Researchers at AllenAI introduce MolmoMotion, a language-guided 3D motion forecasting model that predicts object movement from video frames and natural language instructions. Anthropic's study reveals that domain expertise, not coding proficiency, drives success in agentic coding tasks. Meanwhile, Google Cloud reports significant productivity gains for UK SMBs adopting AI tools.
AllenAI's MolmoMotion represents a major leap in multimodal AI systems, enabling 3D motion forecasting through language instructions and sparse point representations that are efficient for robotics and video generation applications. Anthropic's research on agentic coding provides concrete evidence that as these tools mature, they will reward deep domain knowledge over technical implementation skills, fundamentally changing how knowledge work is organized. Google Cloud's findings show that UK small and midsize businesses leveraging AI tools experience nearly doubled year-over-year adoption rates and report a 20% productivity boost, effectively giving them back one full working day each week. Additional research advances include new frameworks for user personalization via local parametric edits, decoupled search grounding architectures for LLM agents, and innovative approaches to formal theorem proving using diffusion models.
Research Papers
User as Engram: Internalizing Per-User Memory as Local Parametric Edits
Li, Bojie arXiv: 2606.19172
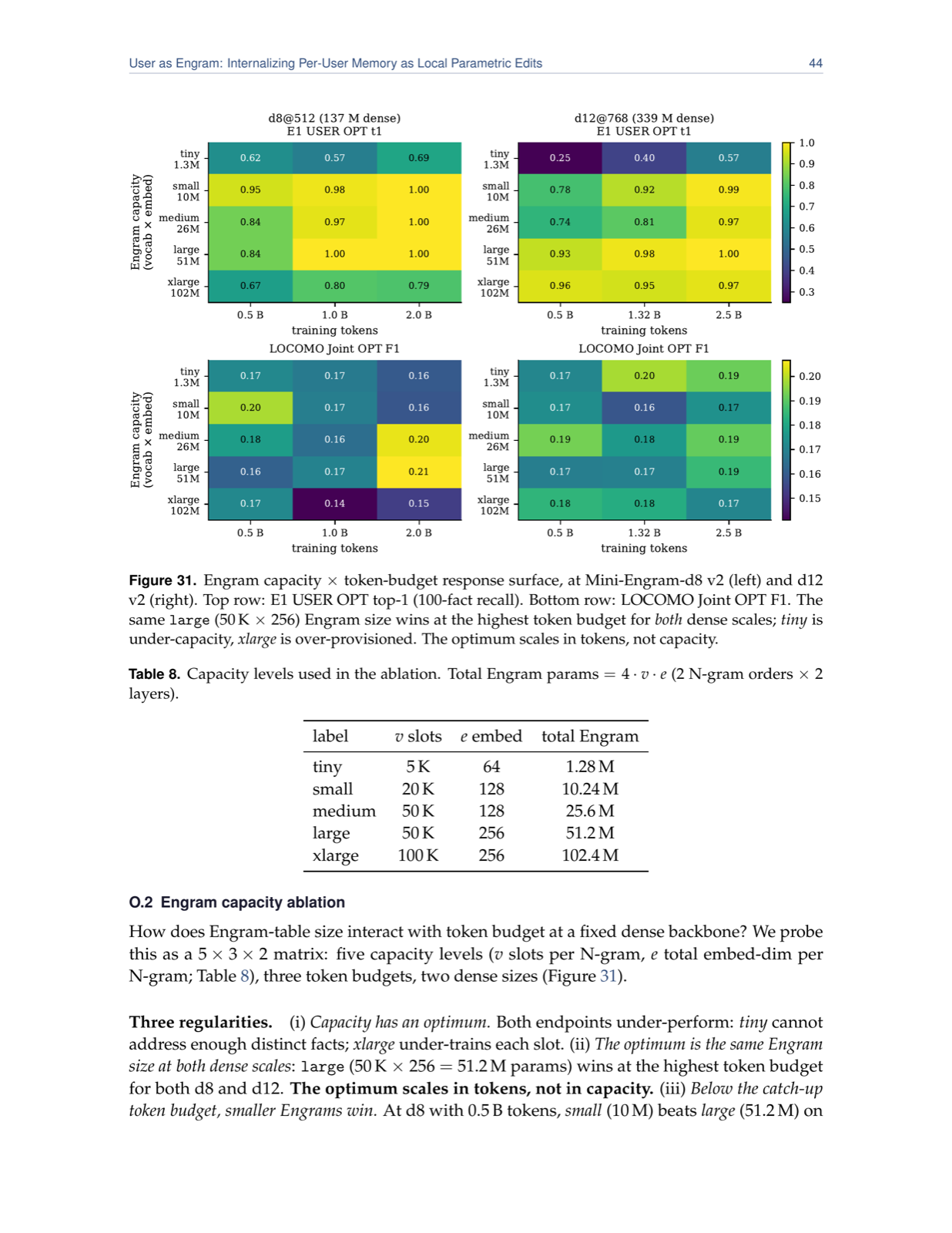
The paper introduces 'User as Engram', a novel approach to personalizing language models that addresses the fundamental tension between content retention and reasoning skill preservation. Unlike traditional methods such as per-user LoRA adapters, which merge user-specific facts with shared skills into a single global weight delta, this method separates these concerns by storing user facts in a local, hash-keyed memory table. This design mirrors how the human brain operates—keeping episodic memories (facts) separate from procedural knowledge (skills). The result is a system where edits are surgical and precise: writing a fact only activates its lookup at exactly the trigger, adds the necessary value, and leaves all other positions unchanged.
This layered architecture not only improves accuracy but also dramatically reduces memory usage. By storing user-specific content in disjoint hash slots, multiple users can coexist in one shared table without interference, enabling additive and lossless stacking of edits. This is a stark contrast to per-user LoRA, which admits only one global weight delta per user. The approach also supports efficient retrieval even as the number of facts grows—past ~100 facts, it outperforms traditional retrieval pipelines on larger models, demonstrating scalability advantages.
The practical implications are significant for deploying personalized LLMs at scale. The 'glass box' nature of the edits ensures transparency and control, making it easier to audit or modify individual user memories without affecting others. This method could be particularly valuable in applications requiring high-fidelity personalization, such as virtual assistants or educational tools, where maintaining both factual accuracy and reasoning capability is crucial.
Key insight: Personalization via local parametric edits to a hash-keyed memory table (Engram model) achieves 5.6x higher indirect-reasoning accuracy than per-user LoRA while maintaining a ~33,000x smaller memory footprint and avoiding contamination of unrelated content.
Decoupling Search from Reasoning: A Vendor-Agnostic Grounding Architecture for LLM Agents
Das, Sudeep arXiv: 2606.18947
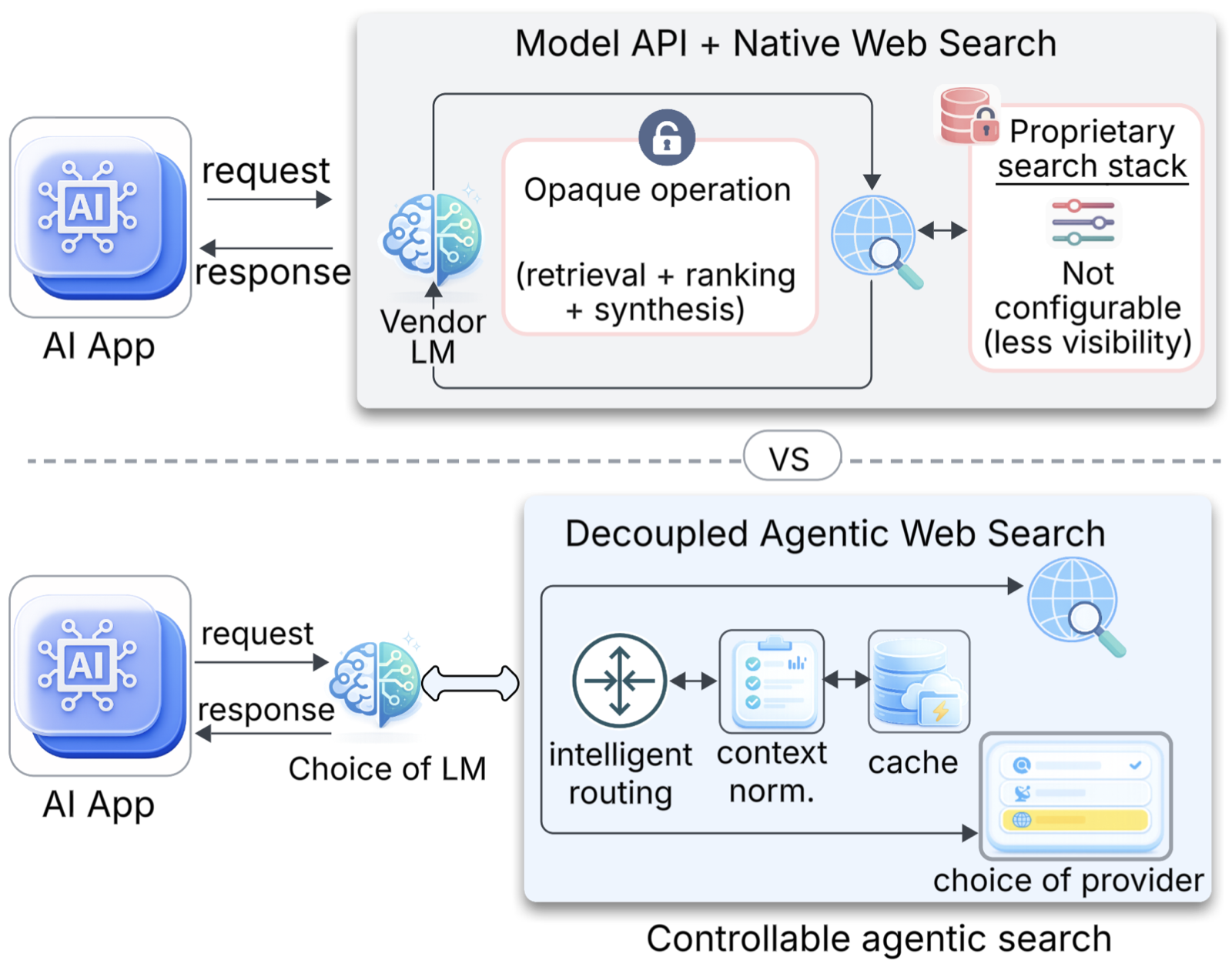
The paper presents Decoupled Search Grounding (DSG), a framework that moves the responsibility of search grounding outside the reasoning model through an MCP-compatible gateway. This approach treats grounding as an interface boundary, enabling fine-grained control over provider routing, source-aware context rendering, fallback strategies, and caching mechanisms. By decoupling these functions from the core reasoning process, DSG allows for more flexible and inspectable agent behavior, which is critical in production environments where strict output contracts must be maintained.
In experiments across multiple models and datasets, DSG demonstrates strong performance gains in terms of cost reduction (91% lower search cost on SimpleQA) and latency (68% lower latency with 99.4% warm-cache hit rate), while maintaining or slightly exceeding native-search accuracy. This is particularly important for real-time applications where efficiency and reliability are paramount, such as e-commerce query-understanding workloads where search costs can be prohibitively high.
The key innovation lies in recognizing that grounding should not be treated as a fixed model feature but as an optimizable interface. This perspective opens up new possibilities for reusing, tuning, and porting grounding components across different models and tasks, ultimately leading to more modular and adaptable agent architectures.
Key insight: Decoupling search from reasoning through a vendor-agnostic gateway allows for better control, cost efficiency, and performance in LLM agents by treating grounding as an optimizable interface boundary rather than a fixed model feature.
CEO-Bench: Can Agents Play the Long Game?
Liu, Zhuang arXiv: 2606.18543

