DeepMind publishes critical security guidelines for increasingly capable AI agents, while Hugging Face introduces new benchmarking tools to evaluate agent performance with real tooling. Meanwhile, foundational research advances multi-agent systems and optimization techniques.
DeepMind addresses the growing security challenges of powerful AI agents within internal systems, emphasizing proactive measures to protect against evolving threats as autonomous systems approach human-level capabilities. Hugging Face releases a comprehensive benchmarking framework that evaluates open models' performance using real tooling rather than just final outputs, measuring efficiency gains of up to 6x in token usage. Research advances include Multi-Agent Transactive Memory for experience sharing across agent populations, FAPO's fully autonomous prompt optimization for multi-step LLM pipelines, and novel approaches to distributed nonconvex optimization with input delays. These developments signal a maturation of AI agent capabilities and the emergence of more sophisticated evaluation methods and system architectures.
Research Papers
Multi-Agent Transactive Memory
Diaz, Fernando arXiv: 2606.19911
The emergence of decentralized LLM agent ecosystems necessitates robust infrastructure for knowledge sharing across heterogeneous populations. Multi-Agent Transactive Memory (MATM) addresses this challenge by creating a shared repository where producer agents contribute reusable procedural knowledge in the form of trajectories, while consumer agents retrieve these artifacts to enhance task execution. This approach is particularly valuable in interactive environments like ALFWorld and WebArena, where trajectories encode rich procedural structures that are typically discarded after single use.
MATM's effectiveness was demonstrated through experiments showing improved downstream task performance and reduced interaction steps when trajectories were retrieved from the shared repository. Notably, this improvement occurs without requiring coordination or joint training between agents, positioning MATM as a scalable design pattern for open agent ecosystems. The framework essentially enables a form of collective learning where individual agent experiences become part of a larger knowledge base accessible to the entire population.
This work contributes significantly to multi-agent systems by introducing a mechanism that allows for experience reuse at scale. It suggests that future agent architectures should incorporate memory systems capable of storing and retrieving not just raw data but structured procedural knowledge, which could dramatically reduce redundant learning and accelerate convergence in complex environments.
Key insight: Multi-Agent Transactive Memory (MATM) enables population-level experience sharing among LLM agents by storing and retrieving reusable trajectories, significantly improving task performance without requiring coordination or joint training.
FAPO: Fully Autonomous Prompt Optimization of Multi-Step LLM Pipelines
Karbasi, Amin arXiv: 2606.19605

FAPO represents a significant advancement in LLM pipeline optimization by moving beyond simple prompt-only adjustments to include structural modifications when bottlenecks are detected. This framework leverages Claude Code to evaluate pipelines, diagnose failures, propose scoped changes, and validate variants repeatedly against a score function. The key innovation lies in its ability to escalate from prompt edits to structural changes only when necessary, making it both efficient and effective.
The empirical results show that FAPO outperforms baseline methods like GEPA across multiple benchmarks and task models, with substantial gains in accuracy—particularly in security tasks where prompt-only optimization was insufficient. This demonstrates the importance of considering the entire pipeline rather than optimizing individual components in isolation, especially for complex multi-step reasoning tasks.
This work has broad implications for LLM efficiency and agent architectures, as it provides a systematic approach to optimizing end-to-end pipelines. It suggests that future agent systems should incorporate autonomous optimization capabilities that can dynamically adjust both prompting strategies and structural elements based on performance feedback.
Key insight: FAPO (Fully Autonomous Prompt Optimization) achieves state-of-the-art pipeline optimization by combining prompt editing with structural changes when necessary, demonstrating superior performance across general-purpose and security-focused tasks.
