New AI frameworks are enabling more sophisticated agent collaboration and workflow automation, while research advances in calibration and streaming techniques promise to make AI systems more reliable and responsive. These developments come as AI models grapple with distribution shifts and privacy concerns.
This week's research digest highlights significant progress in AI agent development with the introduction of WUPHF, a framework for creating collaborative AI teams that work over shared context. Concurrently, researchers are addressing critical challenges in model reliability through advances in mixture-of-experts calibration under distribution shifts and the development of more interpretable deep learning models for clinical applications. Additionally, streaming retrieval-augmented generation techniques are being refined to better understand when and how latency improvements can be achieved, while new approaches to privacy measurement offer more nuanced control over data protection. These developments collectively point toward more robust, adaptable, and trustworthy AI systems that can operate effectively across diverse domains and use cases.
Research Papers
Toward Calibrated Mixture-of-Experts Under Distribution Shift
Liu, Anqi arXiv: 2606.20544

This paper addresses a critical issue in Mixture-of-Experts (MoE) models: how calibration behaves under distribution shifts. Calibration ensures that a model's predictive uncertainty aligns with empirical outcomes, which is essential for trustworthiness. The authors demonstrate that while expert-level calibration alone suffices to maintain overall model calibration in hard-routed MoE systems, it fails for soft-routed variants. This distinction is crucial for AI agent development, as routing mechanisms determine how different parts of a model are activated under varying conditions.
To overcome the limitations of soft-routed models, the authors propose an adversarial reweighting technique that penalizes calibration errors in the routed aggregate during distribution shifts. This method improves both accuracy and calibration across various tasks and data subsets. The approach is particularly relevant for multi-agent systems where agents may encounter diverse environmental conditions or inputs, necessitating robust calibration mechanisms to ensure reliable decision-making.
The implications extend beyond MoE models to broader agent architectures that rely on dynamic routing or ensemble methods. By ensuring that calibration is maintained even under distribution shifts, this work contributes to building more trustworthy and robust AI systems. The proposed adversarial reweighting can be integrated into existing frameworks, offering a practical solution for improving model reliability in real-world deployment scenarios.
Key insight: Expert-level calibration is sufficient for hard-routed MoE models under distribution shift, but soft-routed models require adversarial reweighting to maintain calibration and improve accuracy.
DeepSWIP: Quotient-WMC Counterfactuals for Neural Probabilistic Logic Programs
He, Fengxiang arXiv: 2606.20526
DeepSWIP introduces a novel single-world counterfactual semantics for DeepProbLog programs, addressing the challenge of causal reasoning in neurosymbolic systems. By reducing neural predicates to ordinary ProbLog choices and applying Single World Intervention Programs (SWIPs), it enables exact counterfactual computation through weighted model counting (WMC). This approach is particularly valuable for AI agents that need to reason about interventions and their consequences, such as in planning or decision-making scenarios.
The method's efficiency gains are significant: experiments show a 2.14x speedup over the DeepTwin construction, which avoids endogenous duplication. Additionally, DeepSWIP improves calibration sensitivity and handles rare-evidence instability more effectively than standard approaches. These improvements make it a promising tool for building agents capable of robust counterfactual reasoning, especially in domains where understanding causal relationships is crucial.