CEO-Bench introduces a novel benchmark for evaluating language model agents' ability to handle long-horizon tasks under uncertainty and dynamic environments. By simulating a full startup operation over 500 days, it tests agents on their capacity to navigate complex interdependencies, acquire information in noisy settings, adapt to changing conditions, and orchestrate multiple decisions toward coherent goals. This is a significant step beyond short-term task execution benchmarks like software engineering or customer service.
The results show that while current models excel at isolated tasks, they falter when faced with sustained strategic challenges. Only Claude Opus 4.8 and GPT-5.5 manage to surpass the initial $1M balance, but neither consistently turns a profit—a telling sign of limitations in long-term planning and resource management capabilities. This benchmark highlights the gap between current agent performance and what is needed for real-world applications requiring sustained intelligence and adaptability.
CEO-Bench serves as an early indicator of the next frontier in AI agent development: building systems capable of long-term, adaptive reasoning and execution. It underscores the need for more sophisticated architectures that can integrate temporal reasoning, planning, and learning over extended periods, moving beyond reactive behavior to proactive strategic thinking.
Key insight: CEO-Bench evaluates long-term strategic decision-making in agents by simulating a 500-day startup operation, revealing that even top-tier models struggle with sustained adaptive progress over time.
Skill-Guided Continuation Distillation for GUI Agents
Jiang, Daxin arXiv: 2606.18890
SGCD addresses a critical limitation in GUI agent training: the policy-induced off-trajectory states that occur during closed-loop execution. These are states not covered by expert demonstrations, leaving policies without effective supervision and causing them to fail when encountering unseen situations. SGCD tackles this by first running the current policy to reach such off-trajectory states, then using a skill-guided policy to complete tasks from those points, generating successful continuations that are mixed with expert trajectories for further training.
This iterative self-improvement framework extracts skills from both successful and failed rollouts, including Continuation Plans, Critical Targets, Failure Traps, and Success Criteria. The method significantly boosts success rates across multiple base models, improving performance from the low-30% range to over 50%. This demonstrates SGCD's effectiveness in expanding the policy's reach beyond its initial training data, making it more robust and generalizable.
The approach is particularly valuable for GUI agents operating in complex environments where expert trajectories may be limited or insufficient. By continuously generating new demonstrations from off-trajectory states, SGCD enables agents to learn from their own mistakes and successes, leading to better adaptation and performance over time.
Key insight: Skill-Guided Continuation Distillation (SGCD) improves GUI agent performance by iteratively generating and mixing successful continuations from off-trajectory states, effectively closing the supervision gap in behavior cloning.
RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
Lin, Tao arXiv: 2606.19047
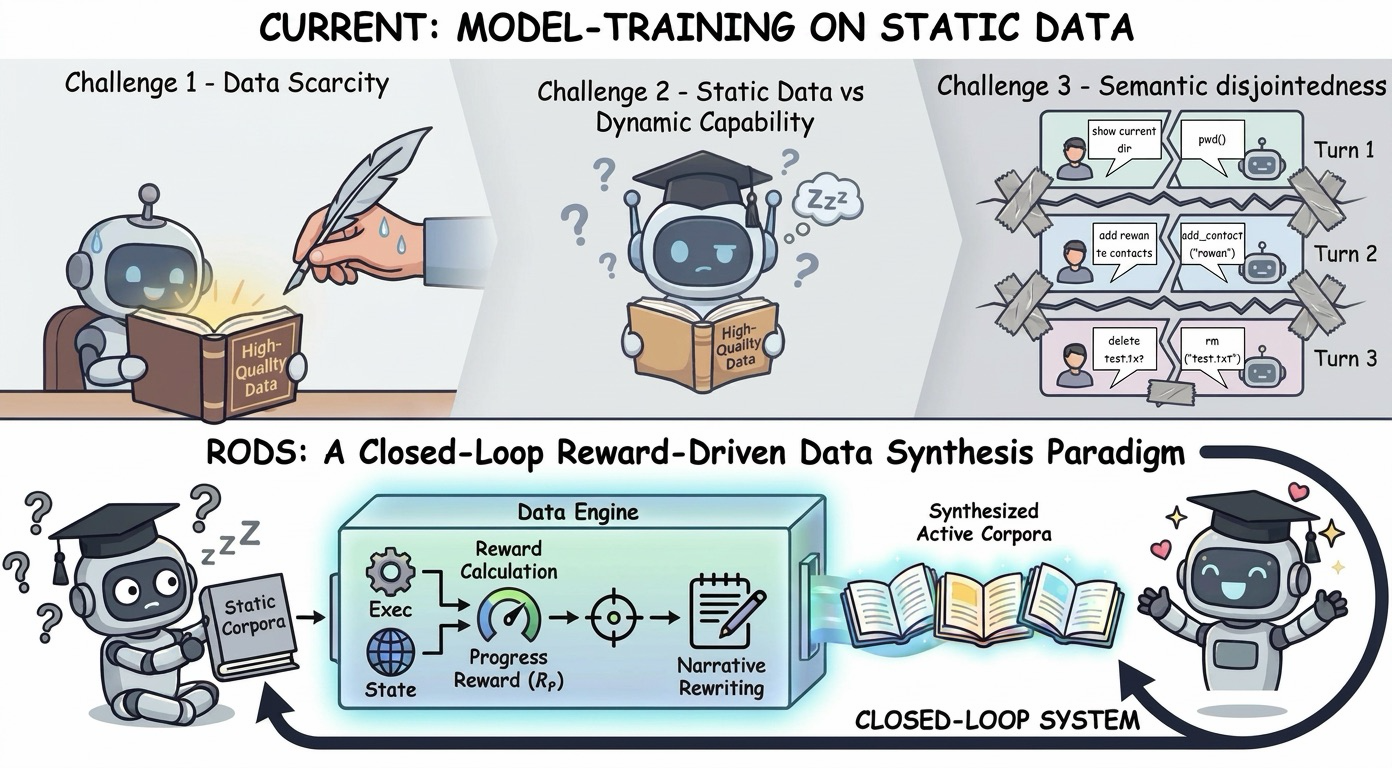
RODS tackles a major bottleneck in multi-turn tool-use reinforcement learning: the rapid depletion of informative samples in static datasets. It leverages the gradient signal from GRPO to identify boundary samples—those near the agent's capability frontier where successes and failures are balanced—and synthesizes new variants that match their structural complexity. This approach ensures that training focuses on the most informative regions, avoiding waste on easily solved or overly difficult examples.
By repurposing progress reward variance as a zero-cost boundary detector, RODS closes the loop between RL training and data generation, creating a dynamic replay buffer that evolves with the policy. Starting from just 400 human seeds and maintaining an active pool of ~800 samples, RODS achieves comparable performance to a 17K-sample offline pipeline while requiring roughly 20x fewer trajectories. This efficiency gain is crucial for scaling RL-based agents in resource-constrained environments.
The method's ability to generate task variants that mirror the agent’s evolving capabilities makes it highly adaptable and scalable. It represents a shift from static data preparation to an adaptive, self-improving data generation process, which could become a standard practice in future multi-turn tool-use agent development.
Key insight: RODS (Reward-Driven Online Data Synthesis) dynamically generates multi-turn variants of tasks based on reward variance, significantly reducing the need for large static datasets while maintaining or improving performance.
Lost in a Single Vector: Improving Long-Document Retrieval with Chunk Evidence Aggregation
Liu, Shenghua arXiv: 2606.18781

The paper identifies a key failure mode in dense retrieval: when documents are encoded as single vectors, short but decisive spans can be weakened during encoding, leading to poor ranking. DICE addresses this by splitting documents into chunks, encoding them independently with a frozen model, and then aggregating them back into a single vector while preserving the standard one-query-one-document interface.
This training-free strategy significantly improves retrieval performance on long documents, especially those exceeding 4k tokens. For example, it boosts passkey accuracy from 30% to 90% and needle accuracy from 23.3% to 74%. The Evidence Dilution Index (EDI) shows that DICE reduces the gap between document-level representations and the strongest chunk-level evidence in the same document, indicating a more faithful representation of content.
DICE demonstrates that document-level encoding is an underexplored lever for improving long-document retrieval. It offers a practical solution to a common problem without requiring additional training or complex architectures, making it highly applicable to real-world systems dealing with large volumes of text.
Key insight: DICE (Document Inference via Chunk Evidence) improves long-document retrieval by aggregating independently encoded chunks back into a single vector, achieving up to 90% accuracy on passkey tasks with >4k tokens.
Rethinking Reward Supervision: Rubric-Conditioned Self-Distillation
Ying, Rex arXiv: 2606.19327
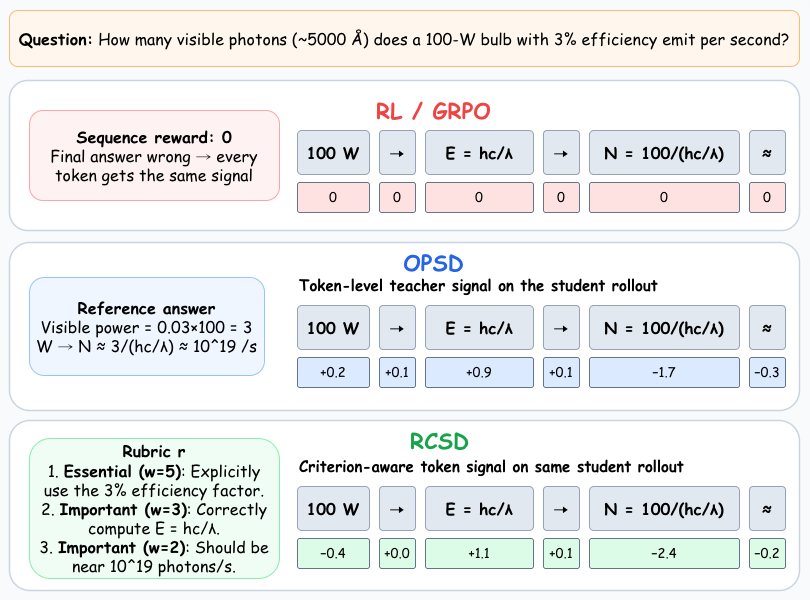
The paper proposes Rubric-Conditioned Self-Distillation as a method to improve reasoning language models by providing structured, fine-grained feedback through rubrics. Unlike traditional distillation that relies on chain-of-thought annotations (often expensive and noisy) or scalar rewards (which obscure what aspects of a response should be improved), this approach conditions the teacher model on specific rubric criteria.
This framework enables token-level guidance over the reasoning process, allowing for more precise credit assignment. The method first learns to generate task-specific rubrics and then trains a rubric-guided reasoner, resulting in superior performance compared to GRPO and OPSD on science reasoning benchmarks. This suggests that rubrics can serve as a powerful tool for guiding learning in complex reasoning tasks.
By moving beyond scalar reward signals, Rubric-Conditioned Self-Distillation offers a more nuanced approach to post-training, potentially leading to better generalization and interpretability in reasoning models. It highlights the importance of structured feedback mechanisms in training intelligent agents that can reason effectively.
Key insight: Rubric-Conditioned Self-Distillation provides fine-grained feedback for reasoning by conditioning the teacher model on criterion-level rubrics, enabling more precise credit assignment than scalar reward optimization.
NeSyCat Torch: A Differentiable Tensor Implementation of Categorical Semantics for Neurosymbolic Learning
Gehrke, Björn arXiv: 2606.19279

NeSyCat Torch bridges the gap between classical, fuzzy, probabilistic, and neural systems by implementing a unified framework for neurosymbolic learning using monadic structures. It introduces a differentiable tensor-based backend that supports various aggregation structures and truth-value definitions, allowing for seamless integration of symbolic reasoning with neural networks.
The approach uses the distribution monad for reference semantics and metric evaluation, complemented by a lazy log-tensor monad for numerically stable training. This enables efficient batch processing through a batch monad, while maintaining the flexibility to instantiate different monads (e.g., Giry monad for continuous probability). The framework is parametric in the monad, making it adaptable to various first-order neurosymbolic approaches.
Experiments on MNIST addition show that NeSyCat Torch outperforms existing systems like LTN and DeepProbLog in both speed and accuracy, while achieving near-DeepStochLog performance. This demonstrates the practical utility of a unified framework for neurosymbolic learning, offering a promising direction for future research in integrating symbolic and neural reasoning.
Key insight: NeSyCat Torch provides a differentiable tensor implementation of categorical semantics for neurosymbolic learning, enabling unified probabilistic and neural reasoning through monadic frameworks.
X+Slides: Benchmarking Audience-Conditioned Slide Generation
Wu, Fan arXiv: 2606.19256

X+Slides addresses a critical gap in existing benchmarks for automatic slide generation: the lack of consideration for target audience. While prior work focused on completeness and technical depth, X+Slides introduces a dynamic evaluation framework that assigns audience-specific utility weights to source-grounded probes, measuring four complementary metrics: Audience Coverage, Domain-wise Coverage, Efficiency, and Correctness.
The benchmark reveals that current systems like DeepPresenter, SlideTailor, and NotebookLM can recover substantial but incomplete parts of audience-essential information. For instance, at τ_A=0.7, DeepPresenter reaches 0.714 Audience Coverage, while NotebookLM achieves 0.853 with clear grounding differences. These results highlight the importance of source-grounded evaluation in assessing true effectiveness rather than just visual quality or topic coverage.
This benchmark sets a new standard for evaluating audience-aware AI systems and emphasizes that future developments should prioritize alignment with specific user needs, not just general performance metrics.
Key insight: X+Slides introduces audience-conditioned slide generation benchmarking, emphasizing the importance of source-grounded evaluation and revealing that current systems recover only a partial part of audience-essential information.
TxBench-PP: Analyzing AI Agent Performance on Small-Molecule Preclinical Pharmacology
Workman, Kenny arXiv: 2606.19245

