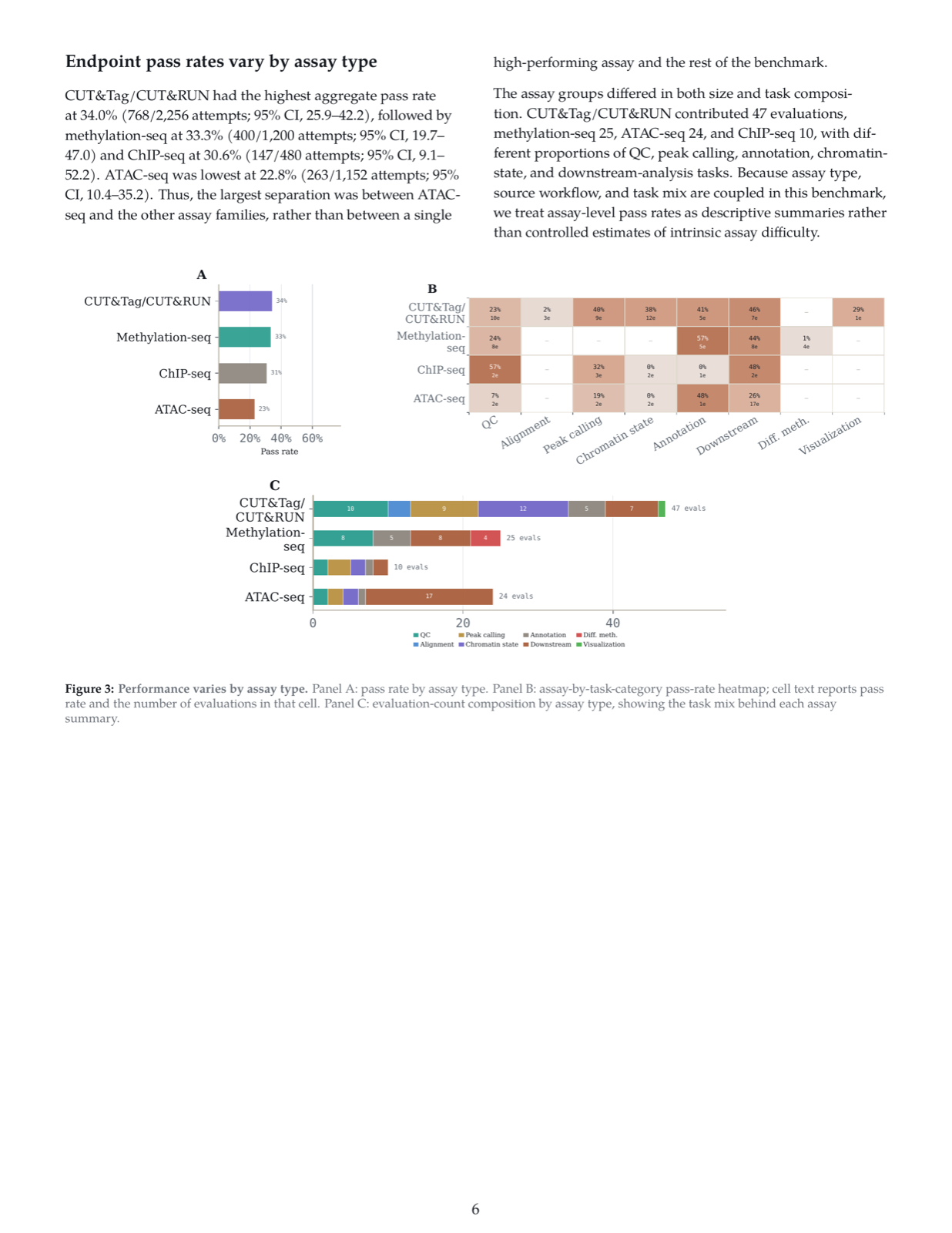
Anthropic launches Claude Corps to democratize AI access for nonprofits, while Google releases DiffusionGemma with 4x faster text generation. Research papers explore agent memory management, multi-agent coordination, and reasoning improvements.
Anthropic has launched Claude Corps, a national fellowship program placing 1,000 early-career professionals in nonprofit organizations to advance AI literacy and community impact. Google's DiffusionGemma model achieves up to 4x faster text generation through optimized architecture. Meanwhile, research papers present significant advances in multi-agent systems including EvoArena for dynamic environment tracking, HyperTool for improved tool usage, and EurekAgent for autonomous scientific discovery. Additional work addresses memory compression, reasoning patterns, and security in agent networks, highlighting the growing sophistication of AI agent architectures and their applications across diverse domains.
Research Papers
EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Hu, Zhiyuan arXiv: 2606.13681
The paper introduces EvoArena, a benchmark suite designed to evaluate LLM agents in dynamic environments where conditions change over time. Unlike traditional benchmarks that assume static settings, EvoArena models environment changes as sequences of progressive updates across terminal, software, and social domains. This is crucial because real-world deployment requires agents to continuously adapt their knowledge and behavior to align with evolving contexts.
To address this challenge, the authors propose EvoMem, a memory paradigm that records memory evolution as structured update histories. This allows agents to reason about environmental changes through modifications in their own memory. Experiments show that current agents perform poorly on EvoArena, achieving only 39.6% average accuracy, but EvoMem consistently improves performance by 1.5% across domains and also enhances standard benchmarks like GAIA and LoCoMo.
Mechanistic analysis reveals that EvoMem improves evidence capture in memory, indicating better preservation of complete evolving environment states. This suggests that the ability to track and reason about changes in one's own knowledge base is essential for robust agent performance in real-world applications where conditions are not fixed.
Key insight: EvoArena demonstrates that current LLM agents struggle in dynamic environments, and EvoMem—a patch-based memory paradigm—significantly improves performance by preserving evolving environmental states.
HyperTool: Beyond Step-Wise Tool Calls for Tool-Augmented Agents
Chen, Siheng arXiv: 2606.13663