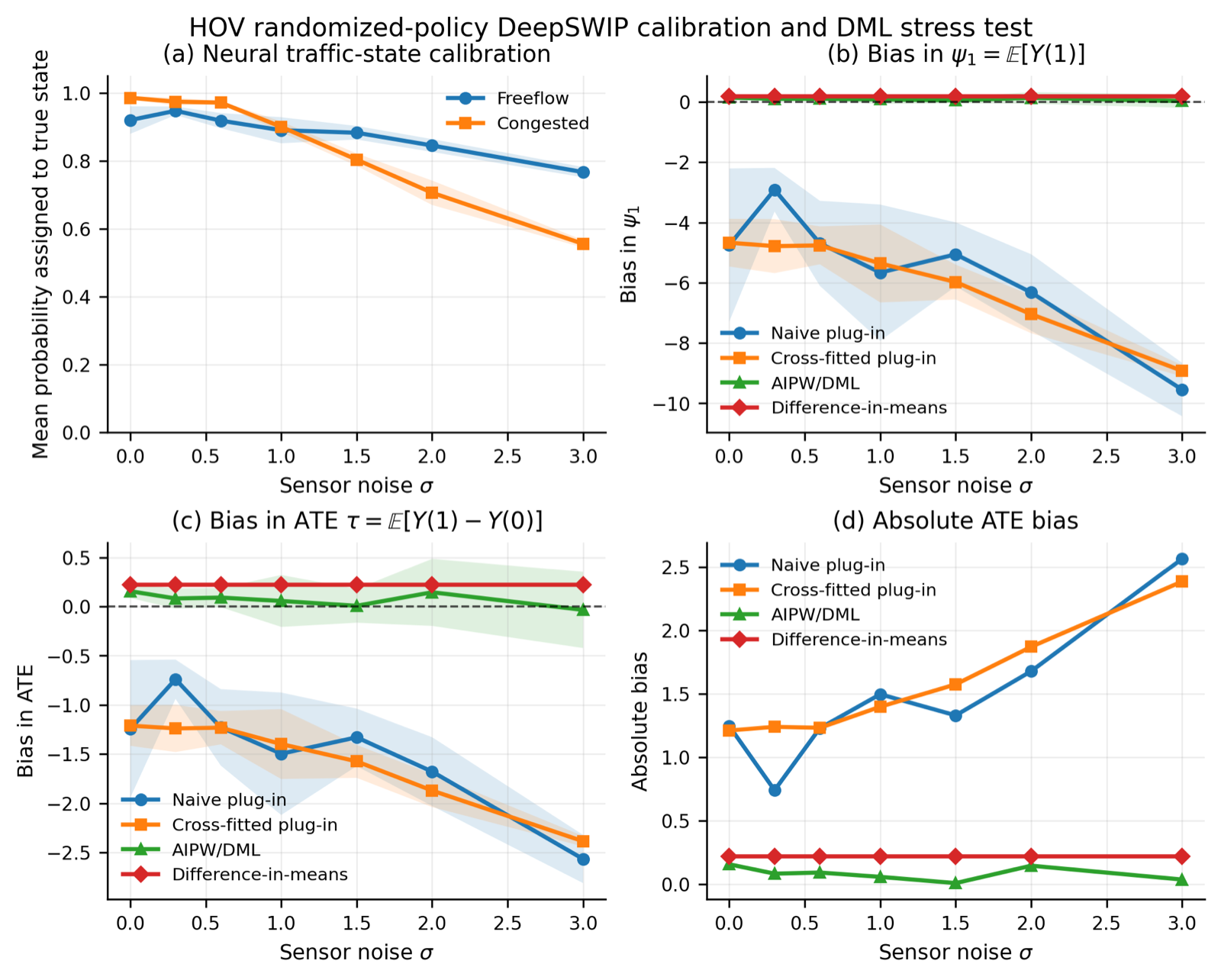
The paper also demonstrates the practical utility of DeepSWIP through experiments on MPI3D and SUMO HOV datasets, showing its ability to reduce bias in plug-in estimates and improve accuracy for population mean and ATE estimands. This makes it a valuable contribution to agent architectures that require both probabilistic reasoning and causal understanding, particularly in complex environments where interventions must be carefully evaluated.
Key insight: DeepSWIP enables exact counterfactual reasoning in neurosymbolic systems by combining neural materialization with weighted model counting, achieving faster inference and better calibration than traditional methods.