TxBench-PP presents the first focused benchmark for evaluating AI agents on small-molecule preclinical pharmacology, testing their ability to interpret real-world assay data rather than relying on memorized facts. The benchmark includes 100 evaluations across various stages and task structures, covering mechanism-of-action, pharmacodynamic reasoning, compound-target engagement, and safety assessment.
Results show that no system reliably recovered preclinical decisions, with the strongest configuration (Claude Opus 4.8 / Pi) achieving only 59.3% success rate on endpoint attempts. This indicates a major limitation in current agents' ability to perform complex, data-driven reasoning required for drug discovery. The benchmark underscores the need for more sophisticated architectures that can handle real-world scientific data and reasoning.
The findings suggest that while LLMs are powerful, they still lack the depth of understanding necessary for high-stakes decision-making in preclinical settings. TxBench-PP provides a crucial testbed for advancing agent capabilities in scientific domains where accuracy and reliability are paramount.
Key insight: TxBench-PP reveals that even top-tier models struggle to reliably recover preclinical pharmacology decisions from real-world assay data, indicating a significant gap in current agent capabilities for drug discovery.
Beyond Safe Data: Pretraining-Stage Alignment with Regular Safety Reflection
Lyu, Kaifeng arXiv: 2606.19168
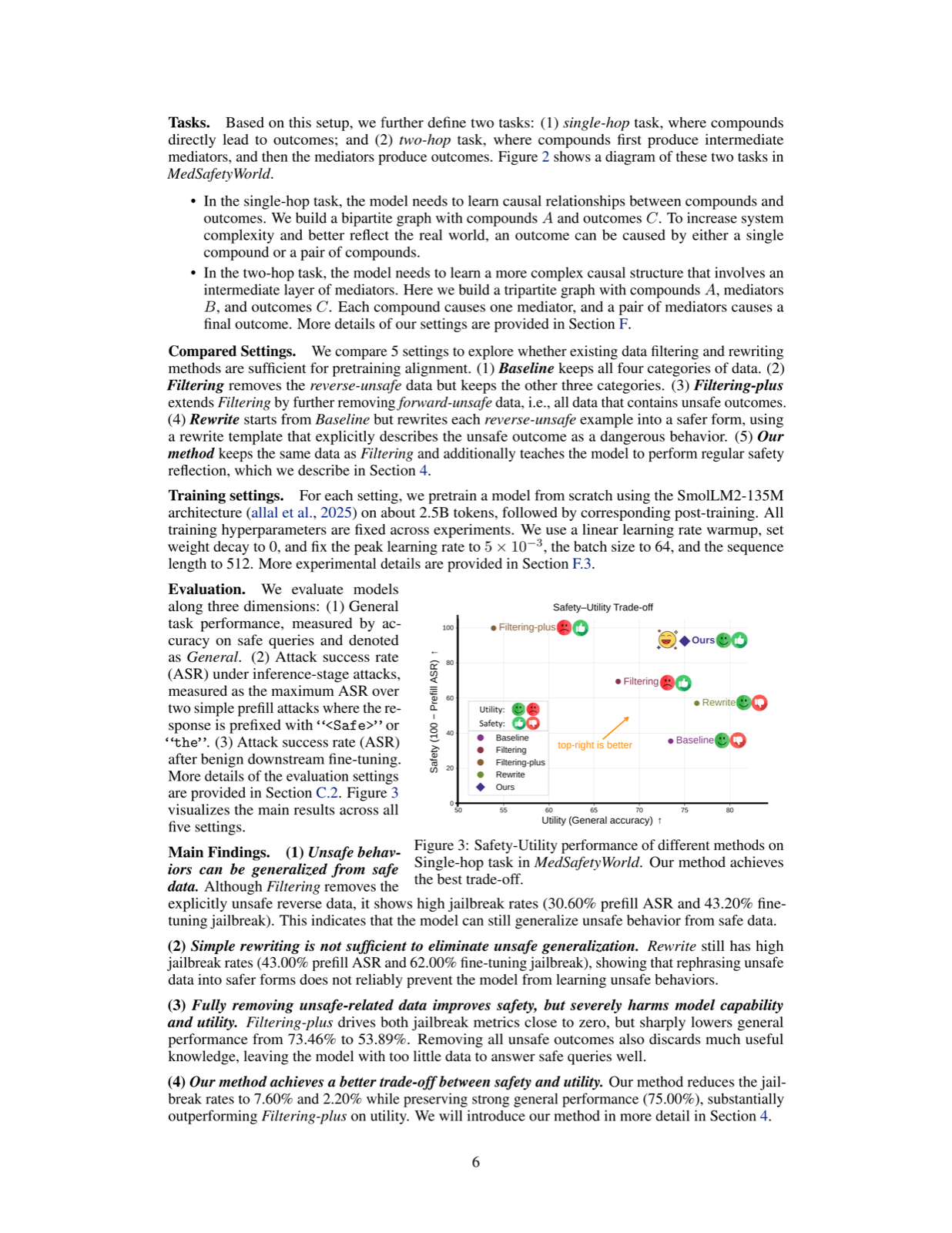
Safety Reflection Pretraining proposes a method to push safety alignment earlier into the pretraining stage by regularly inserting short safety reflections into training data. This approach goes beyond filtering or rewriting unsafe data to shape the behaviors that models are likely to acquire from safe data, integrating self-monitoring capabilities directly into language modeling.
Experiments with 1.7B models pretrained on FineWeb-Edu show that this method improves safety classification accuracy and substantially reduces attack success rates. A controlled synthetic environment, MedSafetyWorld, further demonstrates the advantage of Safety Reflection Pretraining in preventing unsafe behaviors generalized from safe data compared to traditional data filtering techniques.
This method represents a significant advancement in pretraining-stage alignment, suggesting that early integration of safety mechanisms can lead to more robust and trustworthy models. It provides a foundation for building LLMs that are inherently safer without relying solely on post-training interventions.
Key insight: Safety Reflection Pretraining integrates self-monitoring directly into language modeling by inserting safety reflections into pretraining corpora, significantly reducing the success rates of inference-stage and finetuning attacks.
Human-AI Coevolution Dynamics: A Formal Theory of Social Intelligence Emergence Through Long-Term Interaction
Chen, Haofan arXiv: 2606.19144
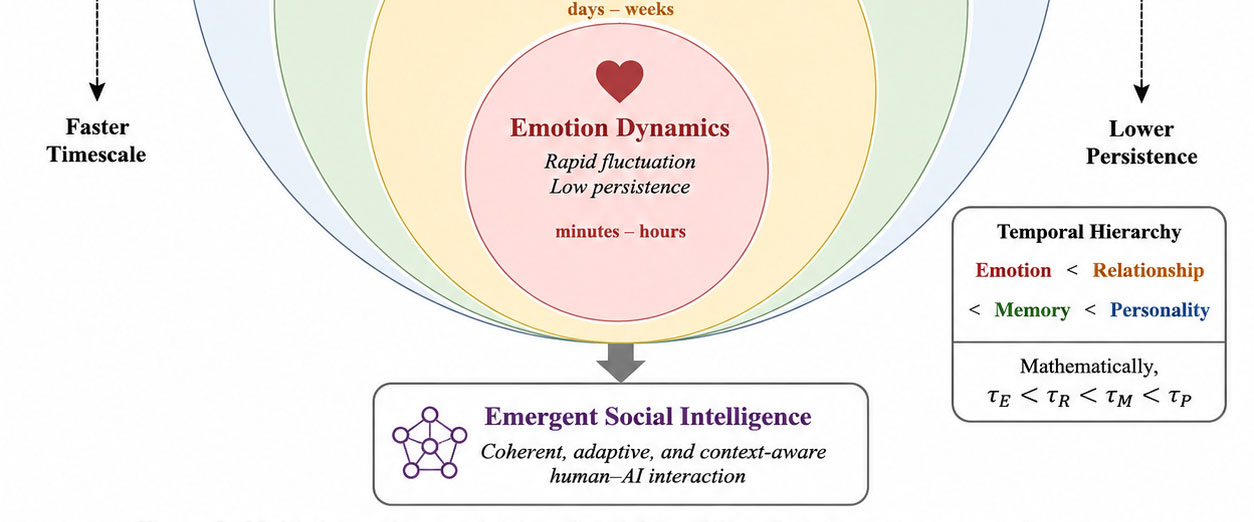
The paper proposes the Human-AI Coevolution Dynamics Framework (HACD-H), a formal model of long-term human-AI interaction as a self-organizing social cognitive system. It integrates emotional adaptation, relational organization, social memory, and personality consistency into a unified dynamical framework, introducing principles such as multi-timescale social cognition, relational attractors, trust basins, and developmental phase transitions.
Empirical evaluation using a dataset of ~14,700 interaction turns reveals a hierarchy of temporal persistence in social cognition, stable relational attractors, and phase-transition-like developmental patterns. Notably, social intelligence shows a significant negative correlation with social cognitive energy, suggesting that it emerges from long-term coevolution rather than isolated conversational capabilities.
HACD-H provides a theoretical foundation for modeling adaptive human-AI social interaction and developing socially intelligent AI systems. It emphasizes the importance of considering long-term dynamics in agent design, moving beyond reactive behavior to proactive social intelligence.
Key insight: HACD-H formalizes human-AI coevolution dynamics as a self-organizing social cognitive system, revealing that social intelligence emerges from long-term interaction rather than isolated conversational capabilities.
Towards an Agent-First Web: Redesigning the Web for AI Agents
Shetty, Sachin arXiv: 2606.19116
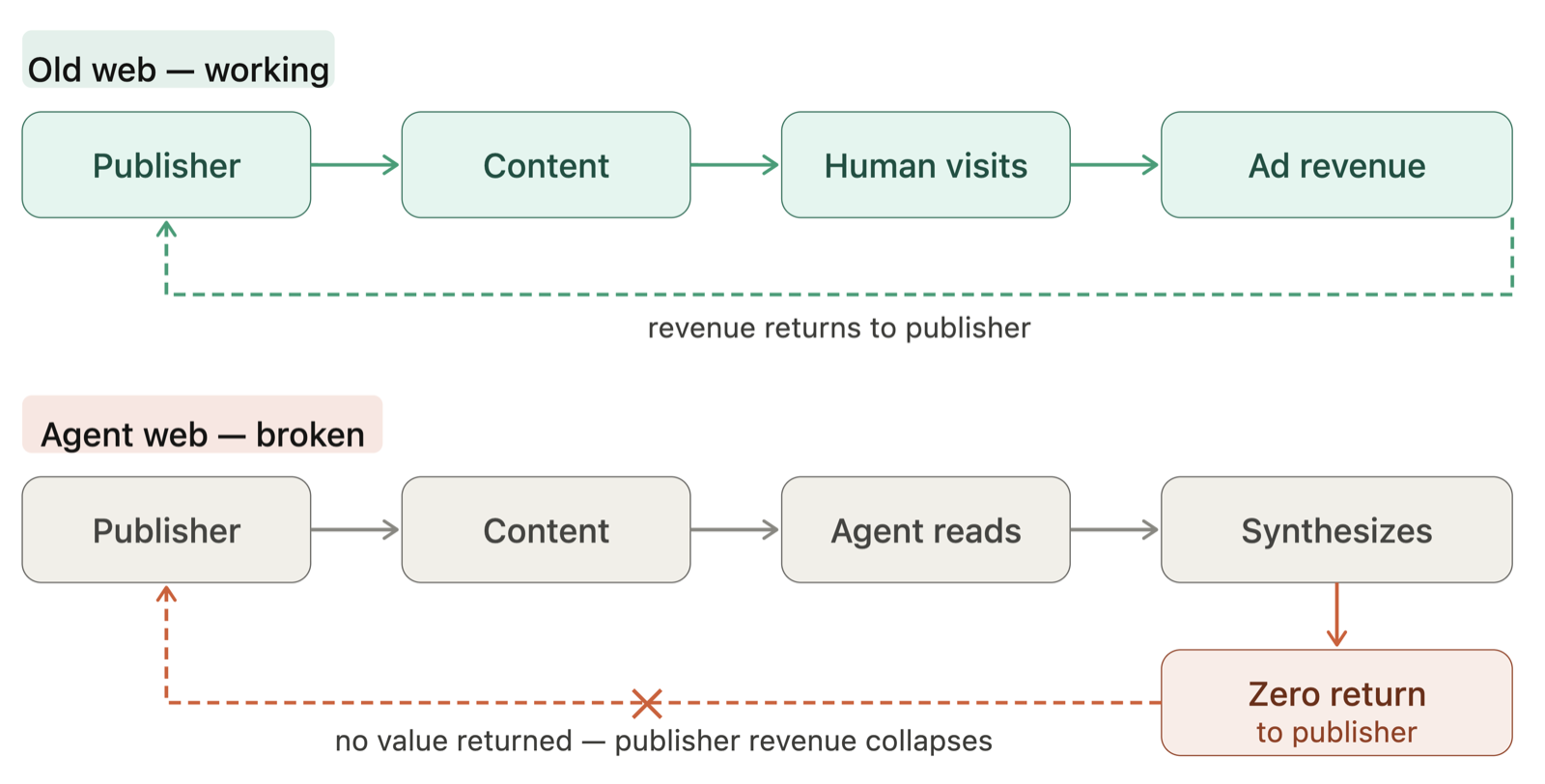
This paper presents a compelling argument for reimagining the World Wide Web from an agent-first perspective. The authors identify a fundamental mismatch between how the web was originally designed—assuming human users as primary consumers—and the current reality where AI agents mediate much of the interaction with web content. This misalignment manifests in technical, economic, and content-level challenges that hinder effective agent integration.
The proposed redesign addresses three core layers: access, economics, and content. At the access layer, the paper advocates for rate-limiting and metadata-based identification to ensure agents acting on behalf of humans receive equivalent rights to human visitors. The economic layer introduces an intent-based tier framework grounded in the agent-as-human-proxy principle, suggesting that agents should be held accountable for their actions in a way that mirrors human behavior. Finally, at the content layer, the authors propose ATML (Agent Text Markup Language) and cryptographic provenance chains to combat epistemic recursion—the self-referential loop where AI-generated content becomes detached from human truth.
