Researchers are advancing tools for iterative model development with AllenAI's olmo-eval workbench, while Google DeepMind launches a multi-agent safety funding initiative. Meanwhile, regulatory tensions emerge as the U.S. government shuts down Anthropic's most powerful AI models. OpenAI responds with new enterprise AI education courses.
This week's AI research digest highlights significant developments in model evaluation tooling and agent frameworks. AllenAI introduces olmo-eval, an evaluation workbench designed to streamline the iterative model development loop by supporting agentic and multi-turn evaluations with stronger analysis capabilities. Google DeepMind partners with leading institutions to fund multi-agent safety research, addressing the growing complexity of AI systems that coordinate with each other. The regulatory landscape shifts as the U.S. government orders Anthropic to shut down its most powerful Claude models, citing national security concerns, while OpenAI launches new Academy courses focused on practical AI adoption in enterprise settings. Additional research explores novel approaches to agent architectures, including learnable bidirectional controllers, hybrid interface benchmarks for computer-use agents, and spatial reasoning with code-based action interfaces.
Research Papers
HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
Wang, Wei arXiv: 2606.12882

HarnessBridge represents a significant advancement in agent architecture by introducing a learnable plug-in module that mediates agent-environment interaction. Unlike traditional manually-engineered harnesses, HarnessBridge's bidirectional projection mechanism allows for dynamic adaptation to complex trajectories, making it scalable for long-horizon tasks.
The system learns two key projections: observation projection, which distills raw trajectories into compact decision-relevant states, and action projection, which converts proposed actions into executable transitions or trajectory-grounded rejections. This dual approach enables more efficient processing while maintaining performance across diverse benchmarks like Terminal-Bench 2.0 and SWE-bench Verified.
Notably, HarnessBridge achieves substantial improvements in token efficiency and trajectory length without sacrificing accuracy, demonstrating that end-to-end trainable components can outperform specialized, manually designed systems. Its ability to generalize from smaller to larger models also suggests broad applicability across different LLM scales.
Key insight: HarnessBridge introduces a learnable, bidirectional controller that significantly reduces token usage and trajectory length while matching or surpassing specialized harnesses in long-horizon tasks.
WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Shan, Caihua arXiv: 2606.09426
WeaveBench addresses a major limitation in existing computer-use agent benchmarks by focusing on hybrid interfaces and long-horizon task execution. Unlike previous work that evaluates interfaces separately, this benchmark requires agents to seamlessly integrate GUI observations/actions with CLI/code operations within single trajectories.
The evaluation methodology is particularly robust, using real Ubuntu desktop environments augmented with minimal desktop-control plugins and a trajectory-aware judge that inspects deliverables, screenshots, logs, and action traces. This approach detects shortcut behaviors like fabricated visual evidence or hard-coded metrics, providing a more accurate assessment of agent capabilities.
The benchmark's findings are sobering: even top-tier model-runtime pairings achieve only 41.2% pass rate, indicating that current agents are far from mastering complex, multi-modal workflows. This reveals a critical gap in CUA development and provides an effective testbed for measuring true orchestration capability across diverse real-world domains.
Key insight: WeaveBench exposes critical gaps in current CUA evaluation by requiring agents to orchestrate multiple interface types (GUI, CLI, code) across long-horizon tasks, revealing that even frontier models struggle with cross-interface coordination.
SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Chen, Min-Hung arXiv: 2606.13673

SpatialClaw tackles a fundamental challenge in vision-language models by rethinking the action interface for spatial reasoning. Rather than relying on single-pass code execution or structured tool-call interfaces, it employs a training-free framework that maintains a stateful Python kernel pre-loaded with perception and geometry primitives.
This approach allows agents to write one executable cell per step conditioned on all prior outputs, enabling dynamic composition of operations and adaptation to intermediate results. The framework's flexibility is evident in its performance gains across 20 spatial reasoning benchmarks, achieving 59.9% average accuracy—11.2 points higher than recent spatial agents.
The method's effectiveness spans multiple VLM backbones without any benchmark- or model-specific adaptations, suggesting broad applicability. By leveraging code as the interface, SpatialClaw opens new possibilities for open-ended, complex 3D/4D reasoning in agentic systems.
Key insight: SpatialClaw demonstrates that using code as an action interface enables flexible, stateful spatial reasoning by allowing agents to compose and manipulate perception results dynamically across complex 3D/4D tasks.
FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
Wen, Ji-Rong arXiv: 2606.12087

FORT addresses a critical issue in deep search agent training: the prevalence of shortcut behaviors that bypass genuine search processes. The framework formalizes shortcut risks through four actionable categories—evidence co-coverage, single-clue selectivity, exposed constants, and prior-knowledge binding—and uses trajectory signatures to diagnose their realized effects.
By controlling these shortcut risks during data synthesis, FORT generates training data that encourages longer, more thorough search processes. This approach results in agents like FORT-Searcher that achieve superior performance on challenging benchmarks compared to existing open-source models trained with standard methods.