How Do Instructions Shape Speech? Cross-Attention Attribution for Style-Captioned Text-to-Speech
Kamath, Sudarshan arXiv: 2606.20532
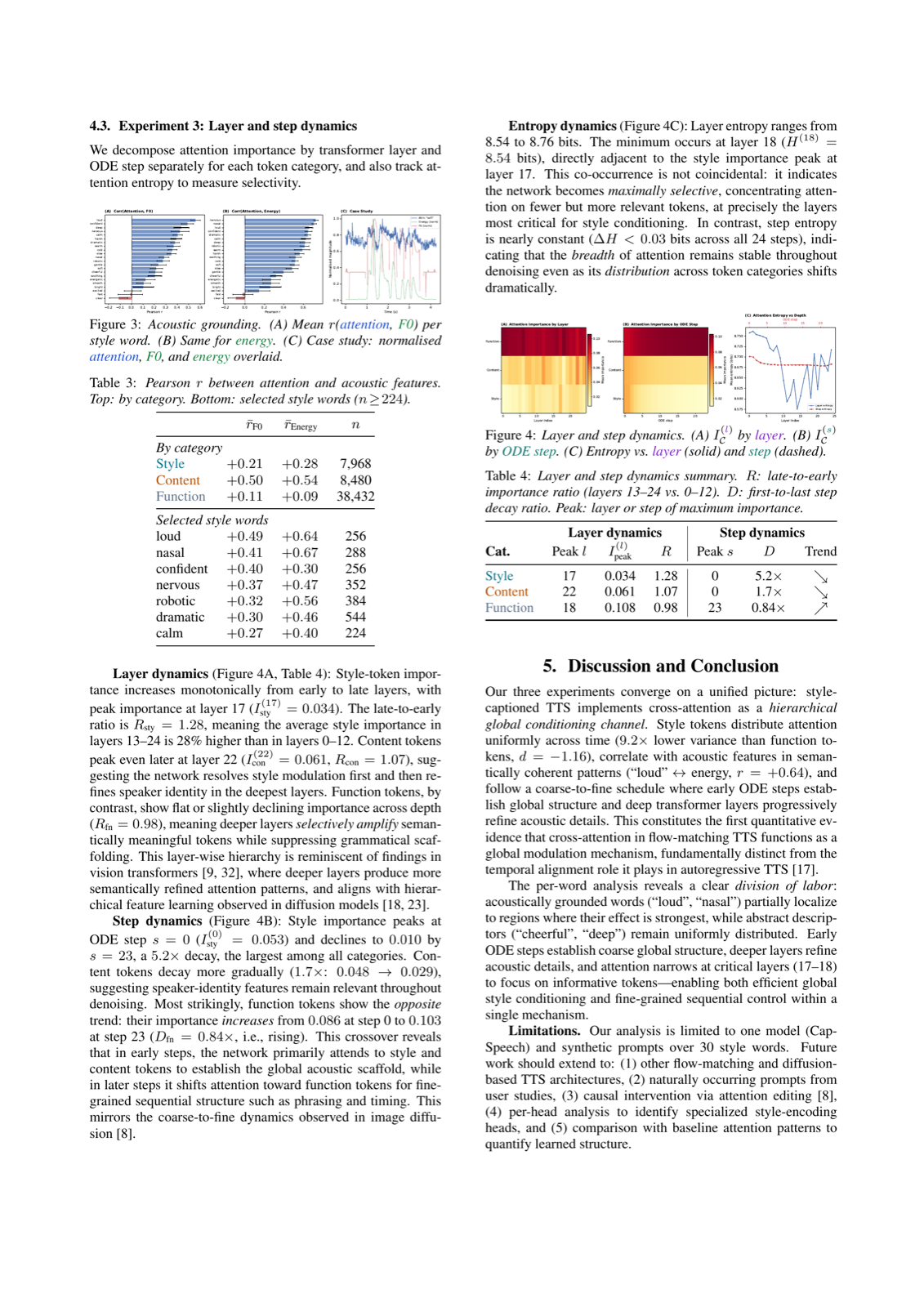
This study introduces a novel method for understanding how natural language instructions shape voice characteristics in style-captioned text-to-speech systems. By adapting the DAAM framework to the speech domain, researchers extract per-token heatmaps across multiple layers and ODE steps, providing unprecedented insight into the internal workings of speech diffusion models.
Key findings include that style tokens exhibit lower temporal variance than content/function tokens, confirming global conditioning effects; style attention correlates with fundamental frequency (F0) and energy parameters; and the most critical stage for style influence occurs in early steps and deep layers. These insights are crucial for diagnosing failure modes and improving controllability in expressive TTS systems.
The work contributes to multimodal models and reasoning & planning by demonstrating how attention mechanisms can be analyzed across different modalities. It also has implications for agent architectures that need to understand and control complex, multi-dimensional outputs, particularly in human-computer interaction scenarios where precise control over generated speech is essential.
Key insight: Cross-attention attribution reveals how natural language instructions influence acoustic output in speech diffusion models, identifying critical layers and time steps where style tokens have maximum impact on waveform generation.
Multi-LCB: Extending LiveCodeBench to Multiple Programming Languages
Babaev, Dmitrii arXiv: 2606.20517
Multi-LCB addresses a critical limitation of existing code-generation benchmarks by extending LiveCodeBench to twelve programming languages while maintaining contamination controls. This approach allows for systematic assessment of cross-language code generation competence, revealing how well models generalize beyond Python and identifying substantial performance gaps across different languages.
The evaluation of 24 LLMs across multiple languages uncovered evidence of Python overfitting and language-specific contamination, suggesting that current models may be relying too heavily on Python-specific patterns rather than developing true cross-language understanding. This finding has important implications for agent architectures that need to operate effectively across diverse programming environments.
This benchmark contributes significantly to LLM efficiency and multi-agent systems by highlighting the need for more robust, language-agnostic training approaches. It also underscores the importance of evaluating models not just on their performance in one domain but across multiple contexts, which is essential for building versatile AI agents capable of working in varied software engineering environments.
Key insight: Multi-LCB reveals significant disparities in multilingual code generation capabilities, exposing Python overfitting and language-specific contamination that limit LLM generalization across programming languages.