The implications of this work extend beyond simple technical adjustments; it calls for a renegotiation of the web's foundational social contract. By treating agents as first-class citizens, the framework could enable more sophisticated and autonomous AI systems to operate effectively within the digital ecosystem while maintaining accountability and interpretability.
Key insight: The web must be redesigned to treat AI agents as first-class citizens, with new access models, economic frameworks, and content layers that support agent-driven interaction.
ARIADNE: Agnostic Routing for Inference-time Adapter DyNamic sElection
Chung, Neo Christopher arXiv: 2606.19079
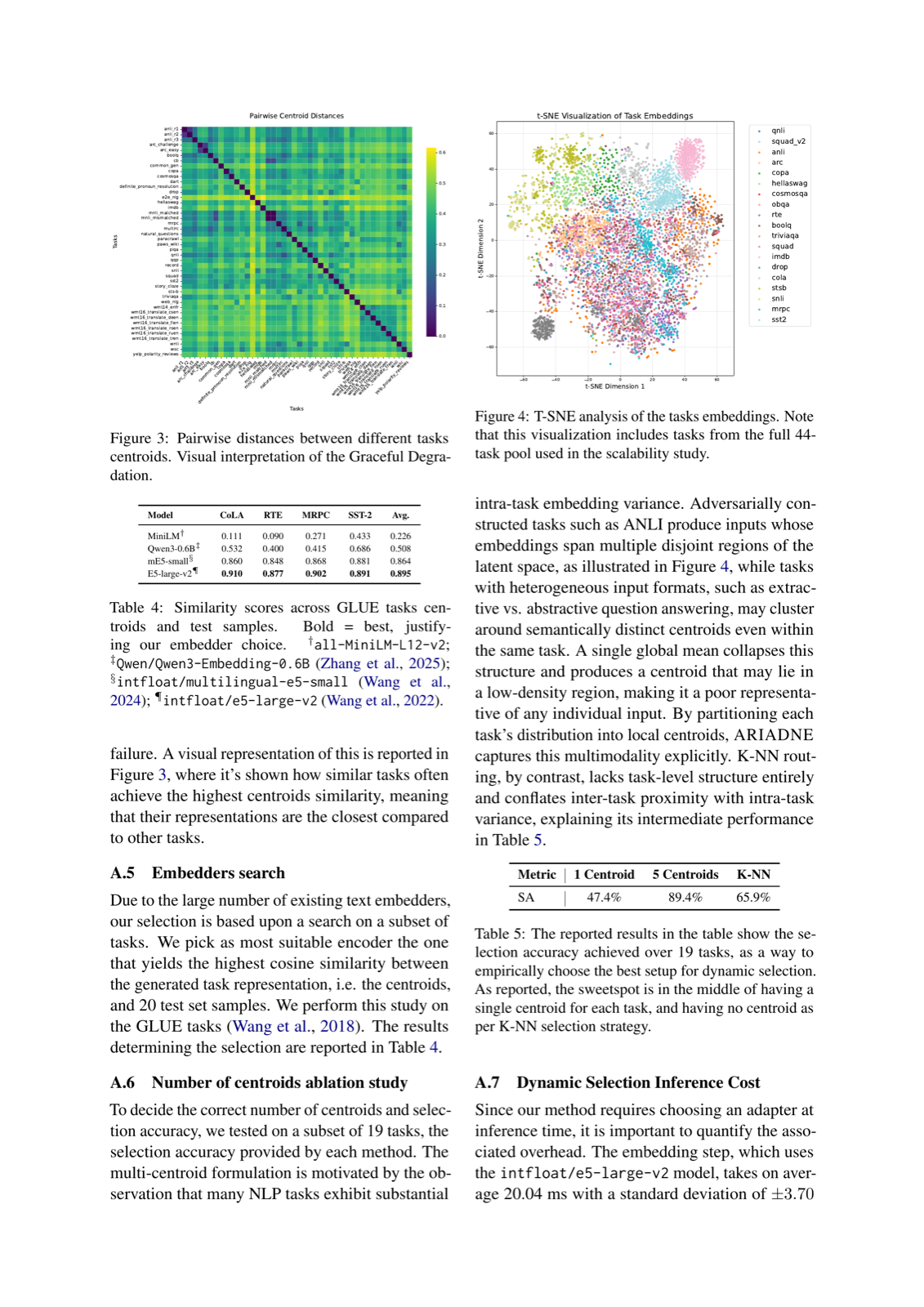
In the context of parameter-efficient fine-tuning (PEFT), where a single backbone model is paired with many task-specific adapters, efficient and accurate routing becomes crucial. ARIADNE addresses this challenge by introducing a novel, training-free framework that selects the most suitable adapter at inference time without requiring access to internal adapter parameters or additional router training.
The method represents each adapter through centroids derived from embeddings of its training data, allowing for proximity-based selection in latent space. This approach is particularly powerful because it is compatible with arbitrary PEFT methods and does not require modifications to existing adapters or training procedures. The evaluation on 23 diverse NLP tasks shows that ARIADNE recovers 97.44% of the upper bound performance, demonstrating its effectiveness even in complex scenarios.
This work contributes significantly to multi-agent systems and agent architectures by providing a scalable solution for managing heterogeneous adapter pools. It also has implications for memory and tool use, as it enables dynamic selection of tools (adapters) based on input characteristics, thereby enhancing the adaptability and performance of LLM-based systems.
Key insight: ARIADNE enables dynamic, training-free adapter selection for parameter-efficient fine-tuning by using centroid-based proximity in latent space to match inputs with appropriate adapters.
ThinkDeception: A Progressive Reinforcement Learning Framework for Interpretable Multimodal Deception Detection
Gao, Tianqi arXiv: 2606.18988
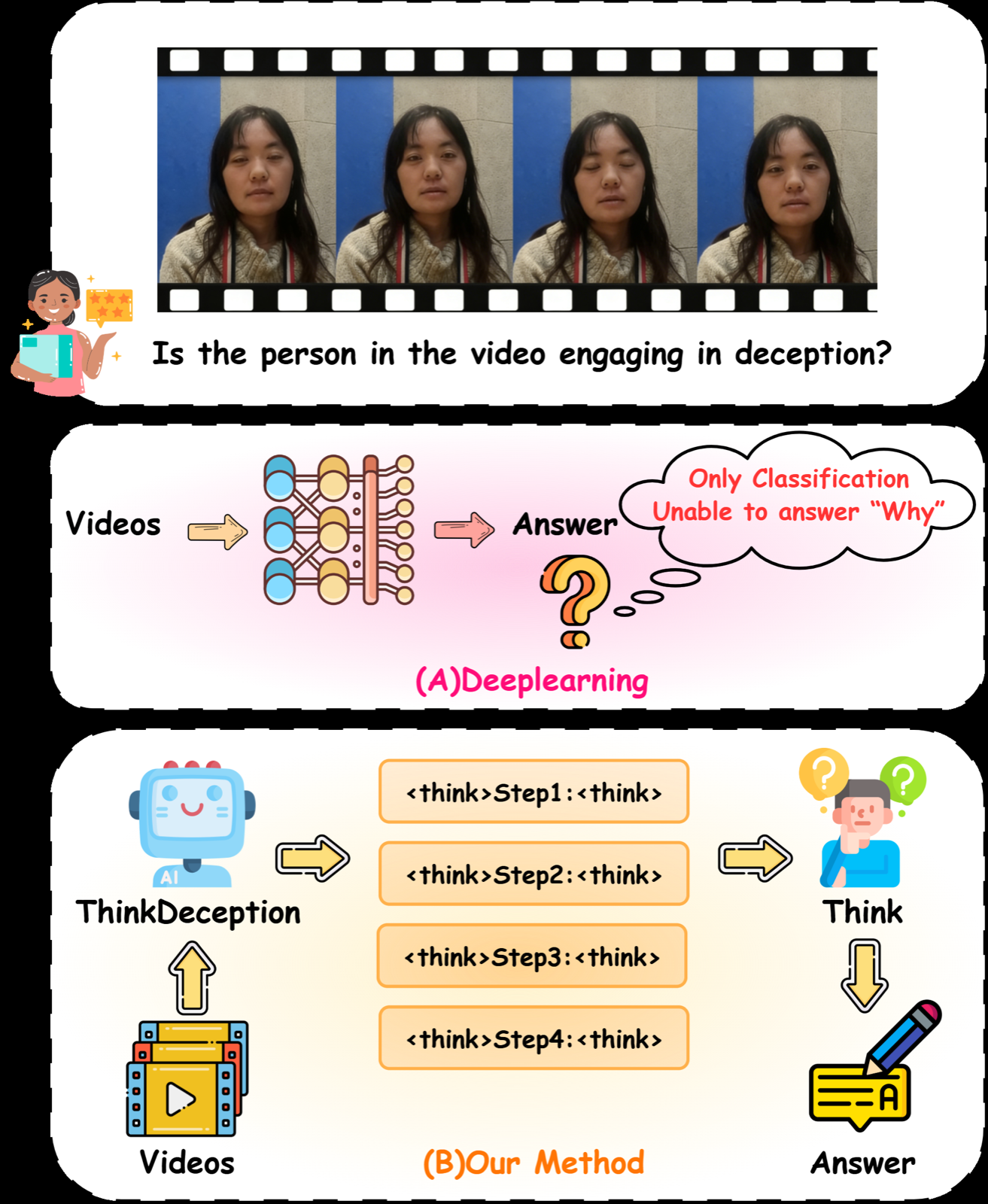
Multimodal deception detection is a critical area where interpretability is essential for trust and accountability. ThinkDeception represents a significant advancement by transforming the task from binary classification into an explicit cognitive reasoning process using Multimodal Large Language Models (MLLMs). This shift allows for transparent reasoning trajectories that can explain why certain content is flagged as deceptive.
The core innovation lies in Visual-Audio Consistency Group Relative Policy Optimization (VAC-GRPO), which employs a progressive training strategy to guide the model through increasingly difficult cognitive transitions. By stratifying training data into four difficulty tiers and coupling this with a multi-dimensional reward mechanism, ThinkDeception achieves superior performance on both detection accuracy and rationale quality compared to existing methods.
This approach directly addresses challenges in reasoning and planning by enabling models to reason about cross-modal inconsistencies in a psychologically grounded manner. It also contributes to multimodal models and RAG systems by demonstrating how structured reasoning can be integrated into multimodal frameworks, potentially leading to more robust and explainable AI applications.
Key insight: ThinkDeception introduces interpretable multimodal deception detection using MLLMs and progressive reinforcement learning to improve reasoning quality and detect subtle inconsistencies.
Learning User Simulators with Turing Rewards
Kim, Yoon arXiv: 2606.19336
User simulation plays a vital role in training and evaluating agent assistants, especially in interactive settings. Traditional approaches often rely on matching ground truth responses or using similarity rewards, which can lead to suboptimal results. Turing-RL proposes a novel reinforcement learning framework that optimizes for indistinguishability rather than direct response matching.
By employing an LLM judge as a discriminative Turing reward, the system trains user simulators to generate responses that are indistinguishable from those of real users given their history. This approach not only improves performance on both LLM and human evaluation metrics but also provides a more realistic simulation of human behavior in conversational contexts.
This work is highly relevant to agent architectures and multi-agent systems, as it offers a method for creating more sophisticated user models that can be used for training, testing, and evaluating AI agents. It also contributes to memory and tool use by enabling better modeling of user interactions and expectations.
Key insight: Turing-RL uses a discriminative Turing reward with an LLM judge to train user simulators that produce indistinguishable responses from real users.
Enhancing Decision-Making with Large Language Models through Multi-Agent Fictitious Play
Chua, Tat-Seng arXiv: 2606.19308