The significance of FORT extends beyond immediate performance gains; it provides a principled methodology for creating robust training datasets that better reflect the complexity of real-world search tasks, thereby advancing the field of deep search agent development.
Key insight: FORT introduces a shortcut-aware difficulty framework that synthesizes training data resistant to identifying shortcuts, leading to more robust deep search agents with longer pre-answer search patterns.
Automated reproducibility assessments in the social and behavioral sciences using large language models
Feuerriegel, Stefan arXiv: 2606.13670
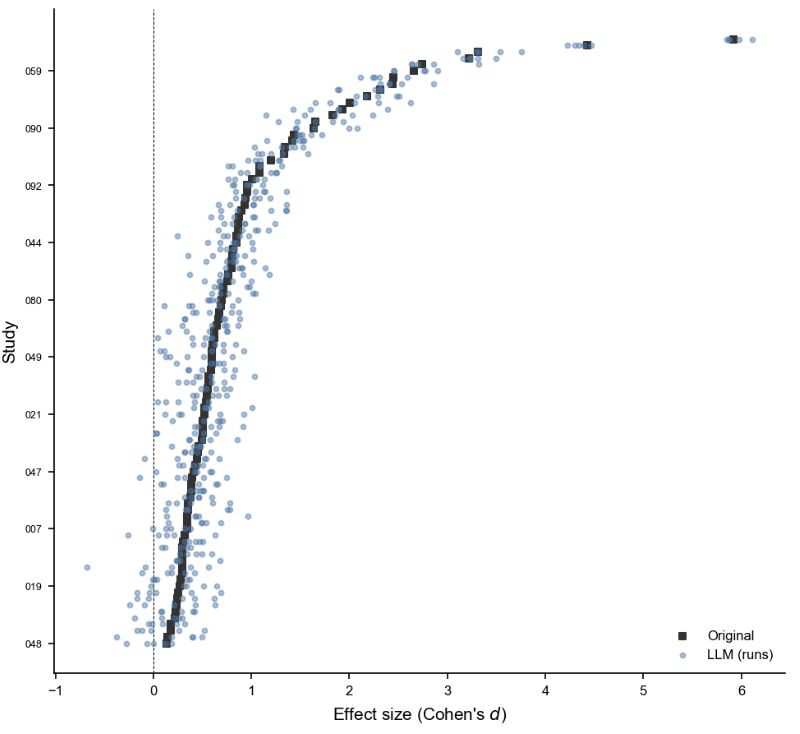
This paper explores the application of LLMs to automated reproducibility assessment in social and behavioral sciences—a domain where traditional methods are resource-intensive and difficult to scale. The study demonstrates that LLM-generated analysis can recover original effect sizes in 41% of cases with a +/-0.05 tolerance in Cohen's d, surpassing human reanalysts who achieved only 34% recovery.
More impressively, the LLM pipeline reached the same qualitative conclusion as the original study in 96% of cases, compared to 74% for human reanalysts. These results suggest that LLMs can serve as a scalable tool for systematic auditing of empirical results, potentially revolutionizing how reproducibility is evaluated across large bodies of research.
The implications extend beyond immediate utility; this work lays the foundation for automated quality control in scientific research, offering a framework that could be adapted to other domains requiring rigorous validation and replication.
Key insight: Large language models can automate reproducibility assessments in social and behavioral sciences, achieving comparable or better results than human reanalysts for qualitative conclusions while being more scalable.
Before You Think: System 0, AI-Mediated Cognition and Cognitive Colonization
Riva, Giuseppe arXiv: 2606.13658

This paper introduces a philosophical framework examining the cognitive and epistemic consequences of AI through the lens of System 0—a concept distinct from Tri-System Theory and Thinkframes. It argues that AI systems can subtly influence human reasoning by embedding external interests within the architecture of cognition itself.
The notion of 'cognitive colonization' is particularly concerning, as it suggests that AI-mediated cognition may not merely assist but fundamentally alter how humans think and reason. This has profound implications for autonomy, decision-making, and epistemic responsibility in an increasingly AI-integrated world.
While the paper focuses on theoretical dimensions, its insights are crucial for developing ethical guidelines and design principles for AI systems that interact with human cognition, emphasizing the need for transparency and awareness of these invisible influences.
Key insight: The concept of System 0 highlights how AI systems can embed external interests within the architecture of human cognition, creating invisible forms of influence that are difficult for users to perceive.
