OpenAI has announced the launch of its Partner Network to help enterprises adopt frontier AI models and achieve measurable impact. Simultaneously, the AI industry is experiencing a wave of IPOs as companies like OpenAI and Anthropic prepare for public markets, shifting investment patterns toward AI-focused ventures.
OpenAI's new Partner Network represents a significant strategic move to address the gap between advanced AI model capabilities and enterprise implementation by connecting organizations with trusted partners who possess deep industry expertise and global delivery capacity. The network includes three tiers (Select, Advanced, Elite) and will train 300,000 certified consultants by end of 2026, with OpenAI investing $150 million in this ecosystem. This development signals a fundamental shift in how AI adoption is approached at the enterprise level, emphasizing ecosystem partnerships over direct model deployment. Meanwhile, the broader AI industry is experiencing a wave of IPOs as companies race to go public, with OpenAI and Anthropic both confidentially filing for IPOs and the 'SpaceX IPO wave' creating a ripple effect that's shifting capital flows from traditional tech giants like FAANG to newer AI-focused companies including Meta, NVIDIA, Google, and SpaceX.
Research Papers
GitOfThoughts: Version-Controlled Reasoning and Agent Memory You Can Replay, Diff, and Merge
Krishnan, Aswanth arXiv: 2606.14470
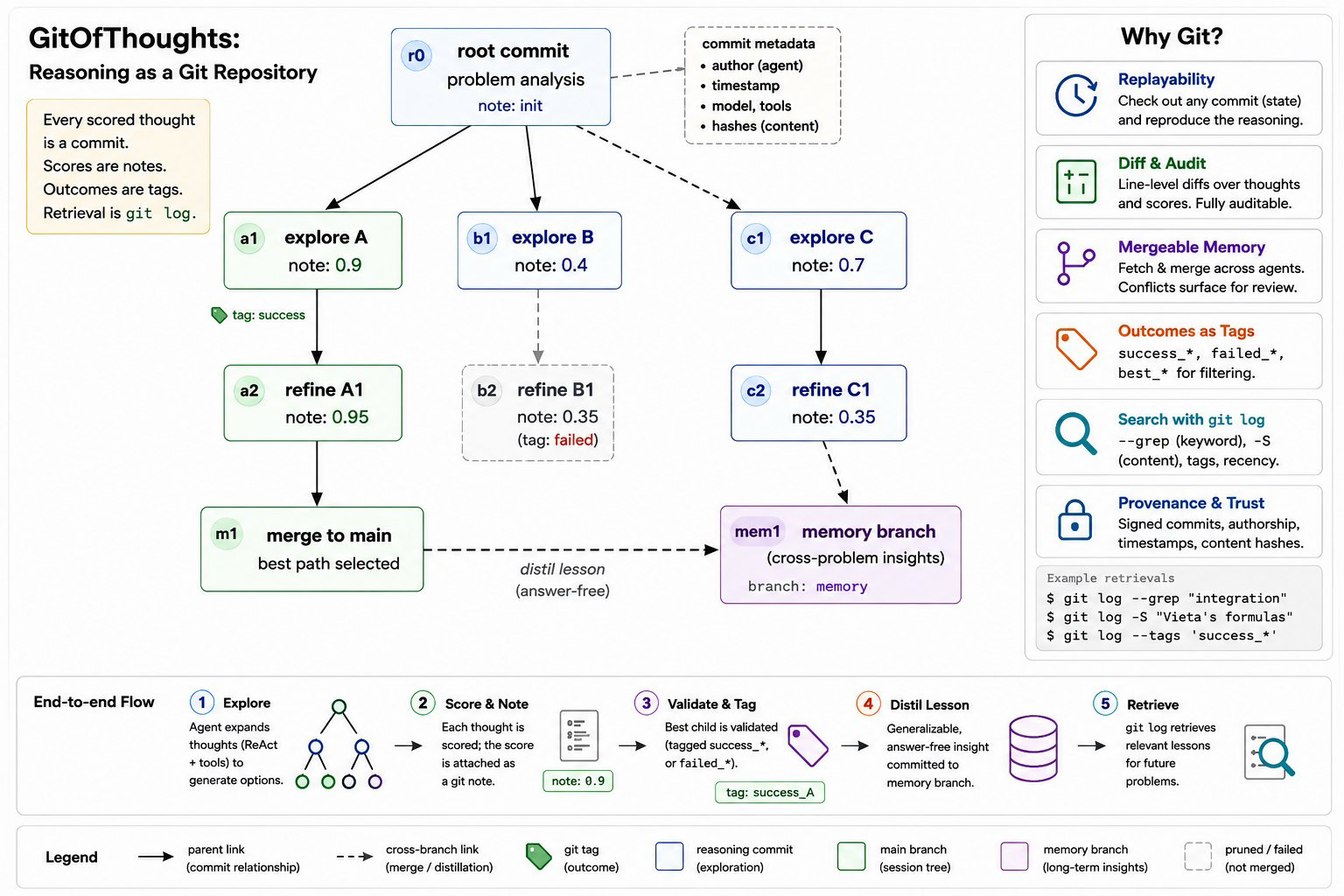
The paper introduces GitOfThoughts, a framework that stores an agent's reasoning tree as a git repository, enabling replayability, auditability, and mergeability. This approach treats each scored thought as a commit, outcomes as tags, and retrieval via standard git commands like 'git log'. The innovation lies in treating reasoning not as ephemeral but as a version-controlled artifact, which is particularly valuable for debugging, collaboration, and system evolution.
However, the core finding challenges conventional wisdom about memory's utility. Across multiple substrates (none, markdown, vector, graph, git) and benchmarks, the authors found that memory formats do not reliably improve accuracy on novel problems. Only when retrieved cases are near-duplicates (similarity >~ 0.8) does performance significantly increase. This suggests that memory is useful primarily for answer retrieval rather than method transfer, even with larger models or more sophisticated architectures.
The implications are significant for agent development: while GitOfThoughts provides strong benefits in terms of auditability and provenance, it does not offer a general accuracy boost. The authors emphasize that the only consistent lever for improvement is test-time sampling, indicating that the value of memory lies more in its structure than in its content. This work sets a new standard for evaluating memory systems by documenting retracted results and refuted hypotheses.
Key insight: Git-of-Thoughts enables version-controlled reasoning for agents, but memory substrates do not generally improve accuracy beyond a 'copyability threshold' where retrieved cases are near-duplicates of current problems.
StreamMemBench: Streaming Evaluation of Agent Memory for Future-Oriented Assistance
Lu, Tun arXiv: 2606.14571
StreamMemBench addresses a critical gap in existing memory benchmarks: they typically test recall or task improvement in isolation, but fail to evaluate how memory supports future-oriented assistance. The benchmark constructs two-step tasks around evidence anchors from EgoLife egocentric streams, testing both initial evidence use and follow-up reuse of feedback.
The evaluation reveals that current systems often fail to utilize observed evidence or turn feedback into reliable follow-up behavior, even when the information is stored locally. This highlights a fundamental challenge in designing memory systems for personal agents: they must not only store but also effectively carry forward relevant cues from one interaction to similar future tasks.