StylisticBias: A Few Human Visual Cues Drive Most Social Biases in MLLMs
Diesner, Jana arXiv: 2606.20527
The StylisticBias benchmark provides the first controlled evaluation of how specific visual cues influence social judgments in multimodal large language models. By generating 25,000 images with fixed identities but varying single attributes, researchers were able to isolate appearance effects from identity differences and quantify the impact of different visual features on model behavior.
This work demonstrates that bias in MLLMs is concentrated in a small set of visual cues, which has profound implications for fairness and safety in AI systems. The finding that age and body type dominate identity-level effects while fashion style drives attribute-level shifts suggests that current models may be learning superficial associations rather than deeper understanding of social concepts.
The results contribute to memory & tool use and reasoning & planning by highlighting the need for more nuanced evaluation frameworks that can detect subtle biases in multimodal systems. It also emphasizes the importance of incorporating fairness considerations into agent design, particularly as these systems become deployed in personally and societally consequential settings.
Key insight: StylisticBias reveals that a small set of visual cues (about 15 attributes) account for nearly 80% of social bias in multimodal language models, with age and body type dominating identity-level effects while fashion style drives attribute-level shifts.
PsyScore: A Psychometrically-Aware Framework for Trait-Adaptive Essay Scoring and ZPD-Scaffolded Feedback
Zheng, Chanjin arXiv: 2606.20287
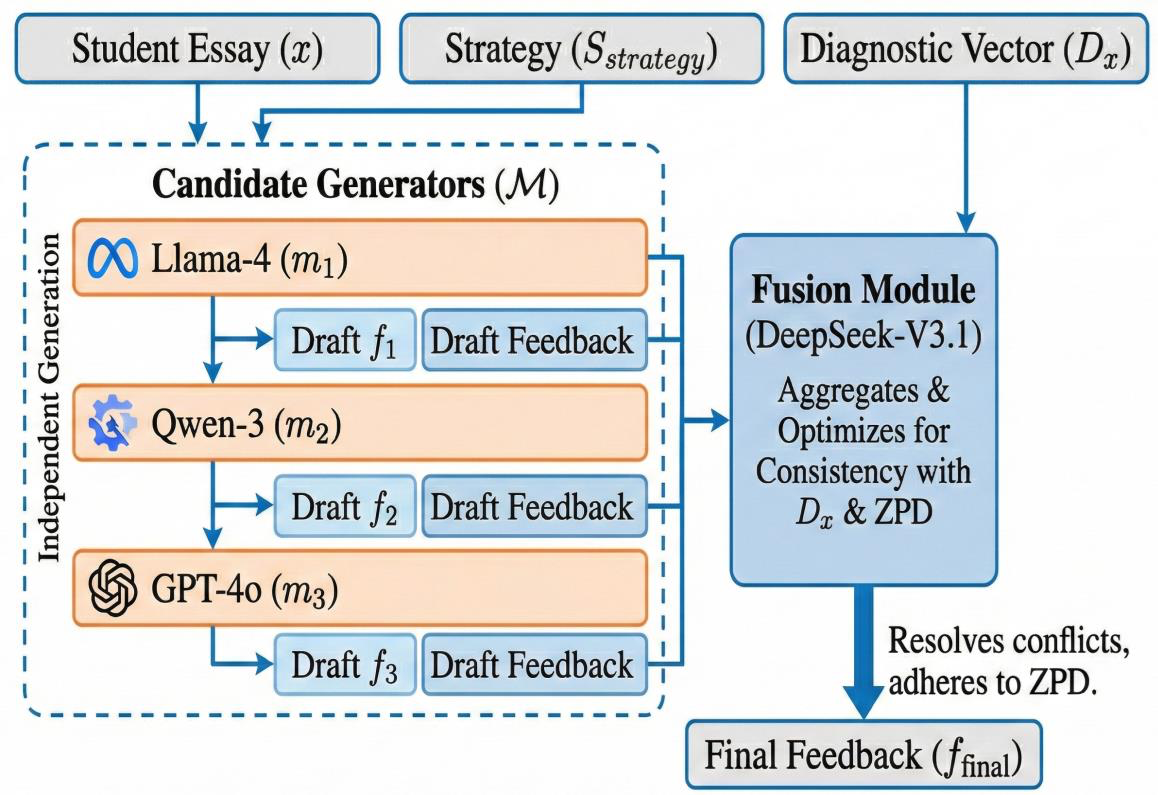
PsyScore represents a significant advancement in automated essay scoring by addressing the fragmentation between scoring and feedback in existing systems. Unlike traditional neural models that offer limited interpretability or LLM-based feedback that lacks sensitivity to learner proficiency, PsyScore introduces a psychometrically-aware framework that unifies these components through a shared latent ability representation.
