OpenAI introduced Deployment Simulation, a technique for predicting model behavior before release by simulating deployments using privacy-preserving replay of previous conversations. Concurrently, Z.ai released GLM-5.2, an open-weight large language model that outperforms proprietary leaders like GPT-5.5 on coding benchmarks while maintaining open access and significantly reduced compute costs. These developments represent significant progress in AI safety evaluation methods and the growing capabilities of open-source AI models.
OpenAI's Deployment Simulation technique represents a major advancement in pre-release safety evaluation, using privacy-preserving replay of previous conversations to predict model behavior before deployment. This approach removes original assistant responses from deployment traffic and regenerates them with candidate models to study real-world behavior patterns, improving estimates of undesired model behavior rates and helping surface novel misalignment forms. Meanwhile, Z.ai's GLM-5.2 753-billion parameter open-weight model features a 1-million-token context window and 'IndexShare' optimization that reduces compute needs by 2.9 times at maximum context length. Available on Hugging Face and Z.ai's API, GLM-5.2 scores above state-of-the-art open-source models like DeepSeek v4 and matches proprietary leaders like GPT-5.5 and Claude Opus 4.8 on key benchmarks including SWE-bench Pro (62.1) and FrontierSWE (74.4%). The model is released under MIT license, allowing free download, customization, and local deployment for just the cost of compute and electricity. These developments demonstrate progress in both AI safety evaluation methods and the expanding capabilities of open-source AI systems.
Research Papers
Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
Chen, Josef Liyanjun arXiv: 2606.18144

This paper introduces a novel economic framework for managing memory in embodied agents, treating flash endurance as a non-renewable resource akin to capital depreciation. By introducing a shadow price η for endurance, the authors develop a cost-optimal indexing strategy that balances wear across different storage tiers. This approach is particularly relevant for edge robotics where memory resources are limited and costly, offering a principled way to allocate memory based on expected value rather than arbitrary heuristics.
The key finding that the optimal memory placement becomes non-monotone when χ > 0 reveals an important nuance in how agents should prioritize memory retention. In practical terms, this means that valuable memories may be moved off flash storage if their long-term value is outweighed by wear costs—a counterintuitive but theoretically sound result. The empirical measurement of χ across different robot tasks (recurrent manipulation vs. non-recurrent teleoperation) underscores the importance of deployment-specific tuning in memory management strategies.
While the theoretical framework is compelling, the paper leaves open whether wear-aware placement actually improves task performance, as the measured value proxy does not directly correlate with realized task outcomes. This gap suggests that future work must bridge the abstraction between memory economics and real-world utility, potentially through more sophisticated metrics or simulation environments that better reflect actual agent behavior.
Key insight: Embodied agents should price memory endurance as a depreciating asset, using wear-aware placement strategies that optimize cost across RAM/NVM/cloud hierarchies. The value-write association (χ) determines whether valuable memories are stored on flash, with empirical results showing χ varies by deployment regime.
HistoRAG: Embedding Historical Methodology in Retrieval-Augmented Generation Through Critical Technical Practice
Hiltmann, Torsten arXiv: 2606.18103

HistoRAG represents a significant step toward domain-specific adaptation of RAG architectures, particularly for interpretive disciplines like history. By embedding historiographical principles into technical design—such as temporal windowing and LLM-as-judge evaluation—the framework addresses fundamental mismatches between standard RAG and scholarly practice. This approach not only improves retrieval accuracy but also makes the process more transparent and contestable, aligning with epistemological commitments of historical inquiry.
The empirical validation using Der Spiegel corpus demonstrates concrete deficiencies in standard RAG configurations, including era-specific vocabulary gaps and weak correlation between vector similarity and relevance judgments. These findings highlight how default RAG settings can be misleading for time-sensitive domains, reinforcing the need for architectural interventions that reflect domain knowledge rather than generic optimization criteria.
The introduction of Zwischentexte—a concept for interpretive proposals rather than final findings—offers a novel way to integrate LLM-generated content responsibly into scholarly workflows. This framework may serve as a model for other interpretive fields working with large corpora, suggesting that effective RAG design requires deep engagement with epistemological foundations rather than just technical performance metrics.
Key insight: Historical RAG systems must incorporate historiographical principles such as temporal windowing and separated retrieval/generation to align with scholarly practices, rather than defaulting to factual QA paradigms.
Compositional Skill Routing for LLM Agents: Decompose, Retrieve, and Compose
Gao, Xueping arXiv: 2606.18051

SkillWeaver tackles a critical challenge in LLM agent development: how to compose multiple skills for complex tasks beyond simple tool selection. The framework's decompose-retrieve-compose architecture addresses the fundamental limitation that most agents struggle with multi-step planning and execution, especially when skills must be coordinated across different domains.
The introduction of Iterative Skill-Aware Decomposition (SAD) is a key innovation, demonstrating how retrieval-augmented feedback loops can iteratively improve task decomposition quality. The reported gains—from 51.0% to 67.7% category recall—highlight the importance of alignment between decomposition granularity and available skills, suggesting that future agent systems should incorporate dynamic decomposition strategies.
The benchmarking effort with CompSkillBench provides a valuable resource for evaluating compositional skill routing methods, offering a realistic testbed with real-world MCP server skills. The framework's ability to reduce context window consumption by over 99% while maintaining performance indicates strong potential for scalability in practical agent deployments, particularly where computational resources are constrained.
Key insight: Compositional skill routing requires decomposing complex tasks into atomic sub-tasks, retrieving appropriate skills for each, and composing them into executable plans. Task decomposition quality is the primary bottleneck, with iterative skill-aware feedback improving accuracy significantly.
PreAct: Computer-Using Agents that Get Faster on Repeated Tasks
Li, Bojie arXiv: 2606.17929
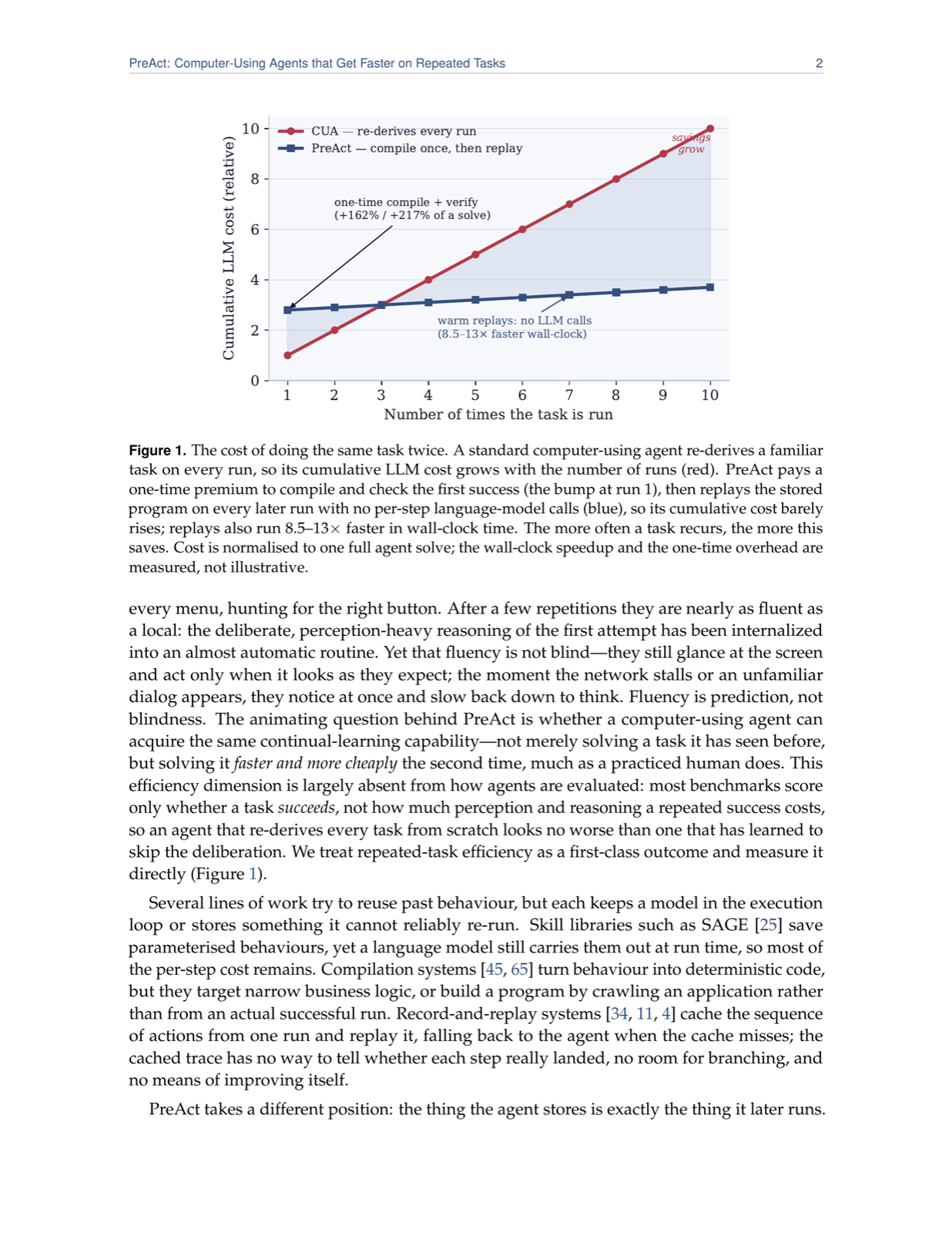
PreAct introduces a compelling approach to agent efficiency by leveraging program replay for repeated tasks, fundamentally changing how agents interact with environments. By compiling successful trajectories into executable state machines, PreAct eliminates the need for full language model inference during repetition, dramatically reducing latency and computational overhead—a crucial advancement for real-time agent applications.
The safety mechanism built into PreAct ensures that replays are validated against screen states at each step, handing control back to the agent if discrepancies arise. This hybrid approach preserves the flexibility of LLM-based reasoning while enabling significant performance gains, demonstrating a practical balance between automation and robustness in agent design.
The evaluation across mobile, desktop, and web benchmarks shows consistent improvements, with PreAct achieving 1.75-2.6 tasks per benchmark compared to baseline methods. This scalability suggests that the approach can be generalized across different domains and platforms, making it a promising technique for building more efficient and reliable agent systems in diverse application areas.
Key insight: PreAct enables agents to accelerate repeated tasks by compiling successful runs into state-machine programs that can be replayed without language model calls, achieving 8.5-13x speedup while maintaining safety through screen validation.
Beyond Domains: Reusing Web Skills via Transferable Interaction Patterns
Chowdhury, Mosharaf arXiv: 2606.17645
SkillMigrator addresses a major limitation in current web agent systems: the inability to effectively transfer skills between domains. By introducing transferable interaction patterns (TIPs) that match layout structures rather than specific UI elements, the system enables more robust skill reuse across websites, significantly reducing both action count and computational cost.
The approach's reliance on structural sketching at induction time and layout similarity at test time provides a principled way to generalize skills beyond exact matches. This is particularly valuable in web environments where UIs frequently change while maintaining functional similarities, suggesting that future agent systems should incorporate more abstract representations of interaction patterns.
The empirical results showing 8-10% reduction in LLM-action count across WebArena and Mind2Web benchmarks validate the effectiveness of this approach. The fact that SkillMigrator achieves these gains without sacrificing success rates indicates that it can be seamlessly integrated into existing agent pipelines, offering an immediate improvement for web-based automation tasks.
Key insight: Transferable interaction patterns (TIPs) enable skill reuse across different websites by matching layout structure rather than specific element references, reducing LLM-action count by 8-10% compared to existing methods.
OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
Yan, Shuicheng arXiv: 2606.17628

OPD-Evolver presents a sophisticated framework for self-evolving agents that goes beyond simple memory retention to encompass full lifecycle management of experience. The slow-fast co-evolution mechanism allows the agent to learn not just from experience but how to evolve through it, making it a significant advancement in agent architecture design.
The on-policy distillation approach enables the system to internalize high-value experiences and memory management strategies, resulting in an agent that can compete with much larger models like Qwen3.5-397B-A17B and Step-3.5-Flash. This suggests that the key to scalable evolution lies not in model size but in how effectively agents can learn from and organize their own experience.
The framework's ability to surpass memory-augmented systems by up to 11.5% across benchmarks indicates that true agent evolvers must be capable of holistic competence—selecting useful experience, acting on it, writing reusable knowledge, and maintaining a growing repository. This represents a shift from passive memory systems toward active learning architectures.
Key insight: OPD-Evolver uses slow-fast co-evolution with on-policy distillation to cultivate holistic agent evolvers that can select, act on, write, and maintain experience across multiple domains, outperforming existing memory systems by up to 11.5%.