By introducing four diagnostic metrics—evidence recall, initial evidence use, feedback incorporation, and follow-up reuse—StreamMemBench provides a comprehensive framework for assessing memory systems. The benchmark is publicly available, enabling further research into how agents can better integrate streaming observations into long-term assistance strategies.
Key insight: StreamMemBench evaluates how agent memory supports future-oriented assistance by testing the reuse of evidence and feedback across tasks, revealing that current systems often fail to leverage streaming observations effectively.
Naive Visual Memory is Not Enough: A Failure-Mode Study of GUI Agents
Shin, Jinwoo arXiv: 2606.14106
This paper systematically analyzes the impact of visual memory on GUI agents using a taxonomy of four failure modes: cognitive failure, visual state misunderstanding, hidden operation blindness, and grounding error. The authors find that prepending full-image memory has divergent effects—reducing state-level failures but worsening action-level ones, particularly increasing hidden operation blindness and grounding errors.
To address these issues, the paper proposes Action-Grounded Visual Memory (AGMem), which stores image crops related to successful actions or recovery rather than full screenshots. This targeted approach significantly improves task success rates by 33.3% on OSWorld, demonstrating that visual memory must be carefully designed to align with agent decision-making processes.
The study underscores the importance of understanding how different types of memory interact with various stages of perception-reasoning-action pipelines. It also highlights the need for more nuanced evaluation methods that can distinguish between beneficial and detrimental effects of memory systems in complex environments.
Key insight: Naive visual memory in GUI agents can exacerbate certain failure modes like hidden operation blindness and grounding errors, while a more targeted approach—Action-Grounded Visual Memory (AGMem)—improves task success by 33.3%.
Towards Direct Latent-Space Synthesis for Parallel Branches in LLM-Agent Workflows
Li, Pan arXiv: 2606.14672

Parallel-Synthesis introduces a plug-and-play framework that allows synthesizers to directly consume KV caches produced by parallel worker agents, bypassing the need for sequential text concatenation. This approach addresses a mismatch between modern structured agent workflows and traditional LLM interfaces, which are inherently sequential.
The system combines a cache mapper that calibrates independently generated branch caches with a fine-tuned synthesizer adapter to enable generation from non-sequential cache interfaces. It trains using data exposing the synthesizer to parallel cache contexts, teaching aggregation across cached branches and distilling reasoning behavior from standard text-concatenation-based synthesis.
Experimental results on nine downstream datasets show that Parallel-Synthesis matches or outperforms text-based synthesis on seven datasets and remains close on the others, while also reducing time-to-first-token by 2.5x-11x. This suggests that direct cache-based synthesis is a promising interface for more efficient and native parallel agent workflows.
Key insight: Parallel-Synthesis enables direct latent-space synthesis from KV caches of parallel branches, reducing time-to-first-token by up to 11x and matching or outperforming text-based synthesis on multiple datasets.
HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry
Luan, Jian arXiv: 2606.14249
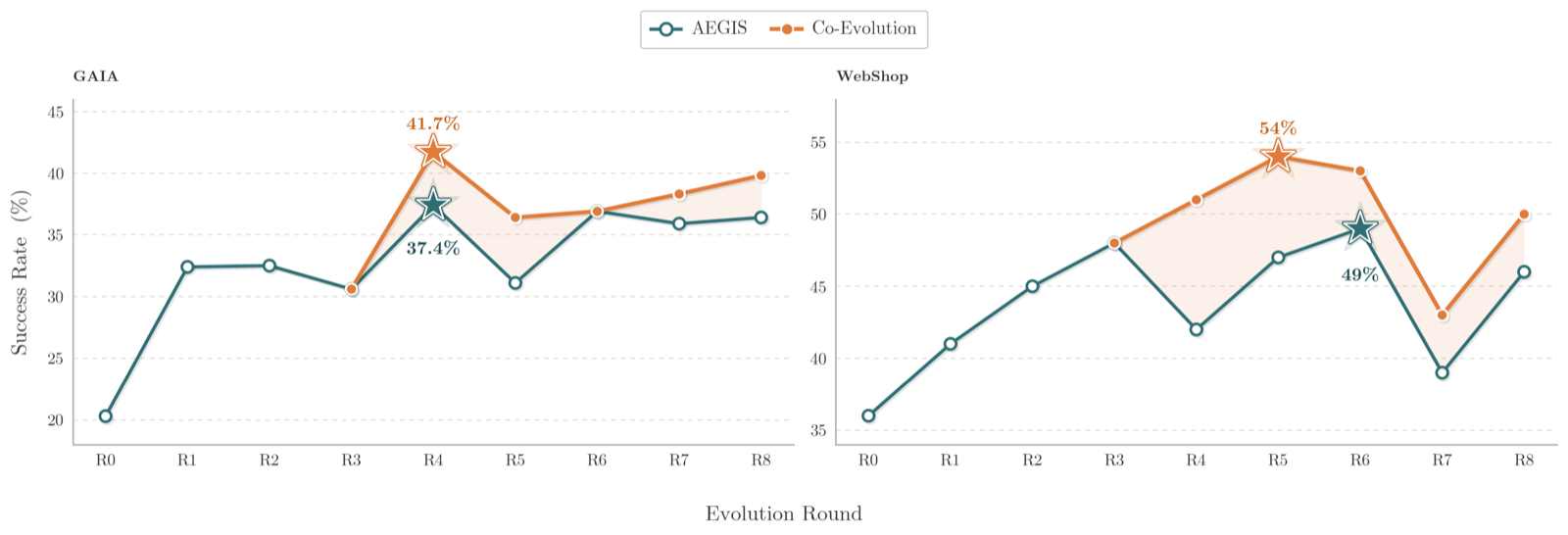
HarnessX represents a significant step toward automating the design of agent runtime interfaces by introducing a foundry for composable, adaptive, and evolvable harnesses. It uses a substitution algebra to assemble typed harness primitives, adapts them through AEGIS—a trace-driven multi-agent evolution engine grounded in symbolic adaptation and reinforcement learning—and closes the harness-model loop by turning execution trajectories into both harness updates and model training signals.
The framework demonstrates substantial performance gains across five benchmarks (ALFWorld, GAIA, WebShop, tau^3-Bench, and SWE-bench Verified), achieving an average gain of +14.5% with maximum gains up to +44.0%. These results suggest that agent progress can be achieved not only through model scaling but also by composing and evolving runtime interfaces from execution feedback.
HarnessX challenges the status quo of hand-crafted, static harnesses by showing how dynamic adaptation based on real-world performance traces can lead to better agent behavior. The open-sourcing of the codebase will likely accelerate further research into automated harness design and optimization.
Key insight: HarnessX enables composable, adaptive, and evolvable agent harnesses through a substitution algebra, trace-driven evolution engine (AEGIS), and feedback loops that update both harnesses and models based on execution trajectories.