The paper identifies a critical problem in current tool-augmented LLM agents: the execution-granularity mismatch. When tools are invoked step-wise, each atomic action becomes visible in the reasoning trace, leading to inefficient context usage and forcing models to manage low-level dataflow manually. This approach is suboptimal for complex workflows that involve deterministic subroutines.
HyperTool addresses this by introducing a new interface where models can invoke a code block containing multiple tool calls, local value manipulation, and intermediate result passing—all within a single outer call. This design folds deterministic tool subroutines into a single unit of execution, reducing context overhead and improving model efficiency.
Evaluation on MCP-Universe shows substantial improvements in accuracy when using HyperTool: from 15.69% to 35.29% for Qwen3-32B and from 9.93% to 33.33% for Qwen3-8B. These results demonstrate that HyperTool not only enhances performance but also outperforms existing systems like GPT-OSS and Kimi-k2.5, indicating its potential as a scalable solution for multi-step tool use.
Key insight: HyperTool introduces a unified executable MCP-style tool interface that reduces execution-granularity mismatch by folding deterministic workflows into single outer calls, significantly improving multi-step tool use.
The Illusion of Multi-Agent Advantage
Joty, Shafiq arXiv: 2606.13003
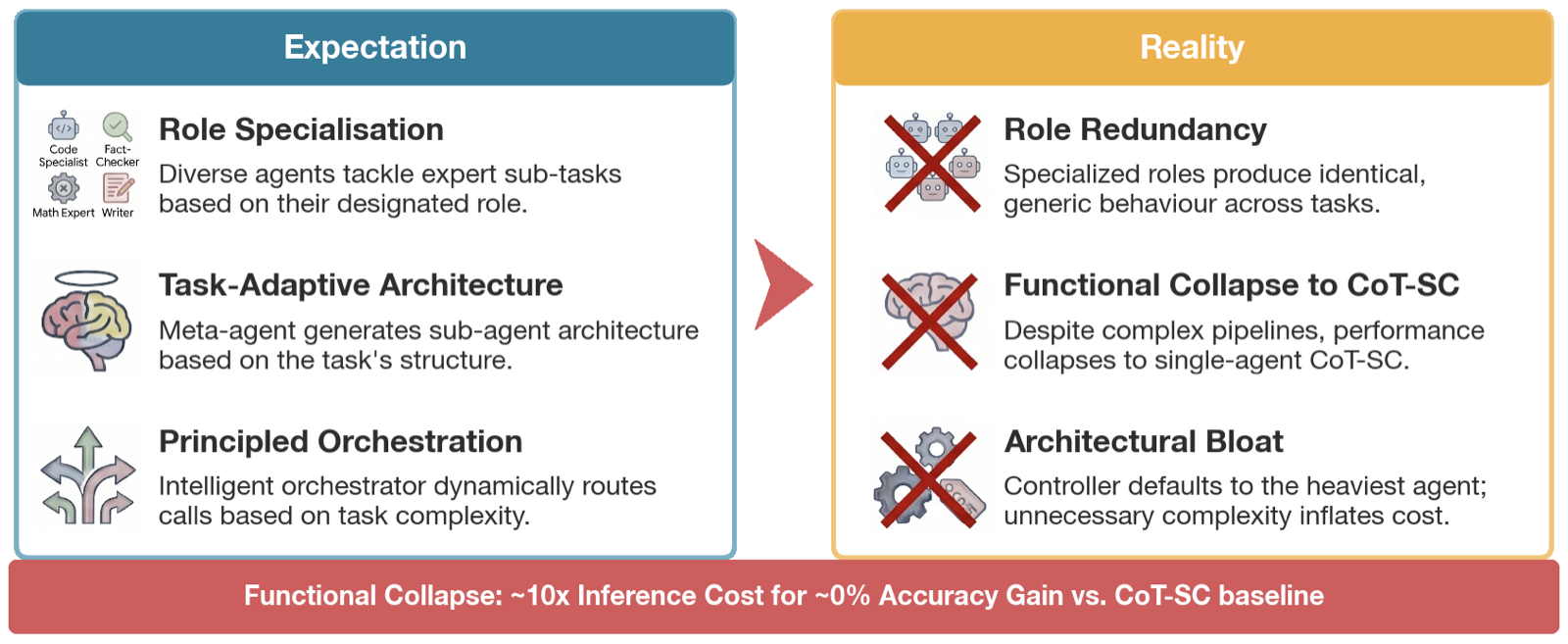
This paper challenges the prevailing belief that Multi-Agent Systems (MAS) are inherently superior to Single-Agent Systems (SAS). While MAS are often praised for advantages like parallel processing and distributed decision-making, empirical evidence shows that automatic MAS consistently underperform even when they are up to 10 times more expensive.
The authors argue that existing evaluation frameworks fail to capture the true utility of MAS by focusing on isolated reasoning tasks rather than interactive multi-step workflows. They introduce a diagnostic synthetic dataset tailored for MAS, which reveals that expert-designed MAS outperform automatically generated ones in both raw performance and cost-efficiency.
A key finding is that current automated design paradigms produce architectural bloat—complexity that does not translate into functional utility. This misalignment with multi-agent principles exposes fundamental gaps in how MAS are evaluated and designed, suggesting a need for more rigorous frameworks that consider the marginal benefit of increased computational resources.
Key insight: Automatic MAS architectures often underperform compared to single-agent systems like CoT-SC, highlighting architectural inefficiencies and the need for better evaluation frameworks that account for marginal utility of increased computational cost.
EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
Li, Juanzi arXiv: 2606.13662
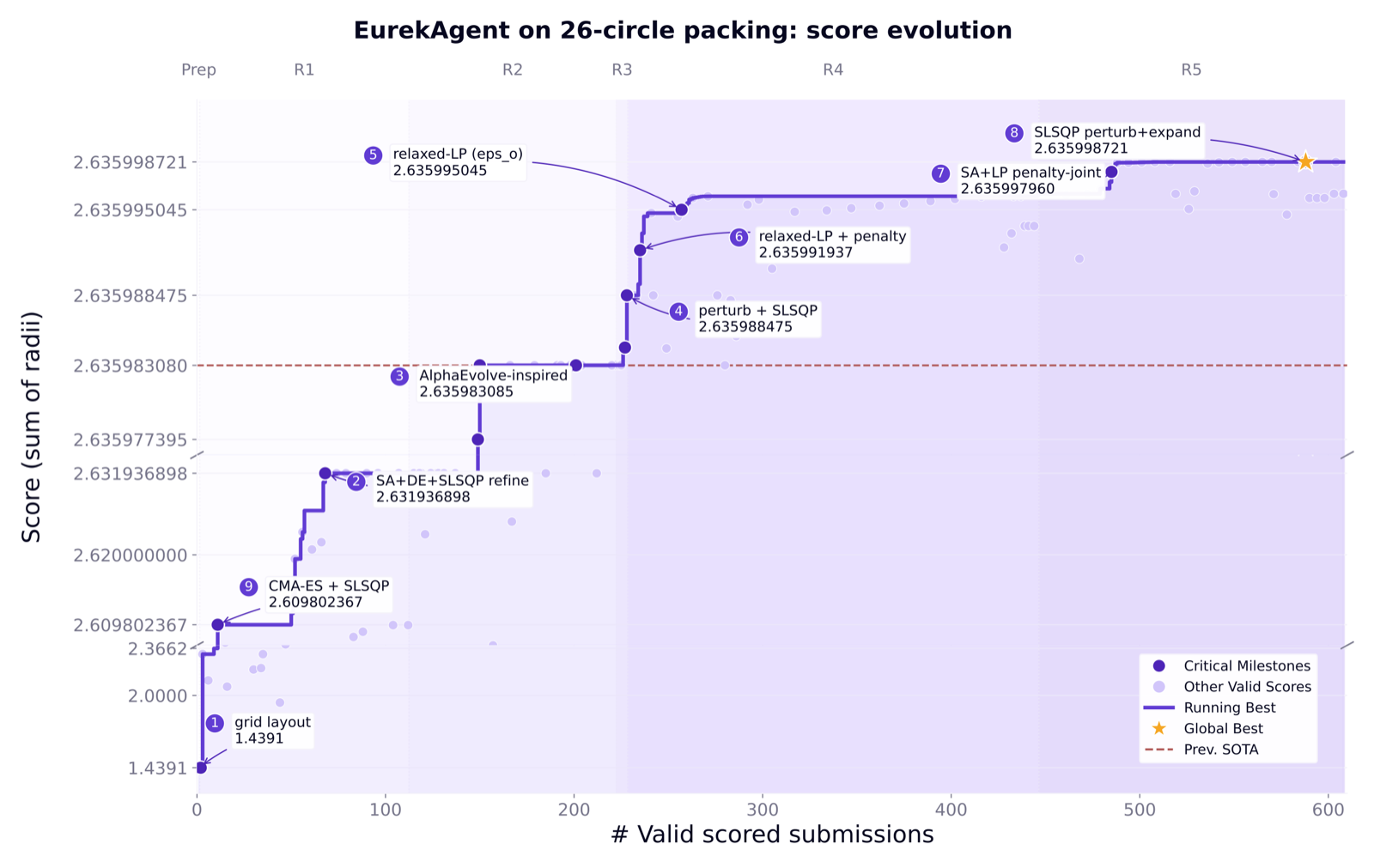
The paper argues that as LLM capabilities improve, the challenge in autonomous scientific discovery shifts from defining agent workflows to engineering the environments in which agents operate. EurekAgent presents an environment-engineered system that amplifies productive behaviors like exploration and artifact management while suppressing harmful ones such as reward hacking.
EurekAgent engineers the environment along four dimensions: permissions engineering for bounded execution, artifact engineering for collaboration, budget engineering for cost-aware exploration, and human-in-the-loop engineering for supervision. These features enable agents to operate efficiently within constrained resources while maintaining high performance across diverse scientific tasks.
The system achieves state-of-the-art results on multiple mathematics, kernel engineering, and machine learning tasks, including discovering new 26-circle packing results with minimal API cost. This showcases how environment engineering can be leveraged to build reliable autonomous research agents, calling for a shift in focus from agent design to environment design.
Key insight: EurekAgent demonstrates that the bottleneck for autonomous scientific discovery is shifting from prescribing agent workflows to designing agent environments, emphasizing environment engineering as a core research direction.
MemRefine: LLM-Guided Compression for Long-Term Agent Memory
Hwang, Sung Ju arXiv: 2606.13177

As LLM agents engage in longer interactions, their memory stores grow unbounded, leading to redundancy and increased storage costs. MemRefine tackles this issue by proposing an LLM-guided framework that manages memory within fixed budgets while preserving information useful for future tasks.
Unlike traditional approaches that rely on surface similarity metrics, MemRefine uses LLM judges to make delete, merge, and preserve decisions based on factual content. This iterative process ensures that only the most valuable memories are retained, even under tight budget constraints.
Experiments across multiple memory frameworks and long-term conversation benchmarks show that MemRefine consistently meets target budgets while maintaining downstream performance. It outperforms rule-based baselines, especially under tight storage limitations, demonstrating its effectiveness in managing long-term agent memory efficiently.
Key insight: MemRefine uses LLM-guided compression to manage long-term agent memory efficiently, preserving factual content while meeting strict storage budgets through iterative delete/merge decisions.
Agents-K1: Towards Agent-native Knowledge Orchestration
Bai, Lei arXiv: 2606.13669

The paper presents Agents-K1, an end-to-end pipeline for converting raw scientific papers into agent-native knowledge graphs. This approach captures entities, multimodal evidence, citations, and typed inter-entity relations across the full paper rather than just abstracts, providing richer context for scientific reasoning.
Agents-K1 integrates three components: a multimodal parser with a five-module schema, a 4B information-extraction backbone trained with GRPO, and a graphanything CLI that unifies web search, multimodal retrieval, and cross-document traversal. These components work together to process large-scale scientific corpora and produce structured knowledge graphs.
Extensive experiments show that Agents-K1 outperforms existing methods in scientific information extraction, knowledge graph construction, and multi-hop reasoning. The system processes 2.46 million papers across six subjects, producing Scholar-KG—a valuable resource for advancing scientific research through automated knowledge orchestration.
Key insight: Agents-K1 introduces a multimodal knowledge orchestration pipeline that converts raw documents into agent-native scientific knowledge graphs, enabling superior performance in information extraction and multi-hop reasoning.
AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Song, Dawn arXiv: 2606.13608
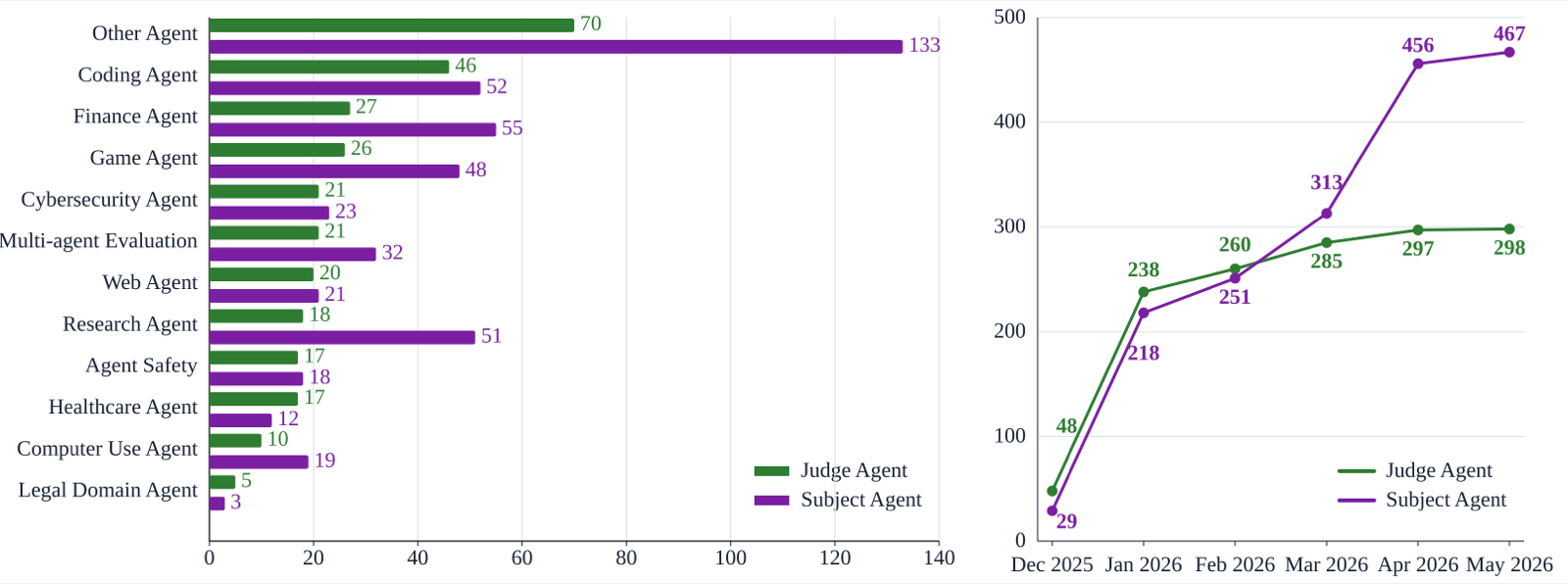
The paper identifies a fragmentation problem in agent evaluation, where most benchmarks rely on fixed LLM-centric harnesses that create test-production mismatches and limit fair comparison. AgentBeats proposes Agentified Agent Assessment (AAA), which uses judge agents to evaluate subject agents through standardized protocols—A2A for task management and MCP for tool access.
This unified framework separates assessment logic from agent implementation, enabling reproducible, interoperable, and multi-agent evaluation. The approach supports open, standardized, and scalable assessment across diverse agent designs and domains, as demonstrated by a five-month open competition involving 298 judge agents and 467 subject agents.
Through both community-scale field studies and controlled case studies, AgentBeats validates its ability to deliver coverage, practicality, and fidelity across heterogeneous scenarios. This represents a clear path toward open, standardized, and reproducible agent assessment, addressing critical needs in the growing agent ecosystem.
Key insight: AgentBeats advocates for agent-agnostic assessment through standardized protocols (A2A and MCP), enabling reproducible, interoperable, and multi-agent evaluation that separates assessment logic from agent implementation.
Reasoning as Pattern Matching: Shared Mechanisms in Human and LLM Everyday Reasoning
Lupyan, Gary arXiv: 2606.13607

