NVIDIA demonstrates superior performance in agentic AI coding using a new benchmark, while Meta reportedly moves to unwind a $2 billion deal with Manus following Beijing's demands. Meanwhile, two significant research papers advance our understanding of latent reasoning and mathematical proof generation.
NVIDIA has achieved leading performance in agentic AI coding tasks through the first open, multi-vendor benchmark called AA-AgentPerf, showcasing a 20x improvement in concurrent agent throughput per megawatt on its GB300 NVL72 platform. This advancement highlights the importance of hardware-software co-design for handling complex agentic workloads. Concurrently, Meta is reportedly seeking to unwind its $2 billion acquisition of Manus following pressure from Chinese authorities, underscoring geopolitical tensions in the AI sector. In research news, two papers present major breakthroughs: one introduces SWITCH, a framework that enables interpretable latent reasoning through on-policy reinforcement learning, and another presents MaxProof, which scales mathematical proof generation using generative-verifier reinforcement learning and population-level test-time scaling to exceed human gold medal thresholds.
Research Papers
Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning
Guo, Zhijiang arXiv: 2606.13106

The paper introduces SWITCH, a novel framework for latent reasoning that addresses long-standing issues in hidden-state recurrence models. By using discrete boundary tokens to define entry and exit points into latent reasoning states, the model becomes compatible with standard on-policy reinforcement learning (RL), which was previously difficult to achieve. This innovation not only improves training stability but also enables mechanistic analysis of how latent computation functions within the model.
The key contribution lies in the ability to perform direct probing and causal intervention through these boundary tokens. The authors demonstrate that
This work has implications beyond just reasoning models—particularly for multi-agent systems where agents may need to reason about each other's hidden states or plan in complex environments. The ability to train and interpret latent reasoning steps opens new pathways for designing more robust, explainable AI agents that can engage in sophisticated problem-solving while maintaining transparency.
Key insight: Introducing explicit boundary tokens (
MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
Cheng, Yu arXiv: 2606.13473
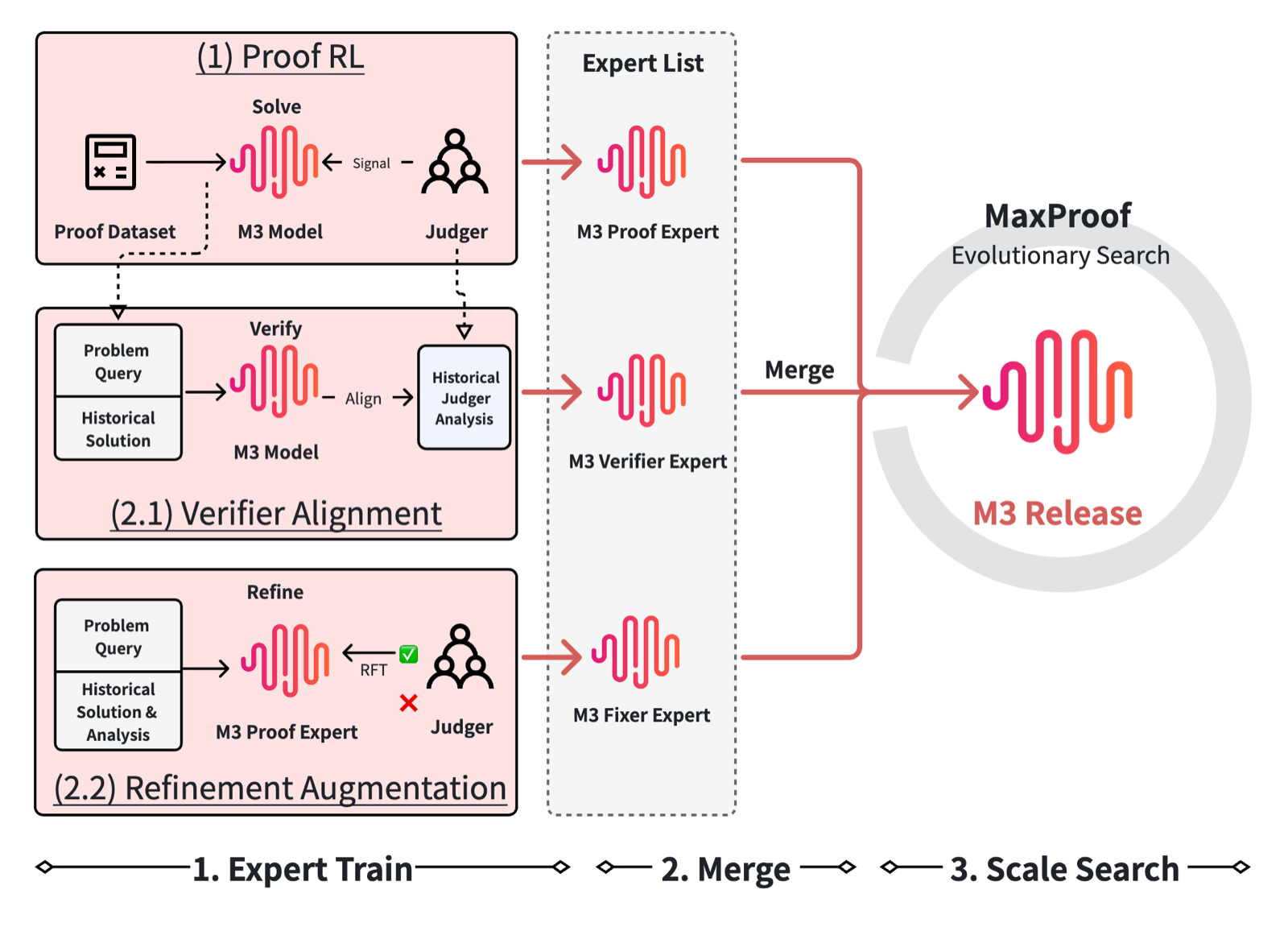
