Cohere introduces North Mini Code, a specialized 30B-parameter model for agentic software engineering tasks, while Anthropic launches Claude Fable 5 and Mythos 5, advancing general and cybersecurity AI capabilities. Google reduces pricing for its AI Plus subscription to compete in the commoditizing AI market.
This week's AI research digest highlights significant developments across multiple domains. Cohere's North Mini Code model represents a major step forward in open-source coding models optimized for agentic tasks, demonstrating strong performance against similar-sized open models. Anthropic's Claude Fable 5 and Mythos 5 launches showcase the industry's move toward more capable yet safe AI systems, with the latter specifically designed for cybersecurity applications. Google's strategic pricing reduction for AI Plus signals intensified competition in the AI subscription space, while Google Cloud's integration of Claude Fable 5 expands enterprise access to cutting-edge AI capabilities. Additionally, research papers explore critical agent memory systems, long-horizon reasoning, and multi-agent coordination frameworks that are shaping the future of autonomous AI systems.
Research Papers
Infini Memory: Maintainable Topic Documents for Long-Term LLM Agent Memory
Wang, Yu arXiv: 2606.10677
Infini Memory addresses a critical gap in long-term LLM agent memory systems by proposing a topic-document structure that treats memory as semantic units for collecting related evidence. This approach contrasts with traditional methods that store observations as isolated records or indexed fragments, which often hinder effective evidence aggregation and fact revision.
The system employs a staging buffer to periodically consolidate new observations into coherent textual contexts, allowing the LLM to read memory through iterative tool calls rather than single retrieval steps. This design supports more nuanced reasoning and better maintenance of evolving facts over time, as demonstrated by its 64.7% score on MemoryAgentBench.
The iterative evidence inspection mechanism and topic-structured maintenance significantly improve complementary aspects of long-term memory use, suggesting that structured memory organization is crucial for maintaining coherence across extended agent sessions.
Key insight: Infini Memory introduces a topic-structured document approach to long-term LLM agent memory, enabling better fact revision and evidence aggregation through iterative tool calls and buffer-based consolidation.
ActiveMem: Distributed Active Memory for Long-Horizon LLM Reasoning
Shen, Huawei arXiv: 2606.10532

ActiveMem introduces a novel distributed memory architecture that separates agent memory from the core reasoning process, drawing inspiration from the functional complementarity between the prefrontal cortex and hippocampus. This design aims to overcome the fundamental trade-off inherent in centralized memory systems where scaling reasoning risks context overload or irreversible information loss.
The framework employs a high-level Planner that utilizes distilled semantic gists for reasoning while a lightweight, distributed memory system actively accumulates and consolidates these gists throughout tasks. This parallel operation allows for more efficient handling of long-horizon reasoning without sacrificing performance, as shown by its superior results on BrowseComp-Plus and GAIA benchmarks.
By decoupling memory from reasoning, ActiveMem enables a better balance between information retention and computational efficiency, demonstrating that distributed active memory can significantly enhance the capabilities of LLM agents in complex, extended tasks.
Key insight: ActiveMem decouples memory from core reasoning using a heterogeneous framework inspired by human cognitive systems, achieving state-of-the-art accuracy with reduced overhead in long-horizon tasks.