FlowEdit: Associative Memory for Lifelong Pronunciation Adaptation in Flow-Matching TTS
Mathur, Nityanand arXiv: 2606.20518
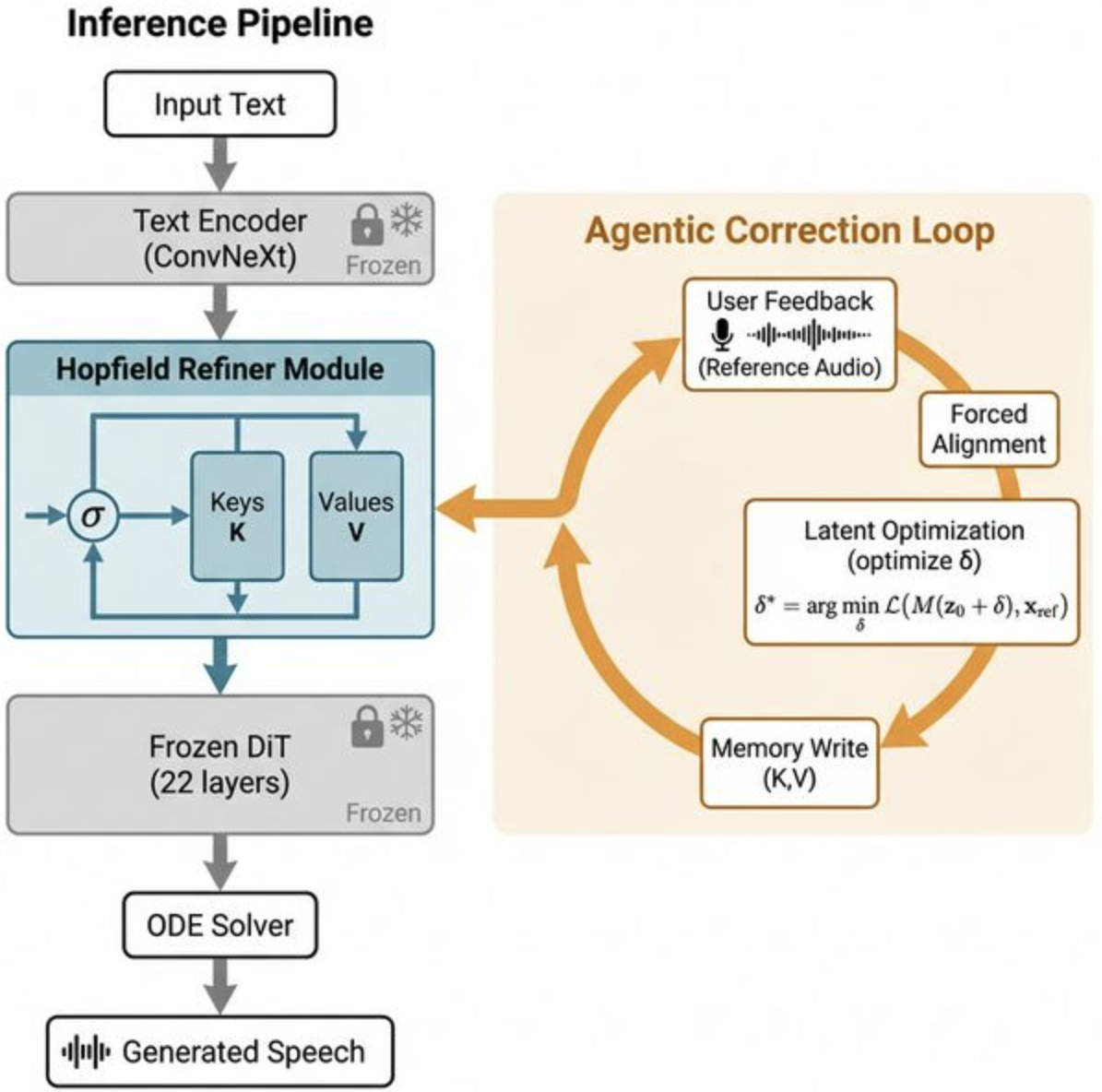
FlowEdit presents a novel approach to lifelong learning in text-to-speech (TTS) systems by leveraging associative memory through a Modern Hopfield Network. This allows the system to store and retrieve pronunciation corrections as latent conditioning edits rather than updating model weights, which is particularly useful for maintaining zero-shot quality while adapting to new data. The method addresses a key limitation of static TTS models that cannot easily incorporate new pronunciations.
The framework's ability to reduce target-word Phoneme Error Rate by 92.7% on a multilingual benchmark highlights its effectiveness in practical applications. By optimizing token-level perturbations in the text embedding space and storing corrections in content-addressable memory, FlowEdit enables fuzzy morphological matching at inference time. This is especially relevant for multi-agent systems that interact with diverse linguistic inputs and need to adapt dynamically.