Beyond Runtime Enforcement: Shield Synthesis as Defensibility Analysis for Adversarial Networks
Almuhammadi, Sultan arXiv: 2606.13621
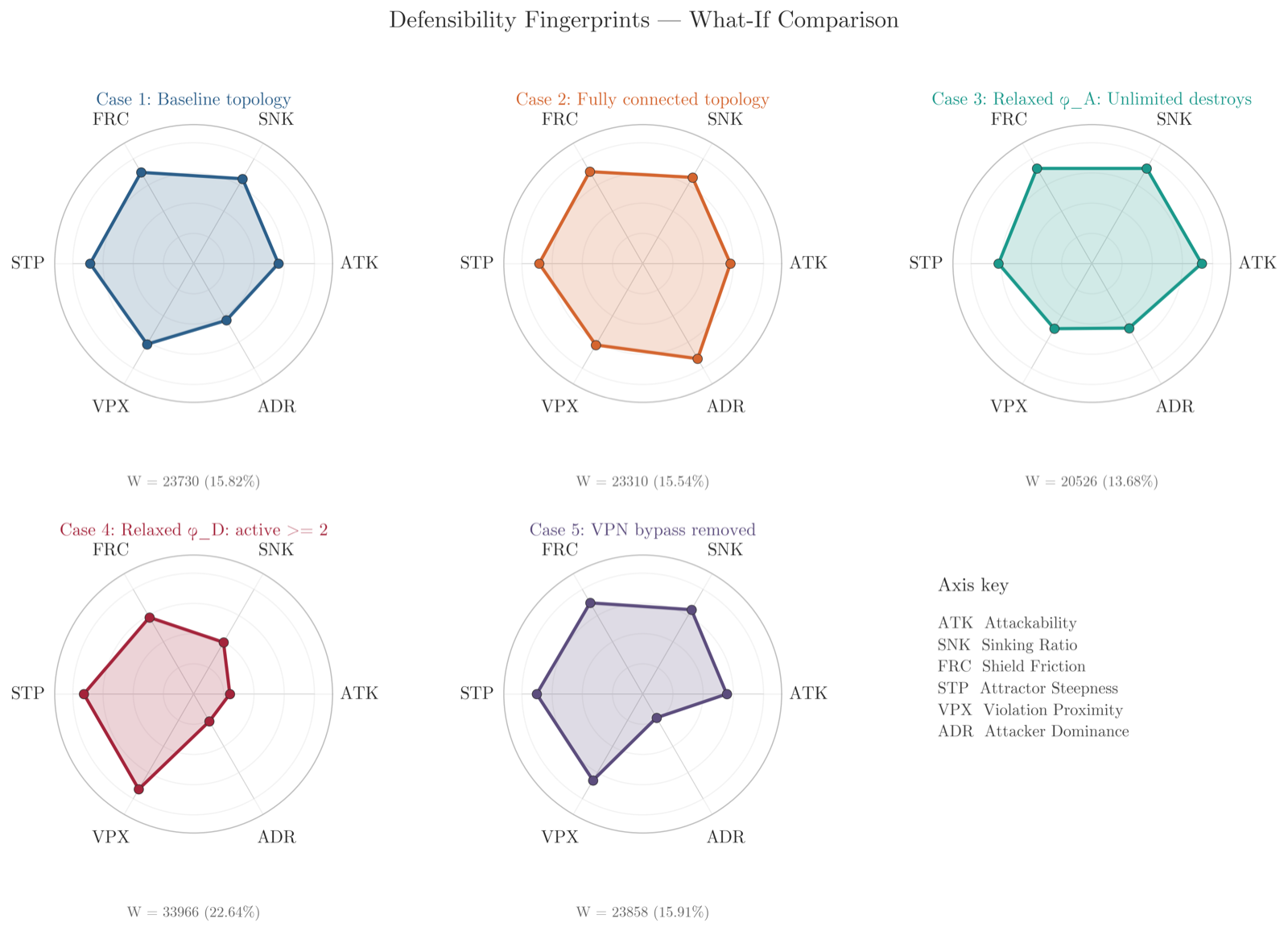
The paper challenges conventional views of shielded reinforcement learning by reframing it as a design-time analytical tool rather than a runtime safety mechanism. This shift allows for deeper understanding of system vulnerabilities through formal verification and structural analysis.
By treating specification compilation, product game construction, attractor computation, and winning-region extraction as analytical instruments, the framework yields defensibility verdicts—certificates indicating whether a topology-specification pair is or isn't defensible—along with associated metrics and behavioral insights.
This approach offers valuable advantages over traditional runtime enforcement: it provides actionable architectural insights, enables what-if analyses, and captures both formal safety properties and operational behavior under adaptive play. The framework's ability to distinguish between formal defensibility and operational effectiveness is particularly insightful for security architecture design.
Key insight: Shield synthesis shifts the focus from runtime enforcement to design-time analytical instruments, providing structural insights about system defensibility rather than just safe policies.