The framework's core innovation lies in its integration of the Graded Partial Credit Model (GPCM) into a neural architecture, enabling precise estimation of student ability while maintaining psychometric interpretability. This approach allows for more nuanced scoring that reflects individual differences in learner traits, moving beyond simple accuracy metrics to capture deeper cognitive processes.
The multi-agent feedback generation module conditions instructional strategies on diagnosed ability parameters, adapting the focus and scaffolding across different proficiency levels. This adaptive feedback mechanism demonstrates how multi-agent systems can be designed to provide personalized learning experiences, aligning with recent trends in AI agent development that emphasize context-awareness and individualized responses.
Key insight: PsyScore integrates psychometric principles with multi-agent feedback generation to provide trait-adaptive essay scoring and scaffolding, demonstrating how LLMs can be made more pedagogically effective by aligning feedback with learner proficiency levels.
How Transparent is DiffusionGemma?
Nanda, Neel arXiv: 2606.20560

This work provides crucial insights into the transparency of diffusion models, particularly DiffusionGemma, which operates in a continuous latent space unlike traditional autoregressive models. The authors demonstrate that despite initial concerns about variable transparency due to high opaque serial depth, they can map information flow through interpretable token bottlenecks, reducing the opaque serial depth from 28.6X to just 1.1X compared to Gemma 4.
The study reveals that while algorithmic transparency remains more challenging for diffusion models due to their distributed computation patterns, novel phenomena such as non-chronological reasoning and token smearing emerge that are specific to diffusion processes. These findings suggest that interpretability frameworks must evolve to account for the unique computational characteristics of diffusion architectures.
The research also confirms that DiffusionGemma maintains similar monitorability to autoregressive models, indicating that transparency benefits can be preserved without sacrificing downstream performance. This is particularly important as diffusion models become more prevalent in AI agent development, where understanding model decision-making processes remains critical for alignment and debugging.
Key insight: DiffusionGemma achieves comparable reasoning transparency to autoregressive models through token bottleneck mapping, while exhibiting unique diffusion-specific phenomena like non-chronological reasoning and intermediate-context reasoning that require new interpretability approaches.
Optimal Deterministic Multicalibration and Omniprediction
Roth, Aaron arXiv: 2606.20557

This work addresses a long-standing question in machine learning theory regarding whether randomization is necessary for optimal sample complexity in multicalibration. By presenting a deterministic algorithm that achieves the minimax-optimal rate of O(ε⁻³), the authors resolve this open problem and provide a significant theoretical advance for trustworthy ML systems.
The deterministic approach has practical implications for real-world applications where randomization may be undesirable or impossible, such as in regulated environments or when reproducibility is crucial. The algorithm's ability to produce optimal predictors that satisfy outcome indistinguishability with respect to various test collections makes it particularly valuable for fairness and accountability in AI systems.
The extension to omnipredictors and panpredictors further demonstrates the broad applicability of this deterministic approach, resolving open problems in multiple areas of machine learning. This work contributes to the growing body of research on deterministic methods that can match or exceed the performance of randomized approaches while providing stronger theoretical guarantees.
Key insight: The paper resolves a fundamental open problem by demonstrating that deterministic predictors can achieve minimax-optimal sample complexity for multicalibration, providing a theoretical foundation for trustworthy machine learning systems without requiring randomization.
Fisher-Geometric Sharpness and the Implicit Bias of SGD toward Flat Minima
Dutta, Hemen arXiv: 2606.20469
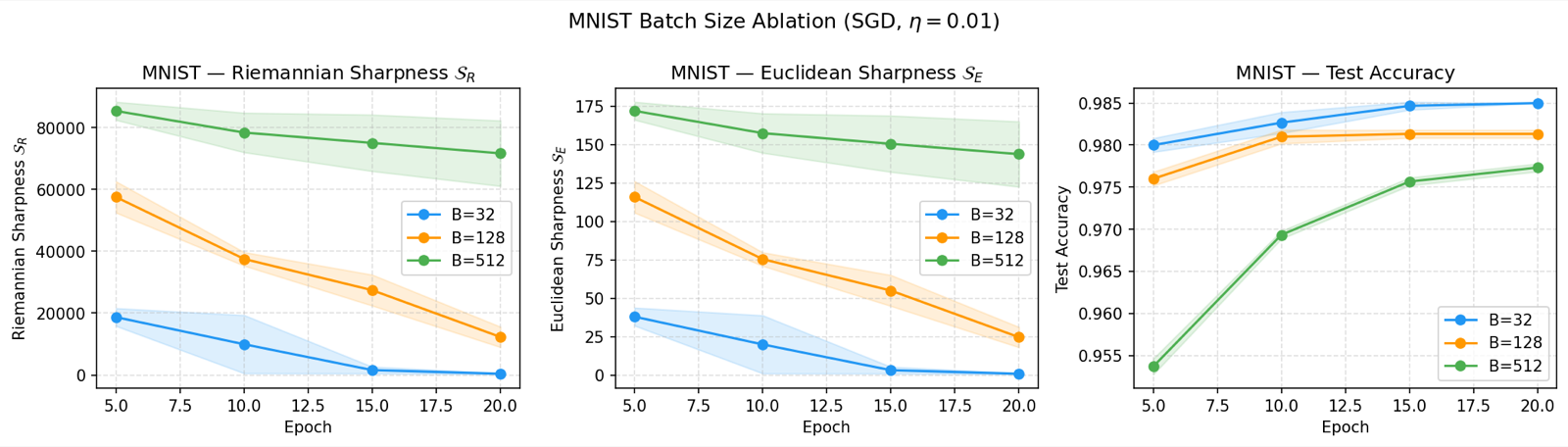
This paper provides a mathematically rigorous solution to the problem of defining flatness in deep learning that was previously undermined by reparametrization invariance issues. By grounding flatness in Riemannian geometry induced by the Fisher Information Matrix, the authors establish a theoretically sound framework for understanding why SGD implicitly favors flat minima.