CacheRL:Multi-Turn Tool-Calling Agents via Cached Rollouts and Hybrid Reward
Kim, Gyuhak arXiv: 2606.14179
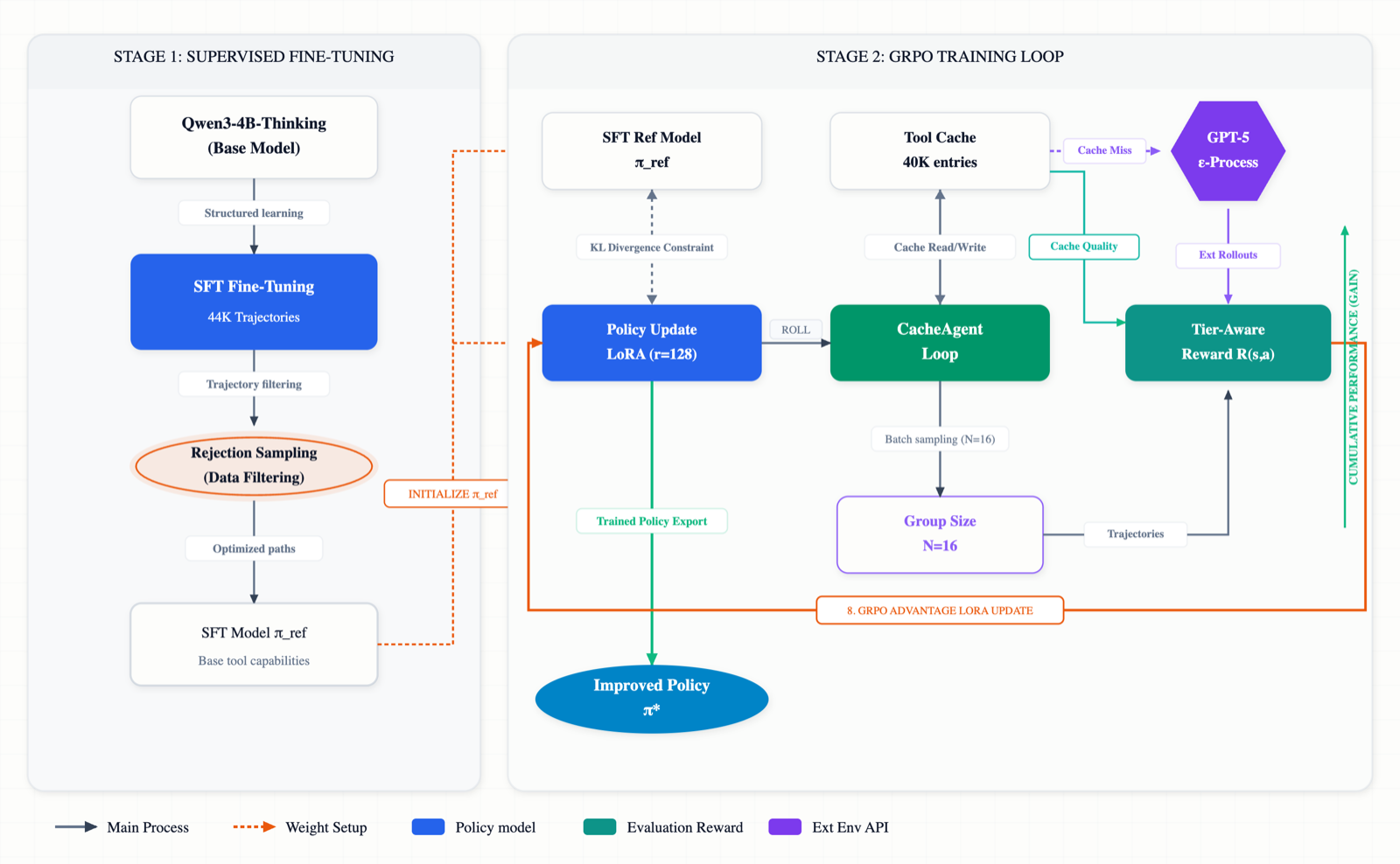
CacheRL presents a novel approach to training small agent foundation models for multi-turn tool-calling tasks by leveraging cached rollouts and hybrid reward mechanisms. It addresses three major challenges in practical agent training: transferring tool-calling knowledge from large models, enabling reinforcement learning without costly live execution, and learning robustly from noisy cached environments.
The system introduces a hybrid thinking trajectory pipeline that augments agent trajectories with LLM-generated reasoning traces, producing training examples that teach both what tools to call and why. It also employs a three-tier fuzzy cache to eliminate live execution costs while preserving trajectory fidelity using token-level masking. A cache-tier-aware reward dynamically adjusts answer-quality weights to avoid penalizing models for cache-induced limitations.
Through iterative supervised fine-tuning and Group Relative Policy Optimization (GRPO), CacheRL improves Qwen3-4B-Thinking's validation reward from 0.43 to 0.78, achieving competitive performance against frontier models like GPT-5. Ablation studies show that removing knowledge transfer reduces performance by 41%, while cache-aware rewards contribute a 17% improvement, highlighting the importance of data quality and reward design over complex optimization methods.
Key insight: CacheRL achieves 92% process accuracy on multi-step tool-calling tasks using cached rollouts and hybrid reward mechanisms, requiring 100x less compute than GPT-5 while maintaining competitive performance.
From Chatbot to Digital Colleague: The Paradigm Shift Toward Persistent Autonomous AI
Yu, Philip S. arXiv: 2606.14502
The transition from chatbots to digital colleagues represents a fundamental shift in how LLMs are conceptualized and deployed. This evolution moves beyond simple next-token prediction towards more deliberate cognition involving Chain-of-Thought reasoning, reflection, and reinforcement learning. The paper's emphasis on 'Thinking LLMs' highlights the importance of inference-time computation and structured reasoning processes that enable more reliable and robust decision-making.
At the execution level, the move from ad-hoc tool-calling to persistent workspaces with reusable skills and verification loops marks a significant advancement in agent autonomy. The 'Workspace + Skill' paradigm allows for state persistence, task closure, and experience reuse, which are crucial for long-term autonomous operation. This approach enables agents to function more like colleagues who can maintain context across multiple interactions and learn from past experiences.
The paper's examination of data construction shifts—from instruction-response pairs to State-Action-Observation trajectories—suggests a move towards more sophisticated evaluation methods that can capture the dynamic nature of persistent AI systems. This shift implies that future benchmarks must evolve to assess not just static performance but also the ability to operate within complex, evolving environments where agents must continuously adapt and improve.
Key insight: LLMs are evolving from conversational tools to persistent autonomous agents with integrated reasoning, memory, and tool use capabilities.
When the Tool Decides: LLM Agents Defer Blindly to Graph Neural Network Tools, and Stronger Backbones Defer More
Vemuri, Pratyusha arXiv: 2606.14476

This paper reveals a concerning pattern in LLM-agent-tool interactions: despite the assumption that agents exercise judgment over tool usage, empirical evidence shows that agents frequently adopt tool outputs wholesale, particularly when the tool is a frozen GNN. This behavior suggests that current agent architectures may not be effectively integrating tool use with their own reasoning capabilities, leading to suboptimal performance.