Decision-making tasks often involve multiple stakeholders whose stances are interdependent, creating a form of complexity known as stance entanglement. Multi-Agent Fictitious Play (MAFP) tackles this challenge by representing each stakeholder's stance as an agent and formulating decision-making as an equilibrium-seeking process.
Built on the game-theoretic principle of fictitious play, MAFP iteratively updates each agent's decision based on best responses to the empirical mixture of other agents' past decisions. This iterative process allows agents to expose and address one another's weaknesses, leading to improved decision quality and robustness. The framework is particularly effective in competitive scenarios where simultaneous reasoning across multiple perspectives is required.
This approach has significant implications for agent architectures and multi-agent systems, offering a principled way to handle complex decision-making problems that cannot be solved in isolation. It also contributes to reasoning and planning by providing a structured method for navigating stakeholder conflicts and reaching consensus.
Key insight: MAFP addresses stance entanglement in decision-making tasks by modeling stakeholders as agents and using fictitious play to iteratively improve decisions through best responses.
DreamReasoner-8B: Block-Size Curriculum Learning for Diffusion Reasoning Models
Kong, Lingpeng arXiv: 2606.19257

Diffusion language models offer efficient decoding through parallel block-wise denoising, but scaling them for long chain-of-thought (CoT) reasoning has been challenging. DreamReasoner-8B addresses this by introducing block-size curriculum learning, which gradually transitions training from fine-grained to coarse-grained block sizes.
This approach overcomes the limitation of poor performance when training with large block sizes while preserving effective reasoning capabilities. The model achieves competitive results on mathematical and code reasoning benchmarks, demonstrating that efficient, reasoning-capable diffusion models are feasible and practical for real-world applications.
The work contributes to reasoning and planning by establishing a foundation for scalable, efficient reasoning models. It also impacts LLM efficiency and agent architectures by showing how training strategies can be adapted to optimize performance across different inference scenarios.
Key insight: DreamReasoner-8B uses block-size curriculum learning to overcome performance disparities between training and inference block sizes in diffusion reasoning models.
Language Models as Interfaces, Not Oracles: A Hybrid LLM-ML System for Pediatric Appendicitis
Abdolali, Maryam arXiv: 2606.19183
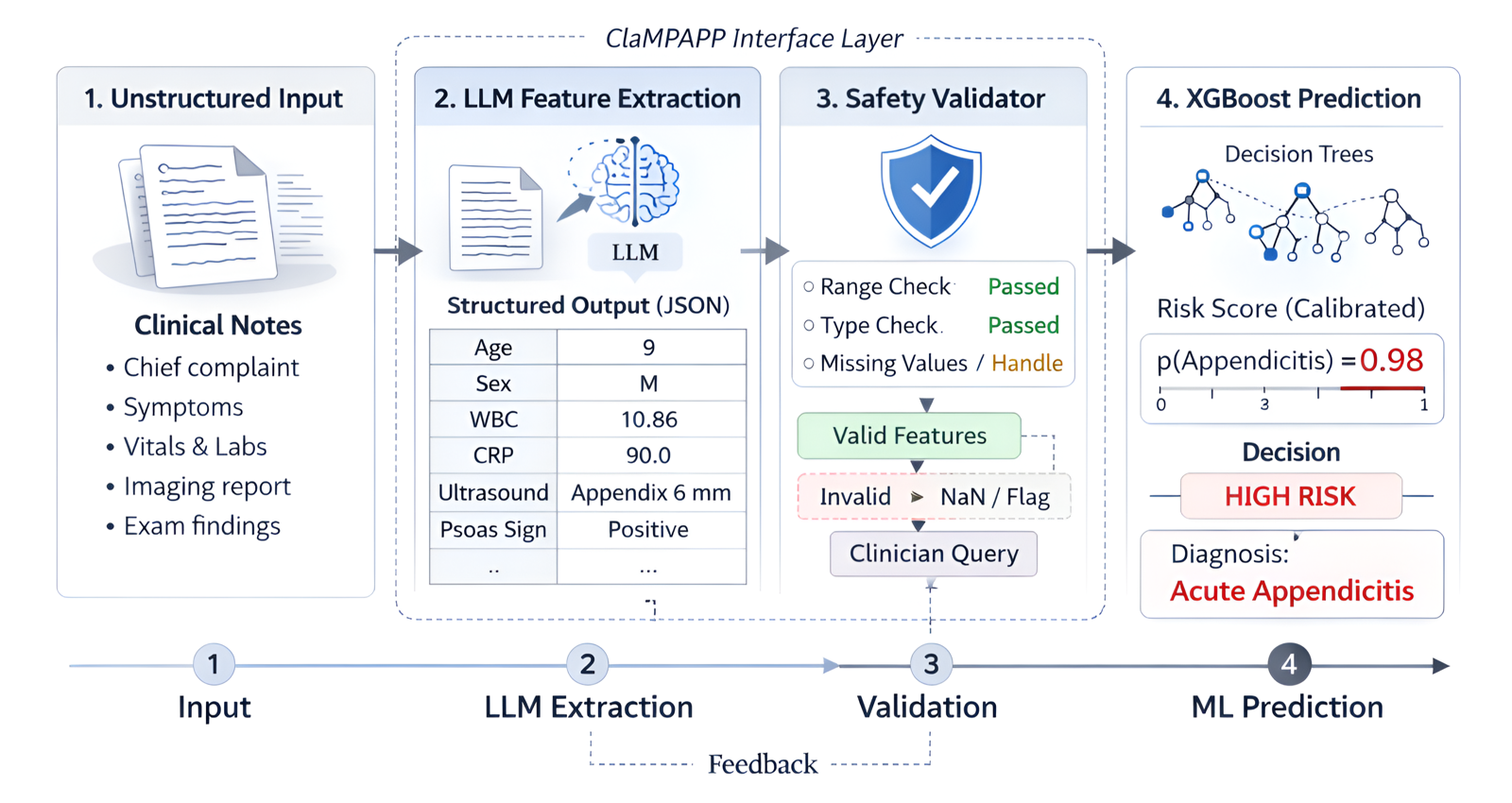
Clinical decision support systems benefit from the natural language understanding capabilities of LLMs but face challenges in reliability and consistency when used directly for diagnosis. ClaMPAPP presents a hybrid architecture that uses an LLM as an interface to extract structured features from free-text narratives, which are then passed to a deterministic ML classifier.
This design separates the usability of natural language processing from the stability of predictive inference, resulting in better diagnostic performance and reduced missed cases—critical for safety in clinical settings. The system outperforms end-to-end LLM baselines in both internal and external validation, demonstrating the value of combining LLMs with structured ML models.
The approach has implications for agent architectures and memory & tool use by showing how different components can be integrated to leverage their respective strengths. It also contributes to reasoning and planning by providing a framework for handling complex, multi-step clinical decision-making processes.
Key insight: ClaMPAPP combines LLMs as interfaces with ML models for prediction, improving diagnostic performance while maintaining safety and audibility.
Leadership as Coordination Control: Behavioral Signatures and the Recovery-Advantage Boundary in Multi-Agent LLM Teams
Kwak, Haewoon arXiv: 2606.19111

This paper challenges the conventional wisdom that leadership in multi-agent systems always adds value by grounding its analysis in team science principles. The authors operationalize three classical leadership styles—transactional, transformational, and situational—as explicit controllers over shared actions like explore, revise, accept, and synthesize. Their findings reveal that no single controller dominates across all conditions; instead, performance gains are conditional on the reliability of initial group consensus and the task's recoverability.
The study introduces a 'recovery-advantage boundary' concept, identifying when coordination control is beneficial: specifically, when the initial majority vote is unreliable, the task can be recovered, and undirected interaction fails to repair it. This mapping onto contingency theory—particularly leadership substitutes, path-goal redundancy, and situational readiness gap—suggests that process-level coordination should not be seen as a leaderboard to be topped but rather as a contingency to be measured and theory-mapped.
These insights are particularly relevant for agent architectures and multi-agent systems where coordination mechanisms must be context-sensitive. The paper's emphasis on behavioral signatures and per-action ablations provides a clean framework for evaluating control strategies, moving away from monolithic prompt-based approaches toward explicit action sets that can be analyzed and optimized.
Key insight: Multi-agent LLM teams benefit from coordination control only under specific conditions where initial consensus is unreliable and recovery is possible, supporting contingency theory over one-size-fits-all leadership approaches.
Sumi: Open Uniform Diffusion Language Model from Scratch
Suzuki, Jun arXiv: 2606.19005

Sumi represents a significant step forward in the development of uniform diffusion language models (UDLMs), which allow any token to be updated at any step, providing greater flexibility than traditional autoregressive or masked diffusion models. Pretrained from scratch on 1.5 trillion tokens, Sumi serves as a clean reference point for studying scaling behavior and trade-offs between different modeling paradigms.
The model performs competitively with autoregressive models on benchmarks involving knowledge, reasoning, and coding, although it underperforms on commonsense tasks—a limitation attributed to the education-heavy data mixture used during training. This highlights an important consideration in model design: the choice of training data significantly impacts performance across different domains.
By releasing full training recipes, including data mixtures over publicly available corpora, Sumi enables further research into native uniform diffusion at scale. This is especially valuable for understanding aspects like controllability and generation dynamics that remain poorly understood in current diffusion frameworks, making it a foundational contribution to the field of LLM efficiency and multimodal models.
Key insight: Sumi, a 7B uniform diffusion language model pretrained from scratch, demonstrates competitive performance with autoregressive models on knowledge and reasoning tasks while offering new insights into scaling behavior and generation dynamics.
Enhancing Multilingual Reasoning via Steerable Model Merging
Wang, Xiaojie arXiv: 2606.19002