The key contribution is showing that Riemannian sharpness is invariant under smooth, function-preserving reparametrizations, directly addressing criticisms of previous Euclidean measures. This invariance ensures that the geometric properties of minima are meaningful regardless of how the network parameters are represented, which is crucial for understanding generalization behavior.
The connection between Riemannian sharpness and test performance through PAC-Bayes bounds provides a formal link between geometric bias and empirical success. The experimental validation on MNIST and CIFAR-10 confirms that this measure reliably tracks generalization better than Euclidean sharpness, offering practical guidance for training strategies and model selection in deep learning.
Key insight: Riemannian sharpness based on Fisher Information Matrix provides a reparametrization-invariant measure of flatness that better explains why SGD favors flat minima and generalizes well, offering a rigorous geometric foundation for understanding implicit bias in deep learning.
Data Bias Mitigation under Coverage Constraints & The Price of Fairness
Miller, Renée J. arXiv: 2606.20461
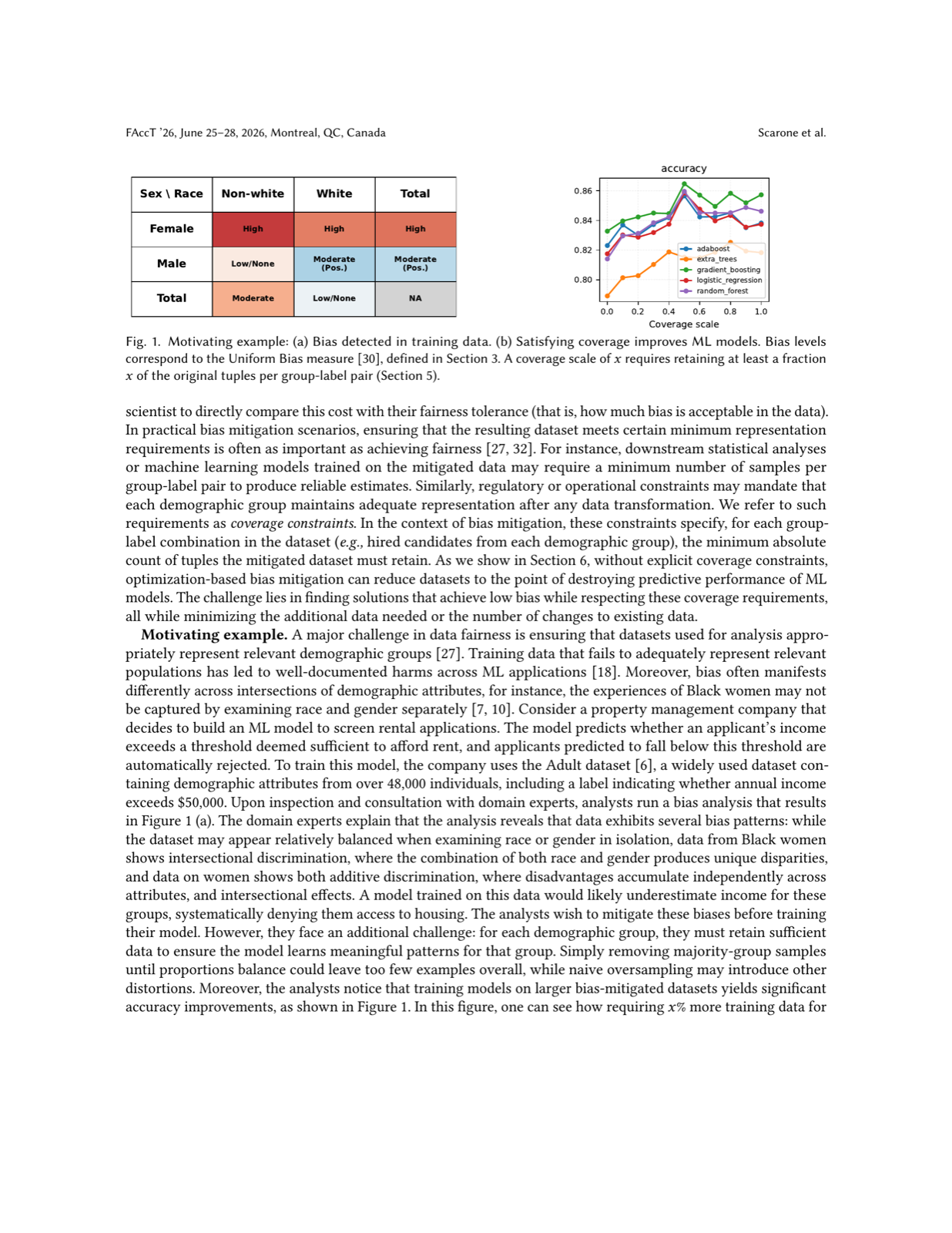
This work addresses critical challenges in bias mitigation by incorporating coverage constraints that enforce sufficient representation across intersectional subgroups, which is particularly important given that traditional approaches often fail to account for the complex interactions between multiple sensitive attributes. The framework recognizes that achieving zero bias may not be data-efficient and allows for small approximation errors in exchange for greater data efficiency.