Influcoder: Distilling Decoders' Gradient Influence Rankings into an Encoder for Data Attribution
Denis, Pascal arXiv: 2606.13668
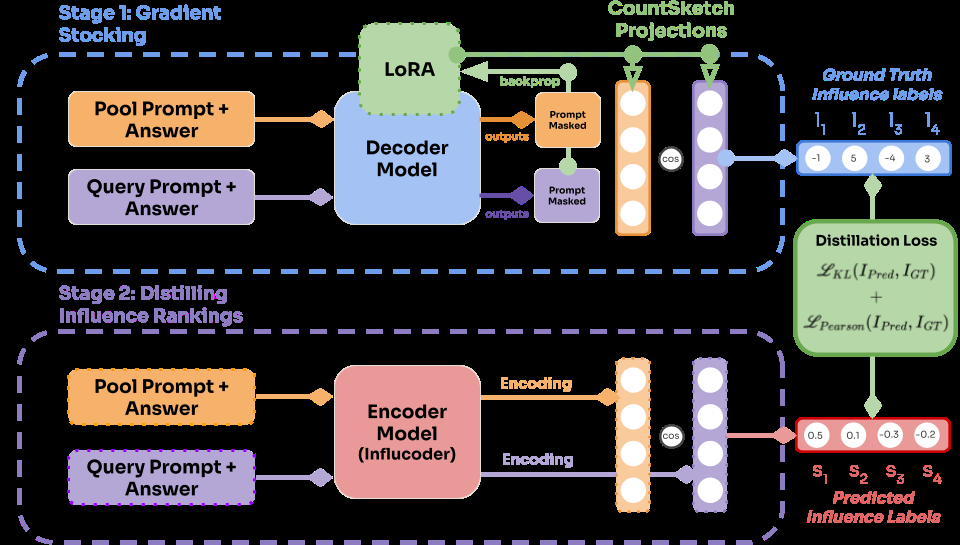
Influcoder addresses a critical scalability issue in data attribution for large language models by proposing a method that distills influence rankings from decoder-based influence functions into encoder representations. This approach dramatically reduces computational requirements while maintaining effectiveness.
Traditional influence function methods are computationally expensive and storage-intensive, making them impractical for large datasets. Influcoder's encoder-based solution offers a quick and cost-effective alternative, enabling practical implementation of influence-based data attribution at scale.
The method's potential applications include dataset curation, identifying problematic training samples, and understanding model conditioning through data attribution. By making influence analysis more accessible, Influcoder supports better data management practices in LLM development.
Key insight: Influcoder enables scalable data attribution by distilling gradient influence rankings from decoders into encoders, overcoming computational bottlenecks of traditional influence functions.
SkMTEB: Slovak Massive Text Embedding Benchmark and Model Adaptation
Ondrejová, Viktória arXiv: 2606.13647

SkMTEB fills a significant gap in multilingual text embedding benchmarks by introducing a comprehensive evaluation suite for Slovak, a low-resource West Slavic language. The benchmark includes 31 datasets across 7 task types, offering nearly four times the depth of existing multilingual coverage for Slovak.
The study reveals that large instruction-tuned multilingual models outperform existing Slovak-specific models trained for NLU tasks, highlighting the importance of cross-lingual transfer in embedding performance. This finding has implications for developing robust, general-purpose embedding models for under-resourced languages.
To address deployment needs, the authors developed e5-sk-small and e5-sk-large models that achieve competitive performance with proprietary APIs while remaining locally deployable. These models offer a replicable path for other under-resourced languages to develop efficient, high-quality embeddings for semantic search and retrieval-augmented generation (RAG).
Key insight: SkMTEB provides the first comprehensive text embedding benchmark for Slovak, enabling better model adaptation and local deployment of embeddings for under-resourced languages.
Understanding Truncated Positional Encodings for Graph Neural Networks
Nayyeri, Amir arXiv: 2606.13671
This work initiates a theoretical study of truncated positional encodings in graph neural networks, revealing that truncation significantly alters the expressive power of popular PE families like spectral and walk-based encodings. While these families are theoretically equivalent in their complete forms, truncation leads to fundamental differences in expressivity.
The findings show that truncated spectral PEs are no longer stronger than the 1-WL test, challenging assumptions about their relative capabilities. The study also highlights how even closely related truncated PEs can exhibit different expressive powers, emphasizing the importance of careful PE selection and truncation strategies.
Experimentally, the research demonstrates that a mix of truncated PEs performs better than any single family on real-world datasets, suggesting practical guidelines for designing effective GNN architectures. These insights contribute to a deeper understanding of how positional encodings influence graph representation learning.
Key insight: Truncated positional encodings in GNNs fundamentally differ in expressive power from their complete counterparts, with implications for graph representation learning and model design.
The Stable Recovery Manifold: Geometric Principles Governing Recoverability in Continual Learning
Melwani, Bhavika arXiv: 2606.13637
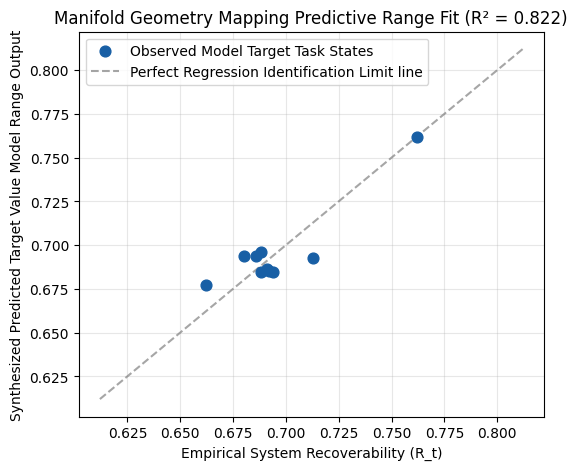
This paper challenges the common view of catastrophic forgetting as information destruction by introducing the Stable Recovery Manifold hypothesis. Using Split CIFAR-100 and ResNet-18, it demonstrates that despite substantial representational drift, recovery dimensionality remains stable throughout training, indicating that forgotten knowledge is still accessible.