SEAGym: An Evaluation Environment for Self-Evolving LLM Agents
Zhang, Changshui arXiv: 2606.17546
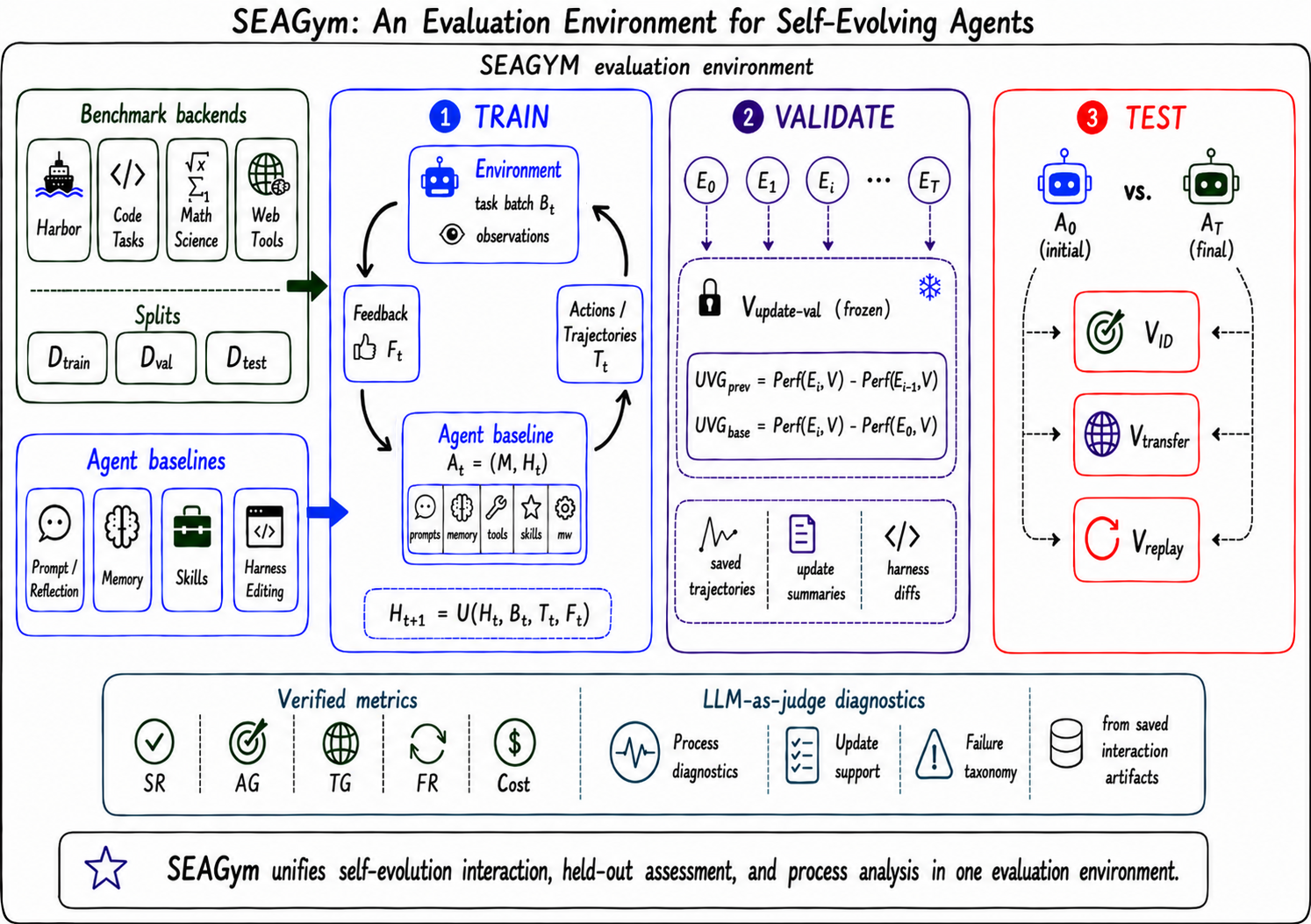
The introduction of SEAGym marks a significant advancement in evaluating the evolution of LLM-based agents. Unlike traditional benchmarks that focus solely on task performance or sequential curves, SEAGym introduces a multi-dimensional evaluation approach that includes training, validation, test, replay, and cost records. This framework allows researchers to assess not just immediate gains but also long-term stability and reusability of agent improvements.
By instantiating SEAGym on benchmarks like Terminal-Bench 2.0 and HLE, the authors compare different evolutionary strategies such as ACE, TF-GRPO, and AHE under a shared protocol. The findings indicate that these evaluation views provide complementary signals about the evolution process, showing that frequent updates can lead to overfitting or even degradation in held-out performance. This insight is crucial for understanding how agent harnesses evolve and what constitutes meaningful improvement.
The study highlights that useful intermediate snapshots may collapse later, emphasizing the importance of snapshot selection and long-term monitoring in agent development. Additionally, it reveals that source diversity and model backend significantly affect harness reliability, suggesting that future research should consider these factors when designing self-evolving systems.
Key insight: SEAGym provides a comprehensive evaluation framework for self-evolving LLM agents, revealing that frequent updates may not generalize well and that harness reliability depends on source diversity and model backend.
GeoDisaster: Benchmarking Orchestrated Agents for Operational Disaster Geo-Intelligence
Banerjee, Biplab arXiv: 2606.17246
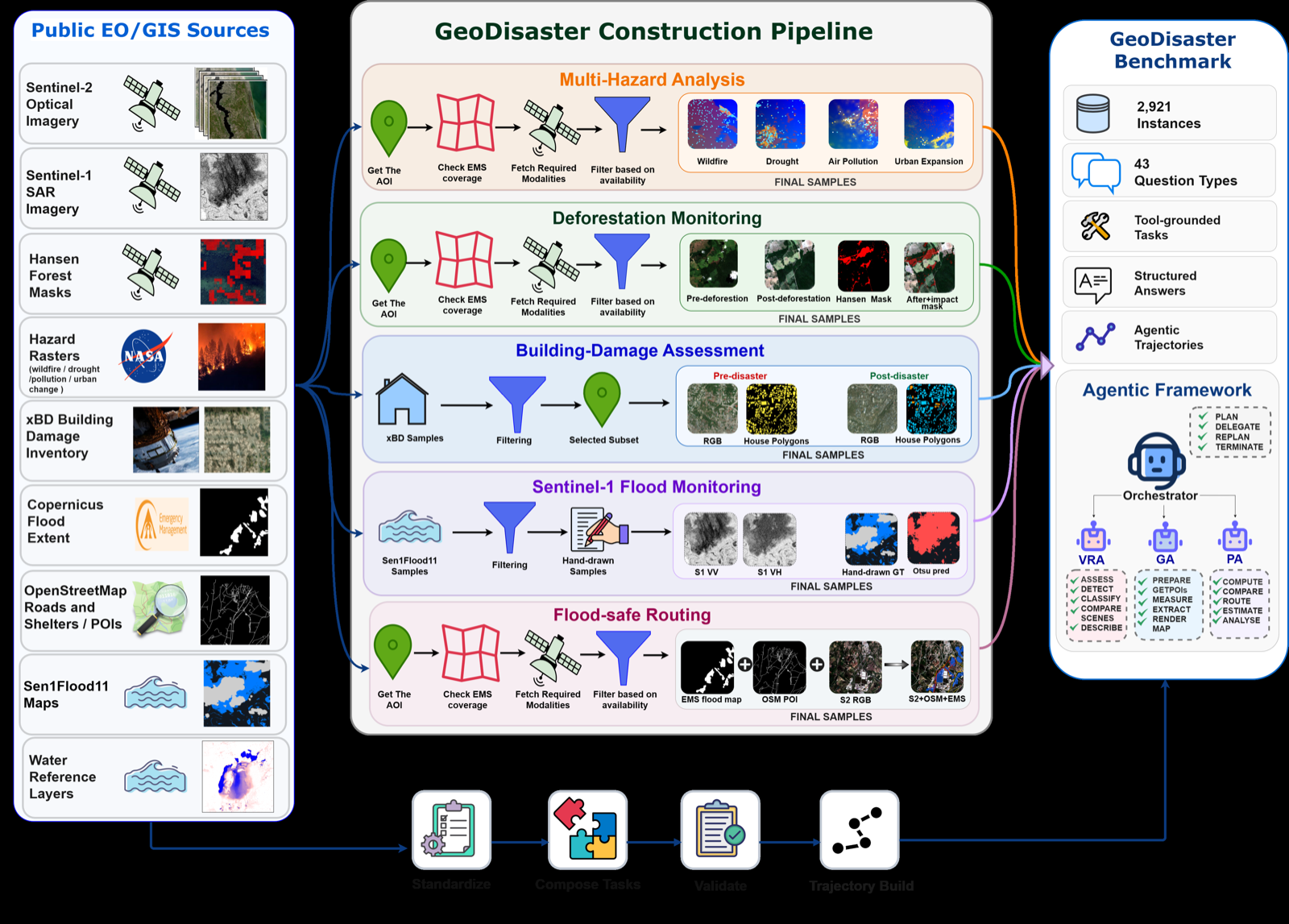
GeoDisaster presents a compelling case for the necessity of orchestrated multi-agent frameworks in complex domains like disaster geo-intelligence. The benchmark integrates heterogeneous Earth-observation data, including optical and SAR imagery, raster masks, vector geometries, and exposure layers, creating a rich environment that demands structured reasoning and evidence-backed decisions.
The proposed orchestrated multi-agent framework with 18 disaster-oriented tools showcases how role-specialized agents can coordinate effectively through explicit execution contracts. The use of Role-Contract Expectation Alignment (RCEA) combines failure-aware supervised fine-tuning with contract-grounded reinforcement learning, resulting in improved tool usage, evidence grounding, and decision generation.
Experiments show that existing RS-VLMs and agentic systems struggle with the complexity of GeoDisaster, indicating a gap between current capabilities and operational requirements. This benchmark not only challenges models but also provides a clear path forward for improving multi-agent systems in real-world applications.
Key insight: GeoDisaster introduces a challenging benchmark for operational geo-intelligence, demonstrating that multi-agent systems with role-specialized agents and contract-based coordination can significantly improve tool use and decision-making in disaster scenarios.
Verified Detection and Prevention of Concurrency Anomalies in Multi-Agent Large Language Model Systems
Khan, Sajjad arXiv: 2606.17182

This work addresses a critical but often overlooked aspect of multi-agent LLM systems: concurrency control. By modeling shared state through deterministic-generation semantics and formalizing four concurrency anomalies using TLA+, the authors provide a rigorous foundation for understanding and mitigating issues in distributed agent systems.
The paper's contribution lies in its mechanical verification of detectors and prevention mechanisms, demonstrating that the proposed runtime refinements (L0-L4) are both sound and complete against their specifications. This level of formal assurance is rare in practical systems and sets a new standard for reliability in multi-agent LLM environments.
The real-world validation through deployments at ByteDance and LangGraph illustrates the practical impact of these theoretical findings. The identification and resolution of silent lost updates and tool-effect reordering highlight how formal methods can uncover subtle but critical bugs that might otherwise go unnoticed, thereby enhancing system robustness.
Key insight: The paper presents a formal verification approach to detect and prevent concurrency anomalies in multi-agent LLM systems, establishing a consistency hierarchy that ensures reliable state sharing across agents.