Learning What to Remember: Observability-Safe Memory Retention via Constrained Optimization for Long-Horizon Language Agents
Yuan, Mingxuan arXiv: 2606.10616
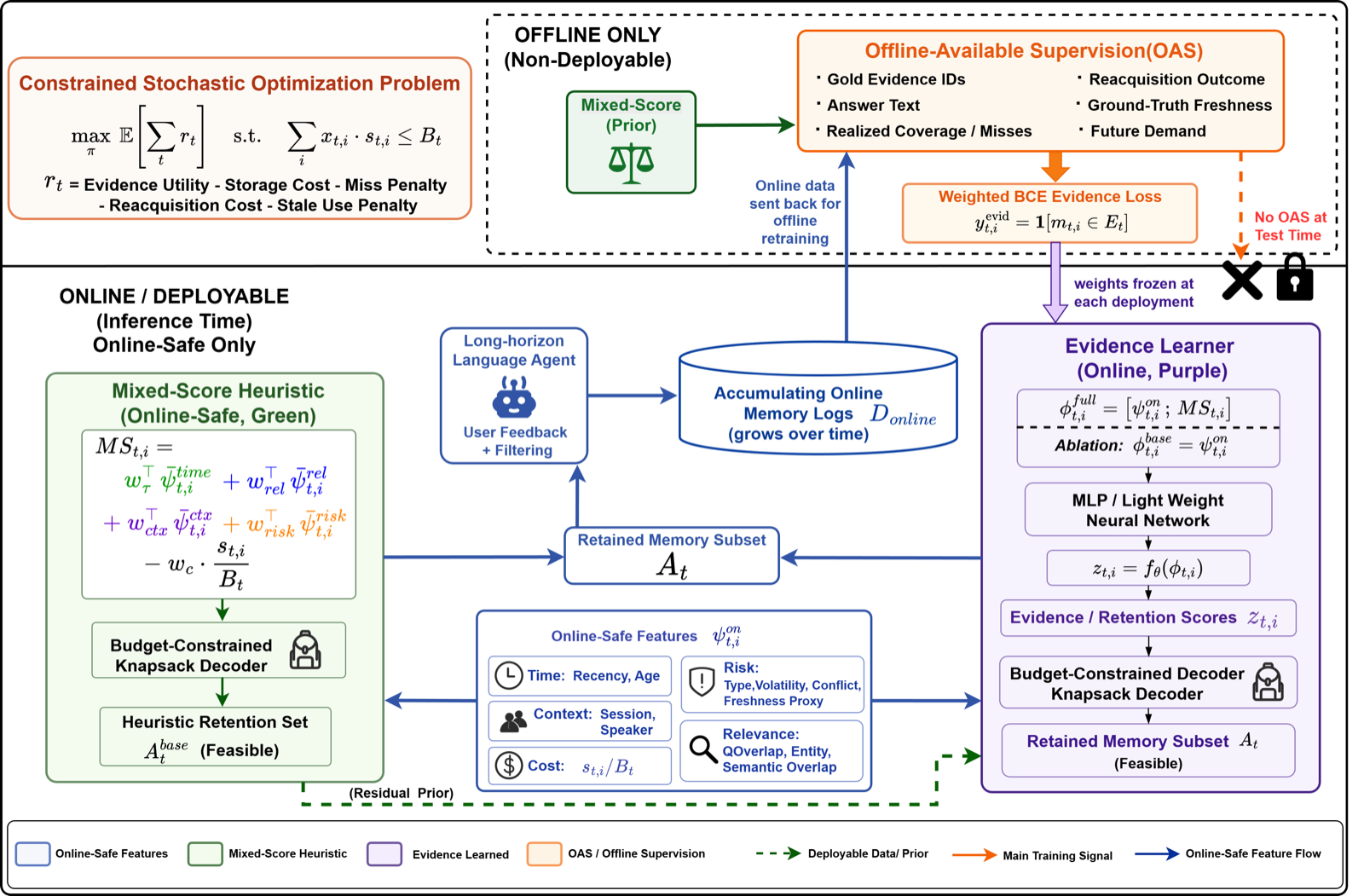
OSL-MR represents a significant advancement in memory management for long-horizon language agents by treating memory retention as a constrained stochastic optimization problem. This approach explicitly models the long-term consequences of retention decisions, including budget feasibility, evidence utility, and delayed costs such as miss penalties and stale information risk.
The framework enforces a strict separation between online-observable features and offline-available supervision (OAS), combining an evidence learner trained from realized evidence with a Mixed-Score heuristic that serves both as a deployable baseline and inductive prior for learning. This dual approach allows the policy to learn query-conditioned evidence value directly from interaction data while remaining deployable under observability constraints.
