
This advancement is particularly valuable for verifying complex distributed systems where communication graph topology directly impacts performance and algorithmic complexity. The ability to monitor diameter-related properties through formal logic provides a rigorous foundation for ensuring system correctness in decentralized environments.
Key insight: An extension of MuTGL logic with a space horizon operator enables monitoring of causal communication graph diameters, enhancing expressiveness for decentralized systems and distributed protocols.
Artificial collectives of specialists and generalists excel at different tasks
Gao, H. Oliver arXiv: 2606.20877
The study systematically characterizes how agent interpretive abilities, rationality bounds, and task qualities interact to shape collective performance. It finds that collectives of specialists (narrow interpretive abilities) correspond to sparse, centralized networks, while generalists (broad interpretive abilities) form dense, decentralized ones.
Performance analysis reveals that while interpretive network properties have small average effects (0.07 standard deviations), they can be 4.5 times larger for specific task qualities (0.33 sd), reaching up to 1.84 sd in certain cases. Generalists perform better on tasks involving generation, choice, and coordination, whereas specialists with a few generalist mediators excel at negotiation.
Rationality bounds moderate these relationships: at loose bounds, specialists outperform through effective sampling; at tight bounds, generalists excel via better gradient estimation. A fundamental trade-off emerges between performance and convergence speed at moderate bounds, suggesting that multi-agent design should match interpretive networks to task demands and computational limits.
Key insight: Collectives of specialists and generalists exhibit distinct performance characteristics on different tasks, with specialists excelling in negotiation and generalists in generation and coordination, suggesting a fundamental trade-off between performance and convergence speed.
Empowering Economic Simulation Through Situation-Aware Llm-Driven Generative System
Chen, Mu arXiv: 2606.20720

The paper proposes SAMAS (Situation-Aware Multi-agent Simulation), which models individual agents using LLMs embedded with macroeconomic understanding and experiences from previous simulation steps. This approach moves beyond traditional TOP-DOWN economic modeling by incorporating micro-level dynamics for generating macroeconomic phenomena.
SAMAS leverages reinforcement learning to improve decision-making through tailored reward signals, while also incorporating LLM-driven role-playing for perception and human-like decision-making. The system jointly models both macro-level structural patterns and micro-level dynamic behaviors, resulting in superior performance in volatility realism and turning point prediction compared to existing ABM systems.
This work represents a significant step toward more realistic economic simulations that can capture complex societal structures and interactions. By embedding rich macroeconomic understanding within LLMs and learning from past trajectories, SAMAS enables more accurate modeling of economic phenomena, particularly relevant for policy analysis and forecasting.
Key insight: SAMAS, an LLM-driven generative system for economic simulation, models individual agents with rich macroeconomic understanding and economic trajectories, achieving superior performance in volatility realism and turning point prediction.
AI Model Releases

PP-OCRv6 on Hugging Face: 50-Language OCR from 1.5M to 34.5M Parameters
PaddlePaddle released PP-OCRv6, a multilingual OCR model family with three tiers (tiny, small, medium) supporting 50 languages including Chinese, Japanese, and 46 Latin-script languages. The models scale from 1.5M to 34.5M parameters with performance improvements over previous versions: PP-OCRv6_medium achieves 86.2% detection Hmean and 83.2% recognition accuracy on in-house benchmarks. The model family supports flexible deployment options including PaddlePaddle, Transformers, or ONNX Runtime backends.
Why it matters: This advancement provides practical OCR solutions for multilingual applications with improved accuracy while maintaining lightweight deployment options, supporting real-world document processing and industrial use cases.
Codex-maxxing for long-running work
Source: openai.com.

The running list: major tech layoffs in 2026 where employers cited AI | TechCrunch
Source: TechCrunch.