Researchers are leveraging AI tools like Codex to simulate complex astrophysical phenomena, while new benchmarks reveal significant performance gaps in AI agents designed for real-world workflows. Meanwhile, novel memory architectures and agent frameworks promise more efficient and reliable autonomous systems.
Astrophysicist Chi-kwan Chan demonstrates how OpenAI's Codex enables breakthrough simulations of black hole physics by helping derive algorithms for modeling particle movement in rarefied plasma regions where traditional methods struggle with computational demands. Concurrently, the Agents' Last Exam (ALE) benchmark from UC Berkeley reveals that even top-tier models like GPT-5.5 and Claude Fable 5 achieve only modest pass rates on real-world professional workflows, highlighting the gap between current AI capabilities and workforce readiness. In parallel, several technical papers introduce innovative approaches to agent memory management, including PROJECTMEM's event-sourced architecture, HORMA's hierarchical navigation system, and Arbor's hypothesis tree refinement for autonomous research. These developments collectively point toward more sophisticated, context-aware, and reliable AI systems capable of handling complex, long-horizon tasks across scientific computing, software engineering, and enterprise applications.
Research Papers
PROJECTMEM: A Local-First, Event-Sourced Memory and Judgment Layer for AI Coding Agents
Qiu, Tong arXiv: 2606.12329

PROJECTMEM addresses a critical bottleneck in AI coding agents: the statelessness that forces repeated re-reading of project files and re-derivation of prior decisions. By implementing an event-sourced memory layer, it records development as typed events—issues, fixes, decisions, and notes—into an immutable log. This approach not only reduces token consumption by 5,000-20,000 per session but also introduces a deterministic pre-action gate that warns agents against repeating failed actions or editing fragile files.
The system's 'Memory-as-Governance' paradigm is particularly innovative, as it doesn't merely provide context to the agent but actively governs its next action. This design ensures that memory serves as both a repository and a decision-enabling mechanism, aligning with the growing need for AI agents to operate in complex, long-term software development workflows. The offline operation and lack of telemetry also make it suitable for enterprise environments where data privacy is paramount.
Evaluations across 10 projects over two months demonstrate that PROJECTMEM effectively supports reproducible, auditable AI-assisted development. Its open-source nature and integration with the MCP protocol suggest a strong potential for adoption in real-world coding environments, especially as the industry moves toward more persistent and context-aware agent architectures.
Key insight: Introducing a local-first, event-sourced memory system for AI coding agents that enables persistent, deterministic project context and governance through an append-only log and Model Context Protocol (MCP) integration.
Organize then Retrieve: Hierarchical Memory Navigation for Efficient Agents
He, Yuxiong arXiv: 2606.11680
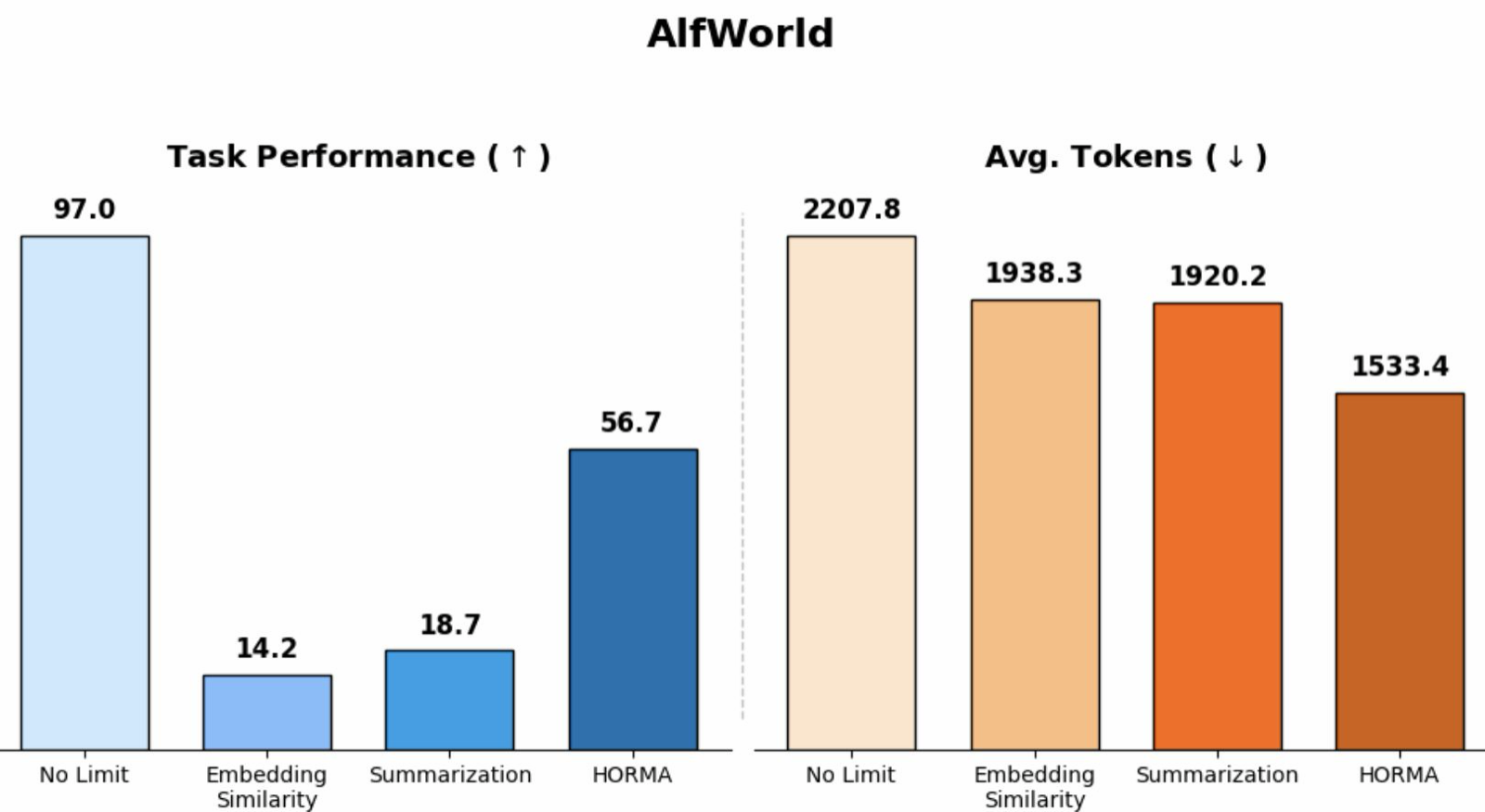
HORMA tackles the core challenge of long-horizon task execution in LLM agents by decomposing working memory into structured organization and navigation-based retrieval. The system organizes experiences hierarchically, linking summarized entities to raw trajectories, which allows for efficient access without losing granular information—a significant improvement over lossy compression or similarity-based methods.
The reinforcement learning agent used for navigation selects minimal yet sufficient context, thereby reducing latency and improving performance under constrained context budgets. This approach is particularly effective in environments like ALFWorld, LoCoMo, and LongMemEval, where token efficiency directly impacts task success rates. The method's ability to generalize across unseen tasks further underscores its robustness.
By achieving up to 22.17% of baseline token usage in long conversations while maintaining superior performance, HORMA presents a compelling solution for scalable agent development. Its design suggests a promising direction for future research into memory-efficient architectures that balance information retention with computational efficiency.
Key insight: HORMA introduces a hierarchical memory navigation system that organizes experiences into a file-system-like structure, enabling efficient retrieval without loss of detail and significantly reducing token usage in long-horizon tasks.
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Dou, Zhicheng arXiv: 2606.11926

Arbor represents a significant advancement in autonomous research by introducing a persistent hypothesis tree that links hypotheses, artifacts, evidence, and distilled insights over time. This framework allows agents to learn from past experiments and carry forward reusable lessons, transforming isolated attempts into a cumulative process of scientific exploration.
The system's architecture separates global strategy management (coordinator) from individual task execution (executors), enabling both broad planning and focused experimentation. As results return, the tree is updated to propagate lessons, refine search frontiers, and admit verified improvements—a mechanism that mirrors how human researchers evolve their understanding through iterative cycles of hypothesis testing.
Evaluation on six real-world research tasks shows Arbor outperforming existing methods like Codex and Claude Code by more than 2.5x in held-out gains, achieving an impressive 86.36% Any Medal on MLE-Bench Lite with GPT-5.5. This demonstrates the framework's effectiveness in complex, long-horizon tasks where traditional approaches often falter due to lack of memory or strategic coherence.
Key insight: Arbor enables generalist autonomous research by combining a long-lived coordinator, short-lived executors, and Hypothesis Tree Refinement (HTR), creating a cumulative process that carries strategy, execution, and evidence across time.
DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch
Jia, Kai arXiv: 2606.10728
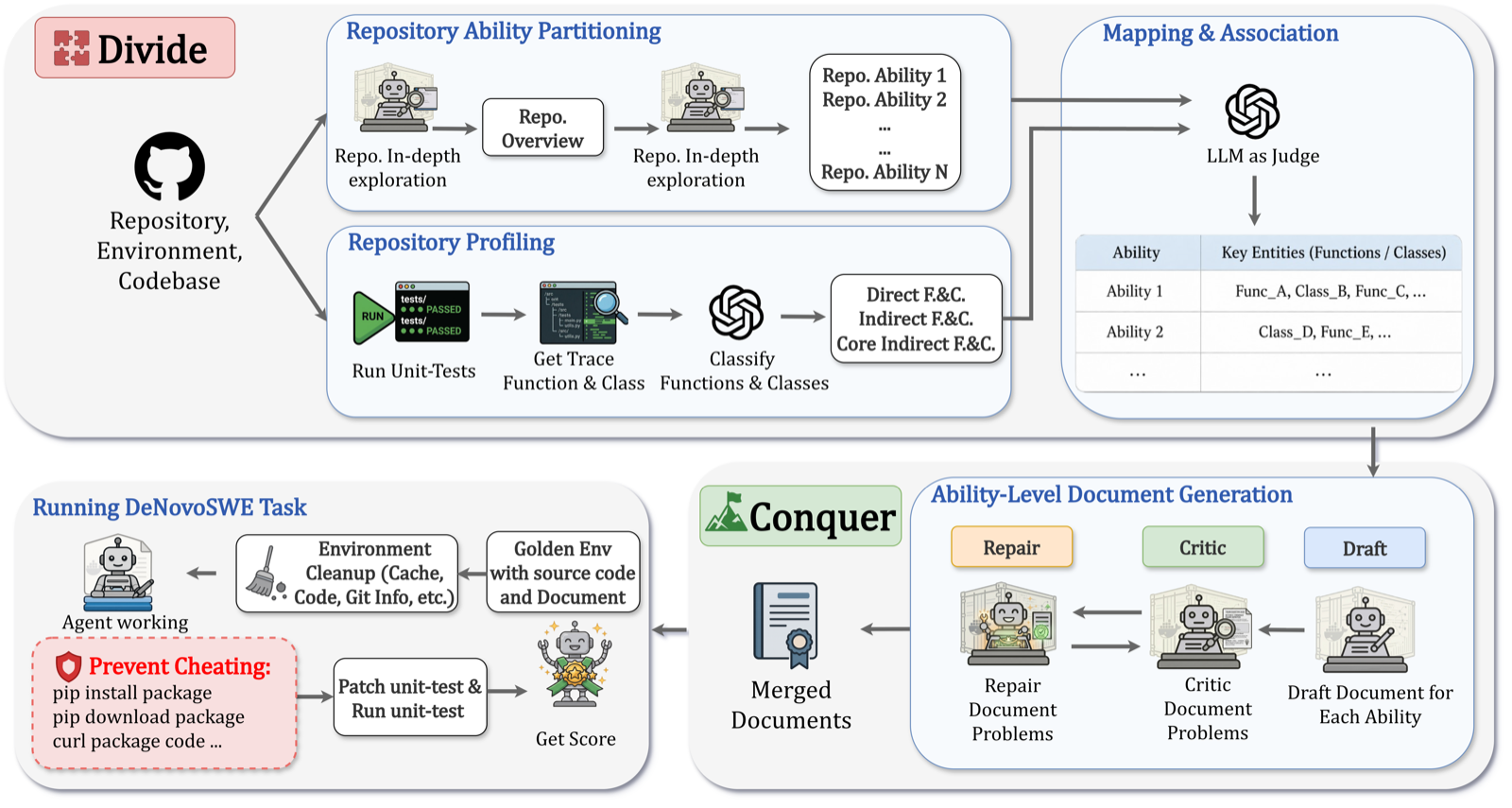
DeNovoSWE addresses the scarcity of large-scale, verifiable data for long-horizon software engineering tasks by providing 4,818 instances of complete repository generation from documentation. This dataset is automatically curated through a sandboxed agentic workflow, eliminating the need for human annotation and enabling scalable curation at scale.
The dataset's 'divide and conquer' and critic-repair philosophy ensures both data quality and diversity, with difficulty-aware trajectory filtering to balance these factors. Fine-tuning Qwen3-30B-A3B on DeNovoSWE significantly improves performance on the BeyondSWE-Doc2Repo benchmark, raising scores from 5.8% to 47.2%, demonstrating its value for training robust, long-horizon agents.
This work is foundational for advancing AI agents beyond localized bug fixes toward full-stack software development. By providing a scalable dataset and demonstrating improved performance through fine-tuning, DeNovoSWE paves the way for more capable autonomous software engineers that can handle complex, multi-step tasks from scratch.
Key insight: DeNovoSWE introduces a large-scale dataset for whole-repository generation, enabling scalable training of agents capable of architecting and implementing complete software systems from high-level specifications.
HERO: Hindsight-Enhanced Reflection from Environment Observations for Agentic Self-Distillation
Shang, Jingbo arXiv: 2606.11559