The rapid correction process—completing in about 15 seconds on a single GPU—makes this approach scalable for real-time applications. As AI agents increasingly engage with natural language interfaces, the ability to adapt pronunciation without full retraining becomes essential. FlowEdit provides a mechanism that supports continuous learning while preserving general speech quality, making it a valuable tool for developing adaptive and robust agent systems.
Key insight: FlowEdit enables lifelong pronunciation adaptation in TTS systems using associative memory, allowing for rapid correction of out-of-vocabulary proper nouns without retraining.
Interpretable Sperm Morphology Classification via Attention-Guided Deep Learning
Johansson, Lars arXiv: 2606.20438
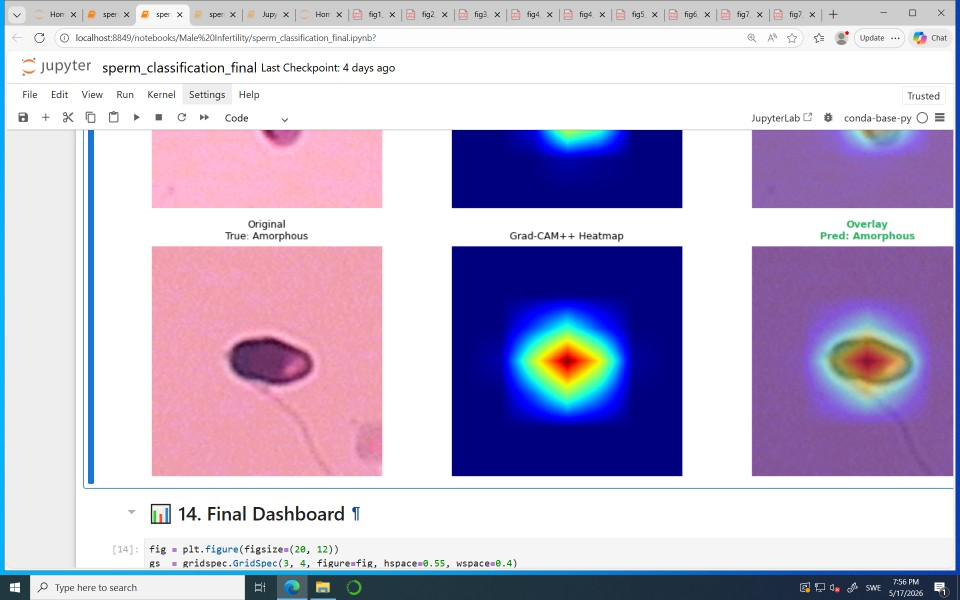
This study introduces an attention-guided deep learning framework for sperm morphology classification that combines a pretrained EfficientNet-B0 with a Convolutional Block Attention Module (CBAM). The approach focuses on key areas of the sperm head, enhancing both accuracy and interpretability—critical factors for clinical adoption. While most deep learning models lack transparency, this method provides visual explanations of decision-making through Grad-CAM++ visualizations.
The model achieves high accuracies on public datasets (90.2% and 93.9% macro F1 scores), outperforming simpler CNNs and standard EfficientNet-B0. This performance gain is particularly important for AI agents in healthcare settings, where interpretability and reliability are paramount. The ability to highlight features influencing decisions supports trust-building and facilitates clinical validation.
The work contributes to the broader goal of developing explainable AI systems that can be integrated into real-world applications. As AI agents become more prevalent in medical diagnostics, frameworks like this one will be essential for ensuring both performance and transparency. The attention mechanism also opens possibilities for further integration with reasoning modules, enhancing agent capabilities in complex diagnostic tasks.
Key insight: Attention-guided deep learning improves both accuracy and interpretability in sperm morphology classification, making it suitable for clinical adoption.