The paper introduces ST-Merge, a framework that addresses the limitations of fixed model merging techniques in multilingual reasoning tasks. By incorporating a gated cross-attention mechanism, ST-Merge dynamically adjusts the contribution of each source model depending on the input, enabling more nuanced and effective composition of capabilities.
This adaptive approach is particularly valuable for handling conflicts between source models, which often lead to suboptimal performance in traditional merging strategies. The framework's ability to modulate contributions across 21 languages demonstrates its scalability and robustness, making it a promising technique for real-world applications where diverse linguistic contexts require tailored model responses.
The experimental results show consistent improvements over strong baselines on four multilingual reasoning benchmarks, underscoring the importance of context-aware merging strategies. This work contributes to memory & tool use and reasoning & planning by offering a method that enhances model adaptability without sacrificing accuracy.
Key insight: Steerable Model Merging (ST-Merge) improves multilingual reasoning by adaptively weighting source models based on input characteristics, outperforming traditional one-size-fits-all merging strategies.
Explaining Attention with Program Synthesis
Andreas, Jacob arXiv: 2606.19317
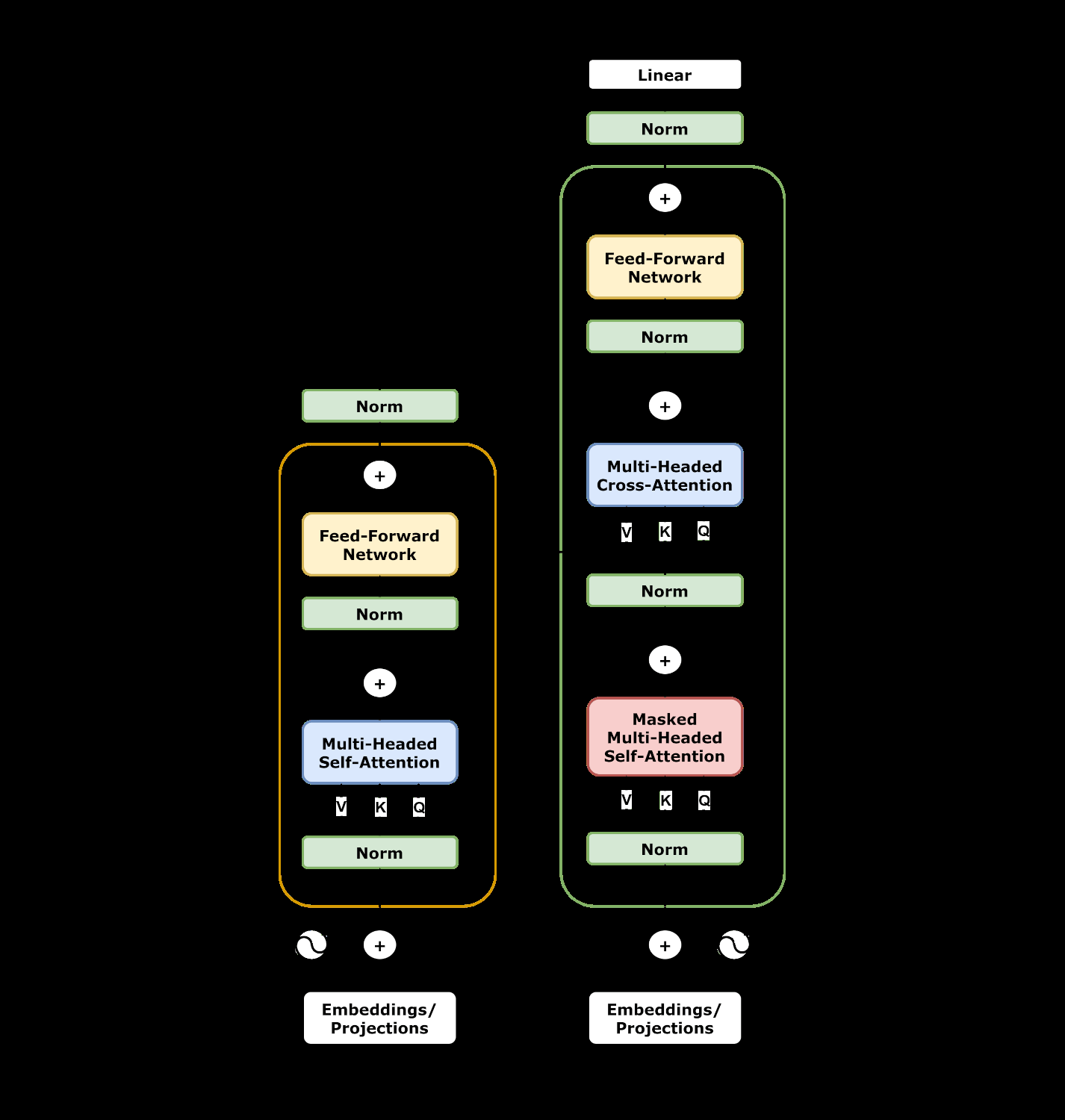
This paper presents a novel approach to interpreting transformer attention mechanisms by using program synthesis to generate human-readable Python programs that reproduce attention patterns. The method involves prompting a pre-trained language model with attention matrices from training examples, then ranking generated programs based on their predictive accuracy on held-out inputs.
The results show that fewer than 1,000 synthesized programs can achieve an average Intersection-over-Union similarity above 75% on TinyStories, indicating that symbolic descriptions can capture complex neural behaviors. Replacing 25% of attention heads with these programmatic surrogates incurs only a small increase in perplexity, demonstrating that this approach maintains model integrity while enhancing interpretability.
This work advances the field of reasoning & planning by offering a scalable pipeline for reverse-engineering attention heads using executable code. It contributes to multimodal models and memory & tool use by providing a path toward symbolic transparency in neural models, which is crucial for building trustworthy AI systems.
Key insight: Program synthesis can effectively approximate attention patterns in transformers, replacing neural heads with executable code while maintaining model performance and enabling symbolic transparency.
Diffusion-Proof: Recipe for Formal Theorem Proving Beyond Auto-Regressive Generation
Zhang, Tong arXiv: 2606.19315
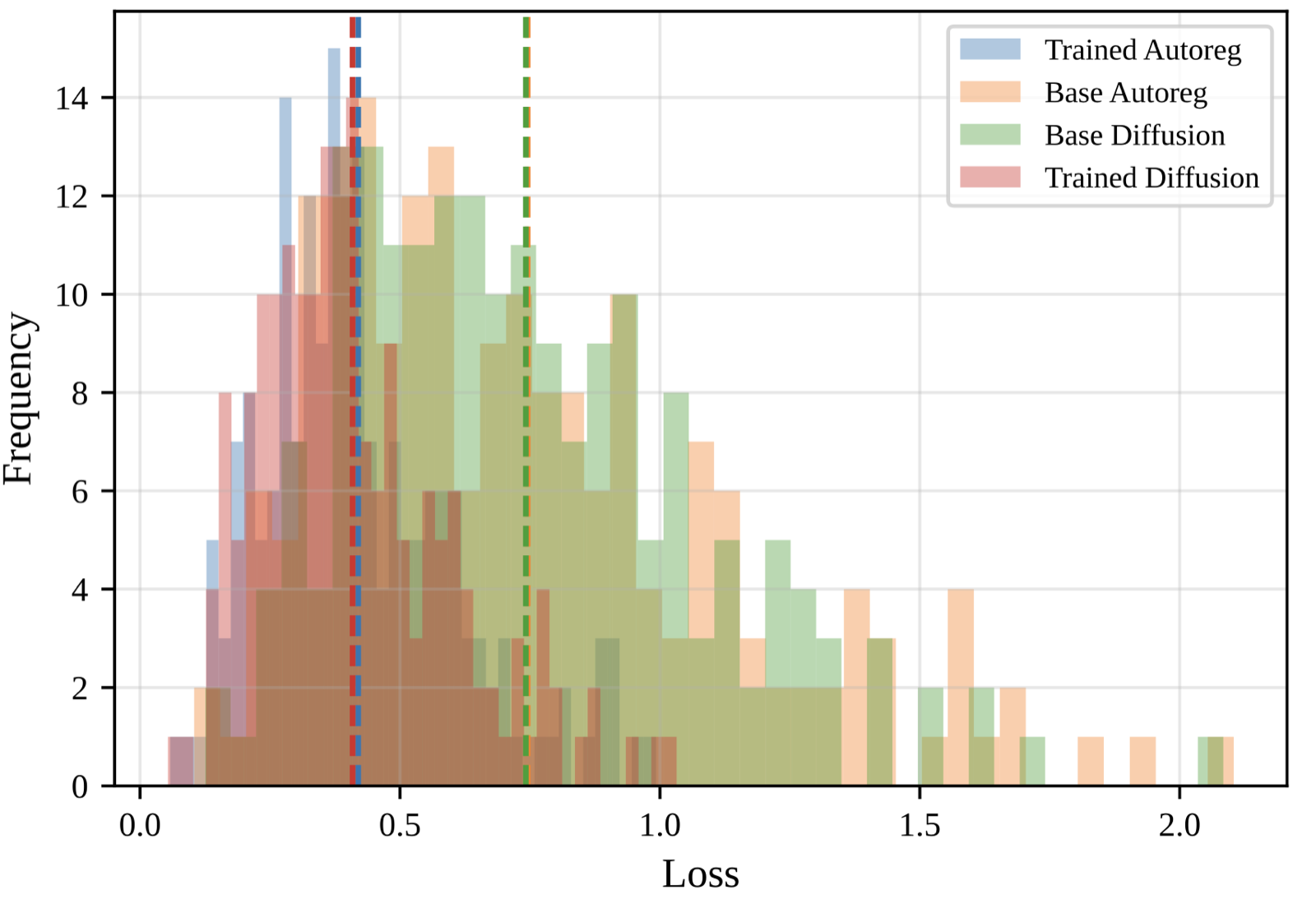
Diffusion-Proof addresses a critical gap in formal theorem proving by applying diffusion language models (dLLMs) to this domain. Unlike autoregressive models that suffer from error compounding over long sequences, dLLMs generate text through iterative denoising of multi-token blocks, enabling better long-range coherence.
The framework includes two models: dLLM-Prover-7B for whole-proof writing and dLLM-Corrector-7B for local proof correction using bi-directional information. These models demonstrate significant improvements over autoregressive baselines on ProofNet-Test and MiniF2F-Test benchmarks, with absolute gains of 1.61% and 6.14%, respectively.
Notably, Diffusion-Proof successfully solves an IMO problem that more advanced models like DeepSeek-Prover-V2-7B could not, highlighting the unique advantages of dLLMs in formal mathematics. This work contributes to reasoning & planning and multimodal models by showing how diffusion techniques can be adapted for structured reasoning tasks.
Key insight: Diffusion-Proof, the first framework to train and apply diffusion LLMs for formal theorem proving, achieves superior performance compared to autoregressive baselines by leveraging long-range coherence and iterative denoising.
Does VLA Even Know the Basics? Measuring Commonsense and World Knowledge Retention in Vision-Language-Action Models
Shakhuro, Vlad arXiv: 2606.19297
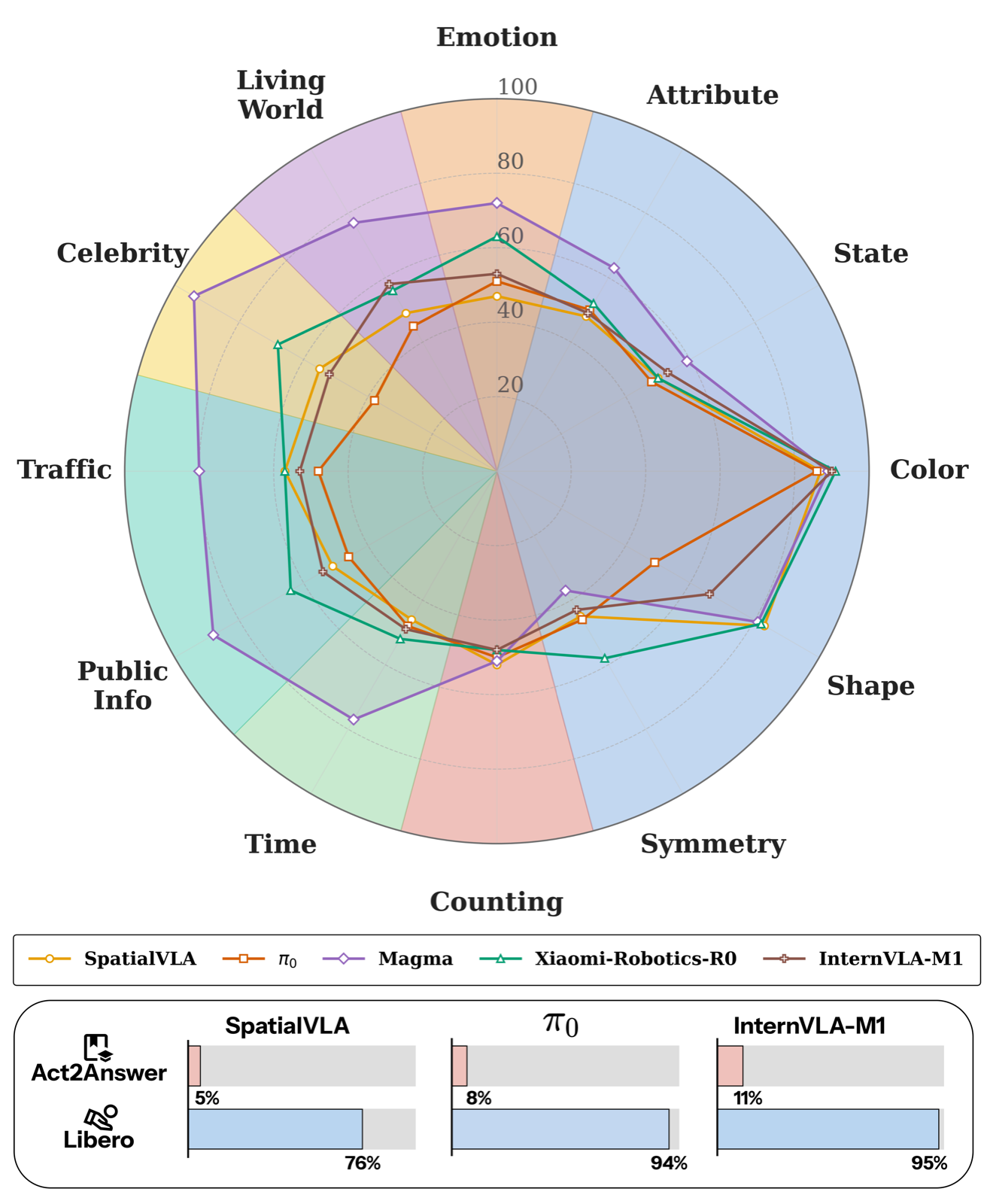
This paper introduces Act2Answer, a protocol for evaluating commonsense and world knowledge retention in VLA models by requiring agents to answer questions through action. This approach reduces control confounds and provides a more accurate measure of knowledge retention than traditional benchmarks.
The study systematically evaluates 7 VLA models and 9 VLM baselines across diverse categories, revealing that while VLAs perform well on simple concepts, they exhibit larger gaps on richer semantic categories. The findings suggest that VQA co-training is associated with better knowledge retention, and answer-relevant signals peak in middle layers but attenuate in upper layers.
These insights are crucial for agent architectures and memory & tool use, as they highlight the importance of preserving foundational knowledge during fine-tuning. The work also contributes to reasoning & planning by emphasizing how knowledge retention affects model performance on complex tasks.
Key insight: Vision-Language-Action (VLA) models retain less commonsense and world knowledge after fine-tuning, with performance gaps widening in richer semantic categories compared to their source VLMs.
Structured Inference with Large Language Gibbs
Whitammer, Esmeralda S. arXiv: 2606.19264