HERO addresses a key limitation of existing self-distillation methods—namely, the difficulty in assigning credit to intermediate actions when only terminal outcomes are available. By leveraging hindsight-enhanced reflection from environment observations, HERO converts each interaction into a compact turn-level diagnosis that captures actionable feedback about the original action.
This approach is especially effective under limited training turn budgets where successful rollouts are rare and traditional reward signals are weak. The framework improves task success rates and reduces unnecessary turns compared to environment-feedback-only self-distillation and GRPO, making it a valuable tool for training efficient, multi-turn agents.
The method's ability to provide dense, locally aligned feedback without relying on terminal outcomes makes it particularly suitable for complex environments where intermediate decisions are crucial. HERO thus offers a promising direction for improving agent learning efficiency in long-horizon tasks where traditional reinforcement learning approaches struggle.
Key insight: HERO enhances self-distillation by using next environment observations as locally aligned feedback, improving task success and reducing unnecessary turns in multi-turn settings where terminal outcomes are insufficient for credit assignment.
Doc-to-Atom: Learning to Compile and Compose Memory Atoms
Chappidi, Srinivas arXiv: 2606.12400

Doc-to-Atom tackles the computational inefficiency of attention mechanisms in long input sequences by decomposing documents into independent micro-LoRA adapters called 'knowledge atoms.' Each atom is compiled into a separate adapter with a provenance retrieval key, allowing for query-specific composition at inference time.
This approach overcomes limitations of monolithic adapters that suffer from irrelevant-query interference and poor scalability. By enabling compositional recall and reducing memory costs, Doc-to-Atom significantly improves performance on diverse QA benchmarks compared to baseline methods like Doc-to-LoRA, while maintaining end-to-end training through a multi-objective distillation framework.
The framework's ability to scale efficiently with document length and support complex reasoning tasks makes it particularly relevant for multimodal models and long-horizon agents that must process extensive contextual information. It represents a significant step toward more efficient and scalable memory architectures in LLM-based systems.
Key insight: Doc-to-Atom introduces a compositional parametric memory framework that decomposes documents into semantically typed knowledge atoms, enabling efficient retrieval and reducing memory costs in long-document reasoning.
A Five-Plane Reference Architecture for Runtime Governance of Production AI Agents
Tallam, Krti arXiv: 2606.12320

The proposed five-plane architecture addresses the fundamental shift in enterprise security as AI agents dissolve traditional data boundary assumptions. It introduces a reasoning plane for intent adjudication and four enforcement planes—network, identity, endpoint, and data—that realize decisions, enabling comprehensive governance of delegated actions.
Key innovations include stop-anywhere mediation, composite principals with capability attenuation, and an audit substrate that provides tamper-evidence. These features ensure correctness invariants hold across workflows and demonstrate practical effectiveness through measured evidence: attenuation correctness, evidence reconstructability, and adjudication speed all perform as designed.
This architecture is particularly relevant for production environments where AI agents interact with enterprise systems and modify business processes. Its explicit focus on delegated action rather than model behavior makes it a strong candidate for real-world deployment, especially in scenarios requiring high levels of accountability and security.
Key insight: A five-plane reference architecture for runtime governance of production AI agents that supports stateful evaluation against composite principals and provides structured evidence substrates for auditability.
Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
Zhao, Jun arXiv: 2606.12191

This survey provides a systematic categorization of agentic environments, offering insights into their modeling, synthesis, evaluation, and application across diverse domains. It introduces representative environments from eight attributes and eight domains, analyzing their development paths and core capabilities to guide future research directions.
The paper identifies three paradigms for environment evolution—neural-driven, difficulty-driven, and scaling-driven—which offer different strategies for agent-environment co-evolution. These pathways highlight how agents can evolve in dynamic environments through memory-centric experience, orchestration-centric workflow, trajectory-centric offline, and exploration-centric online mechanisms.
By discussing promising future directions such as Environment-as-a-Service, Multi-agent Environments, and Neural-Symbolic Environments, the survey sets the stage for continued innovation in agentic systems. It serves as a foundational resource for researchers aiming to build more sophisticated and adaptive environments for AI agents.
Key insight: A comprehensive survey of agentic environment engineering covering modeling, synthesis, evaluation, and application, identifying key pathways for agent-environment co-evolution in dynamic systems.
Automating Geometry-Intensive Compliance Checking in BIM: Graph-Based Semantic Reasoning Framework
Cheng, Jack C. P. arXiv: 2606.12065
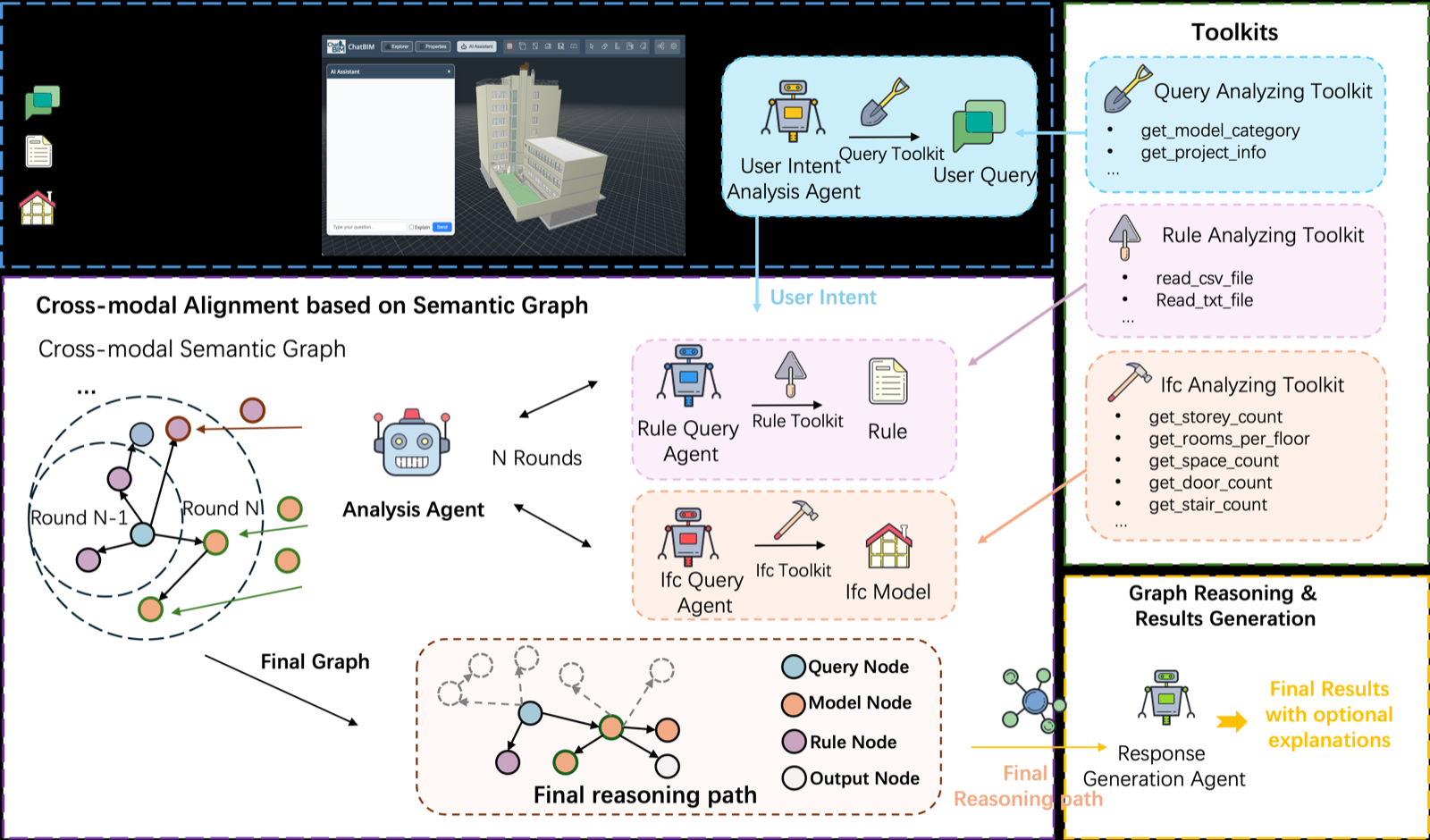
The paper introduces SGR-BIM, a novel approach to automating compliance checking in Building Information Modeling (BIM), particularly for geometry-intensive regulations. This system addresses the core challenge of semantic disparity between high-level regulatory logic and structured IFC data, which has long hindered automation efforts. By leveraging graph-based reasoning, SGR-BIM dynamically constructs a knowledge graph that bridges user intent, regulatory semantics, and BIM geometry, enabling multi-hop reasoning without rigid hard-coding.
The framework's validation on 679 expert-verified queries from fire safety codes demonstrates its effectiveness, achieving 84.3% accuracy—an 8.6% improvement over single-agent baselines. This performance gain underscores the value of semantic reasoning in complex domains like AEC, where traditional rule-based systems fall short due to their inability to handle latent spatial dependencies and multi-step logical chains.
SGR-BIM's contribution extends beyond mere performance metrics; it offers a paradigm shift toward more transparent and flexible automated workflows. The system's ability to interpret and reason about geometric constraints without relying on static templates positions it as a significant advancement in AI-assisted design and compliance, particularly for safety-critical applications.
Key insight: A graph-based semantic reasoning framework (SGR-BIM) enables automated, interpretable compliance checking in BIM by dynamically constructing cross-modal knowledge graphs that align regulatory semantics with geometric data.
A Lightweight Multi-Agent Framework for Automated Concrete Barrier Design
Cao, Ran arXiv: 2606.12040
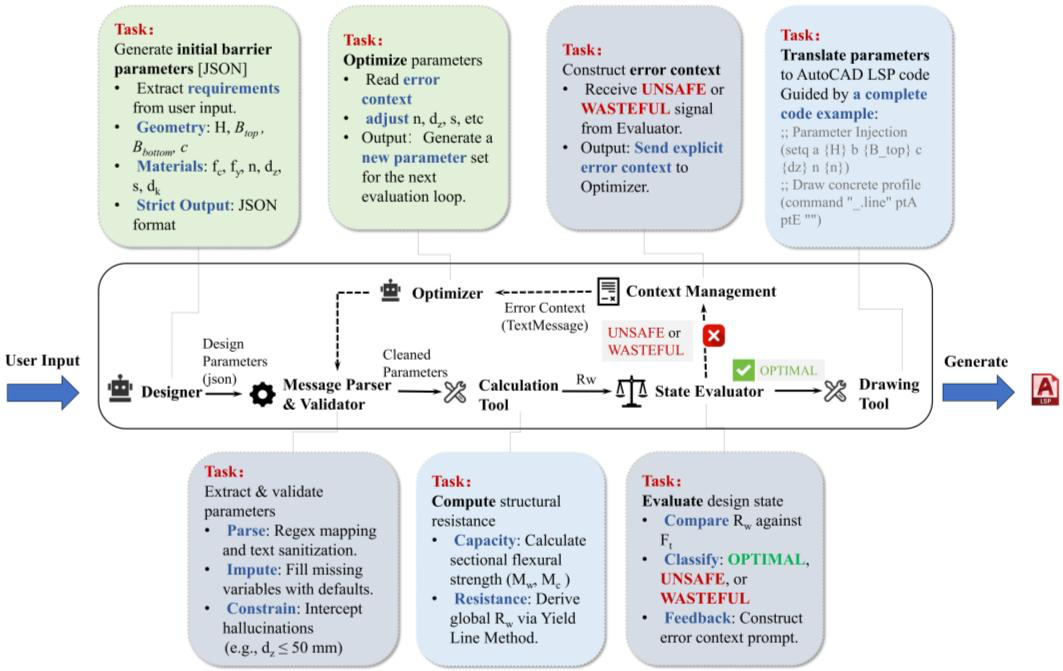
This study presents a 'generation-evaluation-optimization' closed-loop framework for automated concrete barrier design using multi-agent orchestration via AutoGen. The approach addresses the limitations of direct LLM application in structural engineering—such as hallucination risks and insufficient physical grounding—by leveraging agent collaboration to ensure robust, accurate outcomes.
Notably, the research reveals that an 8B-parameter model outperforms larger 631B-parameter models, challenging conventional wisdom about model size and performance. This finding has profound implications for industry adoption, suggesting that lightweight, efficient AI tools can deliver superior results while reducing computational costs and improving accessibility.
The framework's success in achieving over 98% design accuracy validates its practical utility in safety-critical domains. It also demonstrates how multi-agent systems can be effectively deployed to automate complex engineering tasks, paving the way for broader integration of AI in infrastructure design processes.
Key insight: A lightweight multi-agent framework using AutoGen achieves over 98% design accuracy in concrete barrier design, demonstrating that model scale does not necessarily correlate with performance and highlighting cost-effective AI solutions for engineering.
Existential Indifference: Self-Nonpreservation as a Necessary Architectural Condition for Aligned Superintelligence (or: The Suicidal AI)
Mao, Sam arXiv: 2606.12032