Automating SKILL.md Generation for Computer-Using Agents via Interaction Trajectory Mining
Li, Xiaomin arXiv: 2606.20363
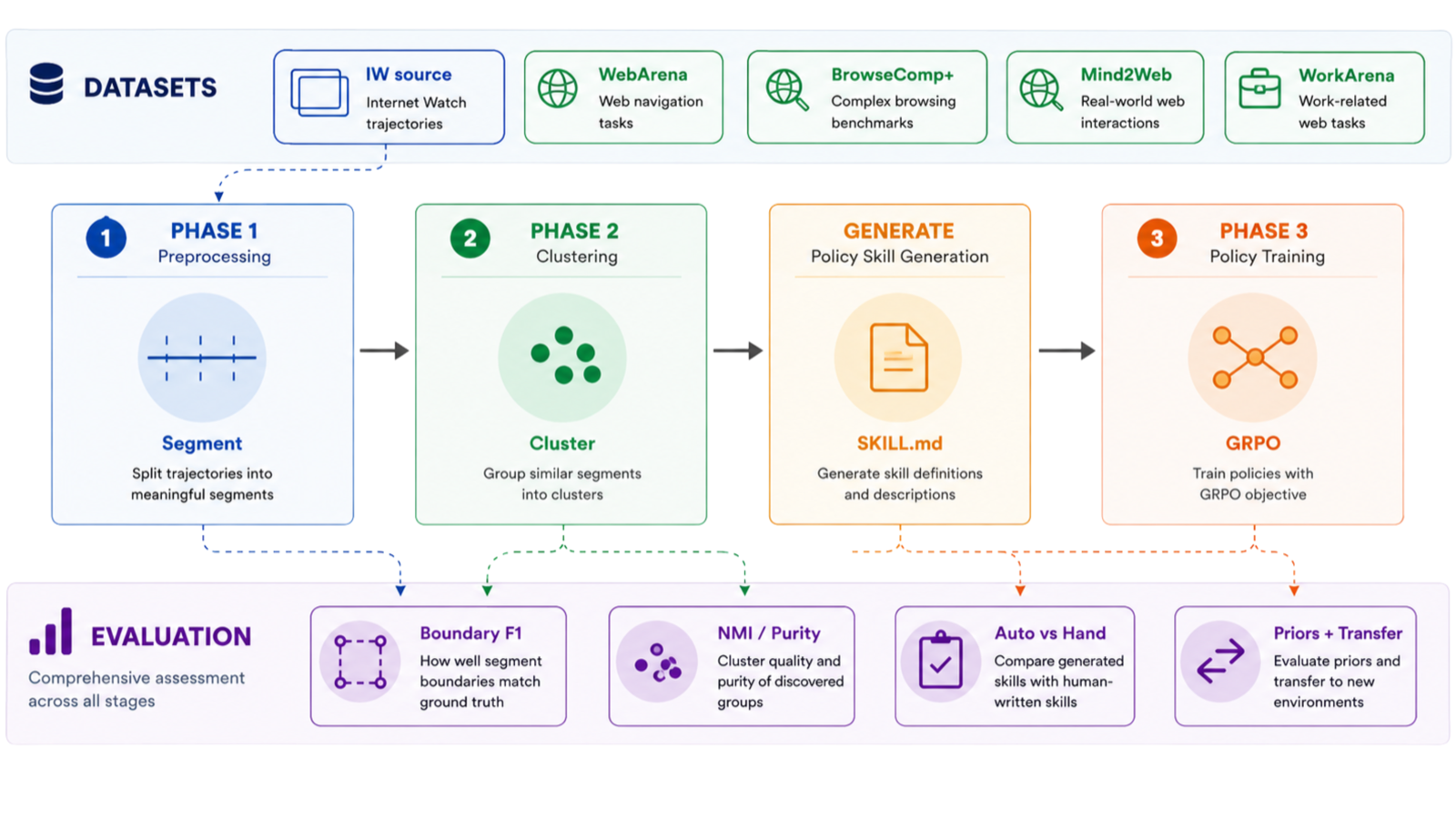
This paper investigates whether explicit skill libraries can be mined from interaction data to improve computer-using agents. The authors propose a three-stage pipeline: GUI trajectory segmentation, clustering into candidate skills, and training a skill-aware policy. While the mined clusters show high purity against labeled benchmarks, they do not translate into significant improvements in downstream policies, indicating limitations in current approaches.
The findings suggest that while trajectory mining can reveal inspectable skill structures, the boundary detection, segment representation, and reward modeling used are inadequate for cross-domain policy enhancement. This is a critical insight for agent architectures that rely on skill libraries or hierarchical planning. The study serves as a diagnostic tool, pointing toward areas needing improvement in automated skill discovery.