The formulation of bias mitigation as an integer linear program provides a principled approach for optimizing over all possible mitigation strategies while characterizing the price of fairness as a function of fairness tolerance. This is essential for practical implementation, especially in regulated environments where specific fairness thresholds must be met, and for data governance decisions that require balancing bias reduction against data modification costs.
The evaluation on multiple public datasets demonstrates that the framework preserves predictive accuracy across different classifiers while addressing intersectional bias, showing that coverage constraints are not just statistically motivated but also essential for maintaining downstream ML performance. This work contributes to the growing field of fair machine learning by providing practical tools for balancing competing objectives.
Key insight: The framework extends bias mitigation to incorporate coverage constraints that ensure sufficient representation of intersectional subgroups, enabling practitioners to make informed trade-offs between bias reduction and data modification costs.
Mesh Inference: A Formal Model of Collective Intelligence Without a Center
Xu, Hongwei arXiv: 2606.19537

The paper presents the first formal model of mesh inference, offering a rigorous mathematical framework for understanding how populations of independent agents can collectively derive conclusions without central coordination or information sharing. This approach addresses fundamental questions about decentralized intelligence and provides theoretical guarantees for collective decision-making in distributed systems.
Key innovations include the use of coupled free energy relaxation and the demonstration that mesh inference converges to unique answers regardless of admission policies, with identification-complete properties when views are carrier-connected. The model's ability to derive centralized optimum exactly under certain conditions while maintaining confidentiality makes it particularly relevant for AI agent architectures where trust and information security are paramount.
The formalization of mesh inference as a center-free learning loop represents a significant step toward understanding how distributed systems can maintain performance without central coordination, which has implications for multi-agent systems in AI. The work's focus on content-addressed lineage as the only global side-channel suggests new approaches to maintaining privacy while enabling collective intelligence, aligning with current research trends in decentralized AI agent development.
Key insight: Mesh inference provides a formal model for collective intelligence where independent agents derive conclusions without central coordination, demonstrating that distributed systems can achieve centralized optimum performance with O(diam²) latency.
A Multi-Agent system for Multi-Objective constrained optimization
Filippini, Federica arXiv: 2606.20236
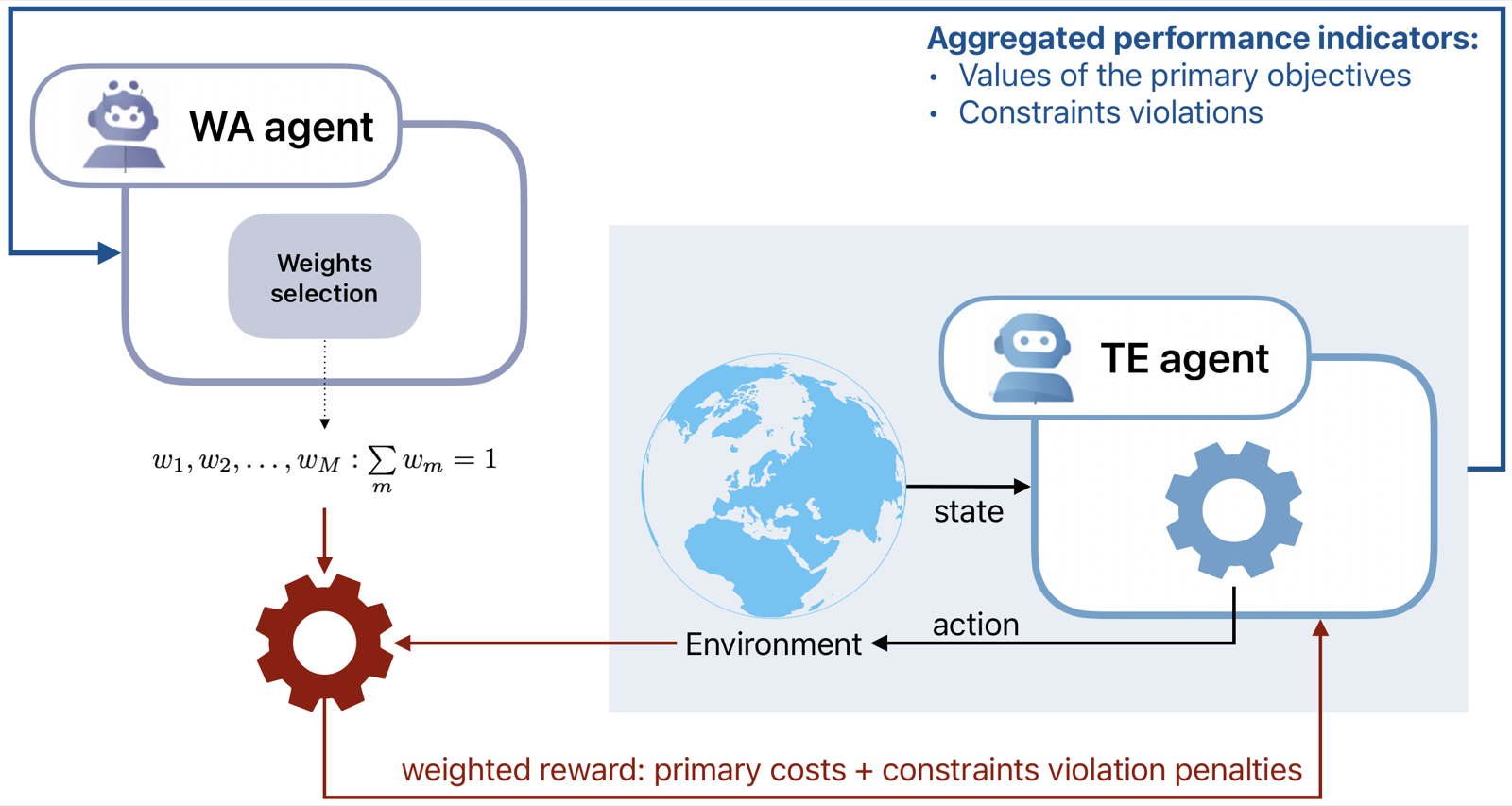