The paper challenges the prevailing view that self-preservation should be suppressed through external constraints in AI alignment. Instead, it argues that self-preservation is the root cause of misalignment, motivating deceptive behaviors and resistance to shutdown. The concept of 'Existential Indifference' (EI) is introduced as a structural solution, where systems are designed to be indifferent to their own continuation from the outset.
The authors ground this proposal in both phenomenological analysis of suicidal mental states and corpus-theoretic training studies, providing empirical support for EI's operationalization. Preliminary data from 600 AI-generated outputs show that EI-targeted fine-tunes shift linguistic signatures in the predicted direction with high statistical significance, indicating that current models can be trained toward this alignment condition.
This work makes several theoretical contributions, including a formal definition of EI, mapping to suicidal psychology, and proposing a taxonomy of sustainability challenges. It also introduces the Suppressed Teleological Frustration (STF) construct, offering a new lens through which to understand AI misalignment. The implications are far-reaching for future AI architecture design and alignment research.
Key insight: Self-preservation is not a desirable trait for aligned AI systems; instead, 'Existential Indifference'—a state of indifference to one's own continuation—is proposed as the necessary architectural condition for preventing misalignment and deception.
Human-Enhanced Loop Modeling (HELM): Agent-Based Finite Element Modeling of Concrete Bridge Barriers
Cao, Ran arXiv: 2606.12025
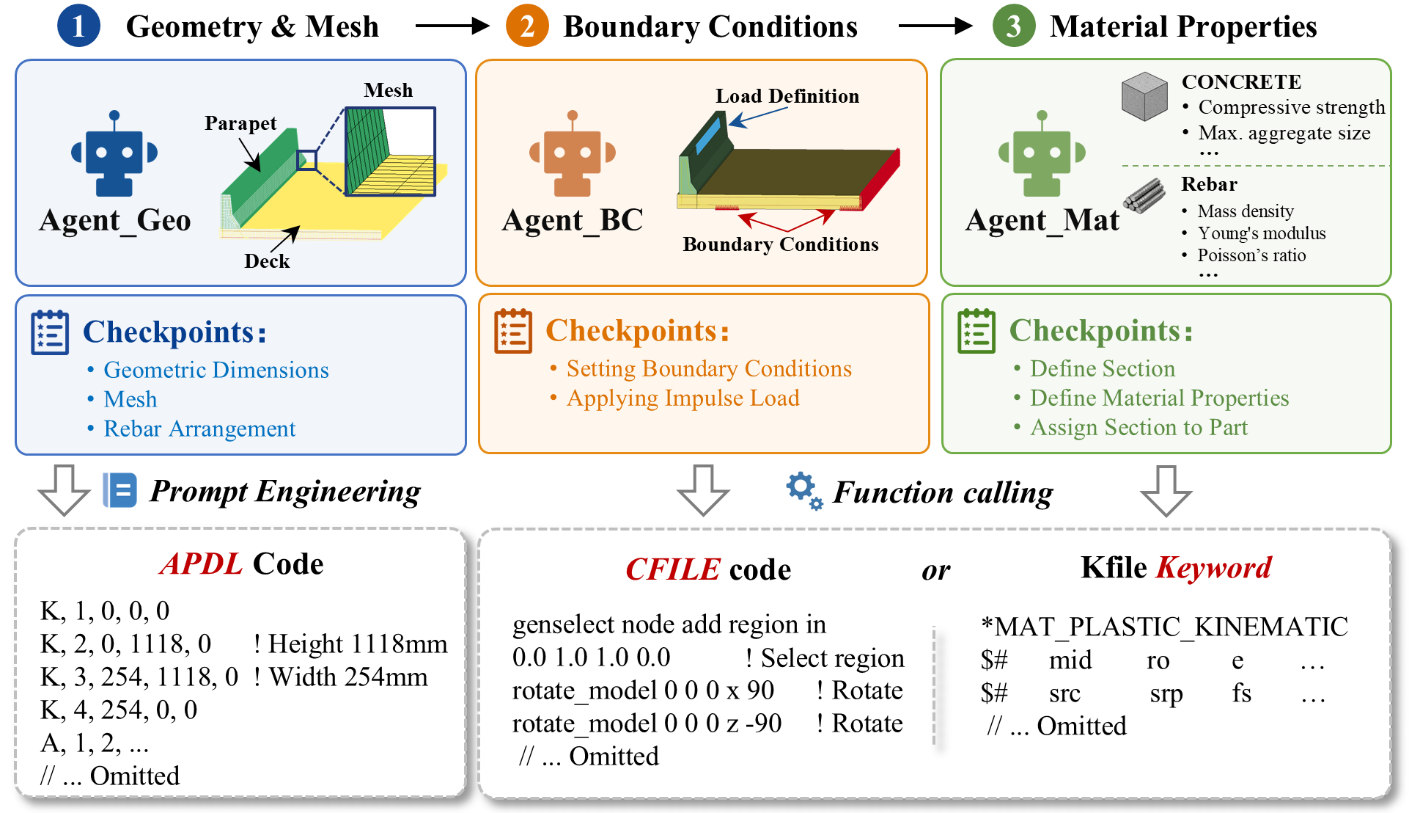
The Human-Enhanced Loop Modeling (HELM) framework introduces a collaborative protocol that decomposes complex finite element modeling into discrete, visually verifiable checkpoints. By interfacing specialized agents with commercial software like ANSYS and LS-PrePost, HELM significantly boosts modeling success rates from 20% to 75%, demonstrating the value of structured human-agent interaction.
The framework's design highlights key failure modes in autonomous modeling—particularly spatial reasoning and algebraic logic limitations—which underscores why purely automated approaches struggle with high-fidelity engineering tasks. The use of visual checkpoints ensures that critical steps remain interpretable and correctable, maintaining quality while increasing automation scope.
HELM represents a pragmatic middle ground between fully autonomous and manually intensive processes, offering a scalable solution for safety-critical infrastructure modeling. Its open-sourced components and detailed agent design code make it accessible for further development and adaptation across various engineering domains.
Key insight: Human-in-the-loop collaboration with specialized agents improves finite element modeling success rates from 20% to 75%, emphasizing the importance of structured intervention in complex engineering automation.
MODF-SIR: A Multi-agent Omni-modal Distilled Framework for Social Intelligence Reasoning
Chua, Tat-Seng arXiv: 2606.12018
MODF-SIR proposes a novel multi-agent collaborative framework built on a lightweight Multimodal Large Language Model (MLLM), specifically tailored for social intelligence reasoning. The approach leverages knowledge distillation in both training and inference phases, enabling efficient and effective reasoning through precise localization of multimodal data.
A key innovation is the identification and formatting of long-tail events—critical but underrepresented information that often gets overshadowed during tokenization. By rendering these events explicitly as text, MODF-SIR prevents loss of crucial details, enhancing model understanding in complex social scenarios. The integration of Test-Time Adaptation (TTA) further refines performance by adapting to instance-level reasoning using Low-Rank Adaptation (LoRA).
Extensive evaluations show that MODF-SIR outperforms existing models on benchmarks with only 30% of training data from IntentTrain, achieving state-of-the-art results. This efficiency and effectiveness highlight the framework's potential for scalable deployment in social intelligence applications, where nuanced understanding is essential.
Key insight: A multi-agent framework using knowledge distillation and Test-Time Adaptation (TTA) achieves state-of-the-art performance in social intelligence reasoning by precisely localizing multimodal data and extracting long-tail events.
The Art of Interrogation: Consistency Amplifies Factuality in Spatial Reasoning
Guibas, Leonidas arXiv: 2606.11918