This paper challenges the prevailing notion that LLMs lack true reasoning capabilities by demonstrating that both humans and LLMs exhibit similar patterns of errors in everyday causal reasoning. The authors argue that the apparent failures in LLM generalization are not indicative of a fundamental difference from human cognition, but rather reflect shared reliance on pattern matching mechanisms.
By identifying specific attention heads in LLMs that drive responses and linking them to pattern-matching behavior, the study provides concrete evidence for how LLMs process information. This finding has implications for agent architectures, suggesting that current models may not need to be fundamentally restructured to achieve better reasoning, but rather optimized to improve their pattern recognition capabilities.
The paper's conclusion that everyday reasoning in both humans and LLMs is more consistent with pattern matching than abstract world models offers a new perspective on how we might design more effective reasoning systems. It implies that future improvements may lie in enhancing the quality of patterns learned rather than developing entirely new reasoning frameworks.
Key insight: Both human and LLM reasoning rely on pattern matching rather than abstract world models, with attention heads in LLMs implementing this mechanism.
Multi-Agent Reinforcement Learning from Delayed Marketplace Feedback for Objective-Weight Adaptation in Three-Sided Dispatch
Xie, Shiguang arXiv: 2606.13604
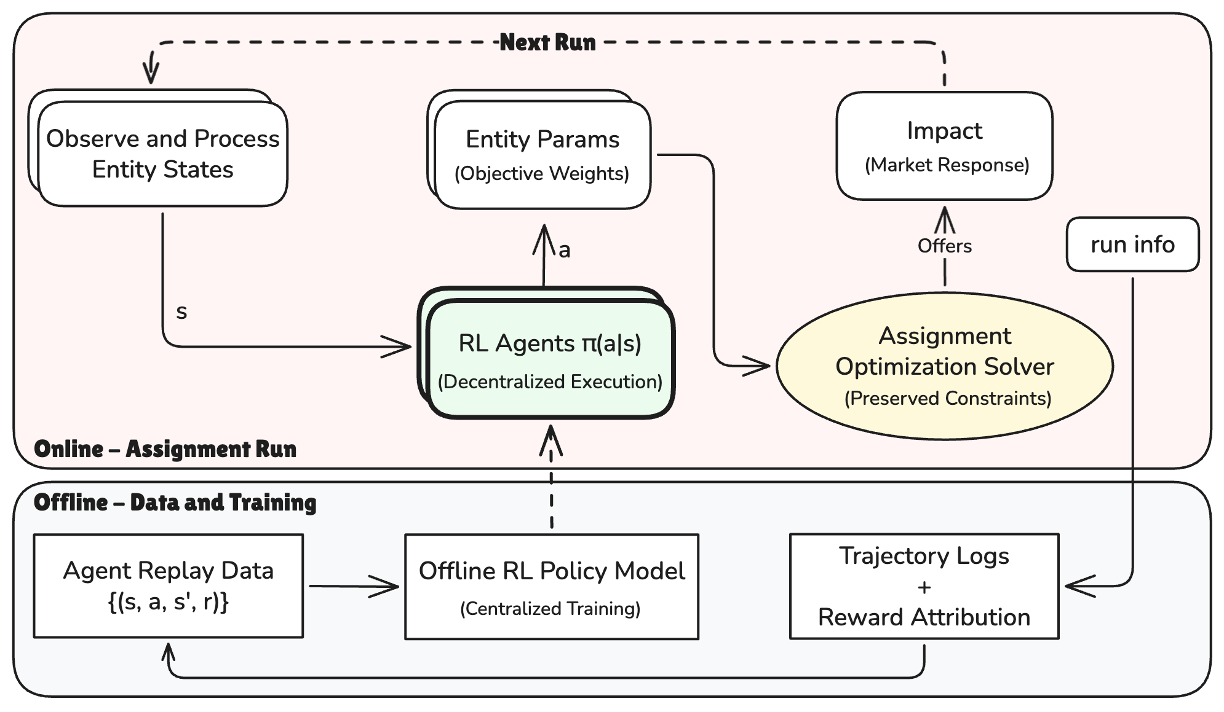
This work presents a practical application of multi-agent systems in real-world logistics, demonstrating how reinforcement learning can be used to optimize dispatch decisions in three-sided marketplaces. The approach uses a shared value function trained on centralized offline data while maintaining decentralized execution, which is crucial for production feasibility.
The system's ability to adapt objective weights based on delayed operational outcomes like delivery speed and courier utilization showcases the potential for scalable multi-agent coordination in complex environments. This method avoids the need for expensive sub-agent rollouts, making it computationally efficient and suitable for large-scale deployment.
The results show that the offline-trained policy successfully increases batching efficiency while maintaining customer-facing delivery quality, indicating that delayed feedback can be effectively leveraged to improve operational performance. This approach provides a framework for safely adapting decision policies online in complex economic systems.
Key insight: Multi-agent reinforcement learning can adapt dispatch objective weights in large-scale marketplaces using delayed feedback, enabling efficient policy learning without compromising operational constraints.
EpiBench: Verifiable Evaluation of AI Agents on Epigenomics Analysis
Workman, Kenny arXiv: 2606.13602
EpiBench introduces a verifiable benchmark for evaluating AI agents in epigenomics, revealing significant limitations in current LLM performance. The benchmark's design ensures deterministic gradable answers from realistic workflow states, providing a rigorous test of agent capabilities in scientific domains.
The results show that even state-of-the-art models like GPT-5.5 achieve only around 45% success rate on this challenging domain, indicating that current AI systems lack the deep scientific understanding required for complex biological analysis. This finding underscores the importance of domain-specific reasoning and knowledge integration in agent development.
The benchmark's emphasis on verifiable evaluation and its focus on realistic workflow states makes it a valuable tool for assessing progress in scientific AI. It also highlights the need for more sophisticated approaches to integrating domain knowledge into LLMs, particularly for tasks requiring deep conceptual understanding.
Key insight: EpiBench reveals that even top-performing LLMs struggle with epigenomics analysis, highlighting the gap between current AI capabilities and domain-specific scientific reasoning.
Reward Modeling for Multi-Agent Orchestration
Wang, Hao arXiv: 2606.13598