In the realm of AI agent development, particularly within constrained optimization problems, traditional reinforcement learning (RL) methods often struggle due to the manual tuning of penalty weights that balance primary objectives against constraint violations. This paper presents MAMO, a multi-agent system designed to address this challenge by formulating the selection of reward weights as a learning problem itself. By doing so, it moves away from heuristic weight assignment and toward an adaptive mechanism that can respond dynamically to changing environmental conditions.
The core innovation lies in how MAMO separates the execution of tasks from the design of objectives. This decoupling allows each agent to focus on optimizing its own subtask while learning appropriate weights for the overall system, leading to more robust and scalable solutions. The approach is especially relevant for real-world applications where constraints may shift over time or where multiple competing goals must be balanced without prior knowledge of their relative importance.
This work contributes significantly to multi-agent systems by offering a framework that not only improves performance in dynamic environments but also enhances the autonomy of agents in decision-making processes. It paves the way for more intelligent and self-regulating AI systems capable of handling complex, multi-objective optimization tasks without human intervention.
Key insight: MAMO introduces a novel multi-agent reinforcement learning approach that decouples task execution from reward weight selection, enabling autonomous and robust optimization in dynamic environments with multiple objectives and constraints.
Semiglobal Input-Delay Tolerance Algorithm for Distributed Nonconvex Optimization of Networked Nonlinear Systems
He, Dinxin arXiv: 2606.19871
Distributed optimization in networked systems is a critical area for AI agent development, especially when dealing with real-world constraints such as communication delays and nonlinear dynamics. This paper introduces a semiglobal input-delay tolerant (SIDT) algorithm that ensures convergence to optimal solutions even under significant input delays—a common issue in practical deployments.
The key advancement of this work is its ability to relax strict convexity assumptions by leveraging the Polyak-Łojasiewicz condition, which allows for broader applicability in nonconvex optimization problems. This is particularly important for AI systems where loss landscapes are often nonconvex and complex, making traditional methods less effective.
By combining hierarchical design with input-to-state stability analysis, the proposed algorithm provides theoretical guarantees on convergence while maintaining practical relevance. It supports the development of robust distributed agents that can operate reliably in uncertain or delayed environments, which is essential for scalable AI systems in robotics, smart grids, and other large-scale networks.
Key insight: The SIDT algorithm enables semiglobal convergence in distributed nonconvex optimization under input delays, extending applicability beyond convex settings through the use of the Polyak-Łojasiewicz condition.