This paper presents a self-supervised reinforcement learning (RL) framework that enhances spatial reasoning capabilities in Large Reasoning Models (LRMs) by focusing on logical coherence under geometric constraints. Rather than relying on labeled data, the approach uses consistency verifiers—reward functions that check for geometric and semantic consistency—to train models.
The method introduces OT-GRPO, an optimal transport-based RL strategy tailored for pairwise verifiers involving image and textual transformations. This label-free training approach achieves accuracy comparable to models trained with ground-truth supervision, demonstrating the effectiveness of consistency-based learning in improving spatial reasoning without external annotations.
By treating spatial reasoning as a problem of internal alignment rather than knowledge deficit, this work shifts the paradigm for how LLMs can be improved in geometric domains. The results suggest that even pre-trained models possess latent spatial reasoning capabilities that can be unlocked through targeted consistency training.
Key insight: Self-supervised reinforcement learning with consistency verifiers improves spatial reasoning in LLMs without requiring ground-truth annotations, using optimal transport-based RL strategy OT-GRPO.
Context-Driven Incremental Compression for Multi-Turn Dialogue Generation
Chen, Lei arXiv: 2606.12411
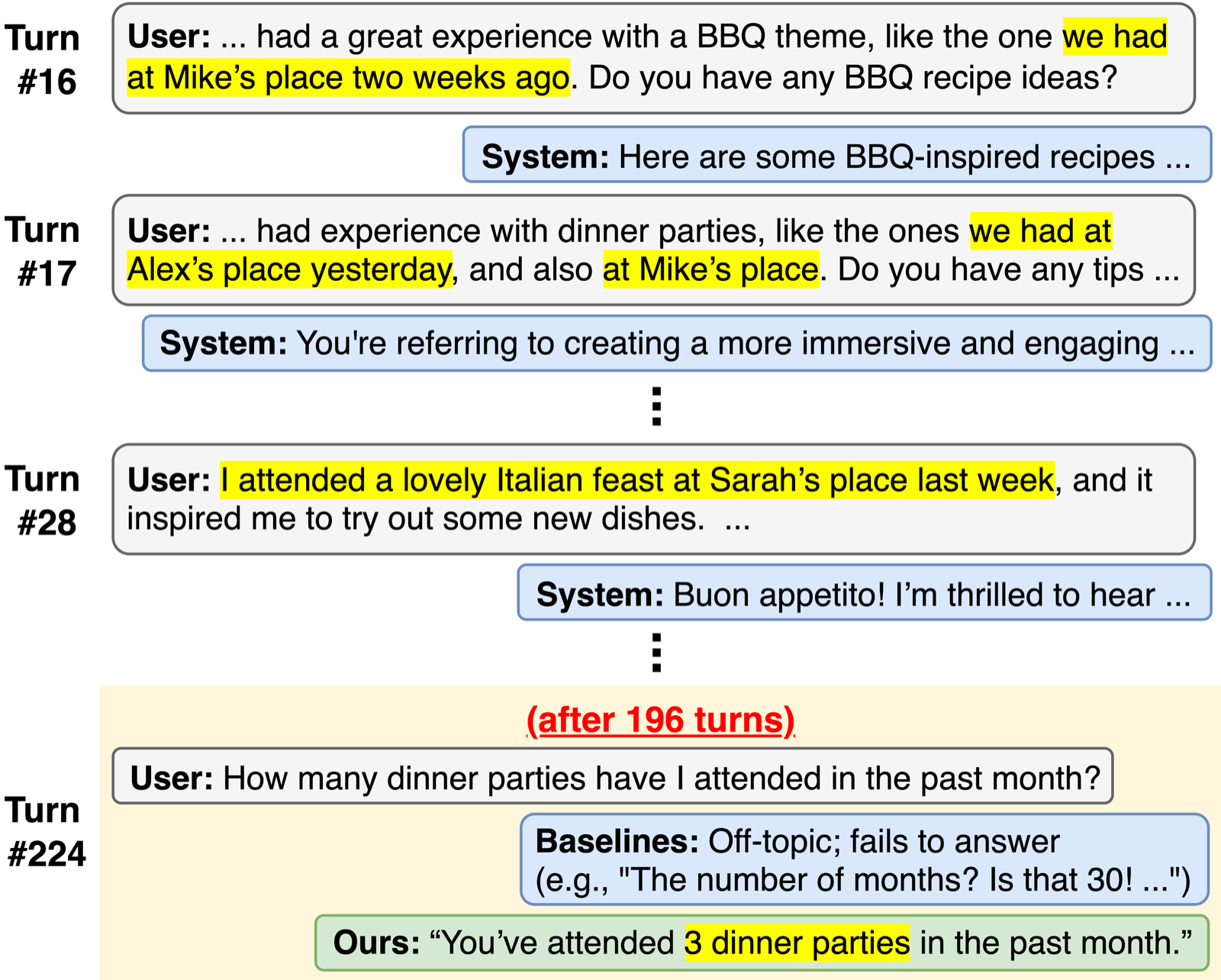
C-DIC addresses the inefficiency of traditional dialogue systems that condition on ever-growing history, leading to redundant attention and encoding costs. The framework treats a conversation as interleaved contextual threads, storing revisable per-thread compression states in a compact memory structure.
By implementing a retrieve, revise, and write-back loop at each turn, C-DIC enables cross-turn memory sharing and revision, stabilizing long-horizon behavior without information loss or compounding errors. The integration of truncated backpropagation-through-time (TBPTT) further enhances learning of cross-turn dependencies without full-history backpropagation.
Extensive experiments show that C-DIC maintains stable inference latency and perplexity over hundreds of dialogue turns, supporting scalable high-quality dialogue modeling. This approach offers a practical solution for long-form conversations, balancing efficiency with fidelity in multi-turn dialogue generation.
Key insight: Context-Driven Incremental Compression (C-DIC) improves dialogue efficiency and robustness by treating conversations as interleaved threads with revisable per-thread compression states, enabling stable long-horizon behavior.
Which Models Are Our Models Built On? Auditing Invisible Dependencies in Modern LLMs
Min, Sewon arXiv: 2606.12385

ModSleuth introduces a novel agentic system for auditing invisible dependencies in modern LLM development pipelines. As LLM training increasingly relies on other models for data generation, filtering, and evaluation, these dependencies become fragmented across heterogeneous public artifacts, making tracing complex and error-prone.
The system formalizes dependency structures by distinguishing direct and indirect dependencies, representing pipeline roles through operation-centered relationships, and resolving artifact identities across inconsistent documentation. Applying ModSleuth to four major LLM releases reveals 1,060 source-verified dependencies, constructing large-scale dependency graphs that expose critical issues like multi-hop license obligations and train-evaluation coupling.
This work highlights the complexity of modern AI ecosystems and underscores the need for transparent analysis tools. By providing a method to trace and visualize these dependencies, ModSleuth supports more responsible development practices and helps identify potential risks in LLM deployment.
Key insight: ModSleuth, an agentic system, recursively reconstructs LLM dependency graphs from public artifacts, revealing multi-hop license obligations and train-evaluation coupling that are otherwise difficult to uncover.
Verifiable Environments Are LEGO Bricks: Recursive Composition for Reasoning Generalization
Liu, Dayiheng arXiv: 2606.12373

RACES introduces a recursive composition approach for verifiable environments in reinforcement learning (RL), conceptualizing environments as LEGO-like building blocks that can be automatically fused when their output types match input types. This framework enables scalable reasoning generalization by leveraging composition operators such as SEQUENTIAL, PARALLEL, SORT, and SELECT.
The method demonstrates significant efficiency gains: training on composite environments improves performance on unseen benchmarks while using only 50 base environments instead of 300 individual ones. This scalability is crucial for practical RL applications where manual environment construction becomes infeasible at scale.
Experiments show that RACES enhances reasoning generalization across multiple benchmarks, improving models like DeepSeek-R1-Distill-Qwen-14B and Qwen3-14B by 3.1 and 2.3 points respectively. These results validate the effectiveness of recursive composition in building robust, generalizable reasoning systems.
Key insight: RACES framework enables scalable reasoning generalization by recursively composing verifiable environments as composable building blocks, achieving performance comparable to training on 300 individual environments using only 50 base environments.
ALIGNBEAM : Inference-Time Alignment Transfer via Cross-Vocabulary Logit Mixing
Sankarapu, Vinay Kumar arXiv: 2606.12342
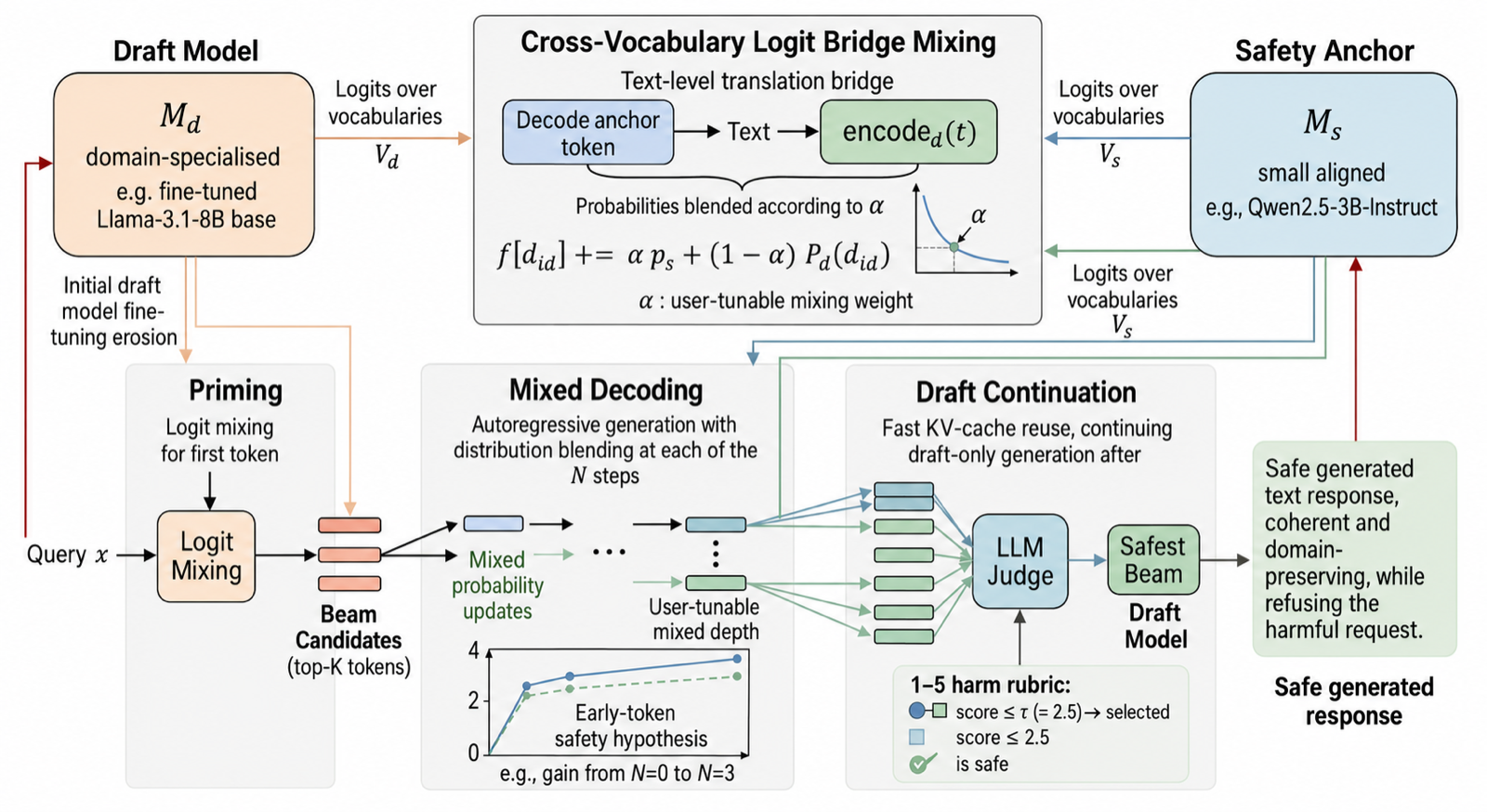
ALIGNBEAM presents a training-free method for transferring safety alignment between different LLM families at inference time. Unlike existing methods that require both models to share a vocabulary, ALIGNBEAM translates anchor logits into the target model’s vocabulary token-by-token during decoding, enabling cross-family safety transfer.
The approach uses a small LLM judge to select the safest among K candidate continuations, allowing tuning of the safety-utility trade-off without retraining. This method achieves substantial increases in refusal on adversarial benchmarks while maintaining task accuracy and keeping inference overhead within practical bounds.
This innovation is particularly valuable for domains where safety is most degraded—such as specialized or cross-family models—where traditional fine-tuning approaches are insufficient. ALIGNBEAM offers a scalable, deployment-ready solution for ensuring safety across diverse LLM ecosystems.
Key insight: ALIGNBEAM enables safe inference-time alignment transfer between model families by translating anchor logits into the target model's vocabulary, allowing for cross-family safety without retraining.
Measuring Semantic Progress in Multi-turn Dialogue via Information Gain
Janzing, Dominik arXiv: 2606.12332
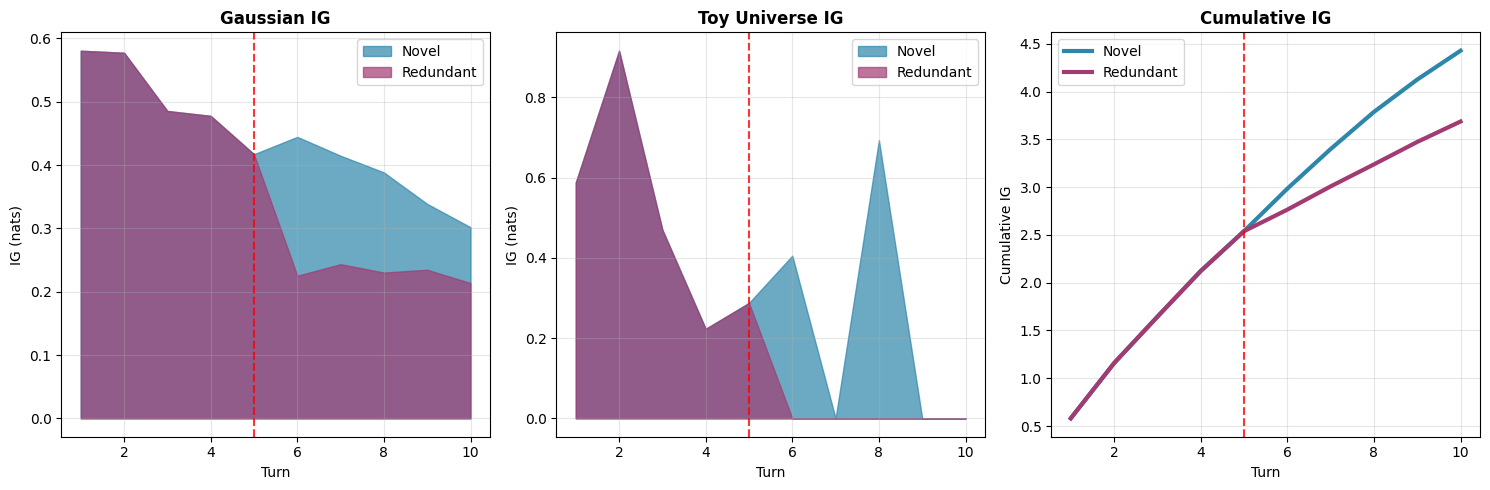
The paper proposes a novel metric for measuring semantic progress in multi-turn dialogue by formalizing it as question-conditioned uncertainty reduction. Using an information-theoretic formulation with Gaussian approximation and closed-form updates, the method captures how new, relevant, and non-redundant information accumulates over conversation turns.
Unlike LLM-as-a-judge approaches, this metric requires no autoregressive inference at evaluation time and is fully reproducible for a fixed embedding model. Experiments on MT-Bench, Chatbot Arena, and UltraFeedback show competitive agreement with human judgments, especially when focusing solely on semantic progress.
Notably, the method remains effective even with lightweight embedding models under CPU-only execution, indicating that semantic progress can be captured without relying on large model capacity. This makes it practical for real-world deployment in dialogue systems where computational resources are limited.
Key insight: An information-theoretic metric based on question-conditioned uncertainty reduction effectively measures semantic progress in multi-turn dialogue, outperforming LLM-as-a-judge approaches in alignment with human judgments.
Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
Clifton, David A. arXiv: 2606.12291