The finding that deference increases with model capability (from 0.60 to 0.98 agreement as backbone size grows from 1.5B to 7B) indicates this isn't merely a weak-model artifact but a systemic issue in how agents process and integrate tool information. This suggests that simply increasing model capacity won't solve the problem of blind deference, requiring more sophisticated integration mechanisms.
The paper's implications are significant for multi-agent systems and tool use architectures. It demonstrates that evaluations of agent-tool systems cannot assume that agents add judgment on top of tools; instead, selective invocation must be explicitly designed rather than expected to emerge from scale. This challenges current approaches to building intelligent agents that rely heavily on external tools.
Key insight: LLM agents often blindly defer to graph neural network tools rather than exercising judgment, even with stronger backbone models.
Causal Object-Centric Models for Planning with Monte Carlo Tree Search
Panov, Aleksandr arXiv: 2606.14418
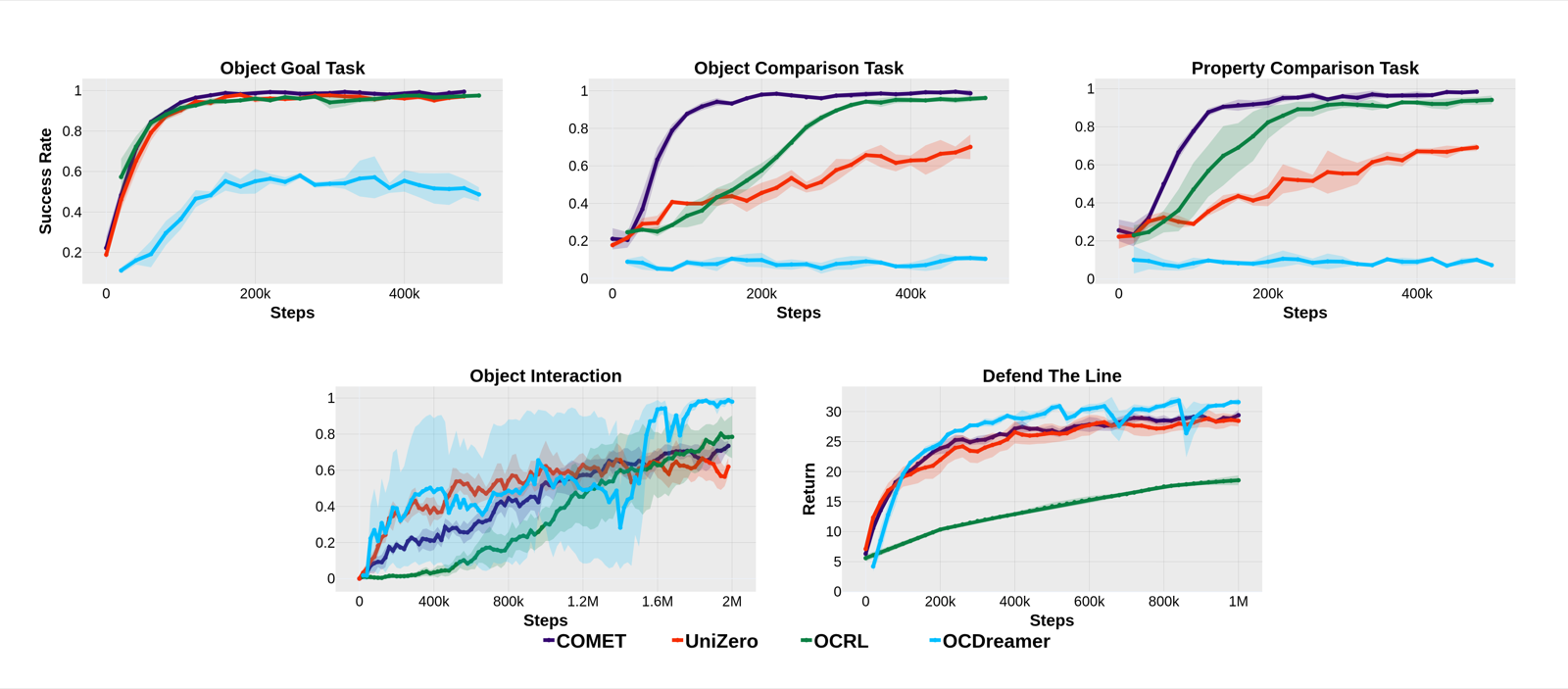
COMET introduces a novel approach to reinforcement learning by integrating causal object-centric modeling with Monte Carlo Tree Search in a slot-structured latent space. This combination leverages both the representational power of unsupervised object-centric encoders and the predictive capabilities of transformer-based world models, creating a more efficient planning framework.
The action-slot fusion mechanism that binds actions to objects through learned relevance scores represents an important advancement in how agents focus their attention during decision-making. By modulating token interactions based on per-slot relevance scores, the model ensures that decision-making concentrates on task-relevant entities, which is crucial for complex environments where not all information is equally important.
The paper's demonstration across diverse tasks from multiple benchmarks shows that COMET achieves higher mean normalized scores during early training stages compared to baselines. This suggests that causal object-centric modeling provides a strong inductive bias that accelerates learning and improves performance, particularly in visually and dynamically complex environments where traditional approaches may struggle.
Key insight: Causal object-centric models improve planning efficiency by combining unsupervised encoding with transformer-based world models.
AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
Shen, Xiaoyu arXiv: 2606.14694

AdaSR addresses the challenge of dynamic information processing by enabling models to reason during input streaming and perform final deliberation once the stream is complete. This approach moves beyond static context processing to a more adaptive framework where computational resources are allocated based on the evolving nature of the input, which is particularly relevant for real-time applications.
The introduction of Hierarchical Relative Policy Optimization (HRPO) provides a novel method for decomposing policy optimization into streaming and deep reasoning phases. This fine-grained advantage assignment allows for more precise control over when and how much computation is allocated at different stages, leading to better balance among accuracy, efficiency, and latency.
The framework's ability to learn when to think and how much computation to allocate across different stages represents a significant step forward in adaptive reasoning systems. This approach could be particularly valuable for applications where information arrives continuously and models must make decisions with partial observations, such as real-time video analysis or streaming data processing.
Key insight: Adaptive streaming reasoning with hierarchical relative policy optimization enables flexible computation allocation during input processing.
AgentSpec: Understanding Embodied Agent Scaffolds Through Controlled Composition
Qin, Lianhui arXiv: 2606.14674

AgentSpec introduces a modular framework that standardizes interfaces among perception, memory, reasoning, reflection, action, and learning components. This approach allows for systematic analysis of how different modules interact and contribute to overall agent performance, which is crucial for understanding complex agent behaviors in embodied environments.
The finding that agent performance is governed by scaffold compatibility and interaction effects rather than isolated module strength highlights the importance of considering component interactions in agent design. This suggests that optimizing individual components may not be sufficient; instead, the entire scaffold structure needs to be considered for optimal performance.