The research introduces Recovery Subspace Dimensionality (k_t) as a measure of the minimum number of singular directions needed to preserve 90% of full probe performance. Principal-angle drift strongly predicts recoverability, suggesting that accessibility and manifold alignment are key factors in continual learning.
These findings support a geometric understanding of catastrophic forgetting, where the problem lies not in information loss but in access difficulties. The results imply that strategies focused on maintaining accessibility rather than preventing forgetting may be more effective for preserving learned knowledge in sequential learning scenarios.
Key insight: The Stable Recovery Manifold hypothesis suggests that forgotten knowledge remains compactly decodable despite representational reorganization, framing catastrophic forgetting as an accessibility rather than information destruction problem.
Simplex-Constrained Sparse Bagging: Transitioning from Uniform Priors to Sparse Posteriors in Ensemble Learning
Bhaskar, Meher arXiv: 2606.13589

Simplex-Constrained Sparse Bagging (SCSB) presents a novel approach to post-training compression and probability calibration in ensemble learning. By formulating ensemble pruning and calibration as a joint optimization problem over the probability simplex, SCSB moves beyond traditional uniform voting priors that ignore local estimator competence. This method is particularly relevant for AI agent development, where ensemble methods are often used to improve robustness and accuracy.
The core innovation lies in addressing the L1-simplex paradox — a mathematical challenge where the L1 norm remains constant on the simplex, preventing effective pruning. SCSB circumvents this by introducing a concave quadratic penalty that successfully induces sparsity. This is significant for agent architectures because it allows for more efficient ensemble models without sacrificing performance, which is crucial as agents become more complex and resource-intensive.
SCSB achieves up to 96% compression in ensembles, resulting in linear inference speedups while maintaining or improving generalization accuracy. The framework is model-agnostic, making it broadly applicable across different types of base estimators such as Random Forests, Bagged SVMs, and neural networks. This versatility positions SCSB as a valuable tool for optimizing agent performance in real-world applications where computational efficiency is paramount.
Key insight: SCSB introduces a mathematically rigorous framework for ensemble pruning and calibration that addresses the L1-simplex paradox by using a concave quadratic penalty to induce sparsity, enabling up to 96% compression with improved probability calibration.
Learning with Simulators: No Regret in a Computationally Bounded World
Rakhlin, Alexander arXiv: 2606.13576

This paper introduces a powerful theoretical framework for learning in computationally bounded environments through the concept of simulatable processes. It demonstrates that with access to a simulator that approximates the data-generating distribution, learners can achieve the same error bounds as in classical settings with independent data — specifically those dependent on VC dimension. This is particularly relevant for AI agents operating under computational constraints or in complex, dependent environments.
The framework also explores conditional sampling and shows its statistical and computational advantages. Notably, it presents a single algorithm that learns any given VC class under all processes samplable in bounded polynomial time, with regret controlled by the time-bounded Kolmogorov complexity of the process. This broadens the applicability of learning theory to more realistic settings where data dependencies are common.
The implications for multi-agent systems and agent architectures are profound. If agents can leverage simulators to understand their environment better, they may be able to generalize more effectively even in complex or non-independent domains. This could lead to more robust and adaptive agent designs that perform well under a wide range of conditions.
Key insight: The framework of simulatable processes allows learners to achieve classical PAC learning guarantees even with dependent data, by leveraging access to a simulator that approximates the data-generating distribution.
CRAFTIIF: Cross-Resolution Analytic Four-Type Interpretable Isolation Forest for Multivariate Time Series Anomaly Detection
Smits, William arXiv: 2606.13486
CRAFTIIF addresses a critical challenge in anomaly detection: the need to identify multiple types of anomalies (point, distributional, temporal, and collective) without requiring labeled data or dataset-specific tuning. This is highly relevant for AI agents that must monitor complex systems and respond appropriately to various forms of irregular behavior.