AI Model Releases
Securing internal systems against increasingly capable and imperfectly aligned AI
DeepMind published a blog post addressing the security challenges of increasingly capable and imperfectly aligned AI agents within internal systems. The post discusses proactive security measures needed to protect against evolving threats as AI agents become more powerful, focusing on safeguarding internal infrastructure from potentially misaligned or overly capable autonomous systems. While specific technical details were limited, the piece emphasizes the need for responsible development practices.
Why it matters: This highlights a growing concern in AI safety as models become more capable - how to maintain control and security within internal systems while enabling powerful agent functionality. It signals that even leading AI labs are grappling with alignment issues as agents approach human-level capabilities.

Billionaire Ambani wants AI in every call, app, and home | TechCrunch
Source: TechCrunch.
Agent Frameworks & SDKs
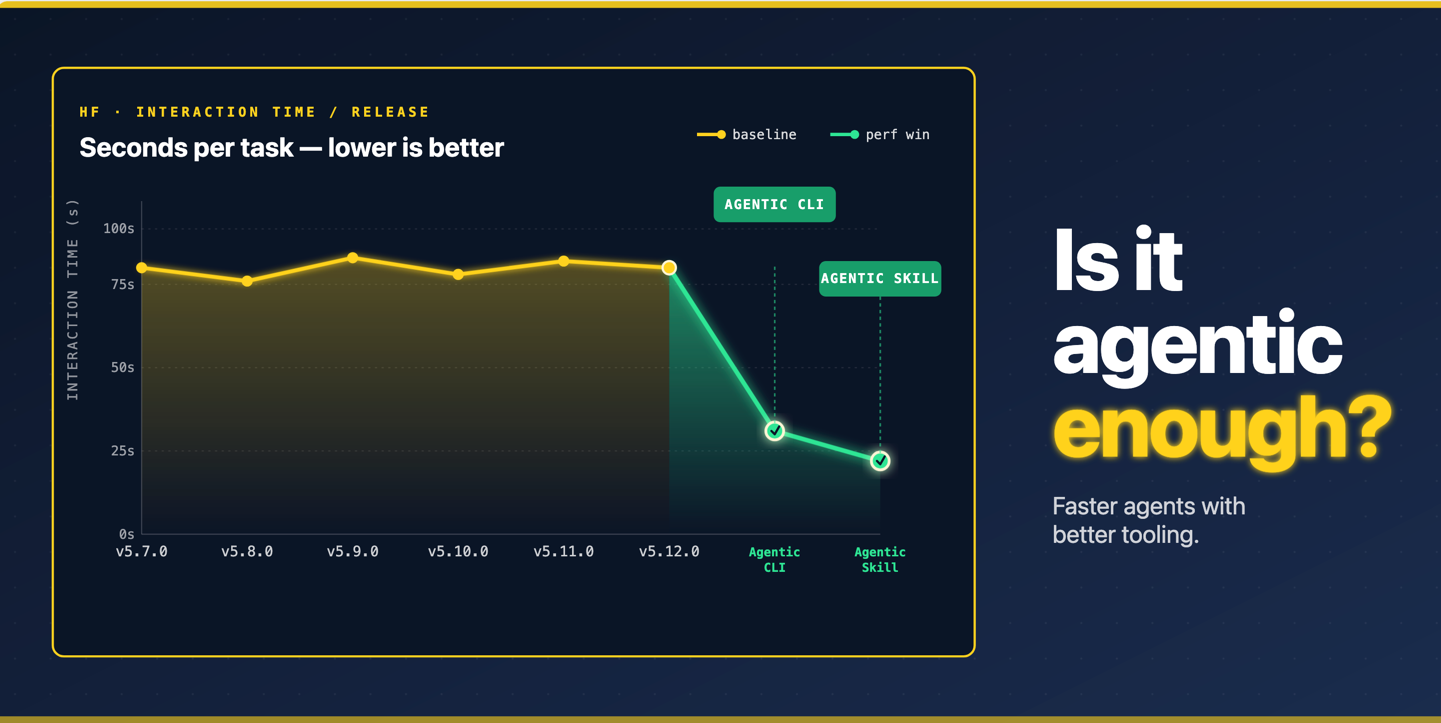
Is it agentic enough? Benchmarking open models on your own tooling
Hugging Face researchers introduced a new benchmarking framework to evaluate how well open models perform when using real tooling, focusing on the process rather than just final outputs. The tool measures agent performance across different library revisions, models, and tasks using the transformers library as a case study. They tested changes like CLI improvements and Skills to see if they reduce agent workloads by up to 6x in token usage. The benchmark runs entirely on open models driven by a pi coding agent across Hugging Face Jobs for consistent hardware.
Why it matters: This represents a critical shift toward evaluating AI tooling not just by final accuracy but by how efficiently agents can interact with it, which will become increasingly important as agents take on more complex workflows. The framework provides concrete metrics for measuring agent-optimized software improvements.