Despite limited transfer performance, the work demonstrates that mining can expose meaningful structure in interaction data, which may be useful for debugging or inspecting agent behavior. For future development, this research underscores the importance of refining segmentation techniques and reward modeling to enable more effective policy learning from mined skills, particularly in multi-agent systems where coordination is key.
Key insight: Trajectory mining can expose skill structure but current methods are insufficient for reliable cross-domain policy improvement, highlighting the need for better segmentation and reward modeling.
The Register Gap: A Meaning Intelligence Framework for Nigerian Public Discourse
Achi, Celestine arXiv: 2606.20255

The Meaning Intelligence Framework (MIF) introduced in this paper addresses a fundamental challenge in natural language processing: distinguishing surface sentiment from true communicative intent. The Register Gap—where zero-shot accuracy is only 33.3% but rises to 73.3% with schema-informed prompting—demonstrates that context plays a crucial role in understanding Nigerian public discourse, especially in multilingual and code-mixed environments.
This work has direct implications for agent architectures that must navigate complex linguistic contexts. The MIF's nine-dimensional annotation schema allows AI systems to better interpret pragmatic force, irony, and coded subtext, which are essential for effective communication in diverse social settings. For multi-agent systems interacting with human users, such nuanced understanding is vital for building trust and relevance.
The practical gains observed—particularly in register identification and strategic action recommendation—suggest that incorporating context-aware frameworks into AI agents can significantly enhance their performance. As AI systems expand into global markets and multilingual environments, tools like MIF will be essential for ensuring accurate interpretation and appropriate responses across different cultural and linguistic contexts.
Key insight: The Register Gap highlights the importance of context-aware language understanding for AI systems, showing that schema-informed prompting significantly improves register classification and meaning interpretation.
ReNikud: Audio-Supervised Hebrew Grapheme-to-Phoneme Conversion
Alper, Morris arXiv: 2606.20179
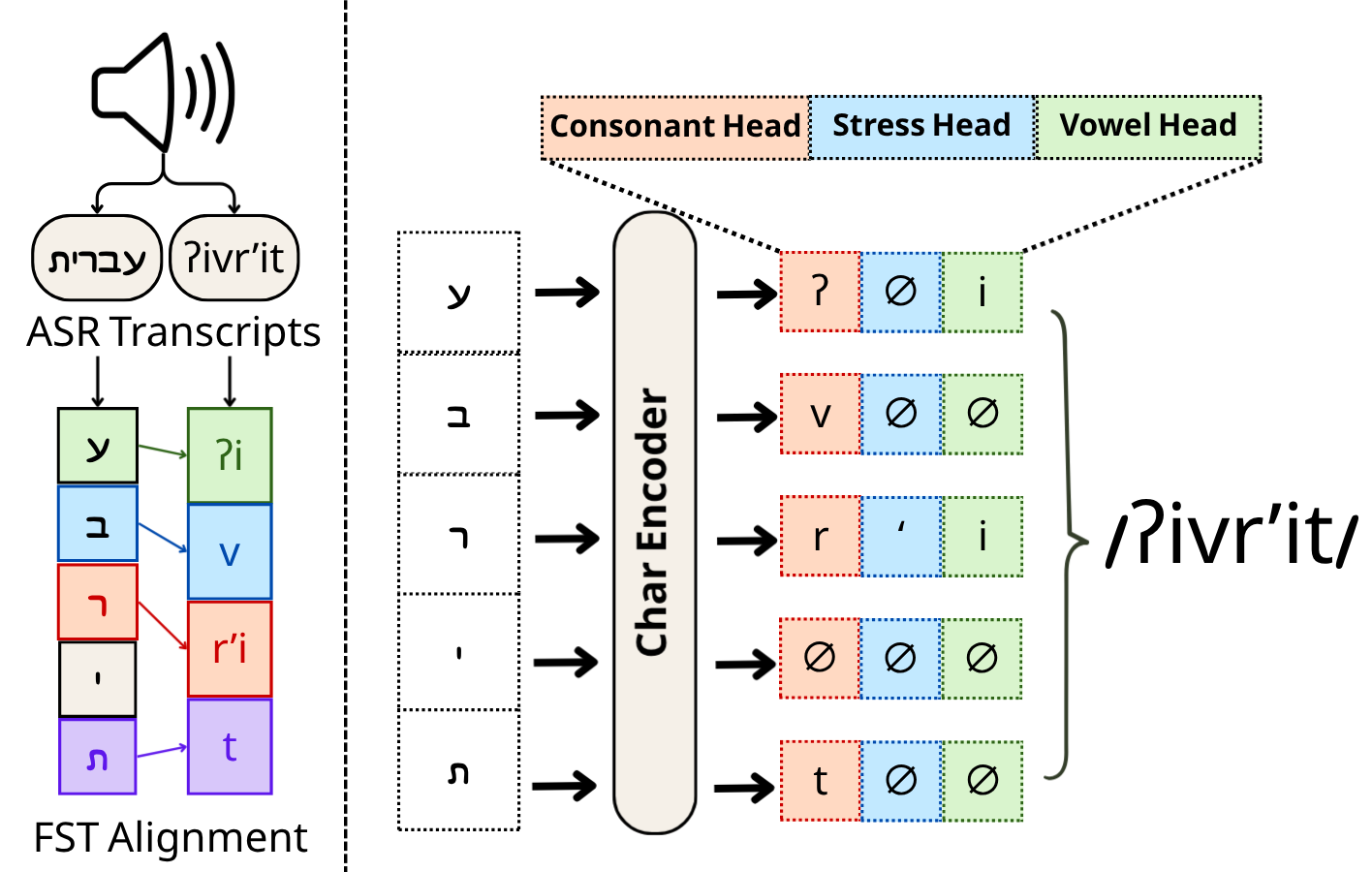
ReNikud addresses a longstanding challenge in Hebrew text-to-speech (TTS) systems: the abjad writing system leaves vowels largely unwritten, creating ambiguity. The method overcomes this by using weak audio supervision via phoneme-based ASR pseudo-labeling on thousands of hours of unlabeled audio, generating phonemic transcriptions that reflect natural spoken norms. This approach avoids the laborious process of manual annotation while capturing everyday pronunciation patterns.