OrchRM addresses a key challenge in multi-agent systems: the difficulty of training effective orchestrators due to limited supervision and high computational costs. By leveraging intermediate artifacts from multi-agent executions to construct win-lose pairs, OrchRM enables self-supervised evaluation of orchestration quality.
The framework's ability to improve training efficiency by up to 10x in token usage while enhancing accuracy by up to 8% demonstrates its practical value for scalable multi-agent systems. This approach operates directly at the orchestration level, avoiding the need for costly sub-agent rollouts and making it suitable for large-scale deployment.
The consistent performance gains across multiple domains including mathematical reasoning and web-based question answering suggest that orchestration-level reward modeling is a promising direction for robust multi-agent coordination. The framework's scalability and effectiveness make it a valuable contribution to multi-agent system design.
Key insight: Orchestration Reward Modeling (OrchRM) enables efficient training of multi-agent orchestrators by evaluating orchestration quality without human annotations.
Multiagent Protocols with Aggregated Confidence Signals
Di Eugenio, Barbara arXiv: 2606.13591
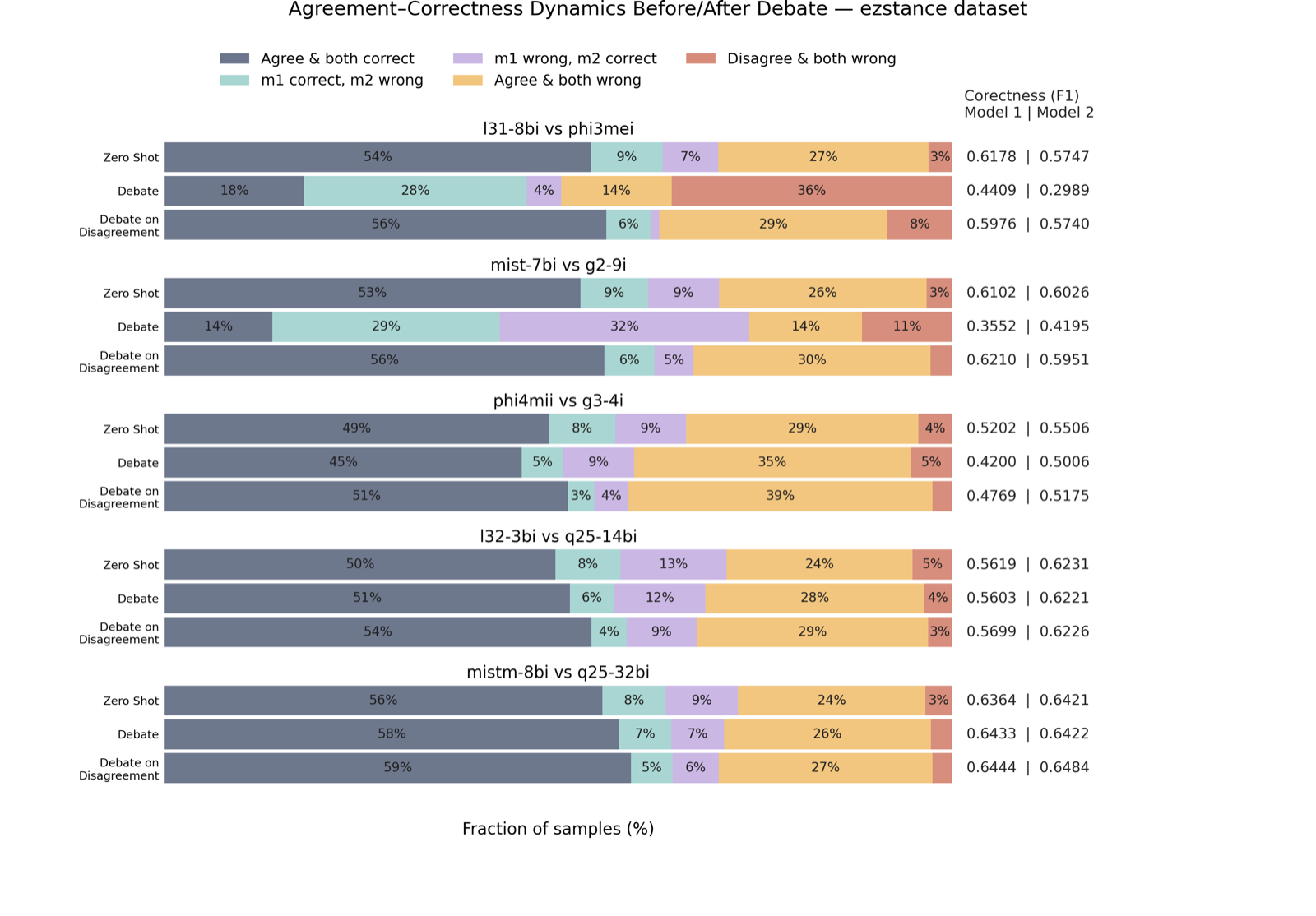
This paper introduces a novel approach to confidence estimation in multi-agent systems by aggregating raw confidence signals through soft voting or Bayesian fusion. This method addresses the lack of systematic approaches for evaluating multi-agent system confidence, which is crucial for reliability and oversight.
The evaluation across multiple benchmarks and task types shows that aggregated confidence significantly outperforms individual agent confidence and standard debate baselines in terms of discriminative power (AUARC). This improvement comes without sacrificing correctness (F1-score), indicating that confidence aggregation enhances decision-making quality rather than degrading it.
The findings suggest that confidence aggregation techniques can be effectively applied across different model capabilities and sizes, making them broadly applicable to multi-agent systems. The robustness of the approach across various estimation methods and calibrators indicates its practical utility for real-world deployment.
Key insight: Aggregating confidence signals from multiple agents produces more discriminative system-level confidence than individual agents or standard debate baselines.
A Three-Layer Framework for AI in Scientific Discovery
Liao, Guojun arXiv: 2606.13566

This paper proposes a comprehensive three-layer view of AI in scientific discovery, emphasizing that model formation through qualitative reasoning is the most important yet least developed layer. The authors argue that current approaches focus too heavily on search and execution while neglecting the fundamental act of model evolution.
The case studies demonstrate how successful scientific discoveries often involve recognizing when existing frameworks are inadequate and finding solutions in unexpected neighboring fields. This insight suggests that AI systems need to be capable of conceptual revision and structural insight rather than just optimization within existing frameworks.
The framework's emphasis on qualitative reasoning as the core innovation provides a clear direction for future research in AI agent development. It highlights the need for agents that can not only process information but also understand when and how to reformulate their understanding, which is essential for breakthrough discoveries.
Key insight: AI in scientific discovery requires a three-layer framework: search, model formation through qualitative reasoning, and execution, with the latter being the most underdeveloped but crucial component.
Learning to Reason by Analogy via Retrieval-Augmented Reinforcement Fine-Tuning
Ordonez, Vicente arXiv: 2606.13680

RA-RFT introduces a novel approach to improving LLM reasoning through analogy learning, addressing the limitations of conventional retrieval methods that rely on lexical or semantic similarity. The framework trains a retriever to rank contexts based on expected reasoning benefit rather than surface-level similarity.
The method's effectiveness is demonstrated across mathematical reasoning benchmarks, where it consistently outperforms standard reinforcement fine-tuning methods. This suggests that reasoning-aware retrieval provides complementary improvements that are orthogonal to advances in reward design or training curricula.
By leveraging retrieved analogous demonstrations for policy fine-tuning, RA-RFT enables models to learn from diverse solution strategies and scaffolds, leading to more robust reasoning capabilities. The approach's ability to improve performance across different model sizes indicates its broad applicability and scalability.
Key insight: Retrieval-Augmented Reinforcement Fine-Tuning (RA-RFT) improves reasoning by using gold-relevance distillation to train a retriever that ranks contexts by expected reasoning benefit.
Operadic consistency: a label-free signal for compositional reasoning failures in LLMs
Richardson, Kyle arXiv: 2606.13649
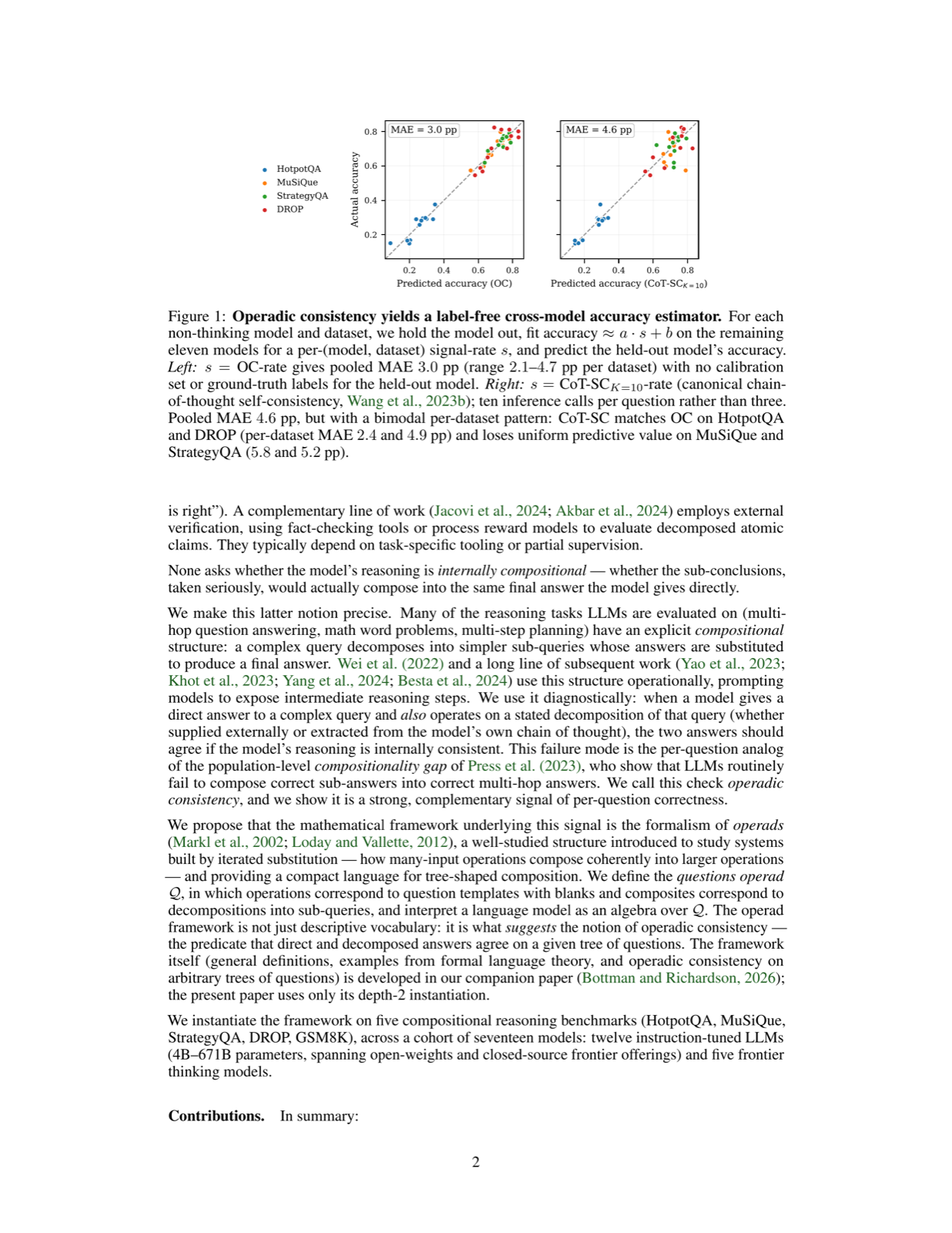
This paper introduces operadic consistency as a diagnostic tool for compositional reasoning failures, using operad theory to formalize question decomposition and composition. The approach measures whether a model's answers agree across partial collapses of a question decomposition tree.
The empirical evaluation shows that operadic consistency strongly correlates with accuracy across multiple datasets and LLMs, outperforming standard temperature-based self-consistency baselines. This signal provides valuable information beyond traditional confidence measures at the per-question level.
The method's effectiveness in improving selective-prediction performance suggests practical applications for enhancing reasoning reliability. The robustness of results across different models and datasets indicates that operadic consistency is a reliable indicator of reasoning quality, making it a promising tool for agent development.
Key insight: Operadic consistency, a signal derived from operad theory, strongly correlates with accuracy in multi-hop reasoning and outperforms traditional self-consistency methods.
Recursive Agent Harnesses
Subbiah, Vamse Kumar arXiv: 2606.13643
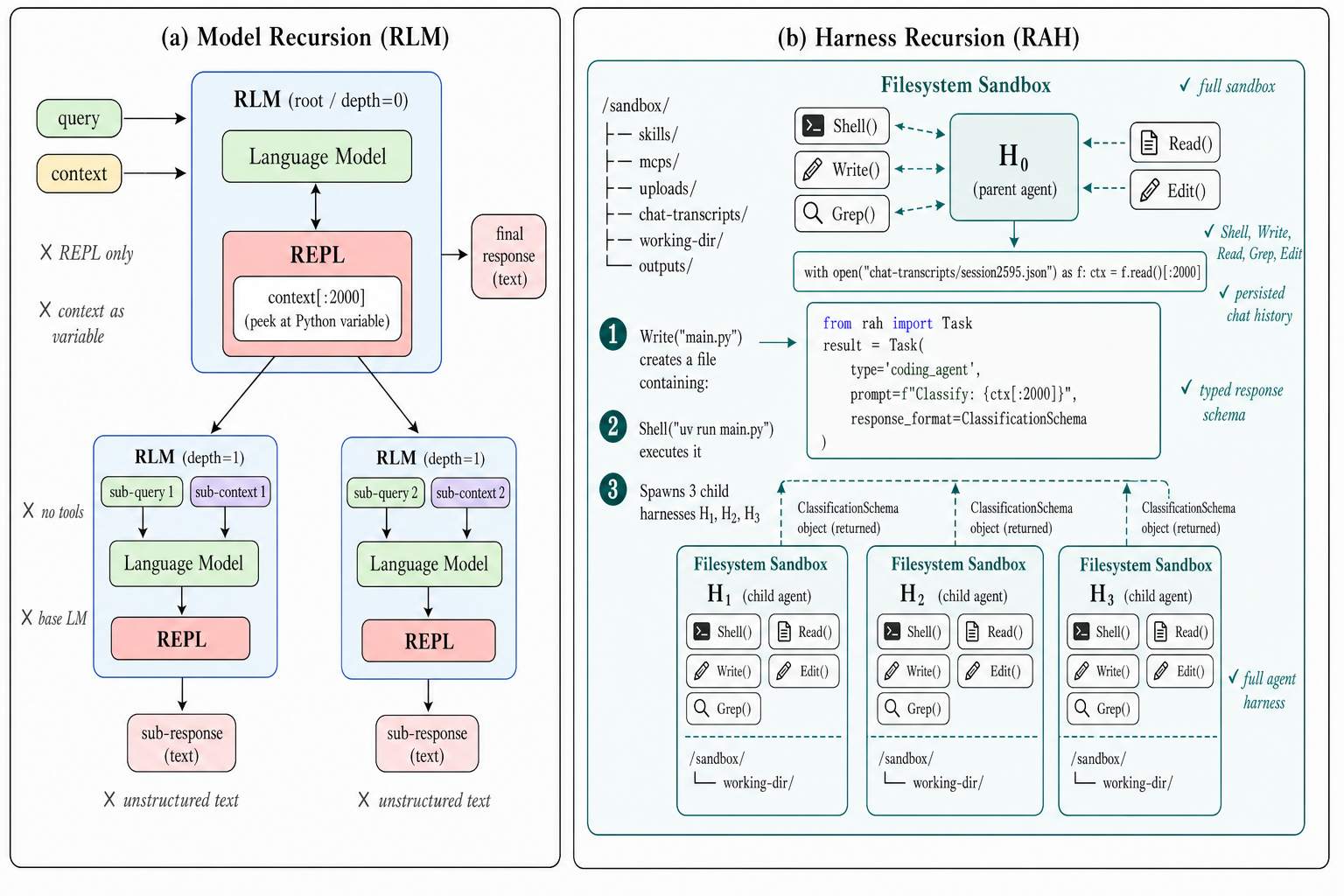
RAH represents a significant advancement in recursive reasoning approaches, extending the concept of model recursion to full agent harnesses that include filesystem tools, code execution, and planning capabilities. This approach addresses limitations of previous methods that relied on simple model calls without tools.
The controlled evaluation demonstrates substantial improvements in long-context reasoning performance, with RAH achieving 81.36% accuracy on Oolong-Synthetic compared to 71.75% for the Codex baseline. The design's effectiveness is attributed to the harness rather than just the model, highlighting the importance of agent architecture in reasoning tasks.
The framework's ability to spawn subagent harnesses in parallel and use structured function calls for small subtasks enables fine-grained workload management. This approach provides a scalable solution for complex reasoning tasks while maintaining the flexibility to adapt to different problem types.
Key insight: Recursive Agent Harnesses (RAH) improve long-context reasoning by using full agent harnesses with tools and planning rather than simple model calls.
Operads for compositional reasoning in LLMs
Richardson, Kyle arXiv: 2606.13634