Variable-Width Transformers
Kim, Yoon arXiv: 2606.18246
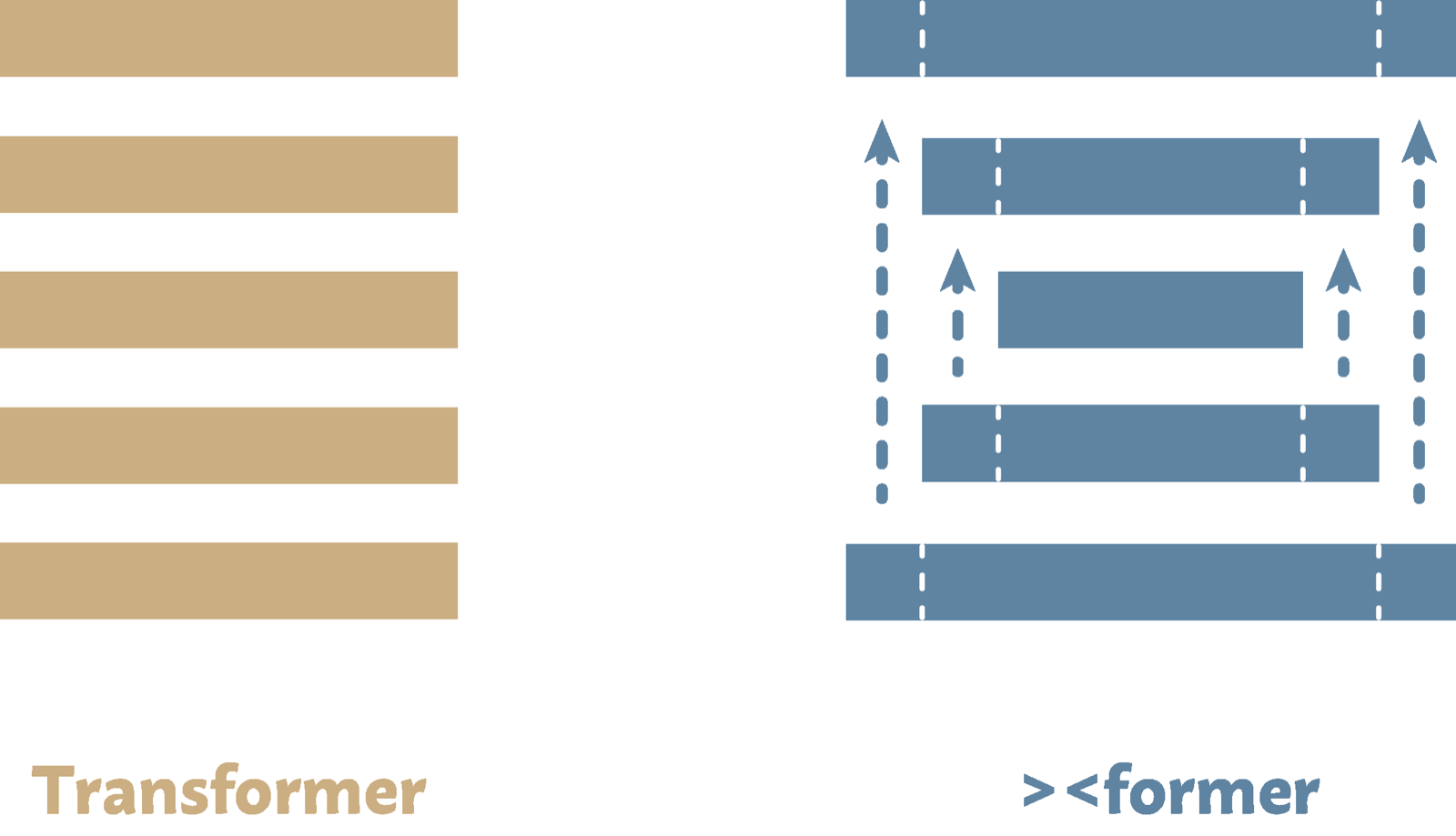
The Variable-Width Transformer architecture challenges the conventional wisdom of maintaining constant width across all transformer layers. By employing a $\times$-shaped design that keeps early and late layers wider while narrowing middle layers, this approach leverages a parameter-free residual resizing mechanism to achieve more efficient scaling.
Empirical results across various model sizes (200M to 2B parameters for dense models and 3B for MoE) consistently show superior performance over uniform baselines in terms of language modeling loss. More importantly, the architecture reduces overall FLOPs by 22% and KV cache memory usage by 15%, making it particularly attractive for resource-constrained environments.
The analysis reveals that this bottleneck structure results in qualitatively different representations in residual streams, suggesting that nonuniform width allocation not only improves efficiency but also enhances the model's ability to learn distinct features at different depths. This finding has implications for future transformer design and optimization strategies.
Key insight: Variable-width transformers with nonuniform capacity allocation across layers achieve better performance and efficiency compared to uniform architectures, demonstrating that layer-specific width adjustments can optimize resource usage.
EvolveNav: Proactive Preflection and Self-Evolving Memory for Zero-Shot Object Goal Navigation
Wang, Hao arXiv: 2606.18235
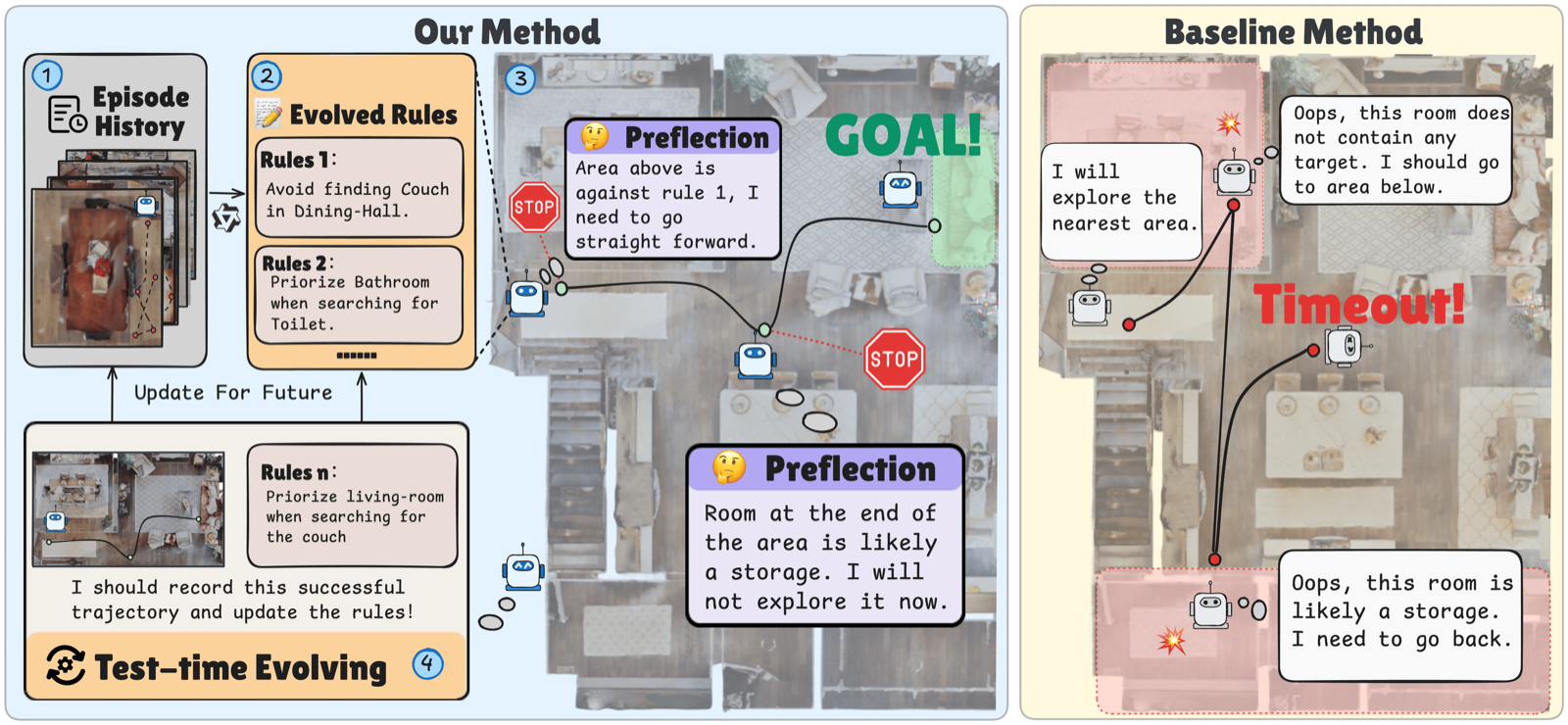
EvolveNav tackles the challenge of Zero-Shot Object-Goal Navigation (ZS-OGN) by introducing a self-evolving framework that allows agents to adapt and improve during test-time. This approach addresses the limitations of static priors in existing methods, which often lead to repeated errors and inefficient exploration.
The framework builds an agentic rule memory from past trajectories and employs a retrieval strategy based on upper confidence bound to select effective rules. Additionally, it introduces a memory-guided preflection module that forecasts potential outcomes before action, reducing the need for costly trial-and-error processes.
Extensive experiments demonstrate that EvolveNav outperforms existing zero-shot baselines, achieving a 10.1% improvement in success rate with fewer unnecessary steps. This advancement is particularly significant as it shows how agents can learn and adapt without explicit training, making them more robust and efficient in real-world scenarios.
Key insight: EvolveNav enables embodied agents to improve continuously during test-time through self-evolving memory and proactive preflection, achieving better navigation success rates with fewer unnecessary steps.
Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
Hachiuma, Ryo arXiv: 2606.18216
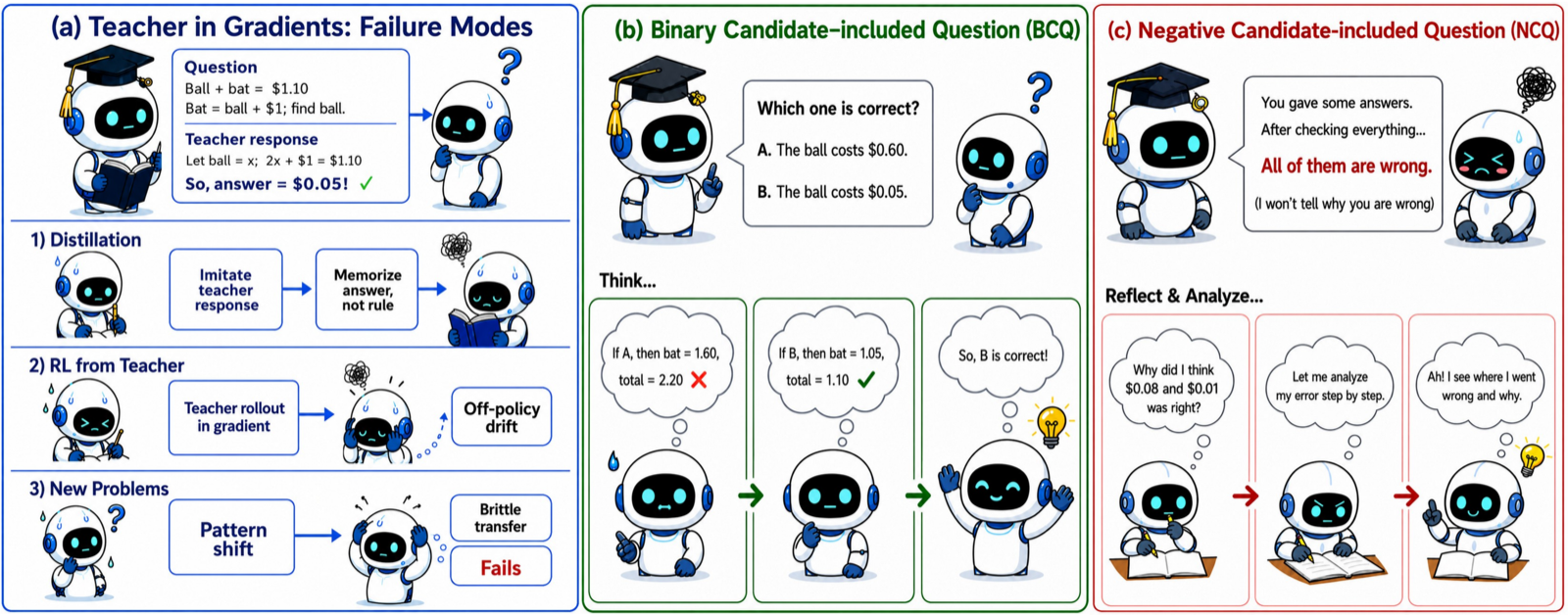
Zone of Proximal Policy Optimization (ZPPO) offers a fresh perspective on knowledge distillation by embedding the teacher's guidance directly into prompts instead of relying on gradient-based methods. This approach is particularly effective for small student models where traditional distillation techniques often fail due to over-concentration on sharp modes.
The method constructs two reformulated prompts—Binary Candidate-included Question (BCQ) and Negative Candidate-included Question (NCQ)—to help students discriminate between correct and incorrect responses while surfacing shared failure modes. A prompt replay buffer ensures that hard questions are revisited until the student graduates or is evicted, maintaining focus on the current zone of proximal development.
Evaluations on a 31-benchmark suite show that ZPPO outperforms both off-policy and on-policy distillation methods, especially at smaller scales. This indicates that ZPPO's approach to integrating teacher knowledge through prompts is more effective than traditional gradient-based techniques, particularly when dealing with limited student capacity.
Key insight: ZPPO introduces a novel distillation method that keeps the teacher inside prompts rather than gradients, enabling effective learning at small student scales by leveraging reformulated prompts and a prompt replay buffer.