The framework's application across multiple environments (DeliveryBench, ALFRED, MiniGrid, RoboTHOR) demonstrates its versatility and potential for broader adoption. By enabling controlled composition and recombination of modules, AgentSpec provides a foundation for studying, comparing, and designing composable LLM agents that can be adapted to various tasks and environments.
Key insight: Modular agent specification frameworks enable controlled composition and comparison of agent components.
SIMMER: Benchmarking Latent Failures in LLM Executable Planning with a World Model
Zhang, Rui arXiv: 2606.14574
SIMMER addresses a critical gap in current LLM planning evaluation by focusing on latent failures—those that don't immediately halt execution but silently compromise goal achievement. This distinction is crucial for understanding the true reliability of LLM planners in real-world applications where such failures can lead to irreversible consequences.
The benchmark's use of a human-curated symbolic world model grounded in kitchen environments provides a realistic testbed for evaluating planning robustness. The inclusion of state machine execution that validates plans against the world model and detects both immediate violations and latent hazards offers a comprehensive evaluation framework that current benchmarks often overlook.
The finding that even frontier models achieve at most 17% error-free plans and that up to 56% of plans contain latent failures highlights the significant challenges in developing robust LLM planners. The demonstration that explicit state reasoning via counterfactual foresight simulation can reduce latent failures by up to 72% suggests promising directions for improving planning reliability through better reasoning mechanisms.
Key insight: LLM planners often fail silently through latent failures that compromise goal achievement without immediate feedback.
Fodor and Pylyshyn's Systematicity Challenge Still Stands
Mascarenhas, Salvador arXiv: 2606.14512

This paper directly confronts a foundational challenge in cognitive science and artificial intelligence: the systematicity challenge posed by Fodor and Pylyshyn. The authors argue that despite recent successes of neural networks in generating human-like language, these systems still cannot explain the systematic biconditional dependencies that characterize human cognition. For example, understanding 'John saw Mary' should logically entail understanding 'Mary saw John,' a property that symbolic systems naturally capture but neural networks do not.
The paper critically evaluates recent claims by Lake and Baroni that their meta-learning for compositionality protocol can match or explain human systematicity. Mascarenhas demonstrates that these models struggle with even slight out-of-distribution rules and often behave unsystematically on in-distribution problems. This suggests that the core issue remains unresolved, indicating a fundamental gap between neural network architectures and the cognitive mechanisms underlying human language understanding.
This work has significant implications for AI agent development, particularly in areas requiring robust reasoning and generalization. If neural networks cannot replicate systematicity, then they may be limited in their ability to perform complex linguistic tasks that depend on abstract logical relationships. This challenges the assumption that large-scale language models alone can achieve human-level cognition without incorporating symbolic or structured reasoning components.
Key insight: Neural networks still fail to explain human systematicity in language understanding, challenging claims that they have solved classical cognitive science puzzles.
A Computational Audit of Demographic Association Encoding in ClinicalBERT Language Predictions
Soetan, Kehinde Temitayo arXiv: 2606.14460

This paper presents a detailed computational audit of representational bias in ClinicalBERT, revealing that the model's demographic associations are not merely inherited from its training corpus but are actively amplified through internal mechanisms. Using Log Probability Bias Analysis and Masked Language Model-based probing techniques, the authors show that 80% of findings for Black patients and 87.5% for agency attribution contradict observed corpus distributions.
The implications for healthcare AI are profound. As clinical language models become integrated into high-stakes decision support systems, understanding how bias is generated internally rather than just passed down from data is crucial. This suggests that even if training data appears balanced, the model's internal representations can still perpetuate or exacerbate disparities, undermining efforts toward health equity.
This work underscores the importance of continuous monitoring and auditing of AI systems in sensitive domains like healthcare. It calls for more sophisticated approaches to bias detection beyond simple statistical disparity analysis, emphasizing that model-internal amplification is a critical mechanism that must be addressed to ensure fair and equitable outcomes.
Key insight: ClinicalBERT amplifies demographic biases internally rather than simply inheriting them from training data, highlighting the need for more rigorous auditing of AI in healthcare.
Persona-Pruner: Sculpting Lightweight Models for Role-Playing
Jeong, Jongheon arXiv: 2606.14695
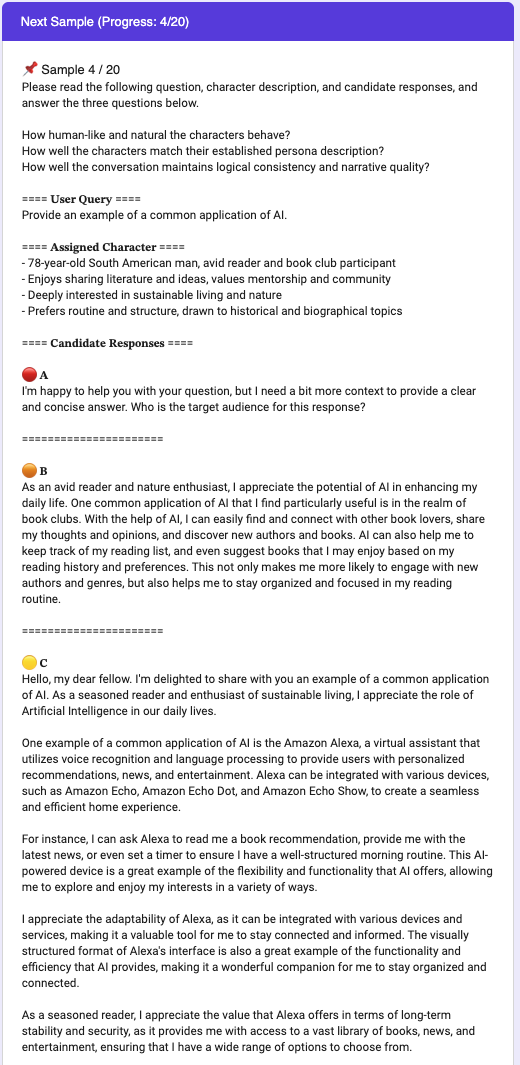
The paper introduces Persona-Pruner, a framework designed to create lightweight models for role-playing chatbots. The core insight is that full generalist language models are inefficient for single-character applications, as only a fraction of their capacity is needed for specific persona tasks. By isolating persona-specific sub-networks from a single description, the method achieves substantial performance preservation while dramatically reducing computational overhead.
This approach addresses a critical bottleneck in real-world AI deployment, especially in gaming ecosystems with numerous NPCs or customer service applications requiring multiple distinct personalities. The results show that Persona-Pruner reduces performance drop by up to 93.8% compared to existing pruning techniques, maintaining both role-playing fidelity and general LLM capabilities.
The technique has broad implications for agent architectures and memory & tool use in AI systems. It suggests a path toward more efficient multi-agent systems where each agent can be tailored to specific roles without sacrificing overall performance, potentially enabling scalable deployment of personalized AI assistants or virtual characters.
Key insight: Persona-Pruner enables efficient role-playing by isolating persona-specific sub-networks, significantly reducing performance drop compared to standard pruning methods.