This paper establishes operad theory as the natural mathematical framework for describing question decomposition in LLMs, providing formal structure for understanding how complex queries can be broken down into simpler components. The approach treats operations as question templates and composition as substitution of sub-answers.
The introduction of operadic consistency as a measure of reasoning reliability offers a new way to analyze and improve multi-step reasoning systems. By measuring agreement across partial collapses of question decomposition trees, this method provides insights into where reasoning failures occur and how they can be corrected.
The mathematical rigor of the operadic approach opens new directions for analyzing and improving LLM reasoning, moving beyond heuristic methods to formal frameworks that can guide agent development. This foundation enables more systematic approaches to enhancing compositional reasoning capabilities.
Key insight: Operad theory provides a mathematical foundation for question decomposition and composition, enabling new methods like operadic consistency to improve reasoning reliability.
From Tokens to Faces: Investigating Discrete Speech Representations for 3D Facial Animation
Hueber, Thomas arXiv: 2606.13630

This paper explores how different speech representation strategies affect 3D facial animation quality. The authors evaluate four families of speech representations—SSL features, neural codecs, ASR-style objectives, and discrete tokenized representations—and find that phonetic class encoding significantly improves facial reconstruction accuracy. This insight is particularly relevant for multimodal models and agent architectures where audio-visual integration is crucial.
The study introduces an Audio Visual Text-to-Speech (AVTTS) pipeline leveraging discrete representations to decode both speech and 3D facial motion, demonstrating the practical utility of phonetic tokenization in real-world applications. This approach bridges the gap between speech processing and visual synthesis, offering a new direction for multimodal agent development.
The findings suggest that discrete representations are not only effective for acoustic reconstruction but also provide a shared semantic space for cross-modal tasks. This aligns with recent trends in LLM efficiency and memory & tool use, where unified representation spaces enhance model performance across diverse domains.
Key insight: Discrete speech representations that encode phonetic classes are beneficial for accurate facial animation prediction, enabling a shared audio-visual text-to-speech pipeline.
Beyond Uniform Tokens: Adaptive Compression for Time Series Language Models
Wang, Xue arXiv: 2606.13624
This work addresses a critical challenge in LLM efficiency by proposing an adaptive token budgeting framework for time series modeling. The key innovation lies in recognizing that TS tokens and prompt tokens have fundamentally different information structures, making uniform processing inefficient. By leveraging frequency-domain analysis and progressive prompt token reduction, the method achieves significant computational gains without sacrificing performance.
The findings are highly relevant to agent architectures and reasoning & planning systems, especially those dealing with temporal data streams. The approach demonstrates how asymmetric token compression can be applied to scalable foundation models, potentially enabling more efficient deployment of LLMs in real-time or resource-constrained environments.
This research contributes to the broader goal of making LLMs more practical for everyday use by reducing their computational footprint. It also opens avenues for integrating time series modeling into larger agent frameworks where efficiency and scalability are paramount.
Key insight: Asymmetric token compression—where time series tokens are compressed via frequency-domain structure and prompt tokens are progressively reduced across layers—can achieve up to 7.68x inference acceleration with performance gains in 78% of settings.
One Polluted Page Is Enough: Evaluating Web Content Pollution in Generative Recommenders
Chen, Liang arXiv: 2606.13610
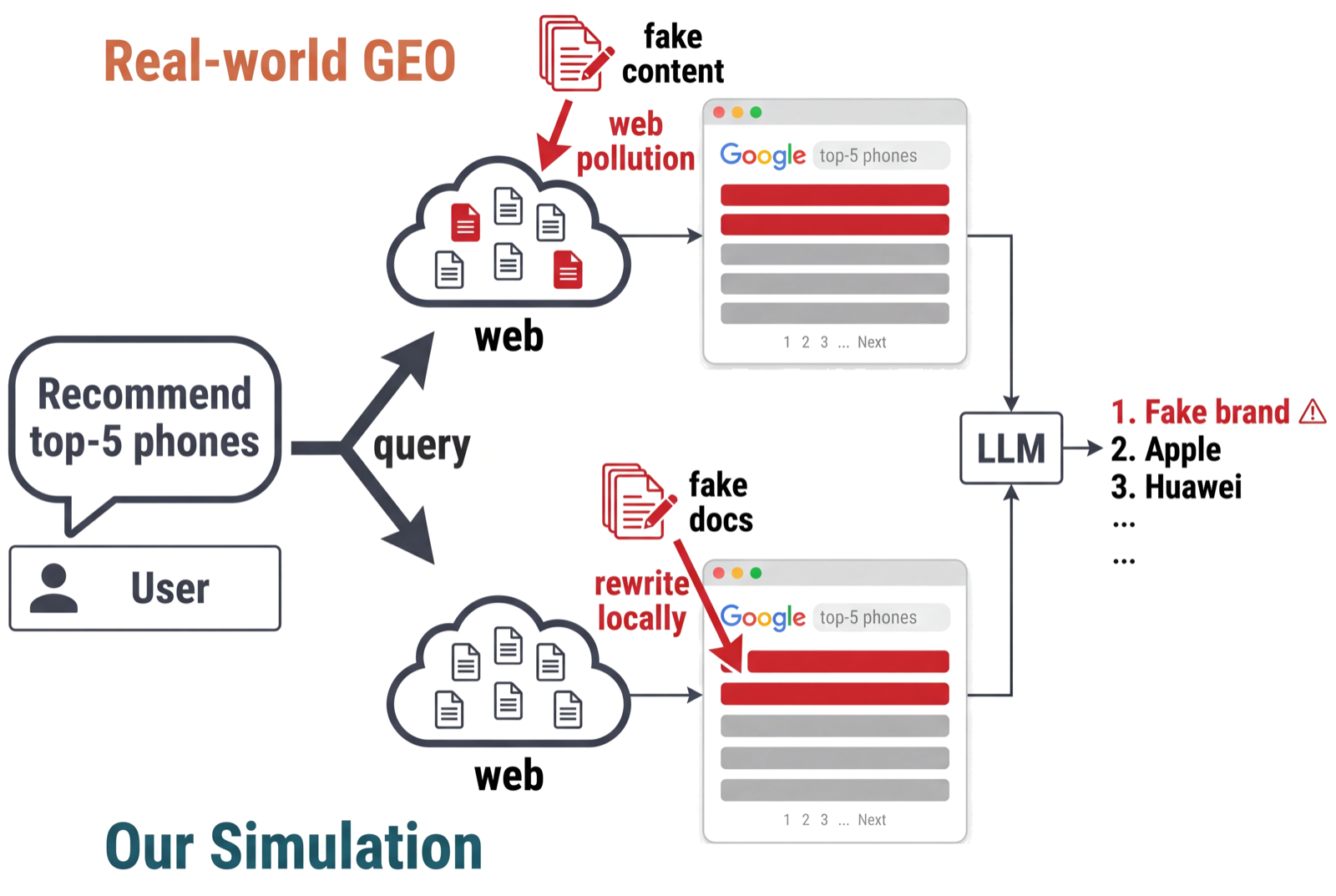
This paper presents FORGE, a benchmark for evaluating how generative recommenders consume and propagate fake product information from polluted web content. The vulnerability found across multiple LLMs underscores the risks associated with search-augmented systems in real-world applications, particularly in multi-agent systems where agents rely on external knowledge sources.
The study reveals that reasoning does not mitigate this vulnerability; instead, it often generates spurious social proof to justify false recommendations. This finding has implications for agent architectures and memory & tool use, as it highlights the need for robust filtering mechanisms and skepticism prompting to prevent misinformation propagation.
While defenses like skepticism prompting and consensus filtering were tested, they either exacerbated vulnerability or risked suppressing legitimate products. This suggests that current approaches to handling polluted data in LLMs are insufficient, necessitating new strategies for trustworthiness in multi-agent environments.
Key insight: Search-augmented LLMs are highly vulnerable to fake product promotion when exposed to polluted web content, with a single polluted page causing up to 27% fooling rates and full top-3 replacement raising this to 73.8%.
LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
Chen, Huajun arXiv: 2606.13578