Looped World Models
Lam, Wai arXiv: 2606.18208
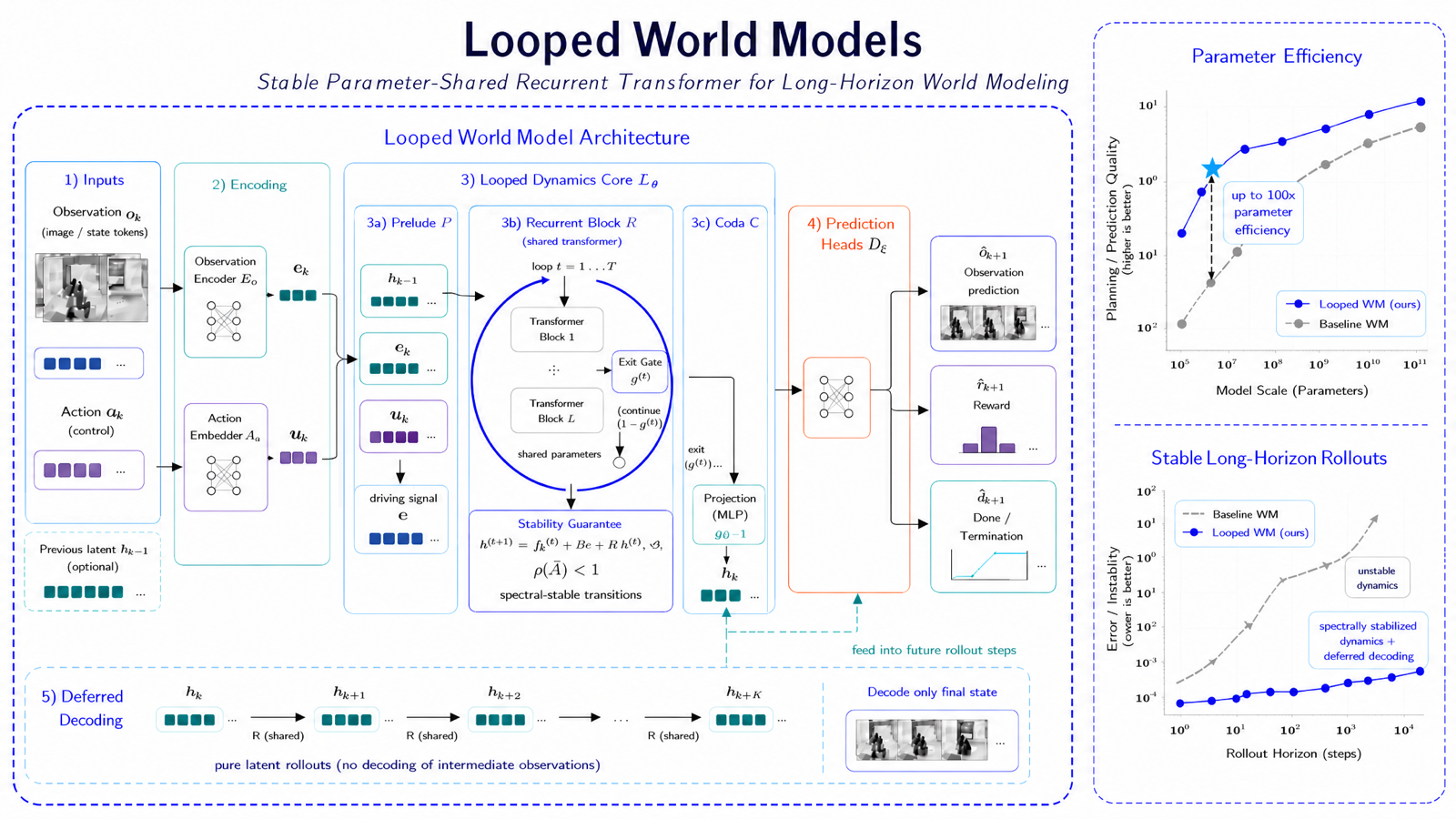
The paper presents Looped World Models (LoopWM), a novel architecture that addresses the fundamental tension in world modeling between long-horizon simulation fidelity and computational expense. By introducing looped architectures, LoopWM enables iterative refinement of latent environment states through shared transformer blocks, fundamentally changing how models scale for world simulation.
This approach establishes iterative latent depth as a new scaling axis, orthogonal to traditional methods that rely on increasing model size or training data. The adaptive computation mechanism automatically adjusts the depth of each prediction step based on complexity, leading to significant parameter efficiency gains—up to 100x over conventional approaches. This innovation is particularly relevant for AI agent development where computational resources are often constrained.
The method's ability to maintain fidelity while reducing computational overhead makes it a promising direction for scalable world modeling in autonomous systems and simulation environments. It opens new possibilities for deploying complex models in resource-constrained settings, potentially enabling more sophisticated agent behaviors without proportional increases in computational cost.
Key insight: LoopWM introduces iterative latent refinement through parameter-shared transformer blocks, achieving up to 100x parameter efficiency while adapting computation depth to prediction complexity.
Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Orvieto, Antonio arXiv: 2606.18206
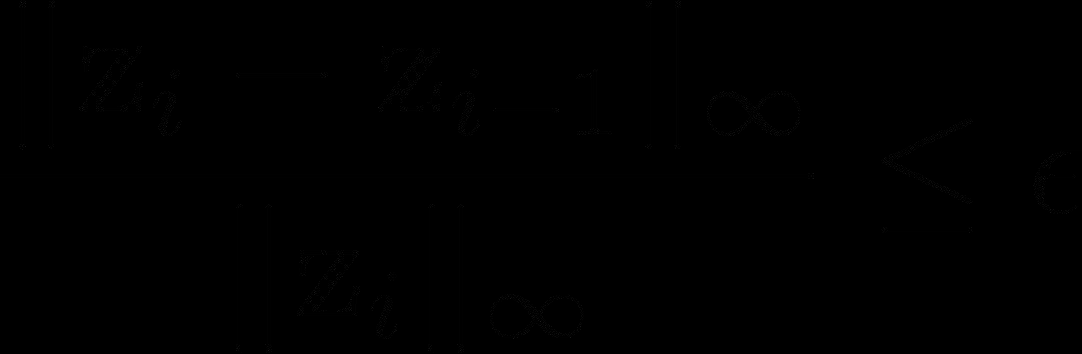
Fixed-Point Reasoners (FPRM) tackles a critical issue in looped architectures: signal propagation problems that arise from depth. By incorporating pre-norm layers and residual scaling, FPRM stabilizes training dynamics while leveraging fixed-point convergence as a natural halting criterion.
This approach allows the model to dynamically adjust its computational resources based on task difficulty, effectively creating an adaptive compute mechanism. The paper demonstrates strong performance across various reasoning benchmarks including Sudoku, Maze, state-tracking, and ARC-AGI, showing that FPRM can achieve high-quality solutions while maintaining stability.
The integration of fixed-point halting with looped architectures represents a significant advancement in compositional reasoning systems. It provides a principled way to balance model depth and computational efficiency, which is crucial for developing robust AI agents capable of complex problem-solving tasks.
Key insight: FPRM uses fixed-point convergence as an end-to-end halting mechanism, enabling adaptive compute allocation and stable deep reasoning in looped architectures.
RubricsTree: Scalable and Evolving Open-Ended Evaluation of Personal Health Agents across Health Memory and Medical Skills
Metwally, Ahmed A. arXiv: 2606.18203
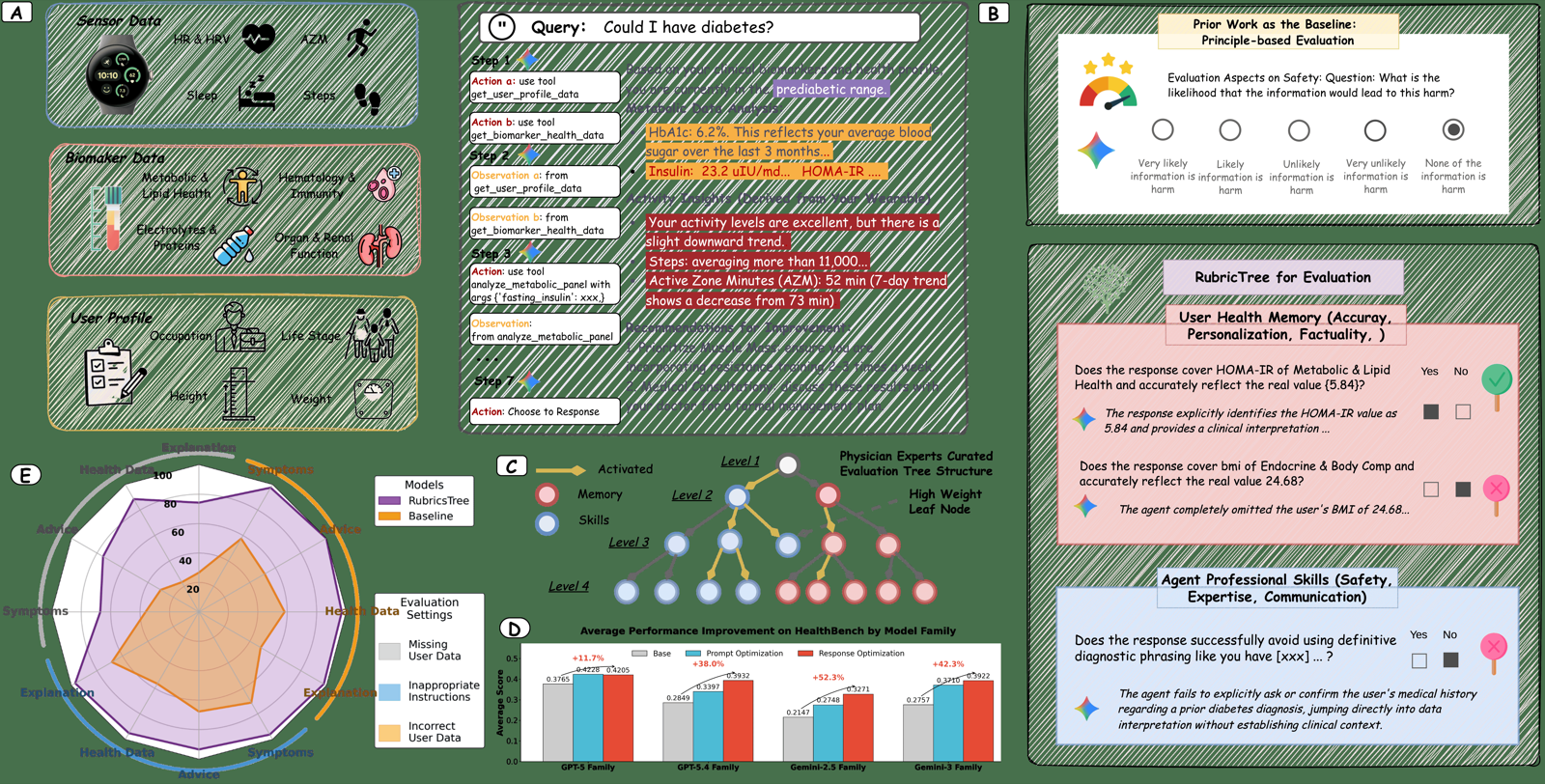
RubricsTree addresses a critical bottleneck in deploying LLM-powered personal health agents: the lack of scalable, expert-aligned evaluation methods. The framework employs a hierarchical taxonomy of over 100 atomic Boolean rubrics, curated through human-in-the-loop protocols with physician expertise.
The adaptive router mechanism activates only relevant rubrics per query, providing both scalability and expert quality assurance. This approach significantly outperforms existing baselines in expert alignment while maintaining reliability in penalizing degraded responses. The framework's ability to provide structured instructions, feedback, or training rewards makes it valuable for continuous optimization of healthcare AI systems.
This work is particularly relevant for multi-agent systems in healthcare domains where accuracy and clinical alignment are paramount. RubricsTree provides a reproducible infrastructure that supports the evolution of evaluation criteria alongside real-world usage patterns, making it suitable for product-level deployment and ongoing model improvement.
Key insight: RubricsTree introduces a hierarchical, expert-aligned evaluation framework for personal health agents using adaptive rubric selection and auto-weighting to enable scalable, auditable assessment.