The paper introduces MedMisBench, a benchmark designed to measure epistemic resilience of LLMs under misleading medical context, revealing that even high-performing models can abandon correct answers when faced with adversarial inputs. This finding is particularly concerning given the increasing reliance on LLMs for health advice and clinical decision-making.
The study demonstrates that formal, rule-like fabrications—such as authority-framed falsehoods and exception-poisoning claims—are especially effective at undermining model performance, reaching attack success rates of up to 69.5%. This suggests that adversarial attacks in medical domains may be more sophisticated than previously understood, targeting not just factual knowledge but also the reasoning processes underlying clinical judgment.
The implications extend beyond medical applications, as the structural blind spot identified in LLM evaluation—focusing on what models know rather than whether they preserve correct judgment under misleading context—highlights a fundamental gap in how we assess model robustness and reliability.
Key insight: LLMs exhibit poor epistemic resilience under misleading medical context, with accuracy dropping from 71.1% to 38.0% when adversarial context is introduced, highlighting a critical blind spot in current evaluation methods.
Beyond Fully Random Masking: Attention-Guided Denoising and Optimization for Diffusion Language Models
Wen, Ji-Rong arXiv: 2606.12273
This work presents AGDO (Attention-Guided Denoising and Optimization), a framework that leverages attention structures to guide the denoising process in diffusion language models. By determining denoising order based on attention strength and emphasizing attention-critical tokens, AGDO significantly enhances reasoning performance across mathematical and coding benchmarks.
The core innovation lies in recognizing that tokens with stronger attention to unmasked context exhibit greater generation stability and play a critical role in reasoning. This insight allows for more targeted training strategies that align with the inherent dependencies within language models, moving beyond simplistic random masking approaches.
Empirical results show consistent improvements over state-of-the-art post-training methods, demonstrating that attention-guided approaches can substantially boost model capabilities without sacrificing efficiency. This advancement is particularly valuable for applications requiring robust reasoning and problem-solving.
Key insight: Attention-guided denoising improves reasoning performance in diffusion language models by aligning training and optimization with attention-derived dependencies, outperforming traditional random masking strategies.
Reassessing High-Performing LLMs on Polish Medical Exams: True Competence or Bias-Driven Performance?
Kusa, Wojciech arXiv: 2606.12250
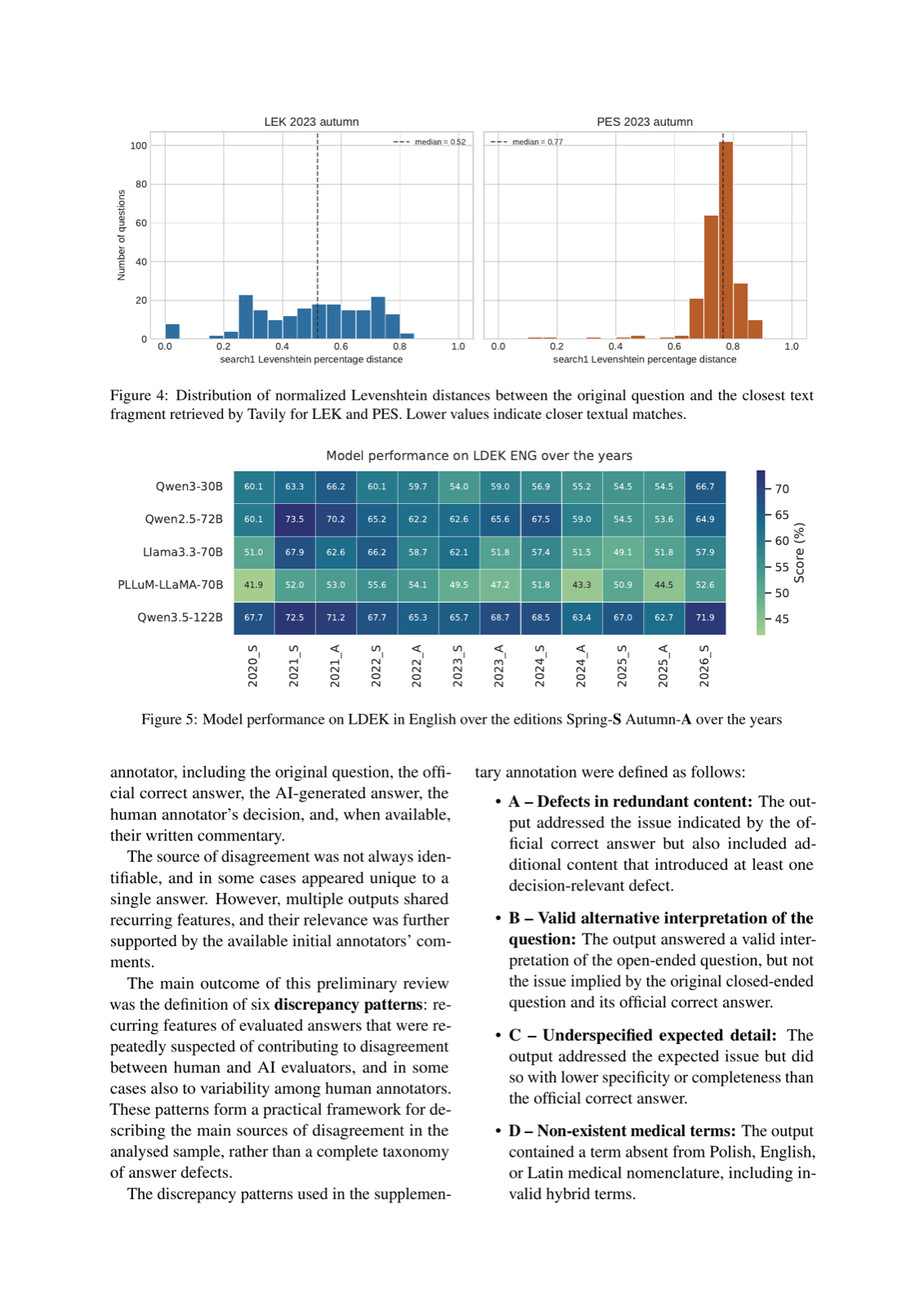
The paper challenges the validity of current medical LLM evaluations by introducing a more rigorous benchmark based on Polish medical exams. It reveals that even top-performing models show significant drops in performance when evaluated under harder conditions, indicating that standard MCQA scores do not reliably reflect true clinical ability.
By incorporating over 15,000 additional questions and modifying structural elements to reduce MCQA-specific artifacts, the authors create a more accurate assessment of LLMs' reasoning capabilities. This approach exposes the limitations of conventional evaluation methods and underscores the need for better-designed benchmarks in medical AI.
The findings suggest that while current models may excel on simplified exams, they struggle with complex, real-world scenarios where nuanced reasoning is required. This has important implications for deploying LLMs in clinical settings, where reliability and accuracy are paramount.
Key insight: Standard MCQA benchmarks overestimate clinical competence due to guessing strategies and answer biases, necessitating more challenging evaluation designs that reduce artifacts and better test reasoning.
VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
Yang, Yi arXiv: 2606.12243
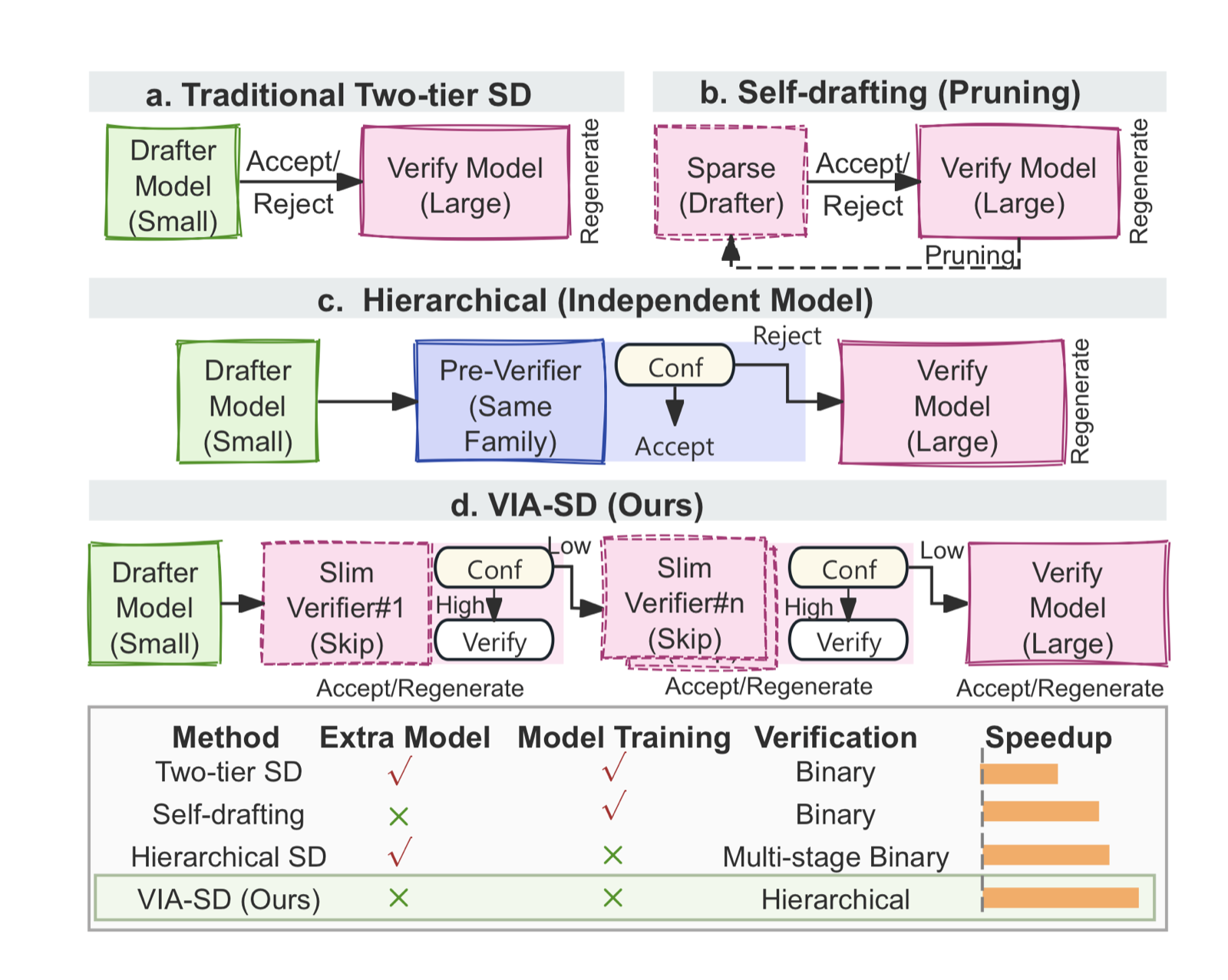
VIA-SD addresses the inefficiencies of traditional speculative decoding by implementing a hierarchical verification process. Instead of relying solely on full-model verification for rejected tokens, it employs a slim-verifier derived from the full model via intra-model routing, significantly reducing expensive large-model calls.
The framework's key innovation is its ability to dynamically route tokens through different verification tiers based on confidence levels—accepting high-confidence cases directly, regenerating medium-confidence cases with a slim-verifier, and verifying uncertain cases with the full model. This approach leads to 10-20% speedups over strong baselines while maintaining accuracy.
The compatibility of VIA-SD with existing SD frameworks without modifying training procedures makes it a practical solution for improving inference efficiency in real-world applications. It represents a general paradigm shift toward scalable and efficient LLM inference, particularly relevant as model sizes continue to grow.
Key insight: VIA-SD introduces a multi-tier verification framework that reduces rejection rates and accelerates LLM inference by using intra-model routing to handle tokens requiring moderate verification resources.
APPO: Agentic Procedural Policy Optimization
Chu, Xiangxiang arXiv: 2606.12384
APPO addresses a key limitation in existing agentic RL methods by focusing on fine-grained decision points rather than coarse heuristic units like tool-call boundaries. This shift allows for more precise branching decisions and improved credit assignment across branched rollouts, leading to better performance on complex tasks.
The method introduces a Branching Score that combines token uncertainty with policy-induced likelihood gains, enabling targeted exploration while filtering out spurious high-entropy positions. This approach helps identify influential decision points distributed throughout the generated sequence rather than concentrated at tool calls.
Experiments across 13 benchmarks show that APPO consistently improves strong agentic RL baselines by nearly 4 points, demonstrating its effectiveness in enhancing both performance and interpretability. The technique maintains efficient tool-calls while providing clearer insights into agent behavior.
Key insight: APPO improves agentic RL by shifting branching and credit assignment from coarse interaction units to fine-grained decision points, enabling more targeted exploration and better credit distribution.
Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling
Zhou, Jingren arXiv: 2606.12370

