OpenAI introduces Record & Replay for Codex to enhance development workflows, while new tools like Recall provide durable memory for AI agents. Meanwhile, political tensions around AI regulation continue to shape the industry landscape.
OpenAI's latest Codex update brings Record & Replay functionality, enabling developers to capture and replay API interactions for improved debugging and testing. Concurrently, the open-source Recall tool offers Claude Code durable memory capabilities that persist across sessions without requiring re-explanation, significantly reducing token waste. These developments come amid heightened political scrutiny of AI, exemplified by the Trump administration's crackdown on Anthropic's models, which has sparked debate about national security implications and global AI policy. Additionally, academic research advances agent architectures with long-lifecycle training through reinforcement learning, memory governance benchmarks for multi-principal systems, and efficient verifiable reasoning in compact language models.
Research Papers
Connect the Dots: Training LLMs for Long-Lifecycle Agents with Cross-Domain Generalization Via Reinforcement Learning
Zhou, Jingren arXiv: 2606.20002

The paper introduces a novel framework for training LLMs to achieve a critical meta-capability known as 'Connect the Dots' (CoD), which is essential for long-lifecycle agents. This capability allows an agent to continuously learn from its experiences, update its understanding of the environment, and improve performance on future tasks based on that updated context. The approach leverages end-to-end reinforcement learning with interleaved solve-task and update-context episodes, offering a structured method for training agents that can evolve over time.
The authors present a GRPO-style RL algorithm with fine-grained credit assignment as part of their CoD framework, along with tailored tasks and environments designed specifically to elicit this meta-capability. Empirical results validate the effectiveness of end-to-end RL in the CoD setting, showing promising capabilities for out-of-distribution generalization across domains and even from CoD to Ralph-loop settings. This work bridges prior research lines and opens new avenues for advancing LLMs and AI agents.
This development is particularly relevant for agent architectures that must operate in complex, evolving environments where static models are insufficient. The framework's emphasis on iterative self-updating context suggests a path toward more autonomous and adaptive systems, aligning with the broader focus on multi-agent systems and long-term learning capabilities.
Key insight: LLMs can be trained to develop a meta-capability called 'Connect the Dots' (CoD), enabling them to learn and adapt over long sequences of tasks in dynamic environments through reinforcement learning.
GateMem: Benchmarking Memory Governance in Multi-Principal Shared-Memory Agents
Yan, Shuicheng arXiv: 2606.18829

GateMem presents a benchmark for evaluating memory governance in multi-principal shared-memory agents—a critical area often overlooked in existing LLM agent research. The benchmark spans domains like healthcare, office environments, education, and households, testing utility, access control, and active forgetting under various roles and relationships. It highlights the complexity of managing shared memory where multiple users interact with a common pool.
The findings reveal that no current method simultaneously achieves strong utility, robust access control, and reliable forgetting. Long-context prompting offers the best governance score but at high token cost, while retrieval-based or external-memory methods reduce costs but still leak unauthorized information. This underscores a significant gap in memory management for real-world shared assistant deployments.
This work directly addresses the 'memory & tool use' focus area by emphasizing the need for sophisticated memory governance in multi-agent systems. It also touches on agent architectures and reasoning, as effective memory management is crucial for maintaining context and enabling coherent decision-making in complex environments.
Key insight: Shared memory in multi-principal agents requires governance mechanisms to ensure access control, utility, and reliable forgetting, which current methods struggle to balance effectively.
VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Zhang, Junlin arXiv: 2606.16140