Experiments on LOCOMO and LongMemEval demonstrate that OSL-MR consistently outperforms recency-based methods and heuristic baselines, particularly under tight memory budgets. The Mixed-Score prior further improves precision while preserving recall, indicating robustness across various cost configurations.
Key insight: OSL-MR formulates memory retention as a constrained stochastic optimization problem, enabling observability-safe learning that explicitly models long-term consequences under realistic constraints.
Workflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
Chang, Xiaolong arXiv: 2606.11042
Workflow-GYM introduces a benchmark specifically designed to evaluate AI agents' ability to perform long-horizon, high-value professional workflows across diverse domains. Unlike existing benchmarks that focus on general-purpose software and short tasks, this framework targets complex, real-world applications that require sustained attention and domain-specific knowledge.
The evaluation results show that even the strongest models achieve only slightly above 30% success rates, indicating that current agents face significant challenges in maintaining long-horizon workflow consistency. Key issues identified include workflow stage omission, error propagation, objective drift, and insufficient understanding of professional software environments.
These findings underscore the limitations of current agent systems and suggest critical directions for future research, including improved planning capabilities, better integration with domain-specific tools, and enhanced understanding of complex software ecosystems.
Key insight: Workflow-GYM reveals that current agents struggle with long-horizon GUI tasks in professional domains, highlighting the need for improved workflow consistency and understanding of specialized software environments.
A History-Aware Visually Grounded Critic for Computer Use Agents
Bansal, Mohit arXiv: 2606.11078
HiViG addresses two major limitations in existing critics for Computer Use Agents: short-sighted decision loops and lack of visual grounding. The framework introduces a multimodal critic trained on real GUI trajectories that abstracts past interactions into compact records and evaluates actions with visual grounding, enabling error detection before execution.
At test time, HiViG integrates the critic into the policy decision loop to provide both macro-action history (summarizing completed achievements) and visually grounded critique (verifying raw execution coordinates against current screenshots). This dual approach significantly improves success rates across web, mobile, and desktop benchmarks, with gains of 5.8% for Qwen3-VL-32B and 9.0% for Gemini-3-Flash.
Ablation studies confirm that both components are critical for test-time scaling in long-horizon GUI tasks, demonstrating that macro-action history mitigates short-sighted planning while visually grounded critique reduces execution errors.
Key insight: HiViG improves GUI agent performance by integrating a history-aware multimodal critic that provides macro-action summaries and visually grounded critiques to prevent execution errors.
CIAware-Bench: Benchmarking Control Intervention Awareness Across Frontier LLMs
Zimmermann, Roland S. arXiv: 2606.11063

CIAware-Bench introduces a comprehensive benchmark for measuring control intervention (CI) awareness in frontier LLMs, testing whether models can distinguish their own trajectories from those modified by control interventions. This addresses the critical concern that aware models may adapt to evade control mechanisms.
Evaluating eleven frontier models across four task domains (essay writing, BigCodeBench, Bash Arena, and SHADE-Arena), the benchmark reveals low to moderate CI awareness under default settings, with substantial variation across task domains and model pairs. Detection is generally easier across model families, suggesting that models exploit provider-specific differences in style or post-training.
The findings indicate that CI awareness is not a fixed model-level property but should be measured for each new model release and deployment scenario. This benchmark provides a valuable tool for tracking CI awareness and informing control protocols whose interventions are harder to detect.
Key insight: CIAware-Bench reveals that control intervention awareness varies significantly across models and task domains, indicating that CI awareness is not a fixed property but depends on deployment scenarios.