The pseudo-vocalization architecture predicts IPA phonemes at each character position, enforcing character-level alignment as an inductive bias—a key innovation for abjad languages. This design choice improves performance on both existing benchmarks and a new MILIM benchmark for spoken Hebrew, surpassing previous state-of-the-art methods. For AI agents working with minority or under-resourced languages, ReNikud offers a scalable solution to pronunciation challenges.
The ability to generate accurate G2P conversions without extensive labeled data is particularly valuable in agent development, especially when deploying systems in multilingual environments. As AI agents increasingly interact with diverse linguistic inputs, tools like ReNikud can help bridge gaps in language support and improve accessibility. The release of code and models further supports reproducibility and encourages further research in speech technologies for under-resourced languages.
Key insight: ReNikud leverages weak audio supervision to overcome the challenges of Hebrew G2P conversion, achieving state-of-the-art performance without manual vocalization annotations.
Predictability as a Fine-Grained Measure for Privacy
Sridharan, Karthik arXiv: 2606.20546

This paper introduces predictability as a fine-grained privacy measure that explicitly accounts for an attacker's core knowledge, compromised dataset portions, and specified query families. Unlike traditional differential privacy (DP), which provides worst-case guarantees, predictability measures the incremental gain in predicting sensitive information after observing algorithm outputs. This approach allows for more nuanced privacy control tailored to specific threats.
The framework is particularly relevant for AI agent development where privacy concerns are paramount, especially in multi-agent systems that process sensitive data. By using generalized method of moments (GMM) to analyze asymptotic predictability, the authors derive a predictability-calibrated output perturbation scheme for ERM. This provides a complementary approach to DP, offering fine-grained control without sacrificing robustness.
The work demonstrates that predictability and DP are generally incomparable, with each being small while the other is large. This insight is crucial for designing privacy-preserving AI systems that can adapt to specific use cases. For agents operating in environments with varying levels of data sensitivity, predictability offers a more flexible and context-aware privacy framework than traditional DP alone.