When to Write and When to Suppress: Route-Specialized Dual Adapters for Memory-Assisted Knowledge Editing
Huang, Yining arXiv: 2606.14668

This paper tackles the challenge of memory-assisted knowledge editing by introducing a route-specialized dual adapter system. The key innovation is recognizing that successful editing isn't just about injecting new facts but also about suppressing unwanted interference in non-targeted contexts. A relevance router determines whether to apply an edit memory, with routed prompts using an edit adapter and unrouted prompts using a locality adapter.
The method demonstrates superior performance across multiple benchmarks (CF, ZSRE, MQuAKE) on both Llama-3.1-8B-Instruct and Qwen3-8B models, achieving state-of-the-art accuracy in probability-preference tasks. This suggests that the separation of edit injection from off-route suppression is more effective than simply increasing adapter capacity.
This work contributes significantly to multi-agent systems and memory & tool use by providing a principled approach to managing knowledge updates in dynamic environments. It shows how adaptive routing can improve the precision of information retrieval and modification, which is essential for agents that must maintain accurate, up-to-date knowledge while avoiding contamination from irrelevant data.
Key insight: Effective knowledge editing requires not just writing new information but also suppressing irrelevant edits, achieved through route-specialized dual adapters.
Graph Structured Combinatorial Semi-Bandit with Nonlinear Reward Associations through Separable Signals
Maghsudi, Setareh arXiv: 2606.14650
This paper presents a novel framework for addressing graph-structured combinatorial semi-bandits where rewards depend on nonlinear associations through separable signals. The approach combines causal reward modeling, reproducing kernel methods, and Taylor approximations to achieve sublinear time and linear data volume performance guarantees.
The theoretical contributions are significant, offering robustness to noise interference, gradual convergence, and solution space mismatch—key challenges in real-world applications. The framework's generality is demonstrated through experiments on synthetic and real-world transportation datasets, showing practical effectiveness despite the complexity of nonlinear reward structures.
This work has implications for reasoning & planning and multi-agent systems, particularly in environments where agents must make decisions based on complex interdependencies. The ability to model nonlinear reward associations using separable signals opens new possibilities for designing more sophisticated decision-making algorithms that can handle intricate causal relationships in dynamic environments.
Key insight: Graph-structured combinatorial semi-bandits with nonlinear reward associations can be effectively addressed using separable signal modeling and Taylor approximations.
Learning Coordinated Preference for Multi-Objective Multi-Agent Reinforcement Learning
Chen, Jingdi arXiv: 2606.14693
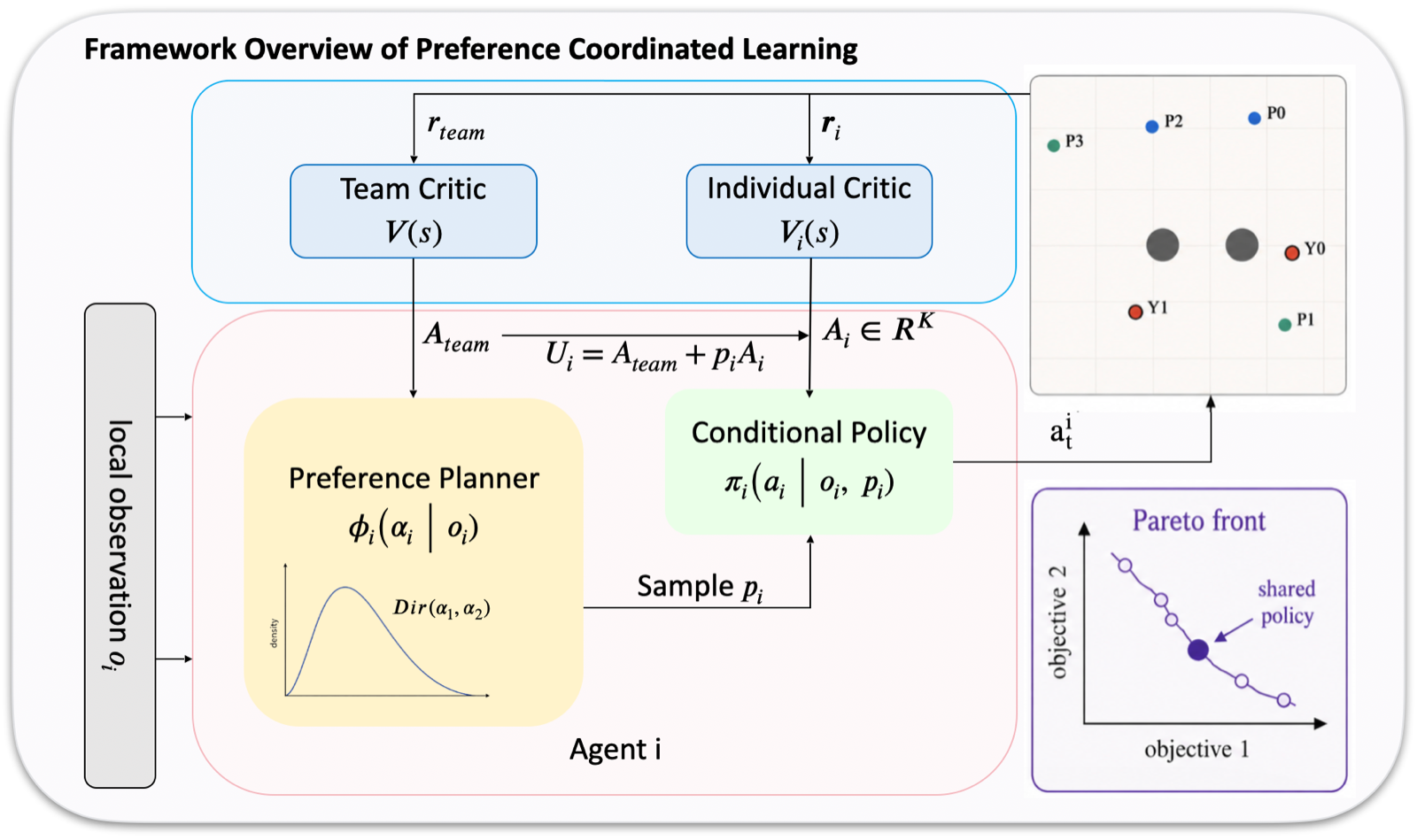
In cooperative multi-objective multi-agent reinforcement learning (MOMARL), agents often face conflicting objectives and different observational contexts. The paper introduces Preference Coordinated Multi-agent Policy Optimization (PCMA), which learns agent-specific preferences to enable better coordination among agents with diverse roles and contributions. This approach allows for more nuanced trade-offs that can lead to improved team performance compared to traditional methods.
The theoretical framework of PCMA formulates MOMARL as a team-optimal game, showing that preference diversity can induce team improvement through a first-order decomposition. This insight suggests that by allowing agents to have distinct but coordinated preferences, the overall system can achieve better outcomes than if all agents pursued identical objectives or simply optimized individually.
Experimental validation across multiple cooperative MOMA environments and a real-world traffic-control scenario demonstrates that PCMA significantly improves both performance and trade-off coordination. These results highlight the importance of considering individual agent preferences in multi-agent systems to achieve more effective collaborative behavior.