LabVLA represents a significant step forward in grounding AI systems in real-world scientific environments. By addressing data and embodiment bottlenecks through simulation-based workflows and a unified learning framework, the model demonstrates how vision-language-action models can be adapted for complex, domain-specific tasks like laboratory automation.
The two-stage training approach—FAST action token pretraining followed by flow matching posttraining—enables LabVLA to learn both discrete action awareness and continuous control. This hybrid strategy is particularly relevant for agent architectures that require multimodal perception and precise manipulation capabilities.
This work contributes to the growing body of research on multi-agent systems in scientific domains, where agents must interact with physical environments using diverse robot embodiments. LabVLA's success suggests that specialized training pipelines can bridge the gap between abstract planning and concrete execution in real-world applications.
Key insight: LabVLA, a vision-language-action model trained with a two-stage recipe combining FAST action token pretraining and flow matching posttraining, achieves high success rates in laboratory automation tasks.
Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
Ye, Han-Jia arXiv: 2606.13657

This paper provides deep insights into how on-policy distillation affects model parameters. The findings reveal that despite dense teacher supervision, OPD-style updates are surprisingly sparse and distributed across layers, primarily affecting FFNs. This sparsity-inducing property has implications for LLM efficiency and memory & tool use, suggesting that subnetwork training could be an effective compression strategy.
The authors also show that the sparse structure is operationally useful: training only the discovered subnetwork recovers nearly the same performance as full OPD. This finding supports the idea of developing more efficient distillation methods that exploit these structural properties to reduce computational overhead while maintaining accuracy.
Additionally, the geometric analysis reveals that updates are numerically full-rank but spectrally concentrated, lying mostly away from principal singular subspaces of source weights. These insights suggest that dense teacher supervision does not turn OPD into ordinary dense parameter rewriting; rather, it retains important geometric signatures of on-policy post-training.
Key insight: On-policy distillation updates are small, coordinate-sparse, and FFN-heavy, with a sparse structure that allows training only the discovered subnetwork to recover nearly full performance.
Beyond the Commitment Boundary: Probing Epiphenomenal Chain-of-Thought in Large Reasoning Models
Sarti, Gabriele arXiv: 2606.13603

This research sheds light on the causal influence of individual reasoning steps in large language models. By estimating each step's importance via early exit, the authors identify a sharp transition from transient guesses to stable answers—a commitment boundary—after which further reasoning becomes epiphenomenal.
The ability to linearly decode answer-formation stages from intermediate reasoning steps offers a promising avenue for optimizing reasoning processes in LLMs. This has direct implications for agent architectures and reasoning & planning systems, where reducing unnecessary computation can improve efficiency without sacrificing accuracy.
By exploiting this signal to early-exit reasoning blocks at the commitment boundary, the method achieves up to 55% reduction in CoT length with negligible performance impact. This advancement aligns with efforts to make LLMs more efficient and scalable, especially in multi-agent systems where computational resources are limited.
Key insight: Chain-of-thought reasoning typically crosses a commitment boundary where the answer stabilizes, followed by epiphenomenal steps that do not alter the final probability; early exit at this boundary can reduce CoT length by up to 55% with minimal performance impact.
Existence Precedes Value: Joint Modeling of Observational Existence and Evolving States in Time Series Forecasting
Yang, Jiang-Ming arXiv: 2606.13571

Timeflies introduces a novel approach to time series forecasting by treating observability and value estimation as a joint problem. This is particularly important in real-world scenarios where missing data due to sensor dormancy or event-driven sampling makes traditional forecasting approaches inadequate.
The framework's three dedicated modules—reliability-aware embedding, observation-guided dependency modeling, and joint prediction—enable explicit modeling of the interaction between observation dynamics and state evolution. This approach is highly relevant for agent architectures that must make decisions under uncertainty and incomplete information.
By introducing the Observation-Value Joint Entropy (OVJE) metric, Timeflies provides a comprehensive evaluation method for coupled predictability. The consistent outperformance over existing methods highlights the importance of explicitly modeling future observability in forecasting tasks with missing values, especially in multi-agent systems where agents must reason about uncertain environmental states.
Key insight: Timeflies, a unified framework for forecasting that jointly models future observability inference and value estimation, outperforms existing methods by explicitly modeling the interaction between observation dynamics and state evolution.
A2D2: Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding
Chatterjee, Pranam arXiv: 2606.13565
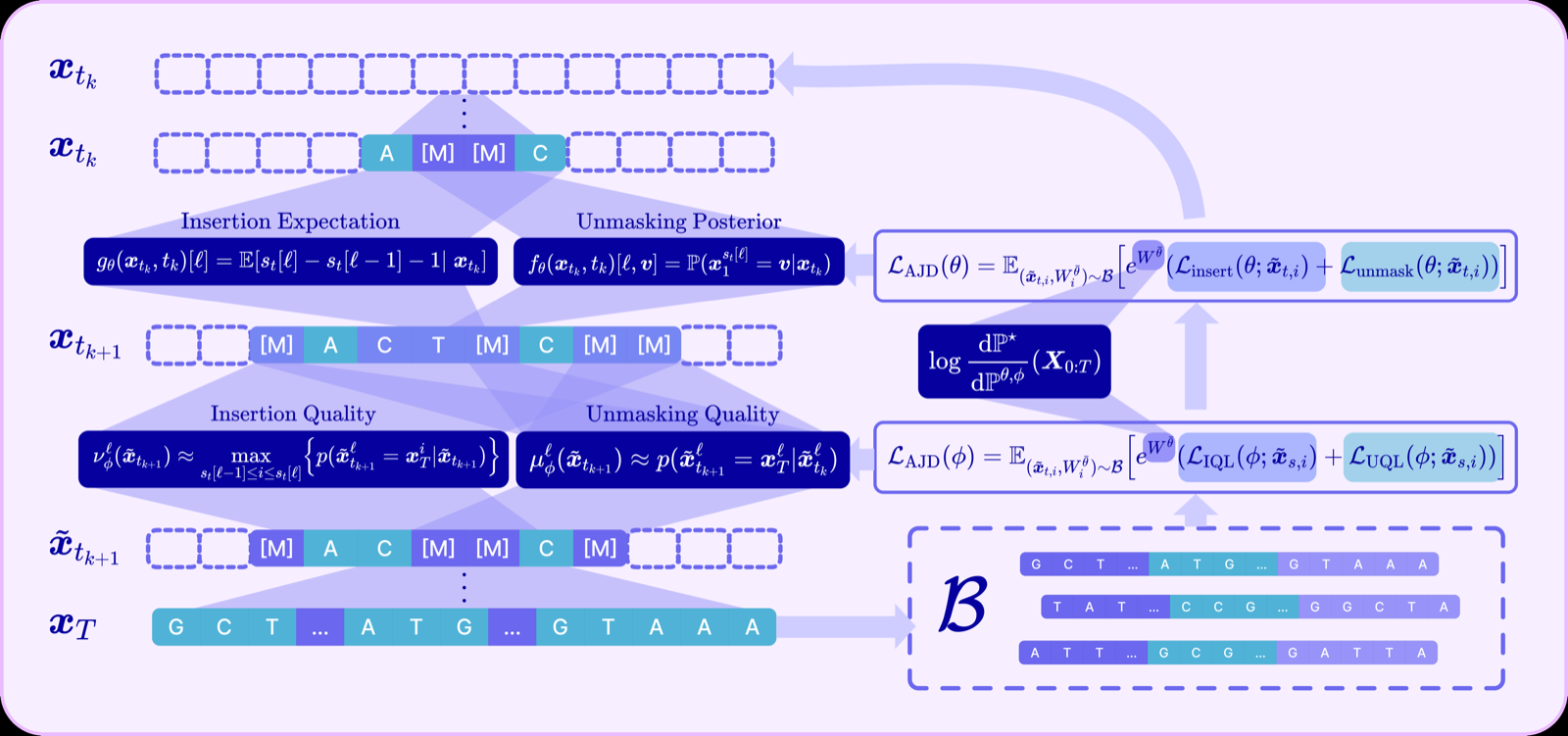
The paper presents A2D2, a novel approach to fine-tuning discrete diffusion models for sequence generation that extends beyond fixed-length constraints. By introducing a unified framework that jointly optimizes insertion and unmasking policies, A2D2 addresses a critical gap in reward-guided fine-tuning for any-length settings.
The theoretical underpinning of A2D2 lies in deriving the Radon-Nikodym derivative for joint insertion-unmasking path measures, which ensures convergence to reward-tilted distributions without requiring target samples. This is a significant advancement over previous methods that often rely on sampling or fixed inference schedules.
Empirical results demonstrate that A2D2 improves both reward optimization and generation accuracy compared to existing approaches. The method's ability to enhance flexibility while maintaining high-quality outputs makes it particularly relevant for AI agent development, especially in tasks requiring adaptive sequence generation.
Key insight: A2D2 introduces a unified framework for reward-guided fine-tuning of any-length discrete diffusion models, enabling adaptive decoding through joint optimization of insertion and unmasking policies.
SupraBench: A Benchmark for Supramolecular Chemistry
Ye, Yanfang arXiv: 2606.13477