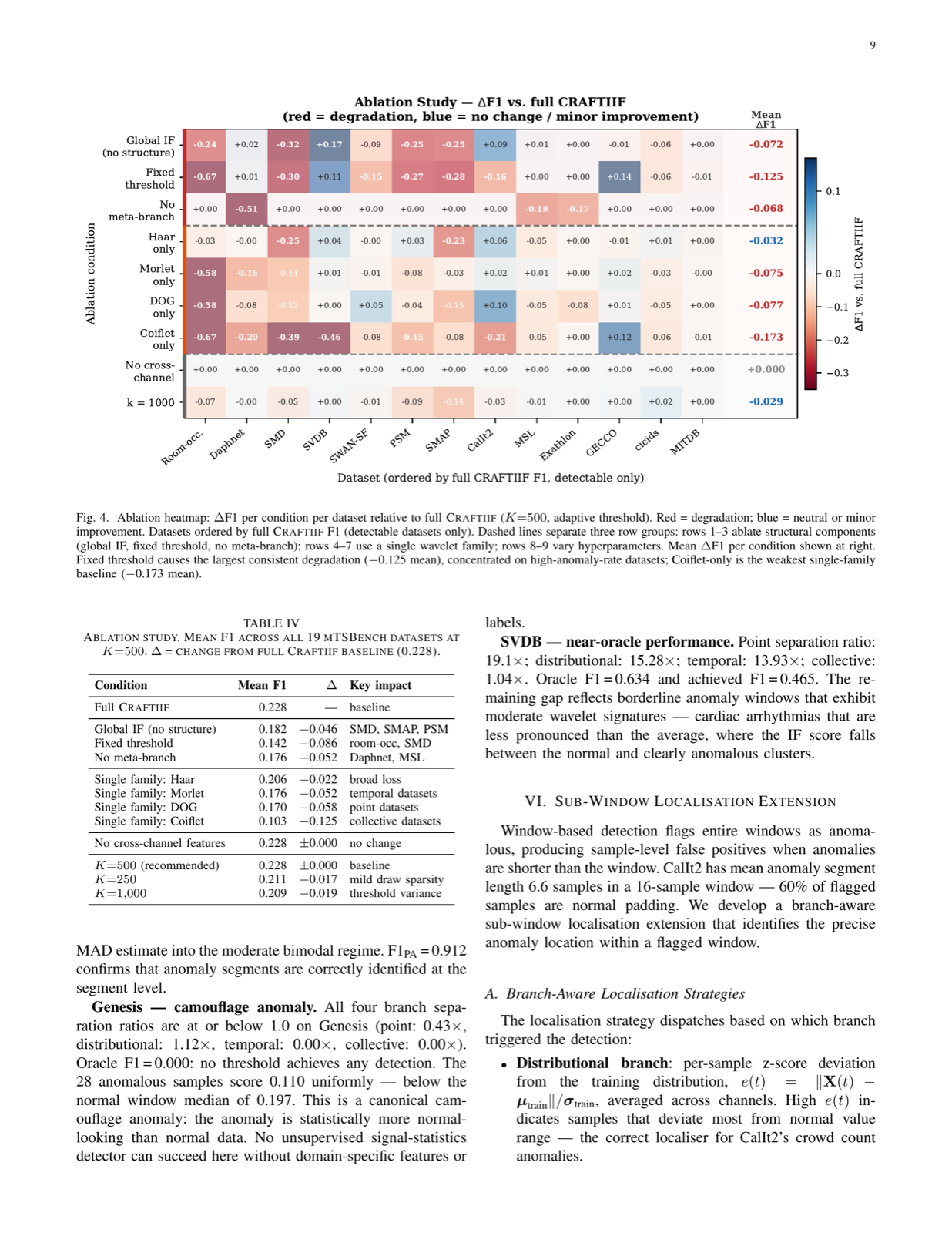
The framework employs K=500 random analytic wavelet feature draws across four families, each targeting a specific anomaly type, feeding five structured Isolation Forests — one per type plus a meta-IF for compound anomalies. This modular design allows for direct attribution of detected anomalies by construction, enhancing interpretability and trustworthiness in agent decision-making processes.
Evaluated on the mTSBench benchmark, CRAFTIIF achieves top performance across multiple metrics, including VUS-PR and F1 scores. The adaptive Otsu/MAD thresholding further enhances its robustness across varying anomaly rates. This makes CRAFTIIF a strong candidate for integration into agent systems that require reliable, interpretable anomaly detection capabilities in real-time environments.
Key insight: CRAFTIIF is a fully unsupervised framework for multivariate time series anomaly detection targeting four distinct types of anomalies using structured Isolation Forests and adaptive thresholding, achieving state-of-the-art performance on benchmark datasets.
Tuning Agent-Based Predator-Prey Models Toward Lotka-Volterra Dynamics
van Gerven, Marcel arXiv: 2606.13639

This work explores the tuning of agent-based models to reproduce classic Lotka-Volterra cycles, offering insights into how agent architectures and controller designs influence emergent system behaviors. It is particularly relevant for multi-agent systems where understanding collective dynamics is crucial for designing effective coordination mechanisms.
By optimizing environmental and demographic parameters with a feature-based loss function that rewards sustained oscillations, phase lag, bounded populations, and long-term persistence, the study shows how agents can be engineered to exhibit desired dynamical properties. This approach could inform the design of agents in complex adaptive systems where stability and predictability are key.
The use of ABMax, a JAX-based framework for agent-based modeling, enables efficient batched simulations on hardware accelerators, which is essential for scaling such models. This highlights the importance of computational efficiency in agent development and suggests that future agent architectures should consider leveraging similar tools for rapid prototyping and optimization.