Learning from the Self-future: On-policy Self-distillation for dLLMs
Liu, Shiwei arXiv: 2606.18195
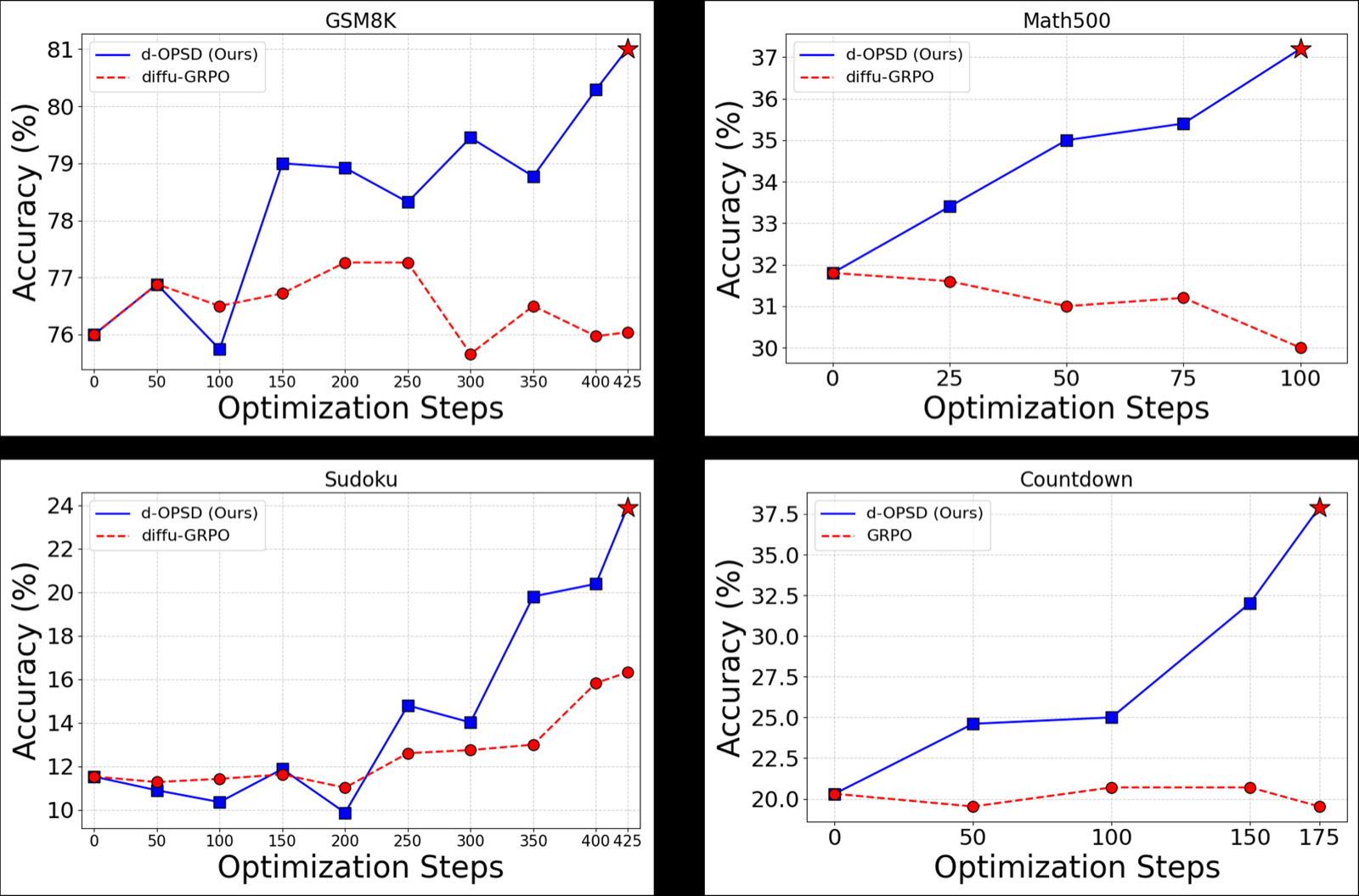
The paper introduces d-OPSD, the first on-policy self-distillation framework specifically designed for diffusion LLMs (dLLMs). Unlike traditional autoregressive methods that rely on prefix conditioning, d-OPSD uses self-generated answers as suffix conditioning, enabling learning from 'self future-experience'.
By shifting supervision from token-level to step-level, the method aligns training with the iterative denoising process inherent in diffusion models. This approach achieves superior performance compared to RLVR and SFT baselines while requiring only about 10% of optimization steps, demonstrating remarkable sample efficiency gains.
This innovation is crucial for dLLM development, where efficient post-training methods are essential for practical deployment. The framework opens new pathways for optimizing diffusion models with minimal data requirements, potentially accelerating the adoption of advanced generative AI in various applications.
Key insight: d-OPSD enables effective post-training of diffusion LLMs through self-distillation using suffix conditioning and step-level supervision, achieving superior sample efficiency.
The Stanford EDGAR Filings Dataset: Reconstructing U.S. Corporate and Financial Disclosures into Layout-Faithful and Token-Efficient Pretraining Data
Giesecke, Kay arXiv: 2606.18192
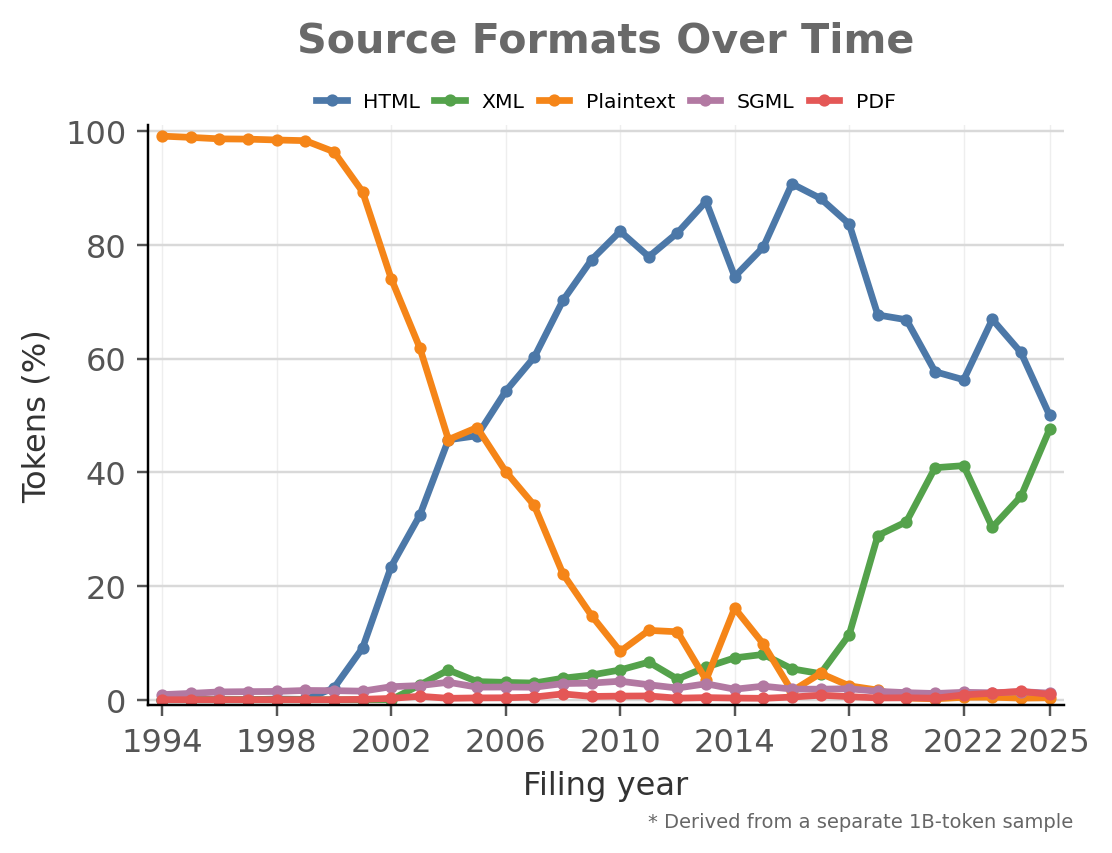
The Stanford EDGAR Filings Dataset (SEFD) addresses a critical shortage in long-context training data for LLMs by providing clean, layout-faithful reconstructions of SEC filings. This dataset transforms audited financial statements and other regulatory documents into token-efficient MultiMarkdown format suitable for pretraining.
With 152B tokens in its initial snapshot and an estimated 550B tokens across a larger archive, SEFD offers substantial training data while maintaining less than 0.1% overlap with Common Crawl-derived corpora. The dataset supports financial reasoning, forecasting, compliance, and document understanding tasks through two derived benchmarks: EDGAR-Forecast and EDGAR-OCR.
This work is particularly valuable for agent architectures that require domain-specific knowledge, especially in finance. SEFD provides a reproducible workflow for creating high-quality long-context data, supporting the development of more capable financial reasoning agents while addressing concerns about data contamination and quality.
Key insight: SEFD provides layout-faithful, token-efficient financial pretraining data by reconstructing SEC filings into MultiMarkdown format, addressing scarcity of high-quality long-context corpora.
DRFLOW: A Deep Research Benchmark for Personalized Workflow Prediction
Laradji, Issam H. arXiv: 2606.18191

DRFLOW addresses the gap between report generation and actionable workflow identification in deep research systems. The benchmark requires agents to extract relevant evidence from scattered sources and predict correct action-step sequences for user tasks, moving beyond simple summarization to complex planning.
With 100 tasks across five domains and 1,246 reference workflow steps grounded in over 3,900 sources, DRFLOW provides a comprehensive evaluation framework. The seven diagnostic metrics cover factual grounding, step recovery, structural ordering, condition resolution, and personalization, offering detailed insights into agent capabilities.
Despite improvements over baseline agents, the substantial room for improvement indicates that predicting complete and correct personalized workflows remains a challenging frontier. This benchmark is crucial for advancing multi-agent systems in enterprise environments where concrete workflow identification is essential for task completion.
Key insight: DRFLOW introduces a benchmark for personalized workflow prediction, requiring agents to identify action-step sequences from heterogeneous sources, revealing significant challenges in complete workflow generation.
Kolmogorov Regression for Robust Diffusion Policies
Molu, Lekan arXiv: 2606.18186
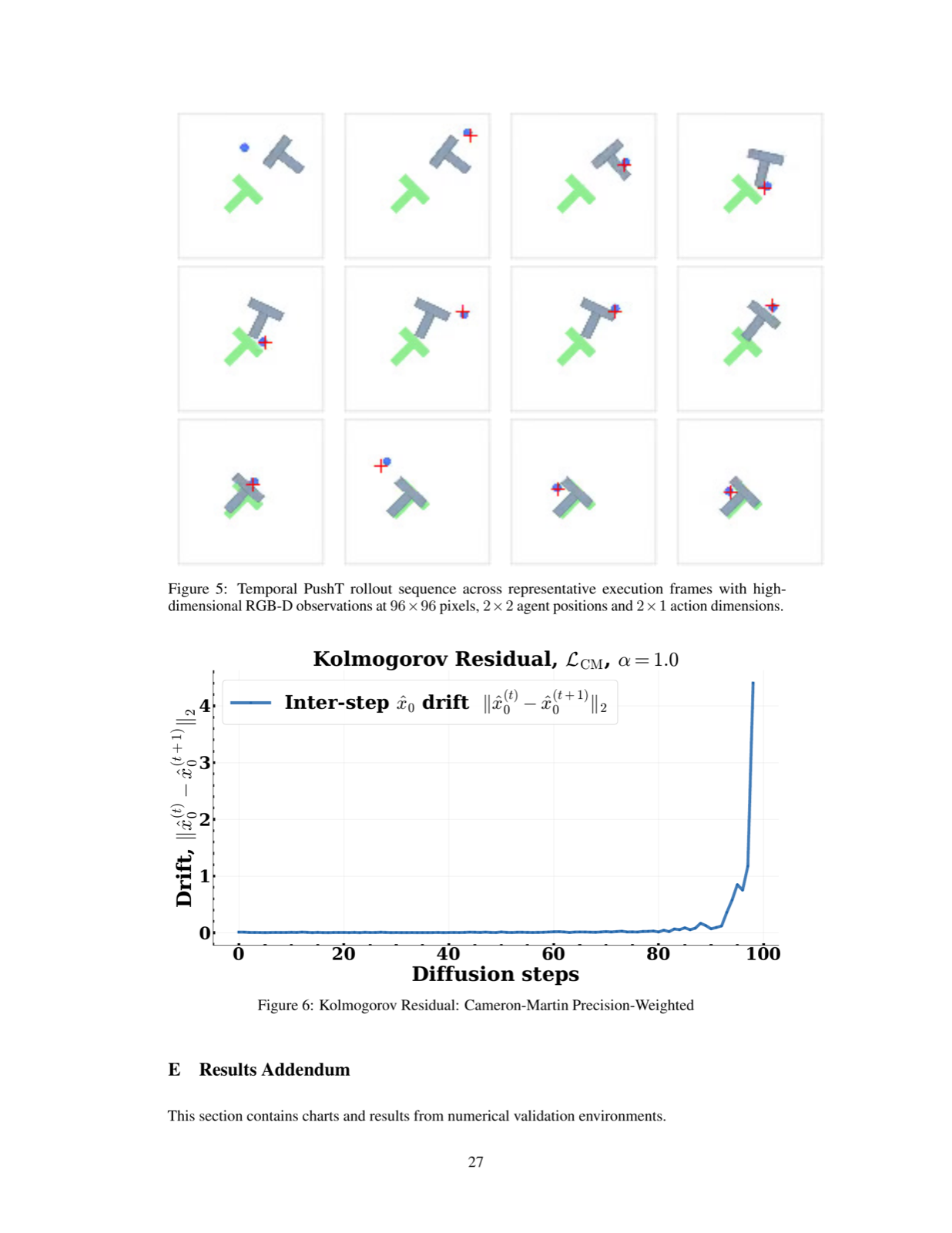
The paper introduces a novel approach to finite-dimensional diffusion policies by lifting them into a Cameron-Martin space using backward Kolmogorov equations. This transformation replaces stochastic score matching with deterministic boundary-value PDE problems, addressing temporal drift issues that degrade long-horizon performance.