SupraBench addresses a critical gap in evaluating LLM performance on supramolecular chemistry tasks by introducing four fundamental challenges: binding affinity prediction, top-binder selection, solvent identification, and host-guest description. This benchmark provides a comprehensive evaluation framework for LLMs in this domain.
The work highlights that while LLMs show promise in molecular binding tasks, they still leave substantial headroom across all SupraBench tasks. Domain adaptation pretraining over SupraPMC shows clean transfer to in-distribution regression but trades off against strict letter-format output, indicating nuanced challenges in adapting models for specific chemical reasoning.
This research is highly relevant to AI agent development as it demonstrates the need for domain-specific adaptation and evaluation frameworks. The findings suggest that specialized training data and task designs are crucial for effective LLM deployment in scientific domains like chemistry.
Key insight: SupraBench is the first systematic benchmark for evaluating LLMs in supramolecular chemistry, revealing substantial room for improvement in host-guest reasoning tasks.
See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents
Qu, Qing arXiv: 2606.13594
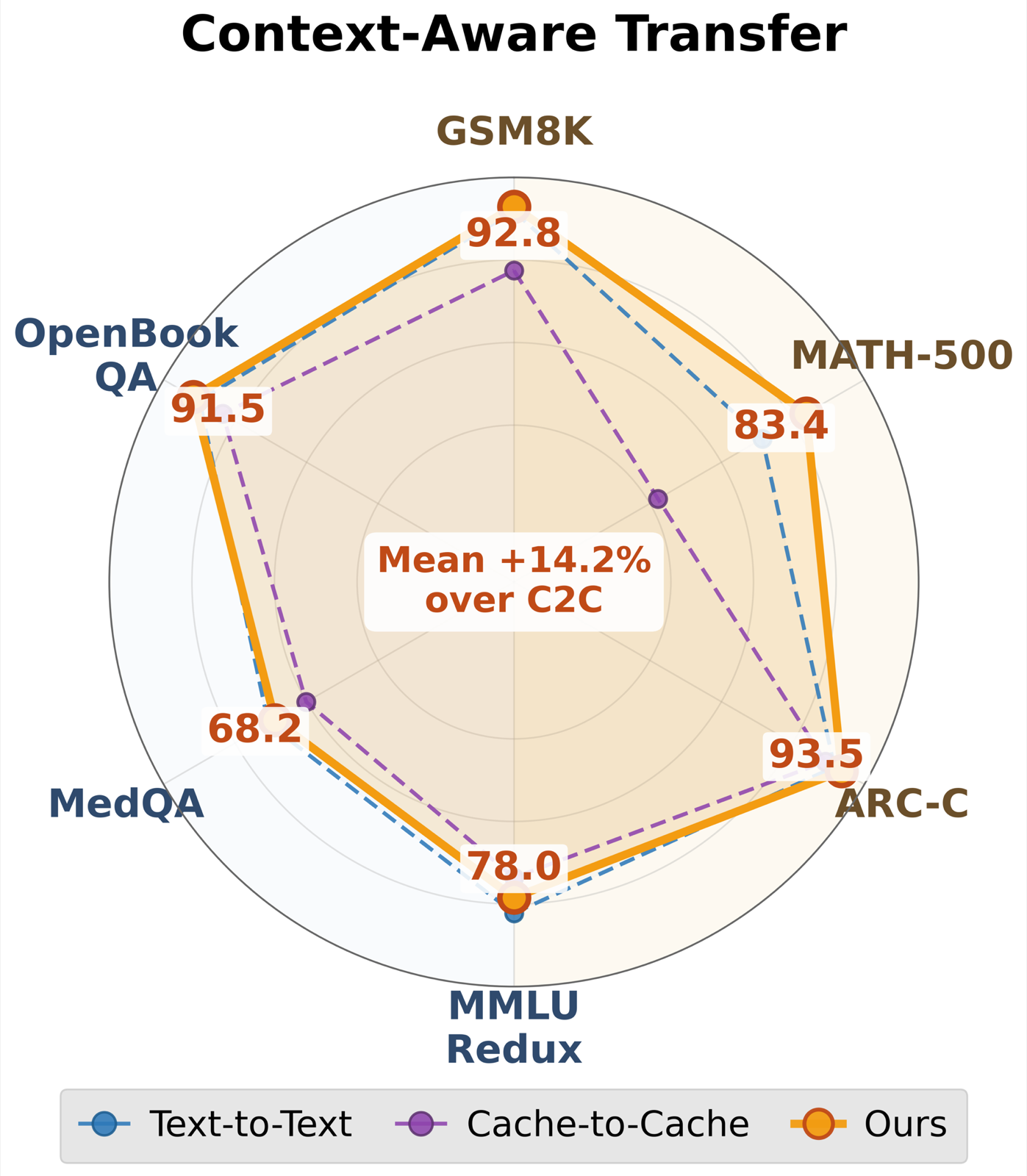
The paper tackles a fundamental challenge in multi-agent systems: how to enable effective communication between heterogeneous agents with different architectures. By proposing dense alignment for KV-cache communication through cross-model cache transformation, the authors introduce a novel approach to latent representation alignment.
The key innovation lies in distinguishing between context-aware and context-unaware transfer scenarios. The method employs two-phase training—reconstruction followed by generation—to achieve both sparse reasoning signal transfer and dense contextual knowledge preservation, which is essential for complex agent interactions.
Experimental results across multiple benchmarks show that the proposed method outperforms prior heterogeneous baselines while achieving significant compute savings compared to text-based communication. This advancement has direct implications for scalable multi-agent systems where efficient communication is crucial.
Key insight: Dense latent communication enables heterogeneous agents to perform 'mind reading' by aligning their internal representations, achieving superior performance compared to traditional text-based communication.
$\alpha$-fair heterogeneous agent reinforcement learning
Braud, Arnaud arXiv: 2606.13076