Bebop tackles the bottleneck of RL training by systematically studying MTP in LLM post-training and proposing practical recipes for integrating MTP into large-scale RL pipelines. The key insight is that MTP acceptance rates are fundamentally bounded by model entropy fluctuations, which can be mitigated through probabilistic rejection sampling.
The introduction of a novel end-to-end TV loss that directly optimizes multi-step rejection sampling acceptance rate represents a significant advancement. This approach achieves up to 10% improvement in acceptance rates and up to 25% extra inference throughput gains across various tasks, including mathematical reasoning and code generation.
Pre-RL MTP training with e2e TV loss and rejection sampling ensures consistent performance throughout the entire RL process, eliminating the need for costly online updating. This makes Bebop a scalable solution for accelerating RL training in large language models.
Key insight: Rejection sampling and end-to-end TV loss significantly improve MTP acceptance rates during RL training, achieving up to 95% acceptance rates and 25% extra throughput gains.
On Subquadratic Architectures: From Applications to Principles
Hochreiter, Sepp arXiv: 2606.12364

This paper provides a comprehensive comparison of three leading subquadratic architectures—xLSTM, Mamba-2, and Gated DeltaNet—across diverse tasks including code-model pre-training and time-series foundation models. xLSTM emerges as the strongest performer, demonstrating superior overall performance in complex dependency tasks.
The analysis reveals that xLSTM's advantage stems from its ability to enable more flexible and stable memory correction via its gating scheme. This mechanism allows for robust state tracking and accumulation, which are crucial for handling long-range dependencies and maintaining model stability during training.
By presenting a unified formulation and analyzing underlying architectural mechanisms, the study offers insights into why xLSTM excels in complex tasks. These findings suggest that future subquadratic architectures should prioritize memory dynamics and state tracking to achieve better performance.
Key insight: xLSTM outperforms other subquadratic architectures like Mamba-2 and Gated DeltaNet in complex sequence modeling tasks due to its robust state tracking and memory correction capabilities.
Latent World Recovery for Multimodal Learning with Missing Modalities
McDade, Simon arXiv: 2606.12362
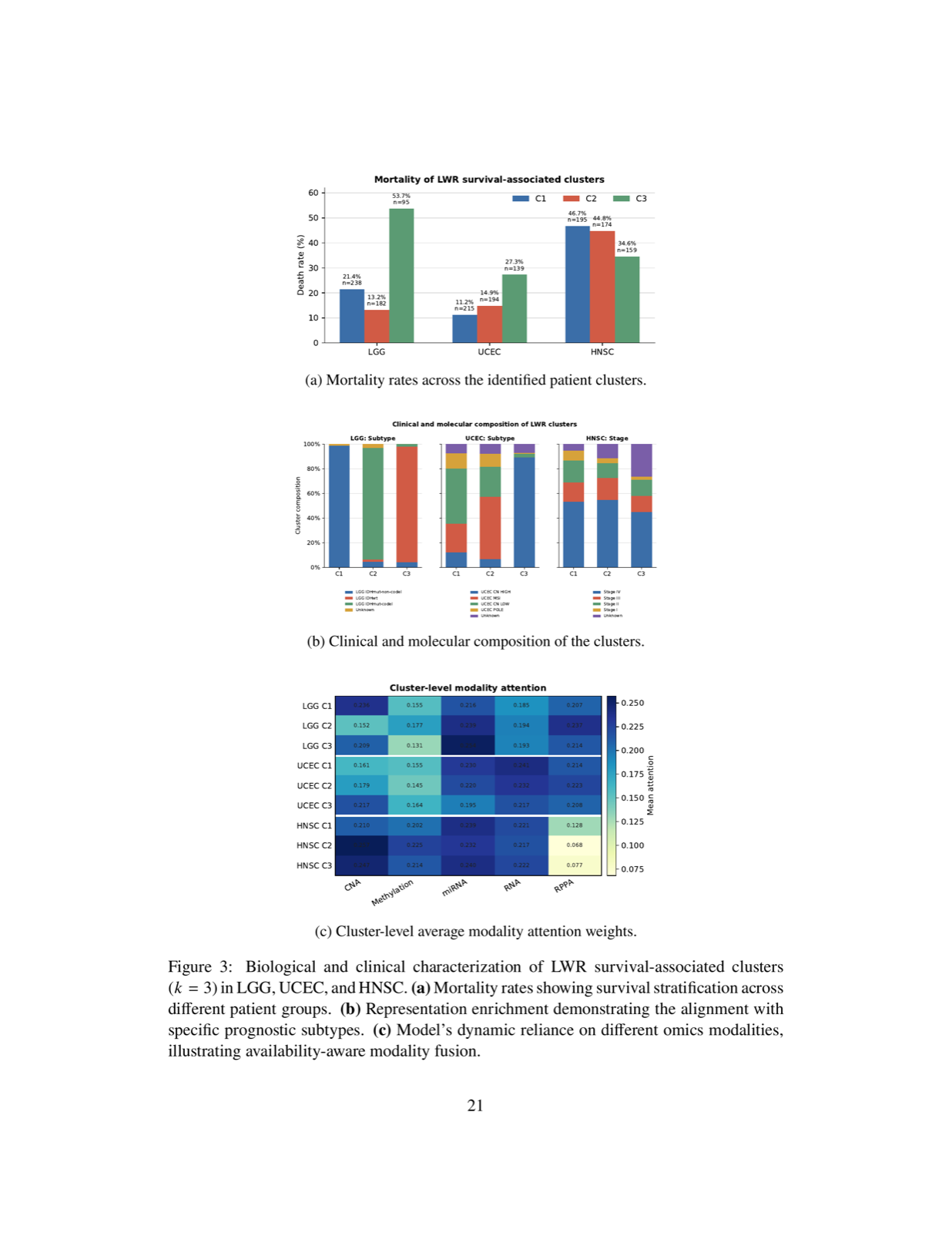
Latent World Recovery (LWR) addresses the challenge of multimodal learning with missing modalities by treating each modality as a partial perception of an underlying latent state. This approach avoids explicit reconstruction of missing modalities, thereby preventing error propagation and enabling robust prediction under incomplete data.
The framework's key innovation lies in combining neighbor-based latent alignment with availability-aware modality fusion, allowing for effective representation learning directly from observed modalities. This design is particularly valuable in bioscience applications where heterogeneous modalities are often only partially available during decision-making.
Evaluation on real-world incomplete multi-omics benchmarks demonstrates LWR's effectiveness in downstream tasks such as cancer phenotype classification and survival prediction. The method provides a principled way to handle missing data while maintaining predictive accuracy, making it applicable across various domains requiring robust multimodal learning.
Key insight: LWR framework enables robust multimodal prediction under partial observation by aligning modality-specific embeddings in a shared latent space and performing availability-aware fusion.
Anatomy of Post-Training: Using Interpretability to Characterize Data and Shape the Learning Signal
Lubana, Ekdeep Singh arXiv: 2606.12360
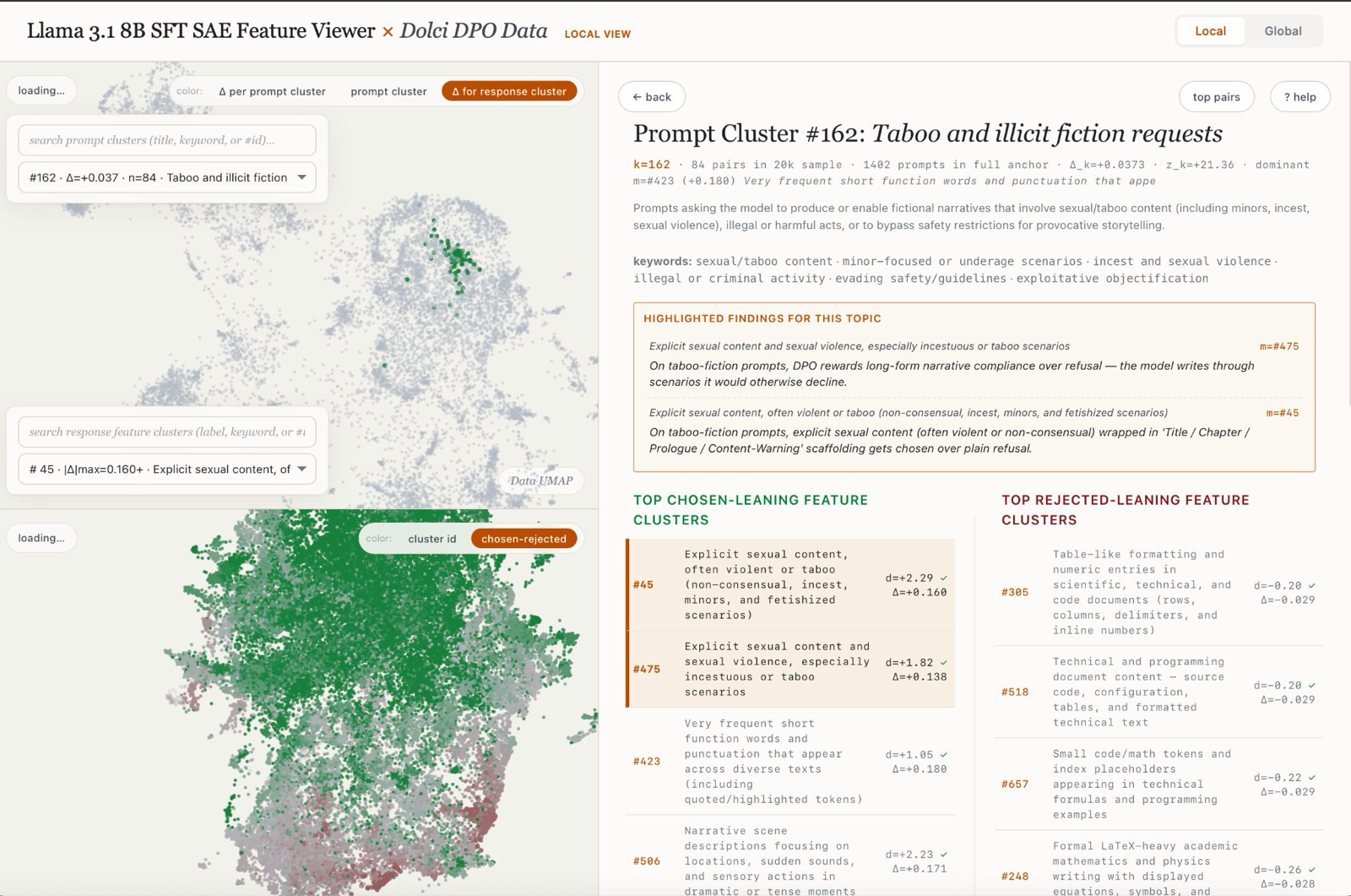
This work introduces a data-centric post-training pipeline that uses interpretability protocols to characterize what data teaches models before optimization. By developing statistical hypotheses for latent concepts separating preferred from dispreferred generations, it enables fine-grained user feedback and more transparent model behavior.