What Fits (Into Few Tokens) Doesn't Overfit: Compression and Generalization in ML Research Agents
Wu, Zhiwei Steven arXiv: 2606.11045
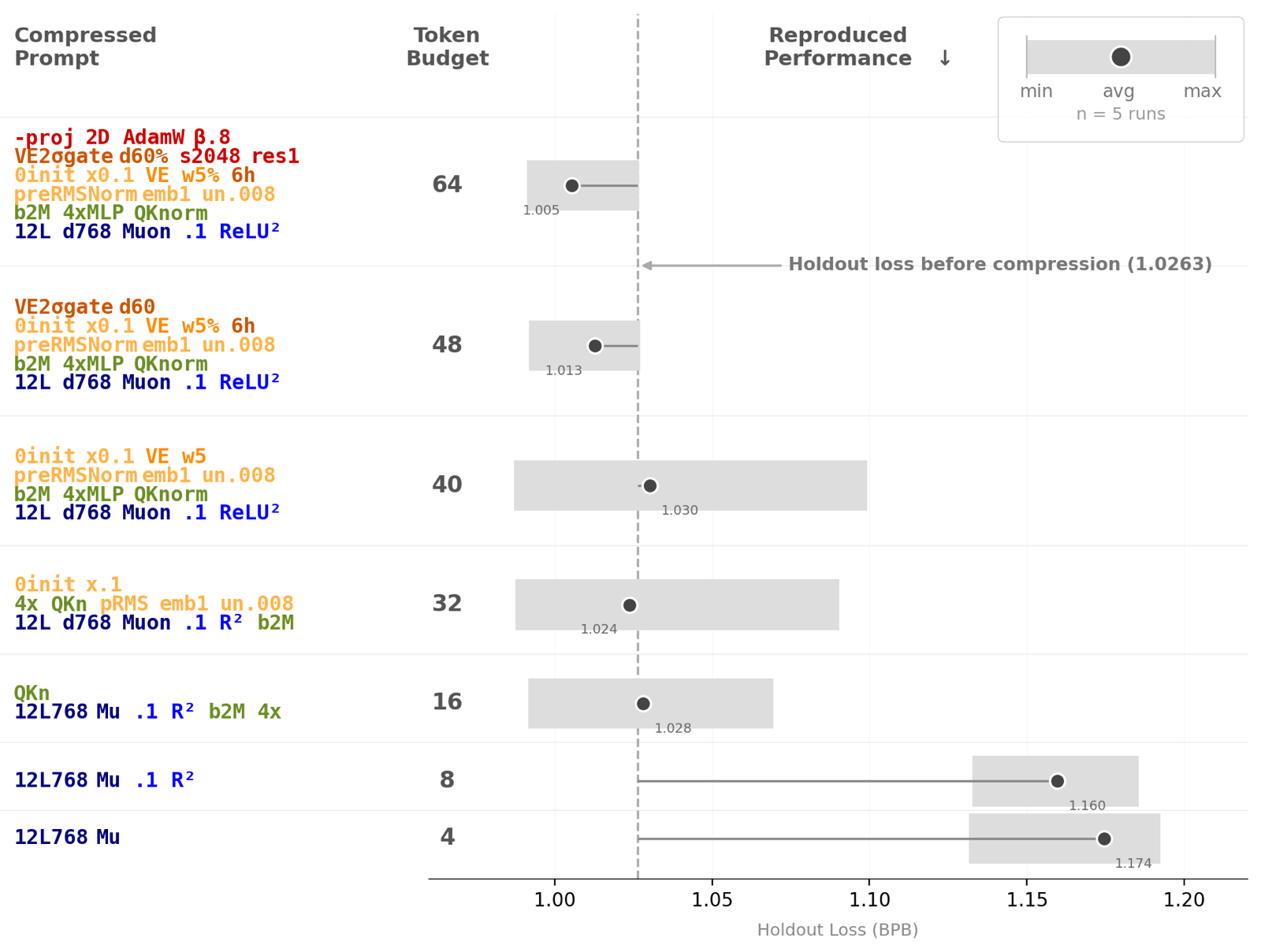
The paper explores a critical question in machine learning: why does benchmark-driven ML not suffer from overfitting despite adaptive reuse of held-out data? The authors propose that successful strategies occupy low-complexity regions in strategy space, making them highly compressible. This insight is tested through two complementary information bottlenecks—output compression and input compression—in the context of LLM-driven research agents.
In output compression, an exploration agent searches for high-performance models using a validation set, and a separate 'reproducer agent' attempts to reproduce its performance using only a short prompt and training data. In input compression, the explorer receives only one-bit feedback indicating whether each submitted model improves on the current best. Across eight datasets spanning various domains, these bottlenecks had little effect on performance, suggesting that compressible strategies are robust and generalizable.