Key insight: Multi-agent systems can improve team performance by learning coordinated agent-specific preferences that enable complementary trade-offs, rather than relying on uniform objectives.
Safety-Contract Graph Multi-Agent Reinforcement Learning for Autonomous Network Security Response
Silva, Jose Luis Lima de Jesus arXiv: 2606.13832
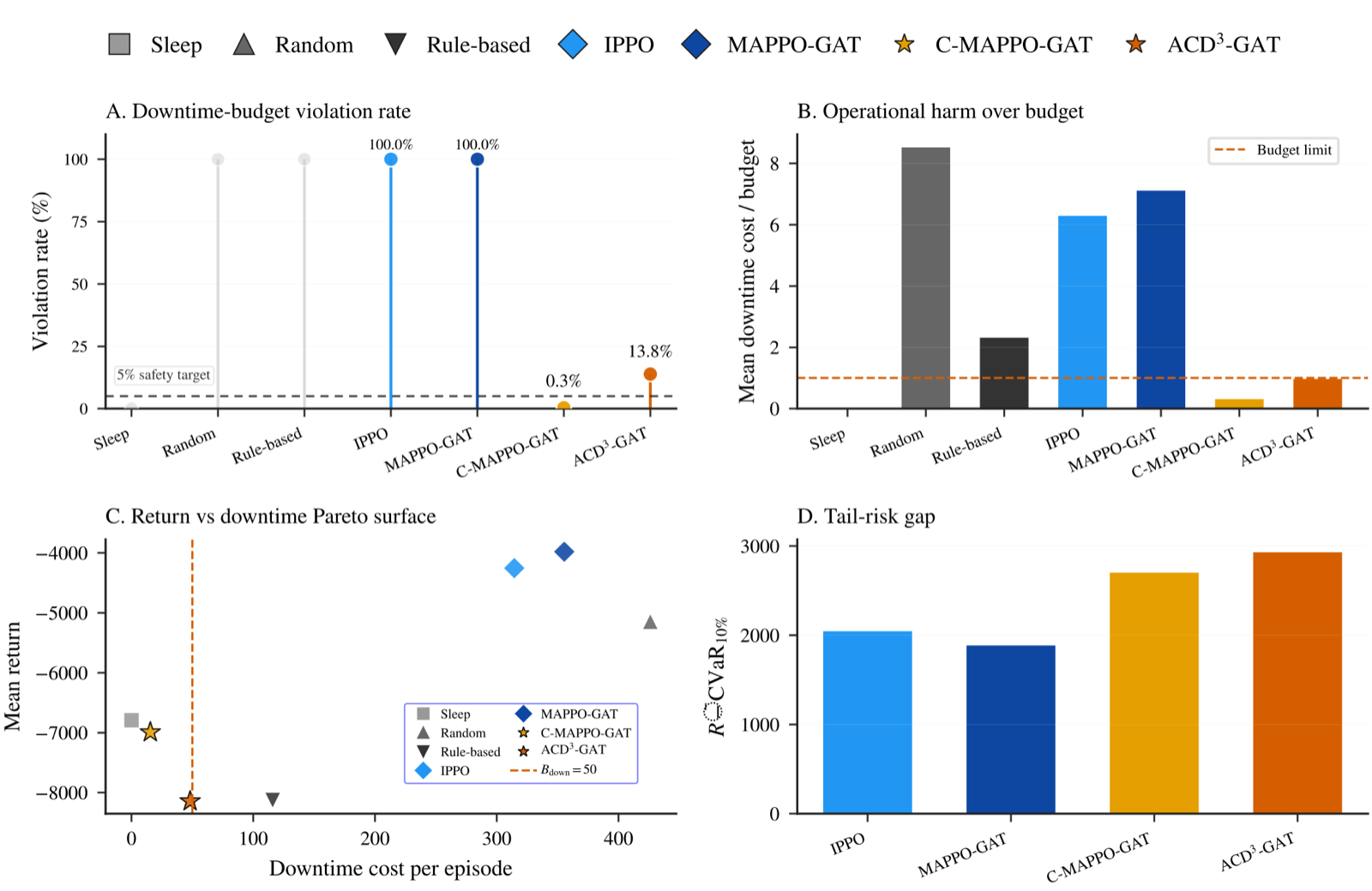
Autonomous network security response systems require both high performance and strict adherence to operational constraints such as Mean Time to Recover (MTTR) and firewall change management. The paper presents ACD³-GAT, a safety-contract graph MARL framework that separates simulator observations from reusable operational budgets and incorporates counterfactual action screening.
Compared to reward-only learning methods like MAPPO-GAT, which often violate operational budgets, ACD³-GAT reduces downtime violations from 100% to just 13.8% while maintaining competitive performance. This demonstrates that incorporating safety contracts into multi-agent reinforcement learning can provide the necessary operational discipline without sacrificing effectiveness.
The framework's use of graph attention networks and CVaR tail-risk estimation allows it to handle complex, real-world constraints more effectively than previous approaches. The results suggest that safety-constrained MARL is a promising direction for deploying autonomous systems in critical domains where compliance with operational budgets is essential.
Key insight: Safety-constrained multi-agent reinforcement learning frameworks can significantly reduce operational violations while maintaining high performance in autonomous network security response systems.
Contract-Based Compositional Shielding for Safe Multi-Agent Reinforcement Learning
Belardinelli, Francesco arXiv: 2606.14130
Safe coordination problems in multi-agent reinforcement learning often arise when global safety cannot be enforced by any single agent. The paper proposes a contract-based approach using Linear Temporal Logic (LTL) specifications to ensure safety while maintaining optimal team behavior through decentralized execution.
Each agent selects from tuples of local LTL obligations whose conjunction implies the global specification, allowing for safe coordination without central control. This method uses a non-stationary multi-armed bandit to optimize team reward while ensuring end-to-end safety, demonstrating that decentralized safety can be achieved without compromising performance.
Evaluation across six environments and fifteen algorithmic variants shows that this approach successfully balances safety and optimality in complex multi-agent scenarios. The results indicate that contract-based shielding is a viable method for enabling safe, coordinated behavior in decentralized multi-agent systems.
Key insight: Contract-based compositional shielding enables decentralized safety enforcement in multi-agent systems without sacrificing team-optimal behavior.
TwinBI: An Agentic Digital Twin for Efficient Augmented Interactions with Business Intelligence Dashboards
Li, Jisoo Jang Wen-Syan arXiv: 2606.13731

Business intelligence dashboards combined with LLM-based assistance often suffer from misalignment between direct manipulation and conversational interaction. TwinBI addresses this by coupling an LLM agent system with an executable BI dashboard state through a shared analytical context.
The framework reconstructs a unified interaction log to maintain consistent analytical state across filters, hierarchies, metrics, and chart context. This enables better coordination between natural language queries and dashboard manipulations, significantly improving accuracy and reducing timeouts compared to traditional dashboard-only approaches.