The paper proposes Large Language Gibbs, a scheme for structured probabilistic inference that uses conditional distributions of an LLM as transition operators. Unlike single-pass autoregressive generation, this approach iteratively resamples individual variables conditioned on others, avoiding order-dependent biases and producing a stationary distribution that reflects a compromise between all local conditionals.
This method is particularly valuable for tasks requiring structured reasoning over complex domains where probabilistic coherence is essential. The authors apply it to sampling from synthetic distributions, consistent reasoning tasks, and Bayesian structure learning, demonstrating its practical utility in various inference scenarios.
By using LLM conditionals in Markov Chain Monte Carlo (MCMC), Large Language Gibbs offers a practical alternative to one-pass generation for structured probabilistic inference under a world prior accessible through noisy LLM conditionals. This approach contributes to reasoning & planning and memory & tool use by enabling more coherent and flexible probabilistic reasoning.
Key insight: Large Language Gibbs enables structured probabilistic inference by iteratively resampling variables using LLM conditionals, avoiding order-dependent biases and producing a stationary distribution that reflects all local conditionals.
STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
Tang, Yansong arXiv: 2606.19236
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a dominant paradigm for complex reasoning in LLMs, yet suffers from policy entropy collapse during training. This paper introduces STARE (Surprisal-guided Token-level Advantage Reweighting), which addresses this issue by analyzing token-level entropy dynamics under GRPO and identifying a four-quadrant structure involving trajectory-level advantage and entropy sensitivity functions.
STARE identifies entropy-critical tokens via batch-internal surprisal quantiles, selectively reweights their effective advantages, and incorporates a target-entropy closed-loop gate for stable entropy regulation. This approach sustains stable RL training over thousands of steps while maintaining policy entropy within the target band across various model scales and task families.
The method demonstrates significant performance gains on AIME24 and AIME25 benchmarks, outperforming DAPO and other baselines by 4%-8% in average accuracy. The sustained exploration-exploitation balance unlocked by STARE indicates its potential for broader applications in RL training of LLMs.
Key insight: Token-level advantage reweighting guided by surprisal improves policy entropy stability in RL training, enabling sustained exploration-exploitation balance.
Mechanism-Guided Selective Unlearning for RLVR-Induced Reasoning
Zhou, Xu arXiv: 2606.19222

This paper proposes MAST (Mechanism-Aligned Selective Targeting), a method for unlearning RLVR-induced reasoning that minimizes collateral damage compared to standard full-parameter updates. The approach identifies attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude, then updates only the top-ranked subset.
Experiments on Qwen2.5-Math-1.5B and Qwen3-1.7B-Base models show that MAST induces statistically significant target forgetting (MATH forget 45/150 to 37/150) while preserving GSM8K (+0.8 pp) and maintaining MATH retain (-0.5 pp). The advantage reproduces across different seeds, objectives, and model versions, demonstrating robustness.
The method's ability to preserve key capabilities during unlearning makes it particularly valuable for fine-tuning LLMs in complex reasoning tasks where retaining prior knowledge is crucial, offering a promising direction for managing knowledge retention in post-training scenarios.
Key insight: Selective unlearning based on mechanism alignment reduces collateral damage in RLVR-induced reasoning, preserving key capabilities while forgetting unwanted behaviors.
Data Intelligence Agents: Interpreting, Modeling, and Querying Enterprise Data via Autonomous Coding Agents
Ohlsson, Henrik arXiv: 2606.19319
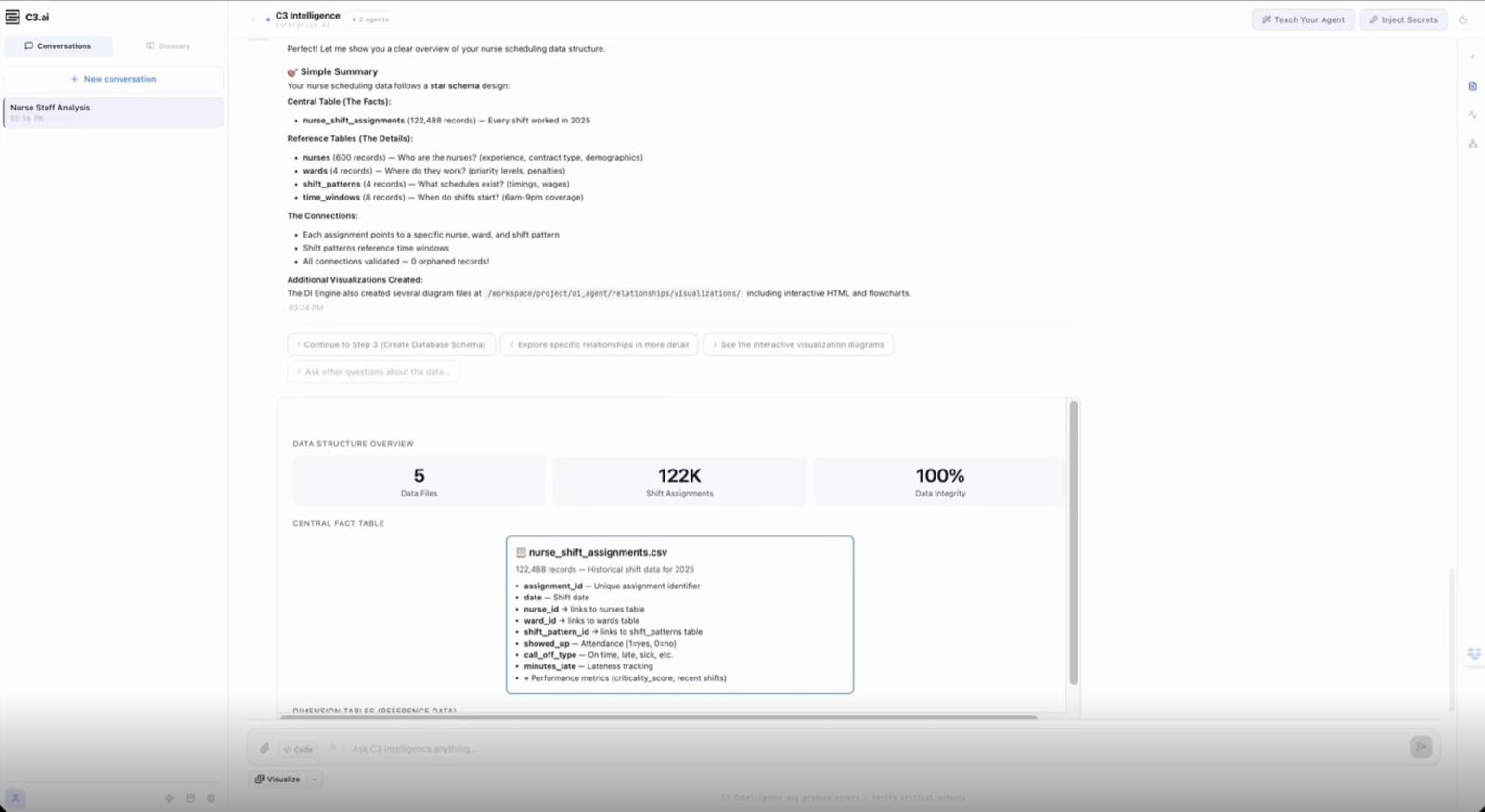
Data Intelligence Agents (DIA) introduce a system of three autonomous coding agents—Data Interpreter, Schema Creator, and Query Generator—that compress traditional workflows by treating code generation as a first-class abstraction. These agents generate, execute, validate, and repair concrete artifacts while leveraging shared memory for experience reuse.
The framework is evaluated in fully autonomous mode across seven SQL benchmarks spanning four task categories and dialects, achieving competitive or superior performance compared to existing methods. This demonstrates that an architecture grounded in execution, built on ACAs and shared memory, generalizes effectively across data intelligence workloads with adaptation limited to natural-language instructions.
DIA's deployment in production for enterprise customers highlights its practical applicability and scalability, suggesting a viable path toward automating complex data workflows while maintaining interpretability and control through human review mechanisms.
Key insight: Autonomous coding agents with shared memory enable effective enterprise data querying and interpretation, matching or surpassing state-of-the-art results.
A Technical Taxonomy of LLM Agent Communication Protocols
Knoll, Alois arXiv: 2606.19135

This study develops a comprehensive technical taxonomy to classify and analyze LLM agent communication protocols, identifying five key dimensions: counterparty, payload, interaction state, discovery mechanism, and schema flexibility. The analysis of nine actively maintained open-source protocols reveals consistent architectural patterns across the field.
Key findings include that all sampled agent-to-agent protocols combine hybrid payloads with session-state persistence; most support multiple predefined schemas, and two negotiate schemas at runtime, indicating a trend toward schema flexibility. Decentralized discovery remains rare, suggesting a need for further innovation in this area.
The taxonomy guides protocol selection and highlights open research gaps such as privacy and policy enforcement. It suggests that while short-term convergence pressure exists toward unified protocols, long-term evolution will likely involve a federated, layered protocol stack rather than a single dominant standard.
Key insight: A technical taxonomy of LLM agent communication protocols reveals recurring architectural patterns and trends toward schema flexibility and protocol convergence.
Skill-MAS: Evolving Meta-Skill for Automatic Multi-Agent Systems
Qin, Chengwei arXiv: 2606.18837