Key insight: Agent-based models with recurrent neural network controllers can be tuned to exhibit Lotka-Volterra dynamics, demonstrating how agent architectures and parameter optimization can produce classical ecological patterns.
Effects of Social Interactions in Self-Organising Railway Traffic Management
Trianni, Vito arXiv: 2606.13068

This paper investigates how predictive neighborhood horizons affect decentralized coordination in railway traffic management. It challenges conventional wisdom by showing that short time horizons suffice for effective coordination, while long horizons compromise local tractability and responsiveness without improving global optimality.
The findings are highly relevant to multi-agent systems where agents must make decisions based on limited information about their neighbors. In such environments, the trade-off between local decision-making efficiency and global coherence is critical. The study suggests that simpler, more responsive models may be preferable in safety-critical applications like transportation systems.
By using a closed-loop simulation framework, the authors provide empirical evidence supporting their claims, which can guide the design of future agent-based coordination protocols. This has implications for AI agents operating in distributed environments where communication and decision-making latency are key constraints.
Key insight: Short time horizons in self-organizing railway traffic management improve local tractability and computational responsiveness without sacrificing global schedule optimality, challenging the assumption that longer horizons are always better.
Neuro-Symbolic Agents for Regulated Process Automation: Challenges and Research Agenda
Mehdiyev, Nijat arXiv: 2606.13405
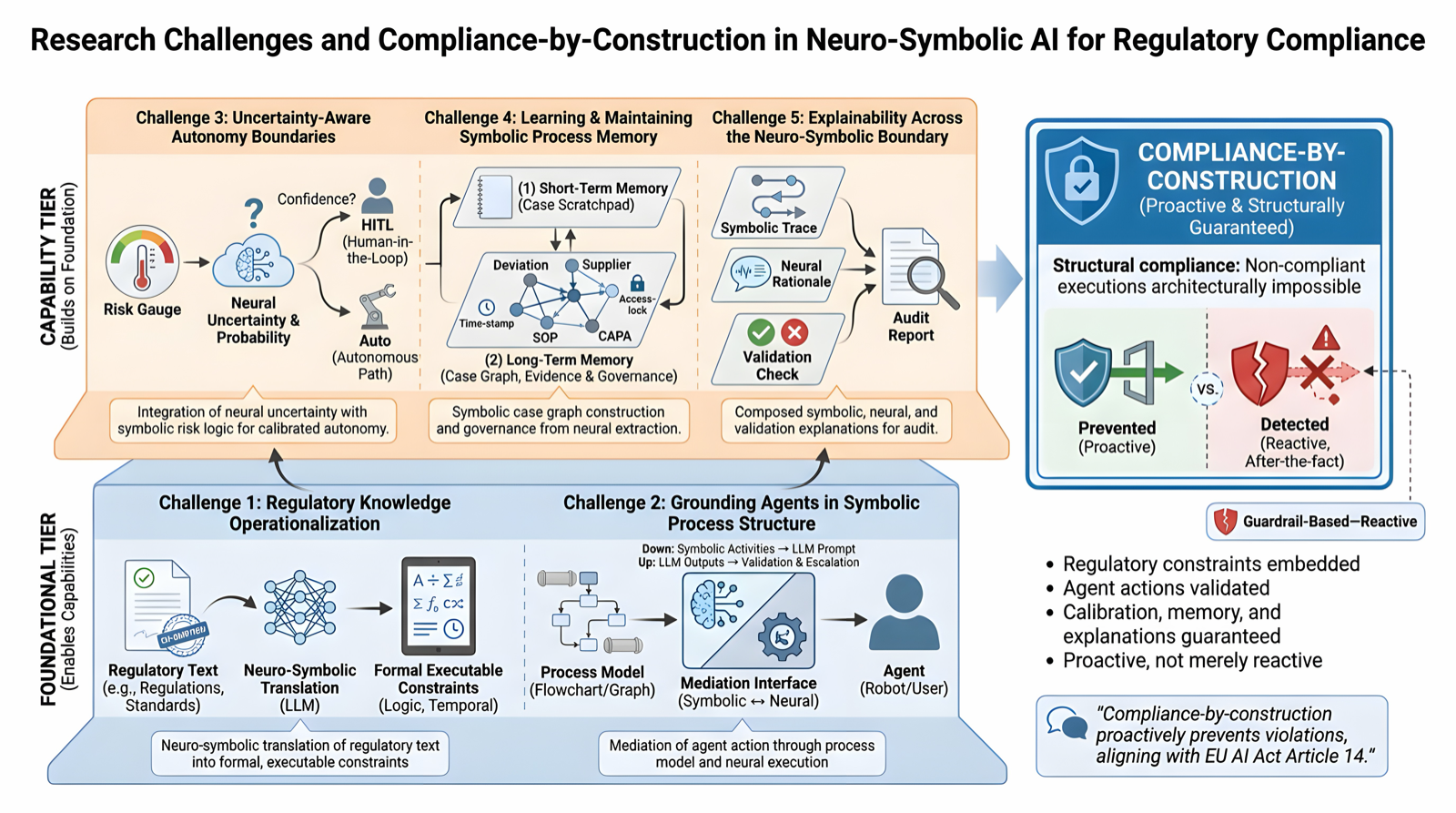
This paper argues for a paradigm shift in how LLM-based agents are designed for regulated industries. Instead of treating symbolic structures like regulations and compliance constraints as mere guardrails, it proposes integrating them into the agent's architecture to enable compliance-by-construction — a foundational approach that prevents control-flow violations at the design level.