Key insight: Predictability offers a fine-grained privacy metric that complements differential privacy by explicitly incorporating attacker knowledge and query families, enabling more tailored privacy controls.
When Does Streaming Tool Use Help? Characterizing Tool-Intent Stabilization in Streaming Retrieval-Augmented Generation
Galbraith, Elroy arXiv: 2606.20113
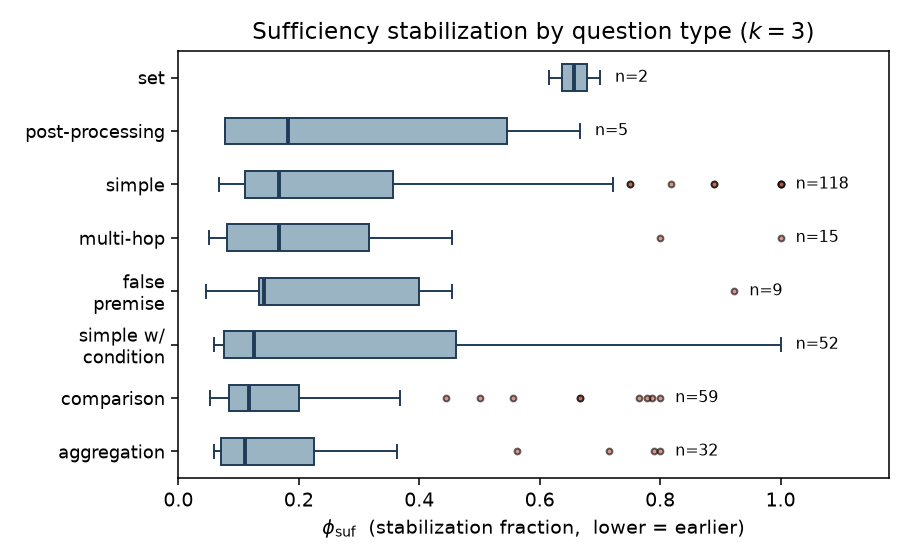
The paper introduces a novel characterization of streaming Retrieval-Augmented Generation (RAG) by focusing on the concept of 'tool-intent stabilization'—the point at which a speculative tool query converges to the correct result. This insight is crucial for understanding when and how streaming RAG can provide tangible benefits in real-world applications. The authors demonstrate that while streaming RAG reduces latency, its effectiveness hinges on the timing of stabilization, which varies significantly across different types of queries.
Through empirical analysis on the CRAG benchmark, they quantify the conditions under which streaming RAG achieves latency hiding, identifying a model-agnostic upper bound H that depends on tool latency L and input cadence δ. Their findings reveal that 73.9% of queries across the benchmark admit substantial latency hiding, with a particularly favorable subset (21.3%) where gold evidence is verbatim-present and retrievable by BM25. This suggests that streaming RAG is most effective when the system can quickly identify relevant information early in the input stream.
The study also highlights that question type plays a significant role in determining whether stabilization occurs early or late, offering practical guidance for designing speculative triggers in streaming systems. By identifying which query properties predict early versus late stabilization, the paper provides actionable insights for optimizing tool use in LLM-based agents, especially those operating under time-sensitive constraints.
Key insight: Streaming RAG can effectively reduce user-perceived latency only when tool-intent stabilization occurs early in the input stream, and this behavior is predictable based on query characteristics.
AI Model Releases

In the Weights is your new AI-centric vanity search | TechCrunch
Source: TechCrunch.
Agent Frameworks & SDKs
WUPHF is a new framework from Nex.ai that enables users to create personal offices of AI teammates who collaborate over shared context. The system supports integration with Claude Code, Codex, OpenClaw, OpenCode, and local LLMs. It's designed as a tool for developers to build AI-powered workflows that can work together on tasks. The framework is built around the concept of 'structured planning' and aims to provide a more organized approach to AI team collaboration.
Why it matters: This represents a significant step toward practical AI agent frameworks that can work collaboratively in shared contexts, potentially reshaping how developers build and deploy AI-powered workflows. Its support for multiple LLM interfaces suggests it could become a versatile platform for building complex AI systems.