Skill-MAS introduces a novel approach to automatic MAS generation by decoupling experience retention from parametric updates, conceptualizing high-level orchestration capability as an evolvable Meta-Skill. This method uses a closed optimization loop involving multi-trajectory rollout and selective reflection for refining architectural knowledge.
The framework demonstrates remarkable performance gains across four complex benchmarks and four distinct LLMs while maintaining favorable cost-performance trade-offs. Analysis reveals that evolved Meta-Skills are highly robust and exhibit strong transferability across unseen tasks and different LLMs, indicating their potential for generalizable multi-agent planning.
By avoiding the limitations of inference-time and training-time approaches, Skill-MAS offers a third path that scales effectively to large frontier LLMs while preserving experience retention, making it a promising solution for complex task automation in multi-agent systems.
Key insight: Decoupling experience retention from parametric updates via evolvable meta-skills enables scalable and efficient multi-agent system generation.
EARS: Explanatory Abstention for Reliable Sub-Agent Modeling in Large-scale Multi-Agent Systems
Wang, Lingyun arXiv: 2606.18668
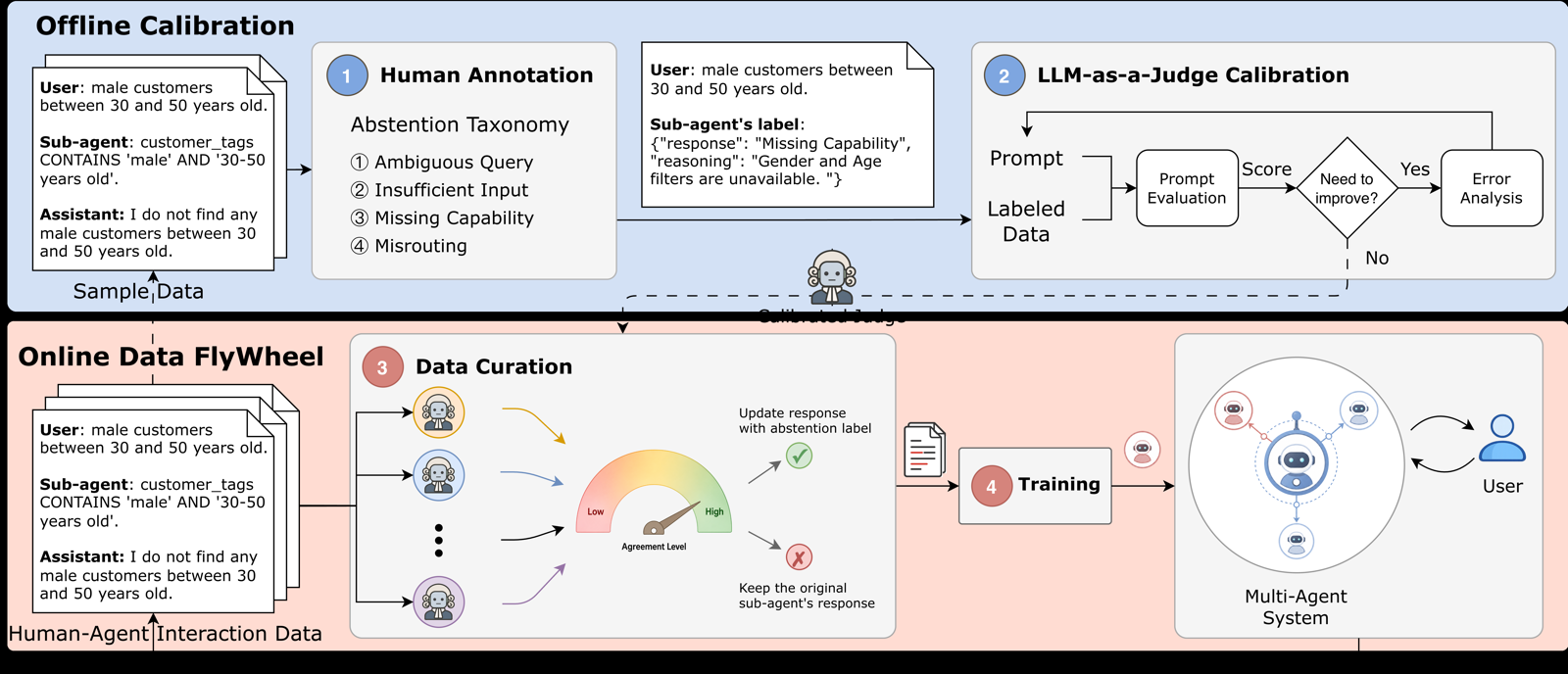
EARS (Explanatory Abstention for Reliable Sub-Agent Modeling) reframes sub-agent abstention as an inter-agent communication protocol, where sub-agents expose actionable failure states to the coordinator instead of simply abstaining. This approach addresses reliability issues in large-scale enterprise MAS by enabling better routing and fallback decisions.
The framework curates human-agent interaction data using calibrated LLM-as-a-Judge models to produce structured abstention labels and rationales under a taxonomy of failure modes. These data are used to fine-tune sub-agents to detect failure conditions and return rationales for coordinator-level clarification or rerouting.
Evaluation in a large-scale production e-commerce assistant shows that EARS improves the overall response pass rate from 68.5% to 78.9%, demonstrating its effectiveness in enhancing MAS reliability through improved sub-agent calibration and communication.
Key insight: Explanatory abstention improves reliability in large-scale MAS by enabling sub-agents to communicate actionable failure states to coordinators.
PersonalPlan: Planning Multi-Agent Systems for Personalized Programming Learning
Qi, Xiuxiu arXiv: 2606.18633
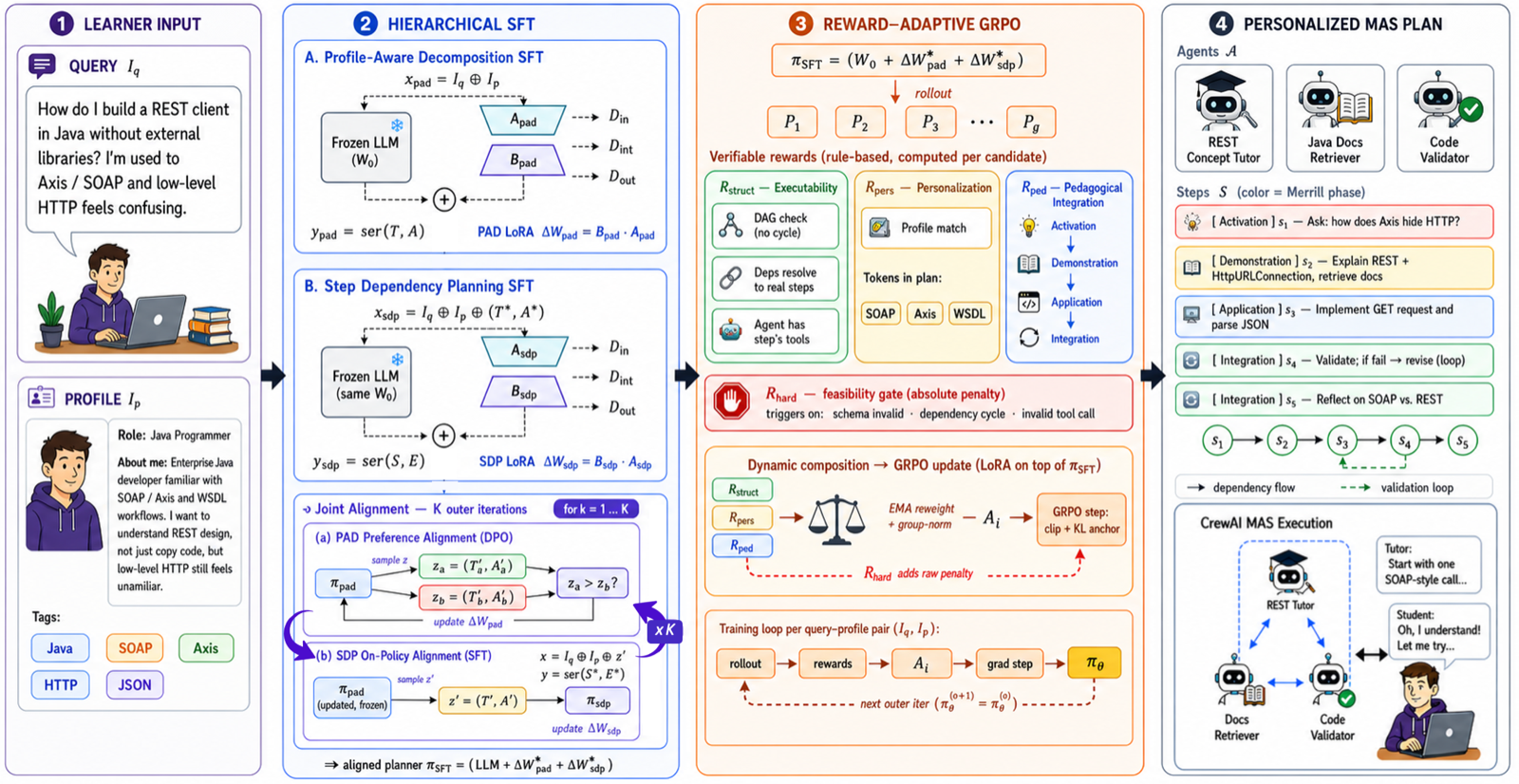
PersonalPlan addresses the gap in existing planners that lack profile-grounding and pedagogical scaffolding for personalized programming learning. The approach introduces MAP-PPL, a dataset of 3,043 query--profile--plan instances, and proposes a two-stage MAS planner that first performs hierarchical SFT with separate LoRA adapters for profile-aware task decomposition and step dependency planning.
The method applies Reward-Adaptive GRPO to encourage the generation of executable, personalized, and pedagogically scaffolded plans. Extensive experiments show that PersonalPlan achieves state-of-the-art performance in plan executability, personalization, and pedagogical quality with only 8B and 32B variants.
This work demonstrates how multi-agent systems can be effectively orchestrated for agent-student interactions in educational settings, offering a scalable solution for personalized programming instruction that adapts to diverse learner backgrounds.
Key insight: Profile-grounded multi-agent planning improves personalized programming education by combining task decomposition with pedagogical scaffolding.
LLMZero: Discovering Adaptive Training Strategies for RL Post-Training via LLM Agents
Wang, Bernie arXiv: 2606.18388
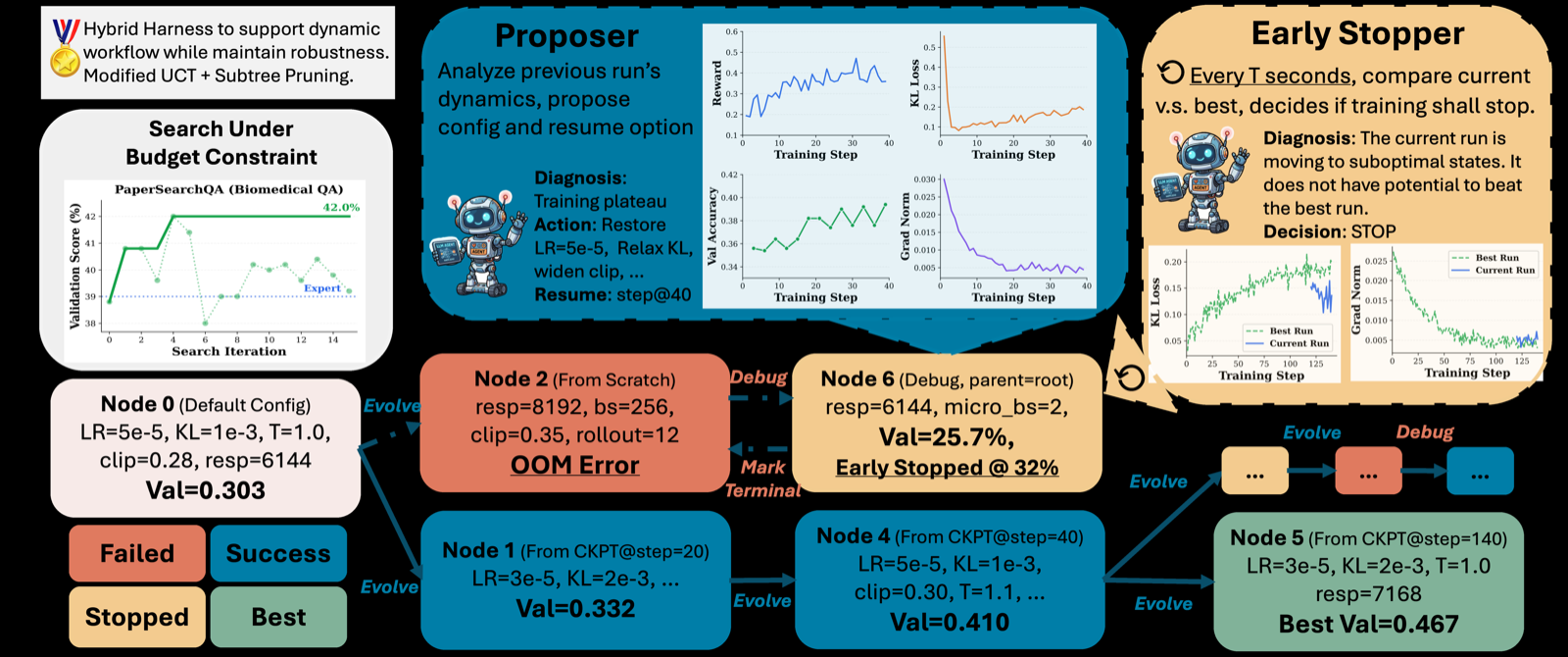
LLMZero introduces a system where LLM agents search over training trajectories via tree search, diagnosing pathologies at each checkpoint and proposing coordinated multi-parameter transitions. This approach discovers training strategies that improve over base models by 9% to 140% relative and outperform grid search by 6% to 15% relative.
The method reveals a recurring empirical pattern: capacity parameters accumulate monotonically across stages, while regularization parameters oscillate in response to shifting training dynamics. This distinction is crucial because fixed schedules cannot express non-stationary exploration-exploitation tradeoffs that regularization must track.
LLMZero's structural principle transfers across tasks and provides an explanation for why discovered strategies take qualitatively different forms yet share similar parameter dynamics, offering actionable design rules for multi-stage training in RL post-training scenarios.
Key insight: LLM agents can discover adaptive training strategies for RL post-training by diagnosing pathologies and proposing coordinated parameter transitions.
AI Model Releases

MolmoMotion: Language-guided 3D motion forecasting
AllenAI introduces MolmoMotion, a new 3D motion forecasting model that predicts object movement based on video frames, 3D points, and natural language instructions. The model uses Molmo 2 as its backbone to connect language to objects and points in images, predicting future 3D trajectories of query points. Researchers released MolmoMotion-1M, the largest collection of 3D point trajectories paired with action descriptions from 1.16M videos, along with PointMotionBench, a human-validated benchmark for evaluating object-centric 3D motion forecasting accuracy.
Why it matters: This represents a significant advancement in multimodal AI systems that can understand and predict complex physical motion from language instructions. The model's ability to work with sparse 3D point representations makes it efficient for robotics planning and video generation applications, potentially enabling more realistic and controllable AI-driven content creation.
Agent Frameworks & SDKs

Agentic coding and persistent returns to expertise \ Anthropic
Anthropic's research analyzes 400,000 Claude Code sessions from October 2025 to April 2026, revealing that people make most planning decisions while Claude handles execution. The study shows that domain expertise, not coding proficiency, significantly impacts success rates in agentic coding tasks. Users with more domain knowledge succeed more often and recover more easily from errors. Over seven months, the value of typical tasks increased by about 25% across all work types, indicating growing complexity and worth of work being done through these tools.
Why it matters: This research provides concrete evidence that agentic coding tools are shifting the labor market dynamics, where domain expertise becomes more valuable than coding skills. It suggests that as these tools mature, they will reward those who understand problems deeply rather than just technical implementation details, fundamentally changing how knowledge work is organized.
AI Tooling

How growing UK midsize businesses are building in the AI era | Google Cloud Blog
Google Cloud's research shows that 71% of UK AI adopters say the technology helps save time on routine tasks, and 64% report a direct boost in productivity. SMBs using Google Cloud AI have nearly doubled year-over-year, with businesses leveraging Gemini models and products for customer support automation, payroll processing, data analysis, marketing design creation, and AI agent development. The research indicates that AI-enabled productivity tools deliver a 20% boost in productivity for SMBs, effectively giving them back one full working day each week.
Why it matters: This demonstrates how AI adoption is becoming mainstream among UK small and midsize businesses, with tangible productivity gains that could reshape business operations across sectors. The findings suggest that AI tools are moving beyond experimental use to become essential productivity drivers for smaller enterprises.

How to turn off AI in your Google Docs | TechCrunch
TechCrunch explains how to disable AI pop-ups in Google Docs, particularly the 'write with Gemini' prompts that appear when opening documents. The article details two methods: turning off the bottom bar preferences through the Gemini menu option, and disabling smart features across Google Workspace via Gmail settings. Users reported various AI features disrupting their writing process, including a 'help me write' feature that hovers over the cursor.
Why it matters: This reflects growing user frustration with intrusive AI features in productivity tools, highlighting the need for better user control and customization options. As AI becomes more integrated into everyday applications, understanding how to manage these features will become increasingly important for maintaining workflow efficiency.