MaxProof represents a major advancement in the application of reinforcement learning to mathematical reasoning. By integrating proof generation, verification, and critique-conditioned repair into a single framework, it demonstrates how modular components can be effectively combined to produce high-quality outputs at scale. The use of tournament selection among candidate proofs during test time is particularly innovative, enabling a form of collective intelligence that improves final results.
The system's performance—scoring 35/42 on IMO 2025 and 36/42 on USAMO 2026—shows that generative models trained with strong verification feedback can approach or surpass human-level performance in competitive mathematics. This is especially notable given the complexity and precision required in formal proofs, which are often difficult for current LLMs to handle reliably.
This work contributes significantly to reasoning & planning and RAG areas by showing how reinforcement learning can be used to enhance the quality of generated content through iterative refinement and evaluation. It also highlights the potential for test-time scaling techniques to improve performance without retraining, which is crucial for deploying AI systems in real-world settings where adaptability and accuracy are paramount.
Key insight: A population-level test-time scaling approach combining generative and verifying capabilities allows for significant improvements in mathematical proof generation, achieving performance exceeding human gold medal thresholds.
AI Model Releases
NVIDIA has demonstrated superior performance in agentic AI coding tasks using the first open, multi-vendor benchmark called AA-AgentPerf. The benchmark measures concurrent AI agent support under real-world coding trajectories, accounting for non-deterministic sequences and tool call latencies. NVIDIA's GB300 NVL72 platform achieved up to 20x higher concurrent agent throughput per megawatt compared to the H200, leveraging optimizations like WideEP/DeepEP and fused MoE. The upcoming Vera Rubin platform is projected to further boost performance with 50 PFLOPs of NVFP4 compute. This represents a significant advancement in measuring and optimizing inference systems for complex agentic workloads.
Why it matters: This benchmarking approach provides the industry's first standardized method for evaluating how well inference systems handle concurrent AI agents, which is crucial as agentic AI becomes more prevalent. NVIDIA's performance gains demonstrate the importance of hardware-software co-design for handling these increasingly complex workloads at scale.

Meta reportedly moves to unwind $2B Manus deal after Beijing’s demand
Source: TechCrunch.