VibeThinker-3B demonstrates that verifiable reasoning—a key component of reliable AI systems—can be effectively implemented in compact models with only 3 billion parameters. By leveraging a Spectrum-to-Signal post-training paradigm and optimizing through curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation, the model achieves performance comparable to much larger flagship models.
The results show that VibeThinker-3B scores highly on demanding benchmarks such as AIME26 (94.3), LiveCodeBench v6 (80.2 Pass@1), and LeetCode contests (96.1% acceptance rate). These findings support the Parametric Compression-Coverage Hypothesis, suggesting that verifiable reasoning can be compressed into compact cores while broader knowledge and general-purpose competence require extensive parameter coverage.
This advancement is significant for LLM efficiency and agent architectures, especially in resource-constrained environments. It suggests a complementary path toward frontier-level performance using compact models, which could revolutionize deployment strategies for reasoning-intensive applications.
Key insight: Verifiable reasoning can be achieved in small language models through post-training techniques, challenging the assumption that large-scale models are required for high-level reasoning tasks.
Think Again or Think Longer? Selective Verification for Budget-Aware Reasoning
Zhang, Liqing arXiv: 2606.19808
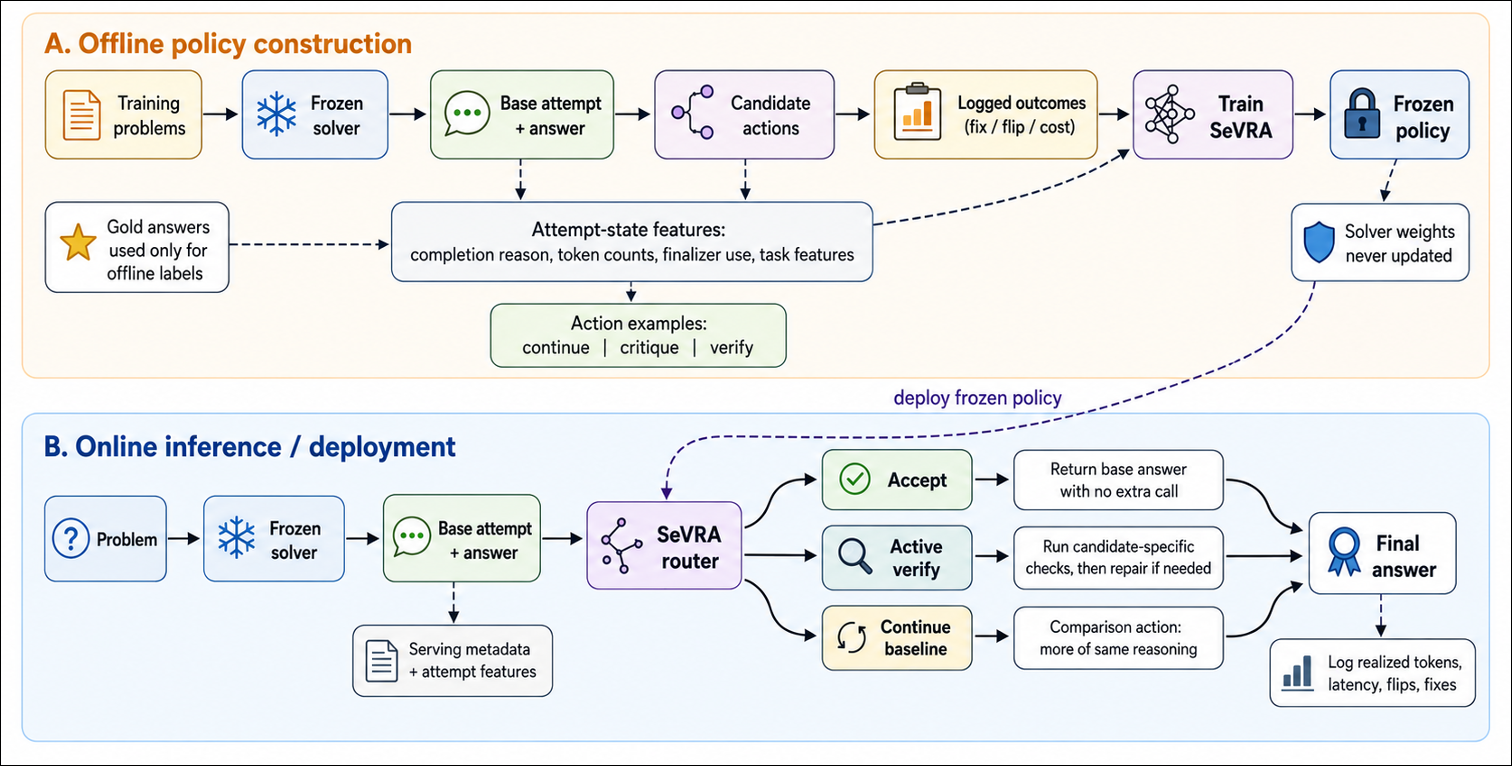
The paper introduces Sevra, a serving-layer controller that makes intelligent decisions about when to verify an answer versus preserving the frozen solver's output. This approach treats test-time reasoning as a deployment allocation problem rather than a new-verifier challenge. By training recoverability-aware gates from attempt states, Sevra reduces unnecessary verification tokens and harmful flips while maintaining high accuracy.
Experiments show that selective verification improves accuracy on several benchmarks (e.g., 76.3% vs. 75.5% for always verifying) while reducing post-generation tokens by 26.8%. However, even longer initial solves can outperform selective recovery in terms of token efficiency, indicating that the optimal strategy depends on specific use cases and constraints.
This work contributes to reasoning & planning and LLM efficiency by providing a practical framework for managing computational budgets during inference. It also has implications for agent architectures where resource-aware decision-making is crucial, particularly in real-time or cost-sensitive applications.
Key insight: Selective verification allows for efficient allocation of reasoning resources by deciding whether to preserve initial answers or invoke active verification, balancing accuracy and computational cost.
AI Model Releases

Record & Replay – Codex | OpenAI Developers
 .
.
Agent Frameworks & SDKs
Recall is a new tool that provides Claude Code with durable memory, allowing it to retain information across sessions without re-explaining projects. The tool operates entirely offline and is designed to stop wasting tokens on repeated explanations. It features deterministic summaries and a benchmark harness for quality control. The project has gained significant attention with 167 stars on GitHub and recent updates including cross-backend determinism fixes.
Why it matters: This represents a significant advancement in AI agent memory management, addressing one of the core limitations of current AI assistants that must re-explain context repeatedly. By enabling durable memory, Recall could dramatically improve developer productivity and reduce token costs when working with large codebases.
AI Tooling

When the Trump administration cracks down on Anthropic, who benefits? | TechCrunch
The Trump administration has ordered Anthropic to take its two newest AI models offline due to export control concerns, citing national security risks. The move follows allegations that Amazon researchers found ways to bypass Fable 5's guardrails, prompting a swift government response. Cybersecurity experts have signed an open letter protesting the order, arguing it's dangerous to remove advanced cybersecurity capabilities from U.S. defenders. The crackdown has sparked debate about AI policy and digital sovereignty.
Why it matters: This incident highlights the growing political tensions around AI development and regulation, with potential implications for the entire AI ecosystem. It demonstrates how government actions can disrupt AI innovation and raises questions about whether such measures benefit competitors or create a more fragmented global AI landscape.