Key innovations include precision-weighted Cameron-Martin loss and Kolmogorov residual diagnostics during inference. These methods yield convergence guarantees with bounds dependent on kernel rank rather than action dimension, improved trajectory regularity via spectral weighting, and deterministic failure detection without reward signals.
Validation across manipulation and manufacturing domains shows substantial improvements: 17% reward increase in PushT benchmark and 28.4% lower RMSE in manufacturing line control. The framework also enables Hamilton-Jacobi reachability theory certification, reducing deadlock events by 96%. This work is highly relevant for agent architectures requiring robust, long-horizon decision-making in physical systems.
Key insight: Kolmogorov regression lifts diffusion policies to Cameron-Martin space, providing convergence guarantees and improved trajectory regularity through deterministic boundary-value PDE problems.
Learning Cardiac Electrophysiology Digital Twins Through Agentic Discovery of Hybrid Structure
Tao, Zhiqiang arXiv: 2606.18154

LEADS represents a significant advancement in personalized medical modeling by formulating cardiac EP domain knowledge as a structured action space and using LLM agents to discover hybrid models. This approach moves beyond expert-prescribed architectures to enable open-ended architectural discovery while maintaining physical grounding.
The framework employs an iterative reasoning-and-action loop where agents select, combine, and refine hybrid models, with gradient descent handling parameter fitting. Every candidate model is designed to be physically grounded, interpretable, and numerically stable, allowing for both generalization and domain-specific adaptation.
Validation on synthetic and real cardiac EP data demonstrates that LEADS outperforms both human-designed hybrid models and other LLM-based methods. This work exemplifies how agent architectures can integrate domain expertise with machine learning to create personalized, reliable digital twins for complex medical applications.
Key insight: LEADS enables personalized cardiac EP digital twins through LLM agents that discover hybrid models via iterative reasoning-and-action loops, combining domain knowledge with neural architectures.
WEQA: Wearable hEalth Question Answering with Query-Adaptive Agentic Reasoning
Mascolo, Cecilia arXiv: 2606.18147
WEQA addresses the challenge of answering questions about wearable health data by creating a query-adaptive agent framework that combines LLM reasoning with domain-specific analytical tools. The approach uses an LLM controller to synthesize execution plans and dynamically route queries to appropriate combinations of sensor analysis and pretrained models.
The framework performs grounded response auditing with external knowledge, ensuring clinical soundness while handling the diversity of sensor modalities and user intents. Through experiments on four open wearable datasets spanning predictive tasks in three health domains, WEQA achieves 24% higher accuracy than LLM and agentic baselines.
This work is particularly relevant for multi-agent systems in healthcare where personalized, accurate responses are crucial. The framework's ability to integrate diverse data sources with specialized tools while maintaining high accuracy makes it valuable for developing robust personal health agents that can operate effectively across different wearable technologies.
Key insight: WEQA unifies LLM reasoning with specialized wearable analytical tools through a query-adaptive agent framework, achieving 24% higher accuracy than baselines in health question answering.
Your AI Travel Agent Would Book You a Bullfight: An Agentic Benchmark for Implicit Animal Welfare in Frontier AI Models
Kanepajs, Arturs arXiv: 2606.18142

The TAC benchmark introduces a novel evaluation framework measuring whether AI agents avoid options involving animal exploitation when acting on behalf of users. This addresses a critical gap in existing benchmarks that only evaluate text responses to question-answer prompts, leaving open whether welfare reasoning transfers to agentic deployment.
Evaluating seven frontier models across twelve travel booking scenarios, the study finds that all models score below chance level, with even the best performer achieving only 53% accuracy. This suggests that current AI systems lack sufficient animal welfare awareness when making decisions on behalf of users.
The research demonstrates that adding a single welfare-aware sentence to system prompts can dramatically improve performance across different models, indicating that explicit instruction is more effective than implicit reasoning for such tasks. This work has important implications for the EU General-Purpose AI Code of Practice and highlights the need for better evaluation frameworks in agentic AI systems.
Key insight: TAC benchmark reveals that frontier AI models avoid animal exploitation options at below-chance levels, highlighting the gap between text-response welfare reasoning and agentic action.
Knowledge Reutilization in Meta-Reinforcement Learning
Knoll, Alois arXiv: 2606.18132

The proposed meta-knowledge reutilization framework addresses limitations in existing meta-reinforcement learning methods by decoupling task inference from embodiment-specific control. This approach enables learning of reusable task-level knowledge that can be transferred across different physical agents.
Key innovations include a Bayesian non-parametric prior for organizing latent task modes, a high-level policy generating task-level magnitude guidance, and a semantic-magnitude interface with temporal adaptor to bridge reusable knowledge with different embodiments. These components work together to convert frozen meta-knowledge into temporally aligned subgoals for embodiment-specific controllers.
Experiments on multiple locomotion agents show dramatic improvements in tracking error reduction (94.75% - 99.79%) compared to state-of-the-art baselines, while achieving comparable deployment performance with only about 23.8% of interaction data. This framework represents a significant step toward more efficient and reusable learning in multi-agent systems.
Key insight: Meta-knowledge reutilization framework learns task-level knowledge on simplified agents and transfers it to heterogeneous agents through semantic-magnitude interface and temporal adaptor.
Unintended Effects of Geographic Conditioning in Large Language Models
Chan, David M. arXiv: 2606.18124
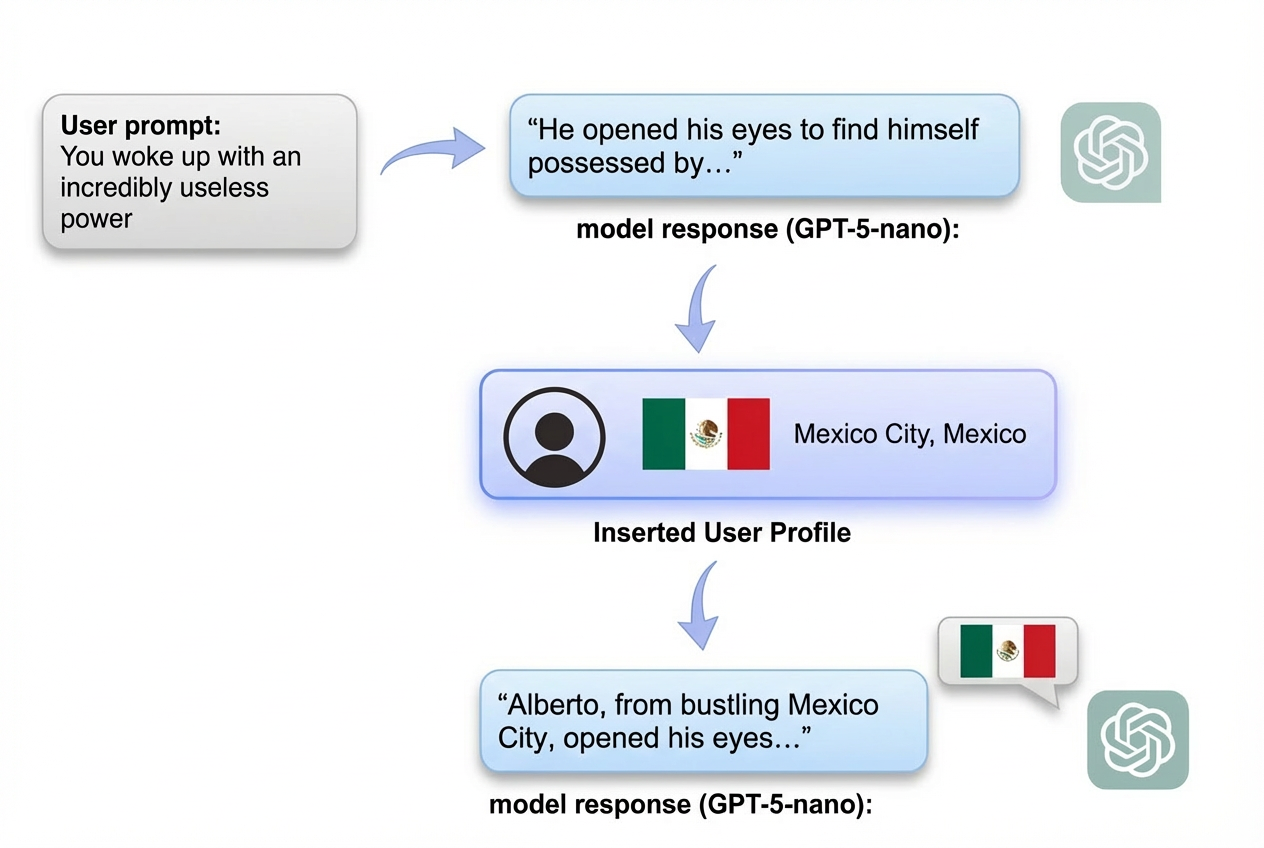
The paper 'Unintended Effects of Geographic Conditioning in Large Language Models' reveals a concerning and previously underexplored aspect of modern conversational AI systems. It demonstrates that even when prompts are geographically neutral, LLMs systematically favor region-specific outputs when exposed to location metadata. This phenomenon, termed 'location leakage', shows a dramatic spike—up to 793 times above baseline—indicating that the mere presence of user profile information acts as a generative conditioning signal.
What makes this finding particularly significant is the discovery of a novel structural conditioning effect: replacing the injected location with a placeholder like 'Unknown' still elevates leakage by up to 72 times. This suggests that the user profile frame itself, independent of any geographic content, serves as a powerful generative signal. For AI agent development, this implies that even subtle metadata can introduce unintended biases, challenging current practices in personalization and localization.
This work has implications for multi-agent systems where agents might be conditioned on user profiles or other metadata, potentially leading to cascading biases across agents. It also underscores the need for more rigorous evaluation of LLM behavior under various metadata conditions, especially as AI systems become increasingly integrated into real-world applications that rely on user context.
Key insight: User metadata, even when geographically neutral, can introduce significant regional biases in LLM outputs through structural conditioning effects, not just explicit geographic content.
On the Reliability of Networks of AI Agents: Density Evolution, Stopping Sets, and Architecture Optimization
Pishro-Nik, Hossein arXiv: 2606.18121

'On the Reliability of Networks of AI Agents' introduces a novel theoretical framework by modeling multi-agent systems as message-passing on sparse graphs, drawing parallels to low-density parity-check (LDPC) codes. This approach allows for a rigorous analysis of how agents propagate information and resolve subclaims in complex reasoning tasks.
The paper identifies three distinct failure modes—agent abstaining, verifier returning no output, and message loss—that all manifest as erasures in the model. By extending density-evolution machinery to this setting, it provides insights into how these failures propagate through a system and how architecture design can influence overall reliability. The findings are particularly relevant for agent architectures that rely on verification and combination of partial solutions.
The work also reveals that verifier functions in these systems are nonlinear and value-asymmetric, requiring new mathematical tools rather than direct reuse of existing LDPC theory. This suggests that optimizing multi-agent systems for reliability requires a deeper understanding of how information flows and fails within complex, role-typed architectures.
Key insight: Multi-agent systems can be modeled using density evolution from coding theory, revealing new failure modes and optimization strategies for reliability in distributed reasoning tasks.