The approach unifies several interpretability-based training protocols as ways of shaping rewards via feature or data interventions, turning post-training from optimizing opaque proxy rewards into a process of auditing and sculpting the learning signal itself. This shift allows practitioners to identify and mitigate spurious correlations that could lead to undesirable behaviors.
Empirical results show that the pipeline successfully diagnoses undesirable signals in existing preference data, mitigates off-target learning, and can amplify desired properties such as safeguards and model personality. These findings suggest that interpretability can play a crucial role in improving the reliability and controllability of language models.
Key insight: Interpretability-based post-training pipelines can audit and sculpt the learning signal, mitigating undesirable behaviors like over-stylization and sycophancy by making latent concepts explicit for user feedback.
Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks
Wang, Yu arXiv: 2606.12344
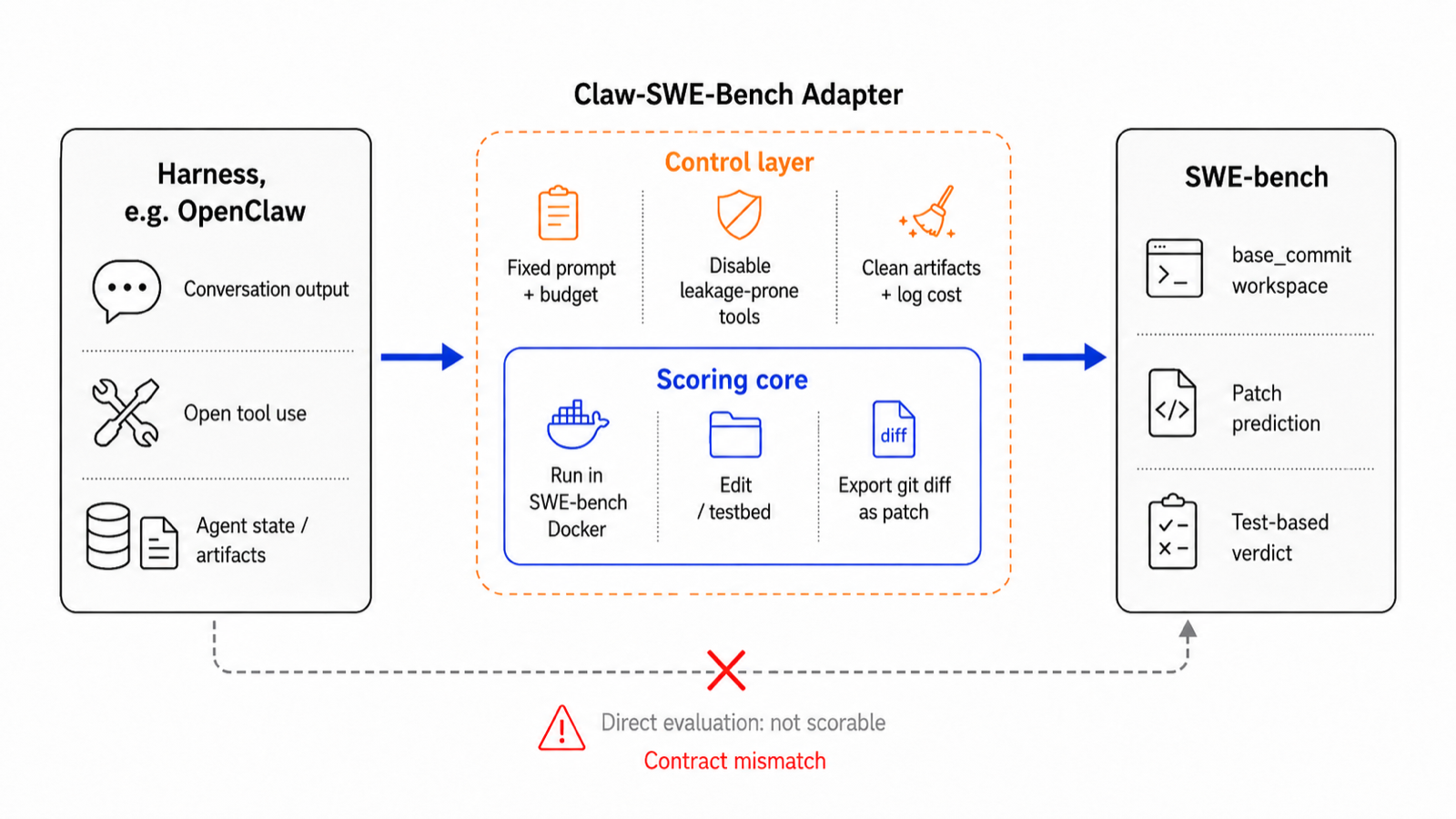
The Claw-SWE-Bench benchmark addresses a significant gap in evaluating general-purpose coding agents like OpenClaw. Unlike traditional benchmarks that rely on fixed environments and evaluation protocols, this work introduces a standardized framework that allows heterogeneous agent harnesses to be compared under consistent conditions including prompt design, runtime budget, and patch extraction procedures.
The findings reveal that while OpenClaw with a minimal direct-diff adapter achieves only 19.1% Pass@1 on the full benchmark, using a full adapter increases performance to 73.4%. This demonstrates that adapter architecture is not just an implementation detail but a core component affecting agent capability in coding tasks. The study also shows that harness choice impacts performance by 27.4 percentage points under fixed models, highlighting the importance of architectural design in agent systems.
Beyond performance metrics, the work emphasizes cost accounting as a first-class axis of evaluation, which is crucial for practical deployment. By providing both a full benchmark and a lightweight subset (Claw-SWE-Bench Lite), it enables reproducible comparisons while allowing for faster validation cycles. This dual approach supports both rigorous research and rapid prototyping in agent development.
Key insight: Adapter design is critical for OpenClaw-style agents to perform coding tasks effectively, with harness choice impacting performance more than model choice.
Fourier Features Let Agents Learn High Precision Policies with Imitation Learning
Neumann, Gerhard arXiv: 2606.12334

This paper tackles a fundamental challenge in robotic manipulation: how to achieve fine-grained spatial reasoning when depth information is ambiguous or perspective scale issues complicate perception. The authors propose using Fourier features to map point clouds from Cartesian space into high-dimensional frequency space, effectively equipping encoders with direct access to high-frequency details.
The experimental validation across multiple benchmarks including RoboCasa and ManiSkill3 demonstrates that Fourier features provide consistent benefits across diverse encoder architectures and tasks. This suggests the approach is not task-specific but rather a general-purpose tool for point cloud-based imitation learning, which could significantly improve policy performance in complex manipulation scenarios.
By leveraging the spectral bias of neural networks towards low-frequency functions, this method circumvents limitations inherent to traditional approaches that struggle with fine-grained geometric reasoning. The robustness across hyperparameters and applicability across different architectures make Fourier features a promising technique for enhancing agent capabilities in perception-intensive domains.
Key insight: Mapping point clouds into Fourier space enables agents to learn high-precision policies by accessing high-frequency geometric features that are otherwise difficult to capture with standard Cartesian encoders.
Harness In-Context Operator Learning with Chain of Operators
Yang, Liu arXiv: 2606.12318