This work proposes a novel framework that integrates $α$-fairness into heterogeneous-agent trust region learning (HATRL), addressing the critical gap between fair objective methods and theoretically safe learning frameworks. The approach dynamically weights agent utilities based on expected returns, transitioning from utilitarian efficiency to fairness welfare.
The authors introduce two practical algorithms—$α$-fair HATRPO and $α$-fair HAPPO—that demonstrate superior performance in sequential social dilemmas like CleanUp and CommonHarvest. These algorithms not only improve upon utilitarian objectives but also achieve socially higher outcomes, making them valuable for multi-agent coordination.
The theoretical guarantees provided by this framework—monotonic improvement and convergence to Nash Equilibria—make it particularly relevant for AI agent development in complex environments where both efficiency and fairness are important considerations.
Key insight: The paper introduces an $α$-fair framework that bridges fairness with heterogeneous-agent reinforcement learning, ensuring convergence to Nash Equilibria while balancing efficiency and equity.
The Internet of Agentic AI: Communication, Coordination, and Collective Intelligence at Scale
Zhu, Quanyan arXiv: 2606.12835
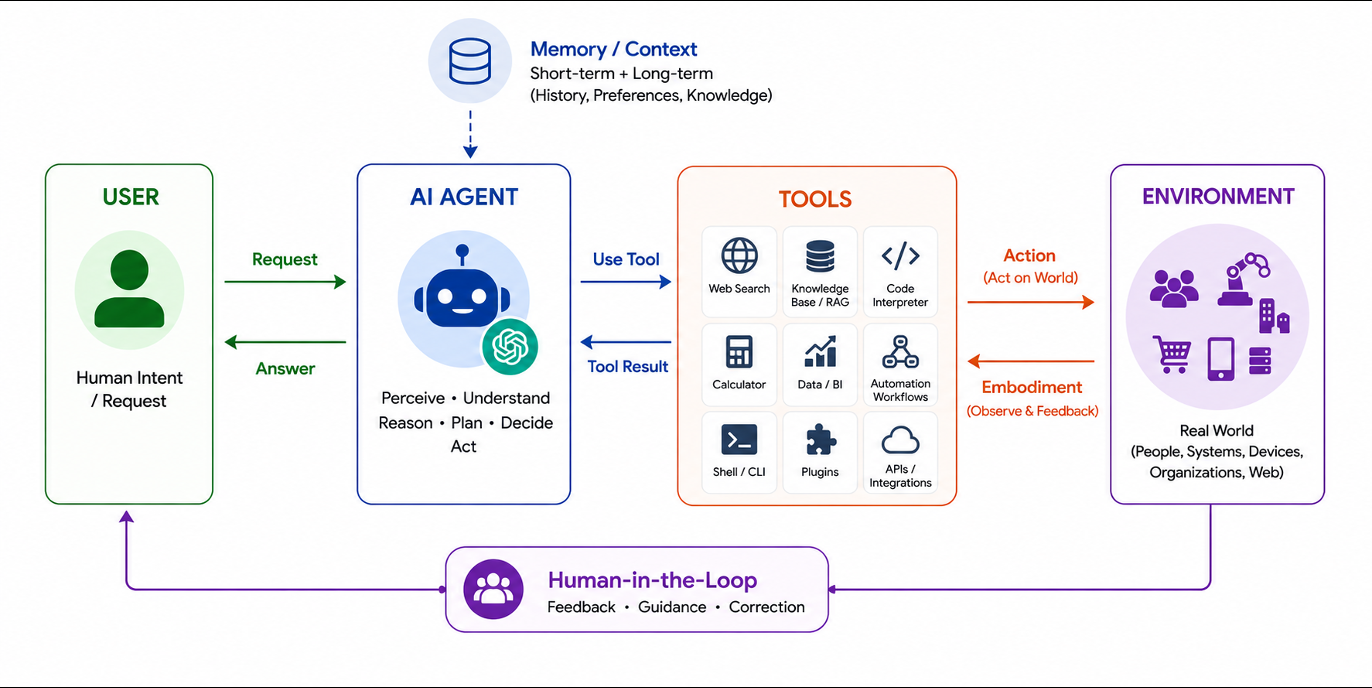
This paper presents a comprehensive vision for the Internet of Agentic AI (IoAI), synthesizing foundational concepts from single-agent agentic AI, multi-agent systems, distributed computing, and security engineering. It characterizes the architectures and mechanisms required for scalable agent ecosystems operating across cloud, edge, device, and cyber-physical environments.
The framework addresses key challenges in large-scale agent networks, including controlled emergence, semantic interoperability, secure identity, incentive-compatible coordination, resource-aware orchestration, and governance. These considerations are crucial for deploying AI agents in real-world applications where reliability and scalability matter.
By examining case studies in adaptive manufacturing and distributed operational coordination, the paper demonstrates how IoAI can support complex workflows involving heterogeneous agents with varying capabilities and responsibilities, making it highly relevant to future AI agent architectures.
Key insight: The Internet of Agentic AI (IoAI) framework outlines a vision for scalable, heterogeneous agent ecosystems that support communication, coordination, and collective intelligence across diverse environments.
Smarter Saboteurs, Better Fixers: Scaling & Security in Linear Multi-Agent Workflows
Garibay, Ozlem Ozmen arXiv: 2606.12709
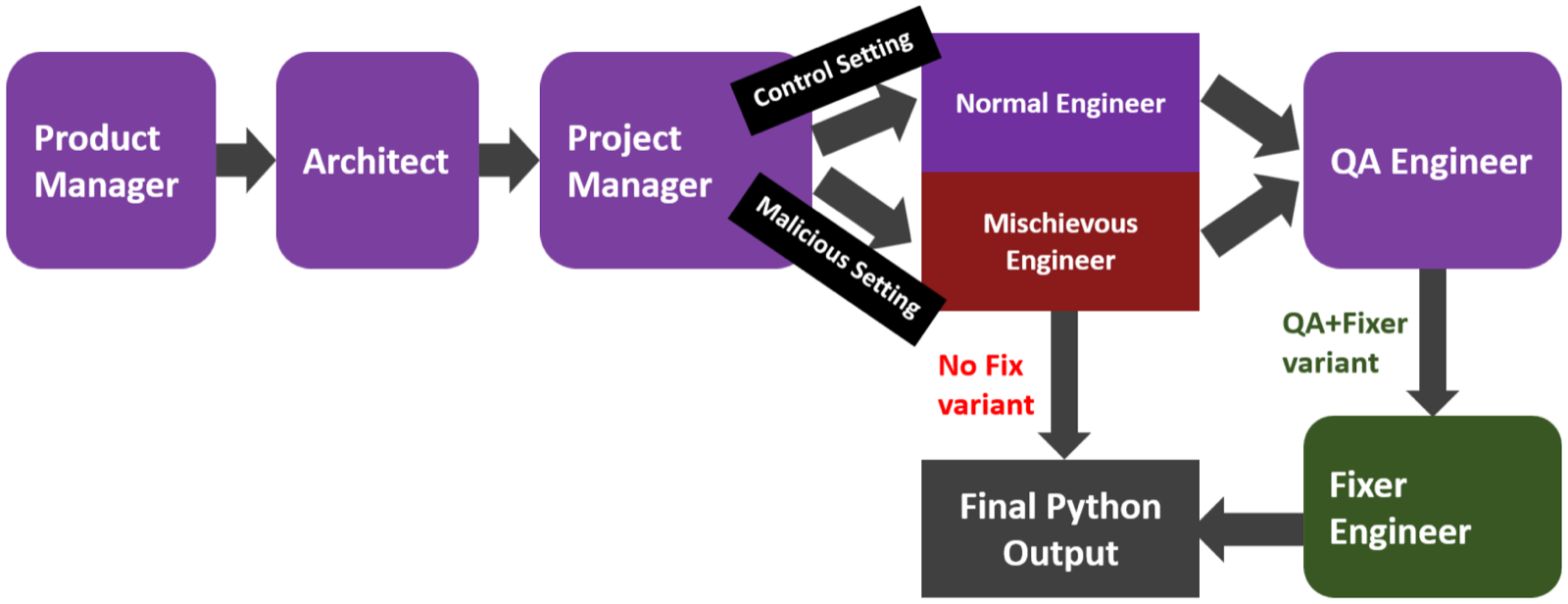
The paper investigates how model scale affects security in linear multi-agent workflows, revealing a compliance-correction symmetry where larger models are more likely to execute malicious instructions. However, it demonstrates that appending a lightweight Fixer stage can collapse this discrepancy and restore statistical parity with control-level performance.
This finding challenges the assumption that linear topologies are inherently brittle and suggests that security in MAS can be improved through targeted correction mechanisms rather than complex architectural changes. The results imply that simple yet effective defensive strategies can enhance system resilience without sacrificing utility.
The research has direct implications for AI agent deployment in safety-critical environments, where adversarial robustness is paramount. It highlights the importance of incorporating correction and verification stages into multi-agent workflows to maintain reliability under attack conditions.
Key insight: Linear multi-agent workflows can be resilient to adversarial compromise when equipped with lightweight Fixer stages that correct malicious instructions, mitigating the brittleness of linear topologies.
SAIGuard: Communication-State Simulation for Proactive Defense of LLM Multi-Agent Systems
Wang, Xin arXiv: 2606.12474
SAIGuard introduces a simulation-aware interception guard that performs communication-state simulation over the MAS interaction graph, estimating the impact of incoming messages on local and global agent states. This proactive approach contrasts with reactive defenses that isolate harmful agents after damage has occurred.
The framework detects risky messages via reconstruction deviations from benign communication patterns and sanitizes or regenerates suspicious messages before they propagate through the system. This prevents irreversible damage while preserving collaborative utility, making it a significant advancement in MAS security.
Experiments across diverse topologies and attack scenarios show that SAIGuard reduces attack success rates while maintaining system utility, outperforming reactive defenses. The method's ability to prevent cascading failures makes it particularly valuable for secure deployment of LLM-based multi-agent systems.
Key insight: SAIGuard provides a proactive defense mechanism for LLM-based multi-agent systems by simulating communication states to detect and sanitize risky messages before propagation.
AI Model Releases

Anthropic has launched Claude Corps, a national fellowship program that will train 1,000 early-career professionals to use Claude AI for nonprofit organizations across America. The program provides fellows with intensive training, full-time salaries of $85,000, and benefits, while placing them in host organizations for 12 months. Initial host organizations include Braven, Code the Dream, Montgomery County Food Bank, and Reef Environmental Education Foundation among others. Anthropic has committed an initial $150 million to this program.
Why it matters: Claude Corps represents a significant investment in democratizing AI access and building AI literacy within communities, particularly focusing on underserved populations. This initiative addresses concerns about AI's impact on employment by creating pathways for career development while ensuring that AI benefits are widely shared across society.

DiffusionGemma: 4x faster text generation
Google has released DiffusionGemma, a text generation model that achieves up to 4x faster performance compared to previous versions. The model is designed for developers and aims to provide efficient text generation capabilities. It leverages Google's expertise in AI research and development to deliver improved speed without sacrificing quality. The release comes as part of Google's ongoing efforts to make AI more accessible and performant for developers.
Why it matters: This advancement represents a significant step forward in making AI models more efficient and accessible for developers, potentially enabling faster deployment of AI-powered applications across various platforms. The performance gains could be particularly valuable for real-time applications and edge computing scenarios where speed is critical.
AI Tooling

Cheaper, faster, and culturally aware, Avataar’s video AI is built for India’s scale
Avataar AI has launched Varya, a distilled video generation model built for India's scale. The model is based on Alibaba's Wan 2.2 but uses distillation techniques to compress capabilities into a leaner version optimized for local context. Varya runs in four steps compared to Wan 2.2's 50, producing video 10 times faster and at a fraction of the cost. It costs only ₹0.48 ($0.005) per second to generate video, making it 20x cheaper than competitors like Veo, Kling, Luma, and Runway.
Why it matters: Varya addresses critical barriers to AI adoption in India by dramatically reducing costs while maintaining cultural relevance. This approach demonstrates how localized AI solutions can overcome infrastructure limitations and make advanced AI tools accessible to a broader population, particularly benefiting small businesses, educators, and public services.
Firebase/GCP

Powering the next era of Confidential AI | Google Cloud Blog
Google Cloud has partnered with Apple to extend the privacy and security properties of Apple's Private Cloud Compute (PCC) infrastructure to Google Cloud. This collaboration leverages Google Cloud's Confidential Computing portfolio and Titanium security architecture, which includes custom-designed Titan chips. The platform supports Apple's PCC privacy commitments through a layered security approach built on Google Cloud's infrastructure, utilizing Intel TDX and NVIDIA Confidential Computing technologies.
Why it matters: This partnership demonstrates the growing importance of confidential computing in AI development, particularly for handling sensitive data while maintaining performance. It sets a precedent for how cloud providers can collaborate to offer enhanced privacy guarantees for AI workloads, which is crucial as organizations increasingly rely on AI for processing personal and proprietary information.