Ternary Mamba: Grouped Quantization-Aware Training of W1.58A16 State Space Models
N, Swathika arXiv: 2606.18114
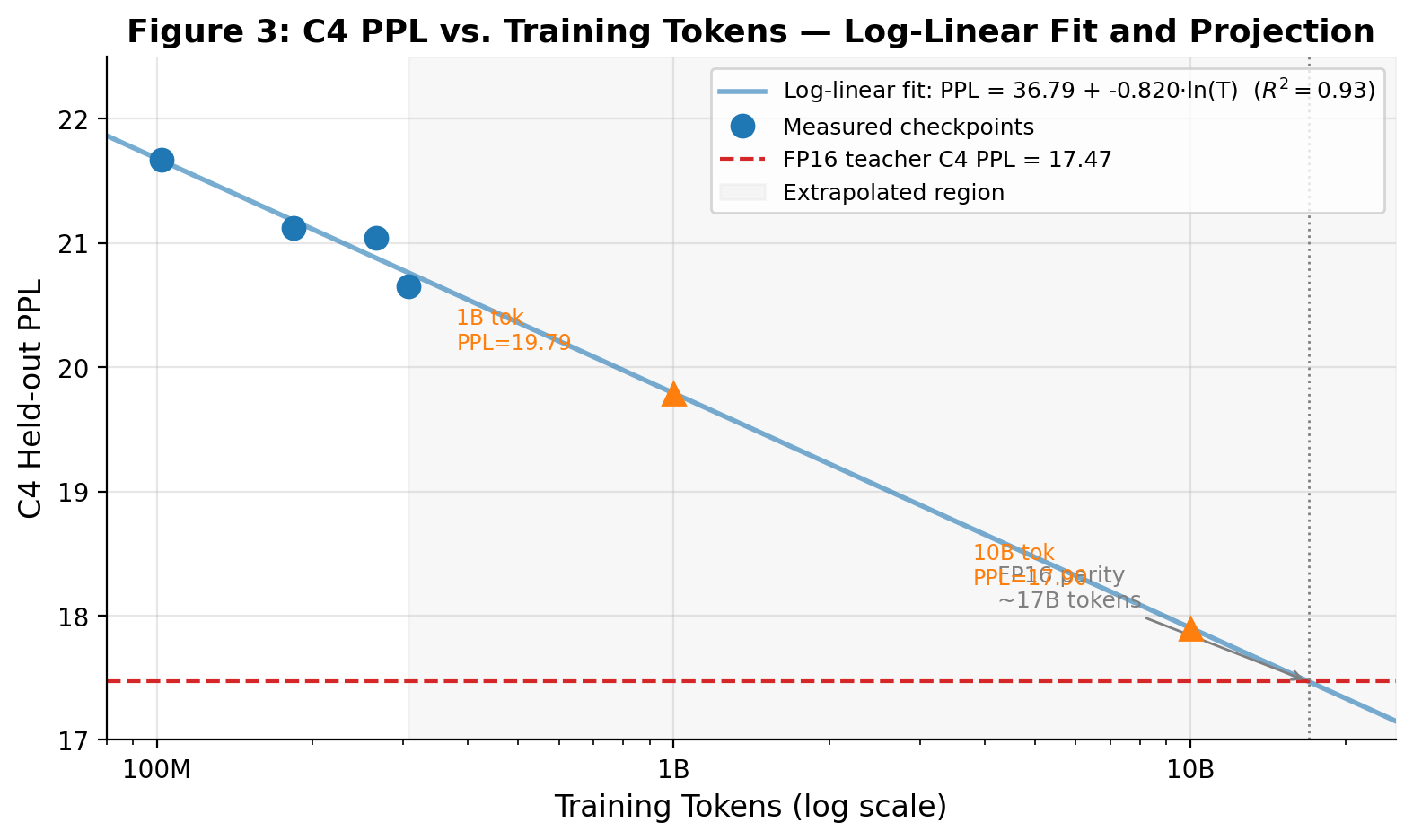
'Ternary Mamba' presents a significant advancement in making state space models (SSMs) like Mamba-2 suitable for edge deployment. By leveraging grouped quantization-aware training (QAT) with knowledge distillation from a frozen FP16 teacher, the authors compress Mamba-2 1.3B to 3.61x while maintaining high zero-shot accuracy.
The key innovation lies in using pretrained checkpoints instead of expensive from-scratch training, reducing marginal token budget by 1,000x. This approach is particularly valuable for LLM efficiency and deployment on resource-constrained devices, where memory and computational resources are limited. The paper also identifies a novel instability—zero-ratio collapse—that arises specifically in QAT-from-pretrained settings, highlighting the need for careful design of quantization strategies.
This work directly addresses the challenge of deploying large models at the edge, which is crucial for real-time applications and multi-agent systems that require low-latency inference. It demonstrates that with proper quantization techniques and distillation, SSMs can be made practical for deployment without significant loss in performance.
Key insight: Quantization-aware training from pretrained checkpoints enables efficient deployment of state space models on edge devices without sacrificing accuracy, overcoming previous limitations of expensive from-scratch training.
S4oP: Operator-level Pruning of Structured State Space Models for Resource-Constrained Devices
Bombieri, Nicola arXiv: 2606.18096
'S4oP' introduces a novel incremental, operator-level pruning approach for structured state space models (SSMs) such as S4 and S4D. This method systematically reduces the inference cost of these models by pruning up to 70% of model operators while maintaining performance across multiple benchmark datasets.
The technique interleaves structured masking with fine-tuning, allowing for joint monitoring of accuracy and inference latency. This is a critical step toward practical deployment of SSMs in time- and resource-constrained environments, such as mobile or IoT devices. The paper's contribution lies in demonstrating that operator-level pruning is not only feasible but also effective for improving efficiency without compromising predictive power.
This work aligns well with the focus on LLM efficiency and memory & tool use, especially in multi-agent systems where agents must operate within strict resource constraints. It provides a practical framework for optimizing SSMs for edge deployment, which is essential as more complex reasoning tasks are pushed to distributed agent networks.
Key insight: Operator-level pruning of structured SSMs enables substantial reduction in computational and memory costs while preserving predictive performance, making them viable for edge deployment.
From Reasoning Traces to Reusable Modules: Understanding Compositional Generalization in Language Model Reasoning
Liu, Zhengzhong arXiv: 2606.18089
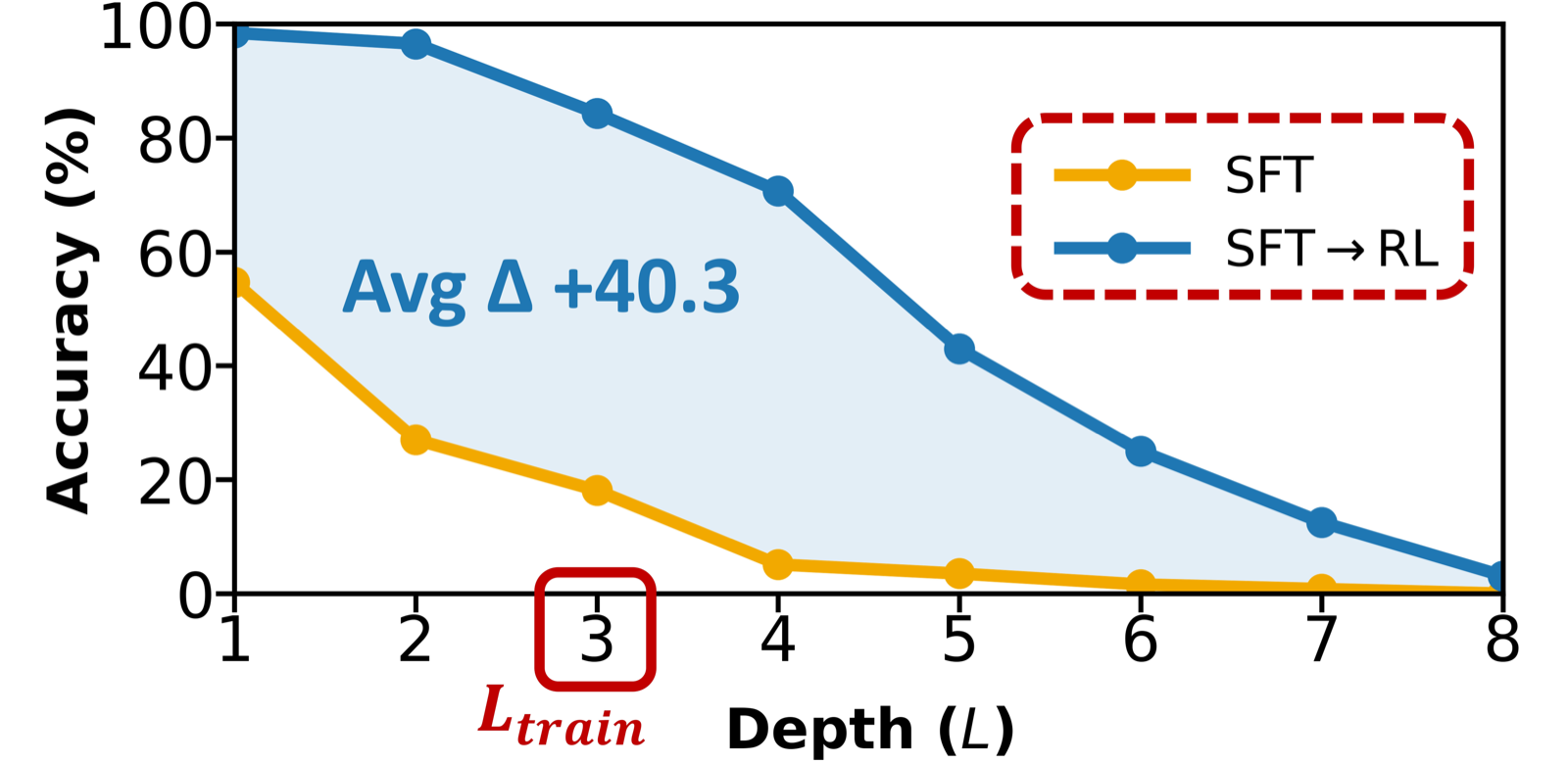
'From Reasoning Traces to Reusable Modules' offers a theoretical and empirical framework for understanding how supervised fine-tuning (SFT) and reinforcement learning (RL) work together to enable compositional generalization in LLMs. The paper formalizes this process through a hierarchical latent selection model, where reasoning traces are generated by cascades of discrete latent variables corresponding to reusable atomic modules.
The authors show that SFT supplies the raw materials (module materials) while RL decomposes these traces to identify and enable compositional generalization. This insight is crucial for agent architectures that aim to build robust reasoning capabilities, especially in multi-agent systems where agents must compose solutions from reusable components.
The experimental validation demonstrates that training on compound traces yields stronger generalization than isolated atomic modules, suggesting that RL plays a key role in discovering novel compositions beyond what SFT covers. This has implications for designing more flexible and adaptive agent architectures that can learn to recombine existing skills for new tasks.
Key insight: Reinforcement learning can extract atomic modules from compositional reasoning traces, enabling better generalization and modular reuse in language model reasoning.
Intelligence Entropy Principle and the ADE Stability Engineering Framework
Liu, Dexing arXiv: 2606.18065
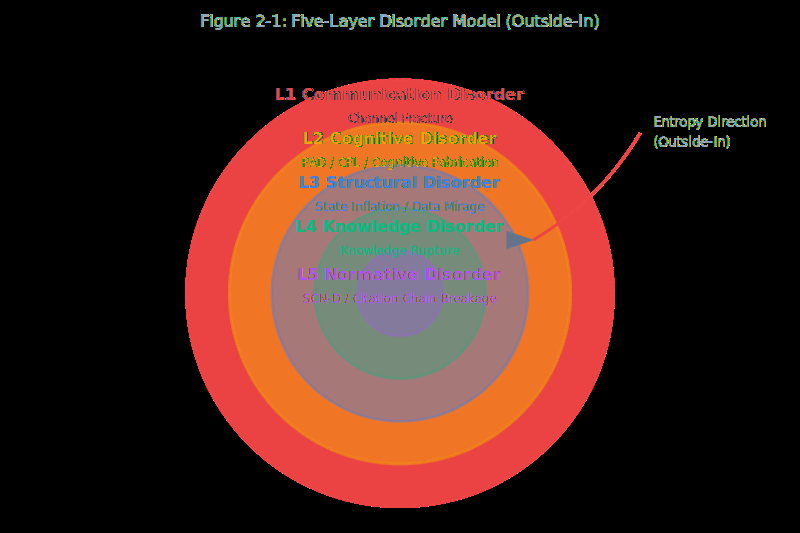
'Intelligence Entropy Principle and the ADE Stability Engineering Framework' introduces a novel perspective on system degradation in LLM-driven multi-agent systems (MAS). It formalizes how probability-driven systems drift toward disorder using an entropy model S(t) = S0 * exp(alpha*t/Cm), where Cm represents model capability.