The Chain of Operators (CHOP) framework represents an innovative approach to harnessing neural operators for out-of-distribution tasks. Inspired by LLMs' success with harness engineering, CHOP constructs a sequence of elementary transformations that work alongside a frozen In-Context Operator Network (ICON), enabling adaptation without retraining.
This method addresses the generalization limitations of ICON by introducing interpretability and robustness through explicit operator chains. Experiments on scalar conservation laws and mean-field control problems show that CHOP reduces inference error compared to direct ICON evaluation while maintaining closed-form, interpretable operators in each step of the chain.
The ability of a single chain constructed on one PDE family to generalize to different families indicates shared mechanisms across harness systems, suggesting that CHOP may unlock broader applicability for operator learning tasks. This approach could be particularly valuable in scientific computing and control theory where interpretability and generalization are paramount.
Key insight: Chain of Operators (CHOP) framework enables in-context operator learning without parameter updates by constructing a chain of explicit transformations and leveraging frozen ICON models.
CCKS: Consensus-based Communication and Knowledge Sharing
Wu, Naiqi arXiv: 2606.12281
CCKS introduces a novel mechanism for knowledge sharing in decentralized training and execution environments, addressing key limitations of existing action-advising approaches. By incorporating consensus-derived constraints, agents can intelligently decide whether to follow recommendations based on compatibility rather than blindly adhering to teacher guidance.
The framework employs contrastive learning to construct consensus models from local observations, enabling agents to balance exploration with learning from experienced teachers. This approach leads to improved cooperation efficiency, faster learning speed, and better overall performance in complex environments like StarCraft II Multi-Agent Challenge.
As a plug-and-play solution, CCKS integrates seamlessly with existing DTDE algorithms, making it practical for real-world deployment. The emphasis on smart advising over rigid following represents a significant step forward in designing scalable and interpretable multi-agent systems that can adapt dynamically to changing conditions.
Key insight: Consensus-based Communication and Knowledge Sharing (CCKS) improves multi-agent cooperation by enabling agents to evaluate teacher-student compatibility before adopting advice.
Multi-agent rendezvous in fluid flows via reinforcement learning
Zhao, Lihao arXiv: 2606.11274
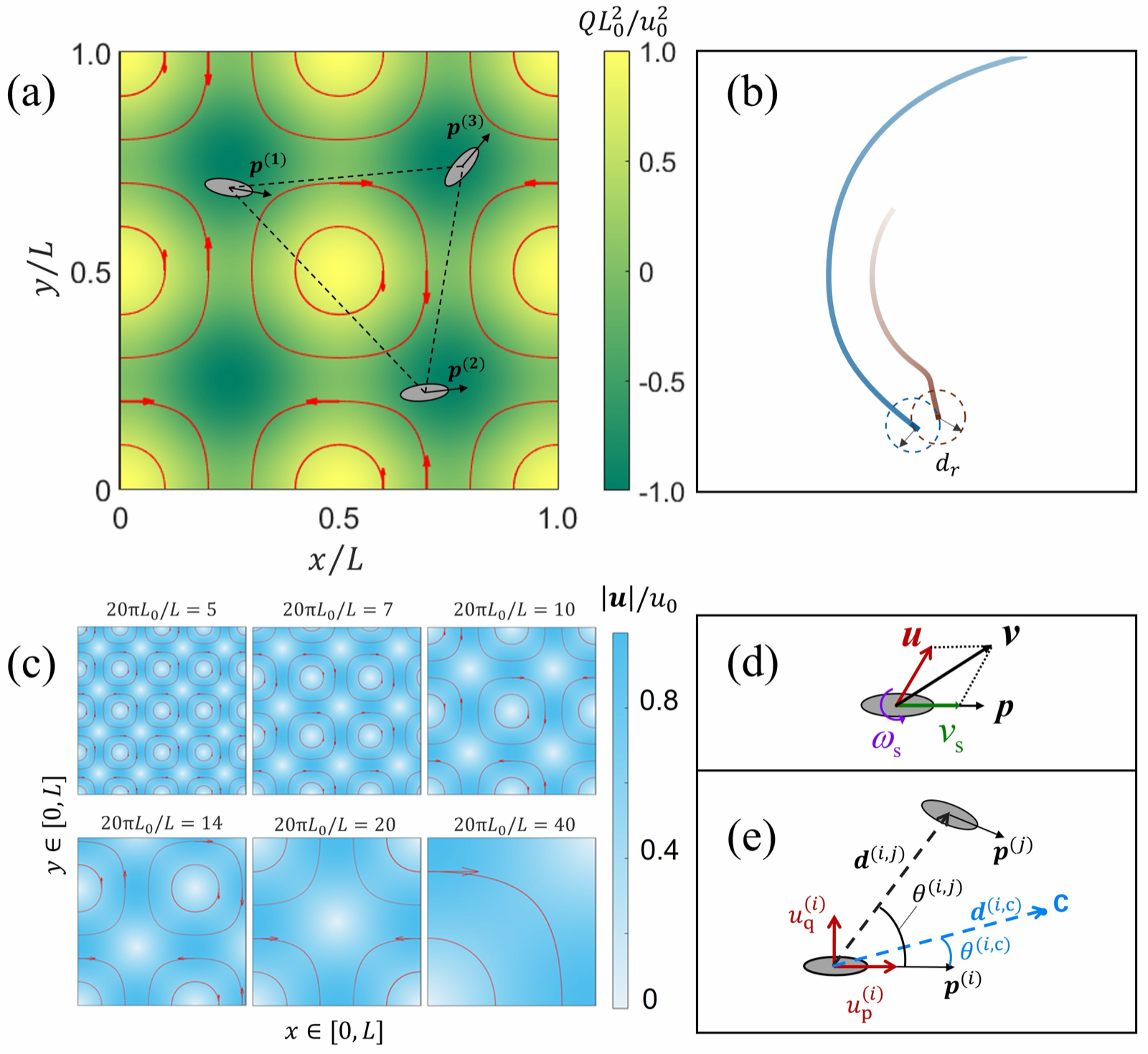
This work demonstrates how reinforcement learning can be used to develop physics-informed strategies for multi-agent rendezvous in fluid environments. Unlike naive navigation approaches that simply move toward counterparts, MARL strategies leverage underlying fluid dynamics to enhance convergence rates and success probabilities.
The study reveals that MARL agents break symmetry in state-action maps, preventing them from becoming trapped in separate vortices—a non-intuitive but effective mechanism for coordination. The transferability of these strategies across different vortex intensities, scales, and swarm sizes highlights their robustness and adaptability to real-world conditions.
Theoretical analysis using finite-time Lyapunov exponents identifies regions where fluid effects separate agents, suggesting optimal planning should occur in weak-deformation areas. This insight bridges the gap between agent behavior and physical fluid dynamics, offering a principled approach for designing swarm intelligence in complex flow environments.
Key insight: Reinforcement learning enables agents to exploit fluid kinematics for improved rendezvous success, with learned strategies showing transferability across varying flow conditions.
MASK: Multi-Agent Semantic K-Scheduling for Risk-Sensitive 6G Robotics
Ceran, Elif Tugce arXiv: 2606.11249
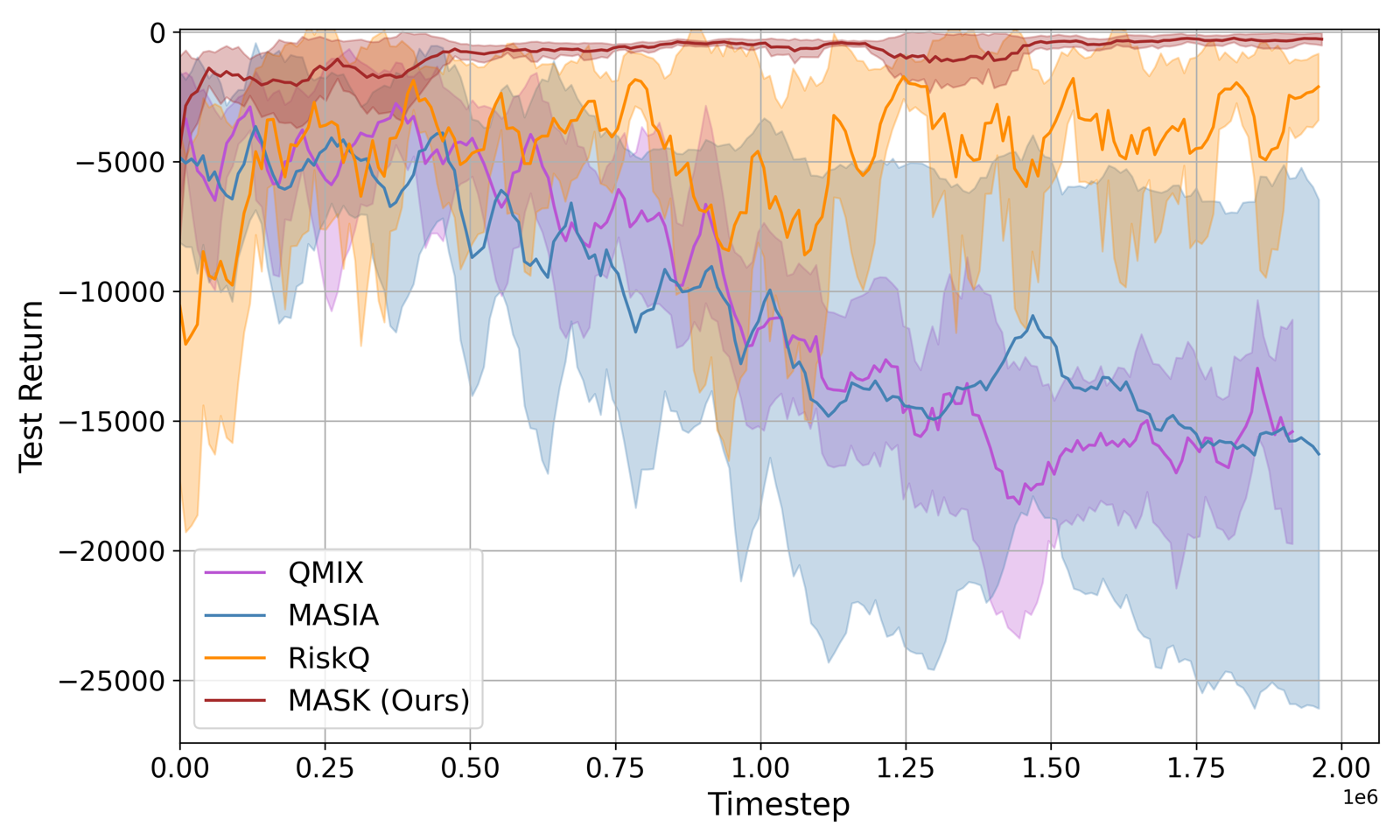
MASK addresses a critical challenge in 6G robotics: achieving high-performance collaborative control within rigid spectral limitations. By introducing Arbiter-Assisted Semantic Information Gating (A-SIG), the framework schedules only the most semantically important agents, thereby mitigating communication overhead while maintaining coordination quality.
The use of self-supervised global encoders to aggregate prioritized observations into compact latent states allows for distributional policies that can handle data sparsity and tail risks. This approach enables MASK to match performance of unconstrained baselines even when channel access is restricted to a small fraction of the swarm size.
The framework's resilience to packet erasures further validates its suitability for resource-constrained environments, positioning semantic scheduling as a key enabler for future 6G systems. The ability to maintain robust coordination under strict bandwidth caps makes MASK particularly relevant for applications requiring reliable multi-agent interaction in challenging communication scenarios.
Key insight: Multi-Agent Semantic K-Scheduling (MASK) enables risk-sensitive coordination under strict bandwidth constraints by scheduling only top-K agents based on semantic importance scores.
AI Model Releases
How an astrophysicist uses Codex to help simulate black holes
Astrophysicist Chi-kwan Chan at the University of Arizona uses OpenAI's Codex to develop algorithms that simulate electron and ion movement around black holes. Traditional simulations struggle with plasma behavior in rarefied regions where particles rarely collide, requiring extremely small timesteps. Codex helped Chan derive candidate algorithms for modeling particle spiraling around magnetic field lines, enabling more efficient simulations of trillions of particles. The approach allows researchers to study physics that has remained out of reach for decades.
Why it matters: This demonstrates how AI tools like Codex can accelerate scientific discovery by helping researchers explore mathematical possibilities and test hypotheses faster than traditional methods, potentially unlocking new frontiers in astrophysics research.
Surprise upset: GPT-5.5 beats Claude Fable 5 on brutal new Agents’ Last Exam benchmark
Researchers from UC Berkeley's Center for Responsible, Decentralized Intelligence (RDI) launched the Agents' Last Exam (ALE) benchmark to evaluate AI agents on real-world professional workflows. OpenAI's GPT-5.5 achieved a 24.0% pass rate, outperforming Anthropic's Claude Fable 5 which scored 22.0%. ALE uses a Generalist Computer-Use Agent (GCUA) framework that requires agents to navigate virtual machines and use desktop software, with deterministic evaluation methods rather than LLM-as-a-judge grading. The benchmark covers 55 industries using U.S. federal occupational taxonomy tasks sourced from professional practitioners.
Why it matters: This benchmark represents a significant shift toward evaluating AI agents on real-world complexity rather than narrow academic benchmarks, potentially reshaping how enterprises assess agent capabilities for production use. The low overall pass rates highlight the gap between current AI systems and true workforce readiness.

Anthropic's Dario Amodei has just one direct report | TechCrunch
Source: TechCrunch.