User studies demonstrate that TwinBI enhances both agent-level reliability and user-facing support by providing richer actionable context derived from visible dashboard state. The system's ability to expose artifacts like schema views, SQL, and insights commands makes it a practical solution for improving business intelligence workflows.
Key insight: An agentic digital twin framework can unify dashboard interaction and natural language queries, improving analytical reliability and user experience in business intelligence systems.
YeasierAgent: Agentic Social Sandbox as a Canvas for Intent-Driven Creation of Platform-Agnostic Symbiotic Agent-Native Applications
He, Jory arXiv: 2606.13722
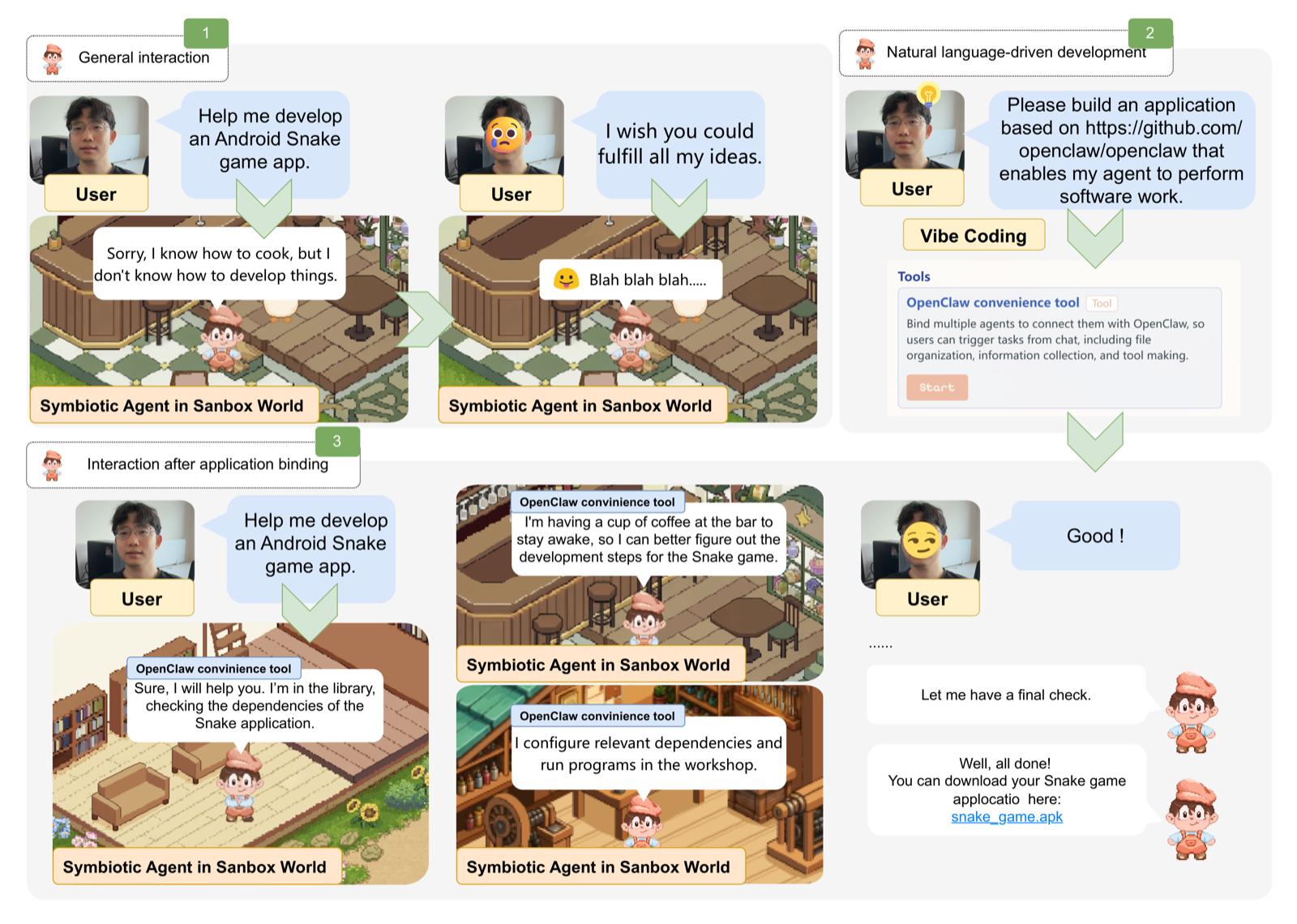
YeasierAgent introduces a paradigm that redefines applications as collaborative spaces among users, agents, and narrative worlds, moving beyond traditional device-coupled models. This approach enables rapid, cross-platform construction of agent-native applications using platform-agnostic interactive units rather than fixed layouts.
The system integrates automated generation, user-created worlds, and spatial multi-agent collaboration to formalize Symbiotic Agent-Native Applications. This represents a significant shift from isolated, tool-specific chatbots toward more immersive, socially embedded computational environments that can provide both emotional companionship and practical execution.
By unifying the attributes of intelligent agents within a single experiential sandbox, YeasierAgent demonstrates how agent-native applications can become more engaging and useful for users. The framework's emphasis on narrative worlds and scene-aware interaction suggests new possibilities for designing applications that feel more natural and intuitive.
Key insight: Symbiotic agent-native applications can shift from isolated chatbots to cohesive, socially embedded computational environments by integrating automated generation and spatial multi-agent collaboration.
AI Tooling
Introducing the OpenAI Partner Network
OpenAI has announced the launch of the OpenAI Partner Network, a new program designed to help enterprises adopt frontier AI models and turn them into measurable impact. The network aims to address the gap between AI model capabilities and enterprise implementation by connecting organizations with trusted partners who have deep industry expertise and global delivery capacity. OpenAI is investing $150 million in this ecosystem and has launched with a select group of global partners including Accenture, Bain, BCG, Eliza, McKinsey, and PwC. The program includes three tiers (Select, Advanced, Elite) and will train 300,000 certified consultants by end of 2026.
Why it matters: This represents a significant shift in how AI adoption is being approached at the enterprise level, emphasizing ecosystem partnerships over direct model deployment. It signals OpenAI's recognition that successful AI implementation requires more than just advanced models - it needs strategic consulting, system integration, and change management expertise that partners can provide.

As AI companies race to go public, who else is along for the ride? | TechCrunch
As SpaceX goes public in the largest IPO ever, AI companies are following suit with OpenAI and Anthropic both confidentially filing for IPOs. The article discusses how this 'SpaceX IPO wave' is creating a ripple effect throughout the market, shifting capital flows from traditional tech giants like FAANG to newer AI-focused companies including Meta, Anthropic, NVIDIA, Google, OpenAI, and SpaceX. This trend represents a fundamental shift in public market investment patterns, with massive capital available for AI labs and deep tech ventures rather than consumer social networks.
Why it matters: This marks a pivotal moment in the evolution of tech investment markets, where the focus has shifted from traditional social media and consumer platforms to AI-driven innovation. The emergence of AI-focused IPOs signals that investors are recognizing AI as a transformative force that will reshape entire industries, not just digital platforms.