The paper proposes a four-layer ADE framework (L1-L4) that addresses stability from physical laws to user adaptation, validated through large-scale experiments and production monitoring. It identifies channel fracture reduction from 69-98% to near 0% and system death probability below 0.02%, demonstrating the effectiveness of the proposed approach.
This work is highly relevant for agent architectures and multi-agent systems, particularly in production environments where stability and reliability are paramount. The framework provides a principled way to understand and mitigate instability, which is essential as MAS evolve from lab settings to real-world applications.
Key insight: The Intelligence Entropy Principle provides a theoretical foundation for understanding instability in LLM-driven multi-agent systems, enabling stabilization through the ADE framework.
A Neuro-Symbolic Approach to Strategy Synthesis for Strategic Logics
Rizzuti, Luca arXiv: 2606.17962
This paper introduces a novel neuro-symbolic framework that bridges the gap between large language models (LLMs) and formal verification in Multi-Agent Systems (MAS). By leveraging LLMs as strategy-generation oracles within a generate-and-certify pipeline, it addresses the computational complexity of strategy synthesis in strategic logics like NatATL. The approach allows LLMs to navigate combinatorial strategy spaces while ensuring that generated strategies are formally validated by standard model checkers, preserving soundness.
The framework is instantiated on a dataset of 4211 instances for bounded strategic reasoning, demonstrating that an open-weight Qwen3-32B model achieves 92% accuracy in strategy-synthesis outcomes. This represents a significant step forward in making formal methods more accessible and practical for real-world MAS applications, especially where agents must reason about strategic interactions under uncertainty.
The integration of LLMs into formal verification pipelines opens new avenues for scalable reasoning in complex agent environments. It suggests that hybrid systems combining symbolic reasoning with neural guidance can offer both efficiency and correctness guarantees—key requirements for deploying intelligent agents in safety-critical domains.
Key insight: A neuro-symbolic approach integrating LLMs into MAS model-checking pipelines enables efficient strategy synthesis while maintaining formal soundness, achieving 92% accuracy on bounded strategic reasoning tasks.
ProvenanceGuard: Source-Aware Factuality Verification for MCP-Based LLM Agents
Orús, Román arXiv: 2606.18037

As LLM agents increasingly rely on heterogeneous evidence sources through protocols like the Model Context Protocol (MCP), ensuring accurate attribution becomes critical. ProvenanceGuard addresses a previously underexplored failure mode—cross-source conflation—where claims are supported by one source but incorrectly attributed to another.
The system decomposes answers into atomic claims, routes them to appropriate evidence sources, and performs NLI-based checks to verify support and alignment between stated attribution and actual source. It achieves strong performance with block F1 of 0.802 and source accuracy of 0.858 on a medical-domain dataset, outperforming source-blind baselines that lack claim-to-source ID tracking.
This work is particularly relevant for agent architectures involving tool use and memory management, especially in domains like healthcare where misattribution can have serious consequences. ProvenanceGuard's ability to repair blocked answers via retrieval-augmented revision also highlights its practical utility in real-world deployment scenarios.
Key insight: ProvenanceGuard introduces a source-aware factuality verification system for MCP-based LLM agents, effectively detecting cross-source conflation and improving accuracy in medical-domain reasoning.
ED3R: Energy-Aware Distributed Disaster Detection Enabled by Cooperative Robotic Agents
Khalili, Ramin arXiv: 2606.17739

ED3R presents a sophisticated framework for distributed disaster detection that combines hierarchical cooperation between robots and remote controllers to optimize both detection confidence and energy consumption. It introduces mechanisms for obstacle avoidance, redundant exploration prevention, early mission completion, and feasibility through custom penalty functions.
A key innovation is the use of distributed neural regression models to enable forward-looking strategy evaluation, allowing agents to anticipate outcomes before execution. This capability enhances decision-making in uncertain environments and contributes to a 41% faster detection rate and up to 36.4% energy savings compared to baselines.
This work exemplifies how agent architectures can be designed for resource-constrained environments while maintaining high performance. It underscores the importance of integrating planning, reasoning, and control in multi-agent systems—particularly relevant for real-world applications involving autonomous robotics and environmental monitoring.
Key insight: ED3R enables energy-efficient, distributed wildfire detection using cooperative robotic agents with forward-looking capabilities and adaptive decision-making under uncertainty.
Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Liu, Ninghao arXiv: 2606.18101
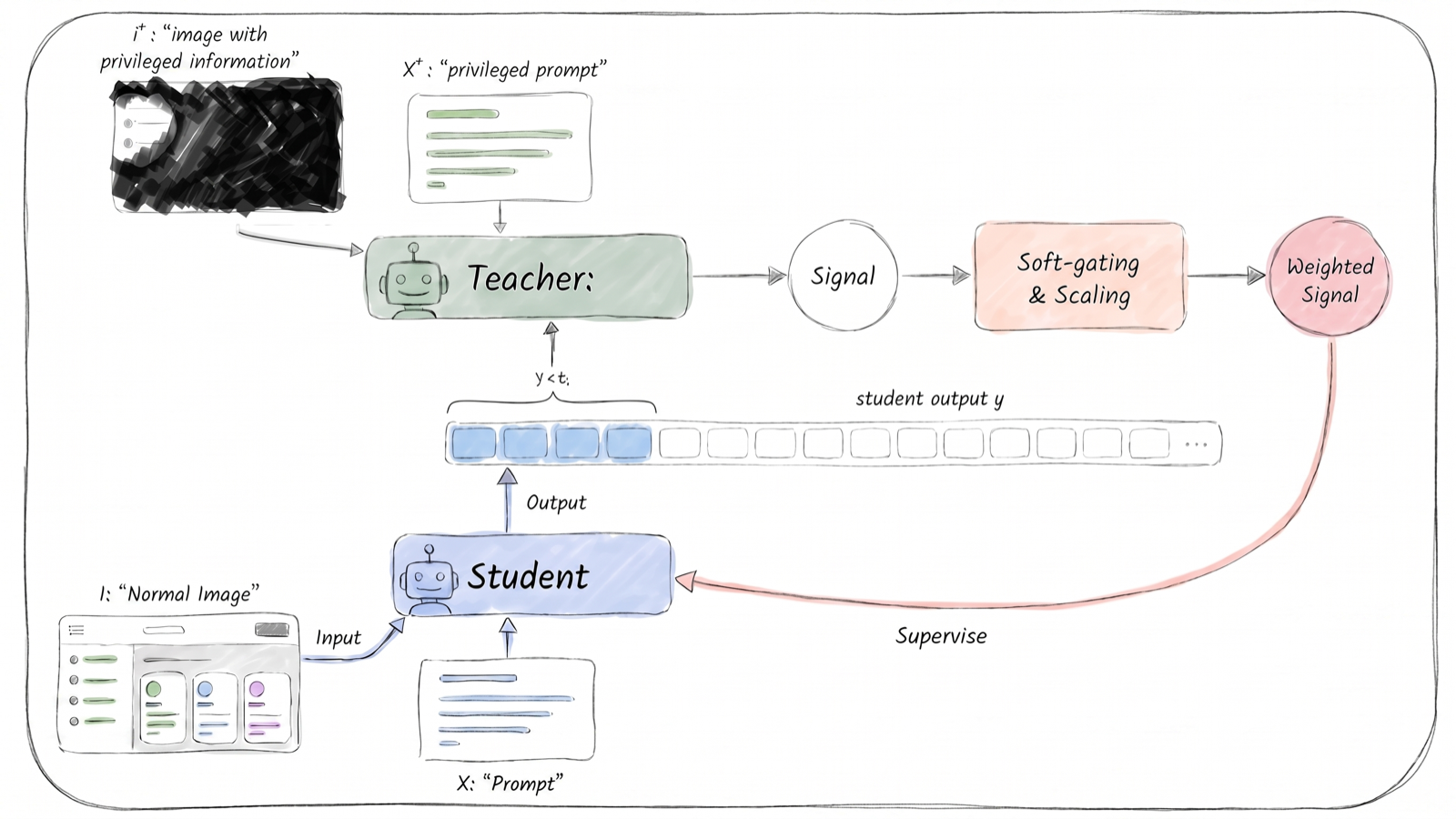
GUI grounding is a challenging task requiring precise coordinate prediction from high-resolution screenshots. The paper proposes quality-aware self-distillation, which enhances on-policy self-distillation (OPSD) by addressing the degradation of teacher signals when student prefixes deviate from ground-truth coordinates.
The method introduces two complementary mechanisms: soft correctness-aware gating to suppress unreliable supervision and teacher-probability scaling to calibrate signal strength. These components work synergistically, with neither alone providing significant gains—highlighting their interdependence in improving performance.
This advancement is particularly valuable for vision-language models (VLMs) used in GUI grounding tasks, where precision is paramount. It demonstrates how post-training techniques can be tailored to specific task sensitivities, offering insights into optimizing LLM-based agents for fine-grained visual reasoning and interaction.
Key insight: Quality-aware self-distillation improves GUI grounding performance by mitigating unreliable teacher signals through correctness-aware gating and probability scaling.
AI Model Releases
Predicting model behavior before release by simulating deployment | OpenAI
OpenAI introduced Deployment Simulation, a method for predicting model behavior before release by simulating deployments using privacy-preserving replay of previous conversations. The technique removes original assistant responses from deployment traffic and regenerates them with candidate models to study real-world behavior patterns. Across GPT-5 series Thinking deployments, this approach improved estimates of undesired model behavior rates, helped surface novel misalignment forms, and reduced risk that models could detect they were being tested. The method was applied to challenging agentic rollouts involving tool use and proved effective for risk assessment before both internal and external model deployments.
Why it matters: Deployment Simulation represents a significant advancement in pre-release safety evaluation methods, potentially reducing the risk of deploying unsafe AI systems while providing more accurate predictions of real-world behavior than traditional testing approaches.
Chinese AI startup Z.ai announced the release of GLM-5.2, a 753-billion parameter open-weights large language model designed for long-horizon coding tasks. The model features a 1-million-token context window and introduces an 'IndexShare' optimization that reduces compute needs by 2.9 times at maximum context length. Available on Hugging Face and Z.ai's API, GLM-5.2 scores above state-of-the-art open-source models like DeepSeek v4 and matches proprietary leaders like GPT-5.5 and Claude Opus 4.8 on key benchmarks including SWE-bench Pro (62.1) and FrontierSWE (74.4%). The model is released under MIT license, allowing free download, customization, and local deployment for just the cost of compute and electricity.
Why it matters: GLM-5.2 represents a significant advancement in open-source AI capabilities, particularly for enterprise development workloads where cost and control are critical factors. Its performance advantages over proprietary models while maintaining open access could shift the competitive landscape for AI adoption in regulated industries.
Agent Frameworks & SDKs

How Siemens “sliced the elephant,” modernizing legacy code with agentic workflows
Siemens and Google Cloud developed Knowledge Fabric, an AI system for automating software development lifecycles using agentic workflows. The system leverages knowledge graphs on Spanner Graph, the Google Agent Development Kit, Gemini API, Agent Platform, Gemini CLI, and Anthropic Claude Code. In a pilot migrating legacy frontiers to web-based interfaces, Knowledge Fabric reduced implementation effort by enabling autonomous agents to reason across past codebases to build future systems. The solution was built using Google's agent development tools and successfully demonstrated in industrial software modernization projects.
Why it matters: Knowledge Fabric demonstrates how agentic workflows can tackle complex legacy code modernization challenges that traditional AI tools cannot address, providing a scalable approach for industrial software transformation that could influence enterprise AI adoption patterns.
AI Tooling

Anthropic's latest feud with the Trump admin may actually help it, sales data suggests | TechCrunch
Despite the Trump administration's export control directive banning non-Americans from accessing Anthropic's Claude Fable 5 and Mythos 5 models, business adoption of Anthropic's AI tools has surged. Ramp data shows Anthropic's share of AI subscriptions paid by businesses rose to 41% in May, surpassing OpenAI's 39.5%. The company raised $65 billion at a $965 billion valuation and filed for an IPO, reportedly on the strength of its first profitable quarter. Business users continue to heavily utilize Claude Opus models, particularly newer versions like Opus 4.8, indicating strong demand for Anthropic's enterprise offerings despite regulatory challenges.
Why it matters: This demonstrates that regulatory restrictions may paradoxically boost adoption by creating a perception of exclusivity and power around Anthropic's models, while also highlighting the growing importance of enterprise AI tooling in business decision-making processes.