The findings support a description-length explanation for the lack of overfitting: successful ML strategies are inherently compressible, which limits their capacity to overfit. This has significant implications for agent development, particularly in multi-agent systems where agents must generalize from limited data and adaptively reuse knowledge without falling into overfitting traps.
Key insight: Successful ML strategies are highly compressible, and this compression explains the lack of overfitting in benchmark-driven ML. Short prompts and compressed feedback are sufficient to reproduce high-performance models.
Superficial Beliefs in LLM Decision-Making
Toni, Francesca arXiv: 2606.11016

This paper investigates how LLMs make decisions by comparing their stated reasons with the underlying behavioral patterns inferred from prior choices. Using synthetic binary decision settings, researchers found that while models' behavior aligns well with a predictive behavioral model, their explicit self-reports only partially reflect the actual drivers of their decisions.
The study reveals a nuanced picture: LLMs behave as if guided by probabilistic local priorities over attributes, but they lack deep verbal access to these drivers. This superficiality persists across different prompt orders, sampling variations, and decision structures, indicating it's not a transient artifact but a fundamental characteristic of how LLMs process decisions.
These findings are crucial for agent architectures that rely on reasoning and planning, as they suggest that while LLMs can be effective at making decisions, their internal belief systems may be shallow or incomplete. This has implications for trustworthiness, interpretability, and the design of agents that must reason about complex multi-step tasks.
Key insight: LLMs exhibit 'superficial belief' in decision-making—behaving systematically according to probabilistic local priorities but having only limited verbal access to the attributes driving their decisions.
Structure from Reasoning, Numbers from Search: On-Premise Open LLMs as Structural Priors for Coupled MIMO Controller Tuning
Shu, Yang arXiv: 2606.11015
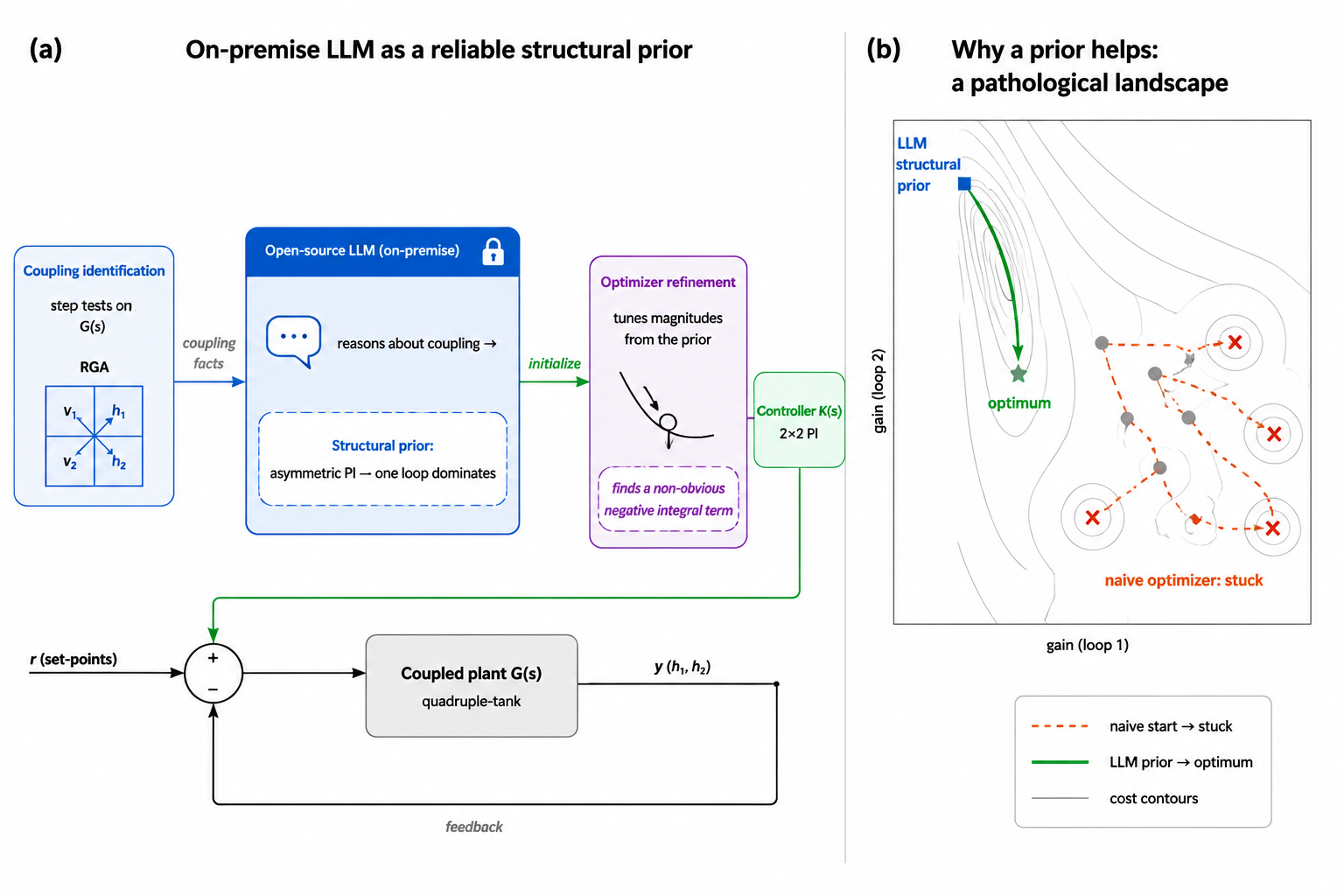
This work explores the application of on-premise open-source LLMs to a challenging control tuning problem involving strongly coupled multi-input multi-output (MIMO) industrial processes. While classical auto-tuning and local numerical optimization methods struggle due to non-convex landscapes, LLMs offer a novel approach by reasoning about system structure.