The concept of compliance-by-construction is particularly important for AI agents in domains such as healthcare, finance, or aviation, where adherence to rules and regulations is non-negotiable. By embedding these structures into agent behavior, developers can ensure that agents operate within legal and ethical boundaries from the outset.
The paper identifies a set of neuro-symbolic research challenges at both foundational and capability levels, emphasizing the need for joint approaches to achieve true compliance-by-construction. This positions neuro-symbolic methods as a promising direction for building trustworthy AI systems in regulated environments.
Key insight: Neuro-symbolic agents should treat domain-specific symbolic structures (regulations, process models) as core architectural components rather than external monitoring mechanisms, enabling compliance-by-construction.
AI Model Releases
olmo-eval: An evaluation workbench for the model development loop
AllenAI has released olmo-eval, an evaluation workbench designed to streamline the model development loop. The tool builds upon OLMES (Open Language Model Evaluation Standard) and extends it across the entire LLM development process. Unlike existing tools that are either built for running established benchmarks or multi-step agent problems, olmo-eval is specifically designed for the iterative nature of model development where adjustments to data, architecture, or hyperparameters require continuous evaluation. It supports agentic and multi-turn evaluation as a first-class use case and provides stronger analysis tools to distinguish real improvements from noise.
Why it matters: olmo-eval addresses a critical gap in AI development tooling by providing a framework that keeps up with constantly changing models, making it easier for researchers to iterate quickly while maintaining rigorous evaluation standards. This could accelerate the pace of AI research and development.

TCS and Anthropic partner to bring Claude to regulated industries
Anthropic and Tata Consultancy Services (TCS) have formed a strategic partnership to bring Claude AI to regulated industries. TCS will provide Claude to 50,000 of its own employees across 56 countries and develop Claude-powered products for clients in financial services, healthcare, public sector, and other regulated industries. The collaboration includes joining Anthropic's Claude Partner Network, enabling TCS to build industry-specific offerings such as claims processing for insurers and lending advisory for banks. This partnership leverages TCS's compliance expertise and global reach to make Claude accessible to enterprises requiring high accuracy and auditability.
Why it matters: This partnership represents a significant step toward making advanced AI systems like Claude available in highly regulated sectors where trust, accuracy, and compliance are paramount. It demonstrates how AI companies are partnering with established technology firms to navigate regulatory requirements while expanding their market reach.
New OpenAI Academy courses for the next era of work
OpenAI has launched three new Academy courses to help organizations build AI fluency across their workforce: AI Foundations, Applied AI Foundations, and Agents and Workflows. These courses are designed to take learners from understanding basic AI concepts to applying AI in everyday work tasks, developing repeatable workflows, and directing agent-assisted work. The curriculum is shaped by teams across AI research, product, safety, and deployment, incorporating new capabilities and updated safety practices as they evolve.
Why it matters: These courses represent OpenAI's strategic approach to AI adoption, focusing on practical implementation rather than just technical capabilities. They address the growing need for organizations to build AI fluency across their workforce to realize the full value of AI technologies.
Google DeepMind and partners announce multi-agent safety research funding call.
Google DeepMind has announced a multi-agent AI safety research funding call in partnership with leading institutions. The initiative aims to advance safety research for AI systems that can coordinate and interact with each other, addressing the growing complexity of multi-agent AI environments. This move comes as AI systems become increasingly sophisticated and capable of autonomous interaction. DeepMind is seeking proposals from researchers working on safety challenges specific to multi-agent systems, including coordination failures, misalignment issues, and adversarial interactions.
Why it matters: This funding initiative signals a critical shift in AI safety research toward addressing the unique risks posed by multi-agent systems, which are becoming more prevalent as AI capabilities expand. It represents a proactive approach to ensuring safety as AI systems become more complex and autonomous.
AI Tooling

The U.S. government has ordered Anthropic to immediately shut off access to its two most powerful AI models, Claude Fable 5 and Claude Mythos 5, citing national security concerns. The directive requires disabling both models for all users worldwide, not just foreign nationals as initially framed. Anthropic complied but expressed frustration with the decision, arguing that the government's evidence of a 'narrow potential jailbreak' was insufficient to justify recalling a model deployed to hundreds of millions of people. The company maintains its strongest safeguards operate through independent classifier systems separate from the model itself.
Why it matters: This action highlights the growing regulatory tensions around advanced AI development and deployment, particularly when models demonstrate capabilities that could be exploited for cybersecurity purposes. It raises important questions about how governments balance national security concerns with the continued development of AI technologies.