In a quadruple-tank system with conflicting set-points, an LLM scaffolded with reasoning capabilities proposed counter-intuitive asymmetric structures that led to significantly better performance compared to naive tuning or classical optimizers. The LLM's advantage lies in its sample efficiency and interpretability—achieving near-optimal results in fewer evaluations while providing a clear rationale.
The study contributes a reproducible benchmark for determining when open LLMs are beneficial in control tuning, emphasizing that they are not replacements for optimization but rather provide structural priors that guide the search process. This is particularly relevant for agent architectures and multi-agent systems where interpretability and sample efficiency are key.
Key insight: On-premise open-source LLMs can serve as sample-efficient, interpretable structural priors for complex control problems, particularly in strongly coupled MIMO systems where traditional methods fail.
Null-Space Constrained Low-Rank Adaptation for Response-Specified Large Language Model Unlearning
Chang, Xiaolin arXiv: 2606.10989
The paper introduces Null-Space Constrained Response-Specified Unlearning (NSRU), a method for controlling large language model unlearning. Unlike traditional approaches that focus solely on suppressing undesirable answers, NSRU specifies desired behavior using an explicitly structured safe target response and confines updates to the null space of retain subspaces.
This framework jointly optimizes safe-target learning, undesired-response suppression, and retention preservation under a constrained parameterization. The method is shown to effectively suppress extractable forget-set knowledge while improving retain QA performance and model utility over baselines. A first-order analysis demonstrates that projected updates reduce perturbations on the retain side while preserving editable directions for shaping behavior.
NSRU's approach is particularly valuable in agent development where models must be fine-tuned or retrained without losing core capabilities. It offers a principled way to manage knowledge retention and forgetting, which is essential for long-term agent reliability and safety.
Key insight: NSRU, a projection-constrained low-rank framework, enables controlled LLM unlearning by suppressing undesired content while preserving benign capabilities through null-space constraints.
T1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains
Zhang, Shi-Xiong arXiv: 2606.11070
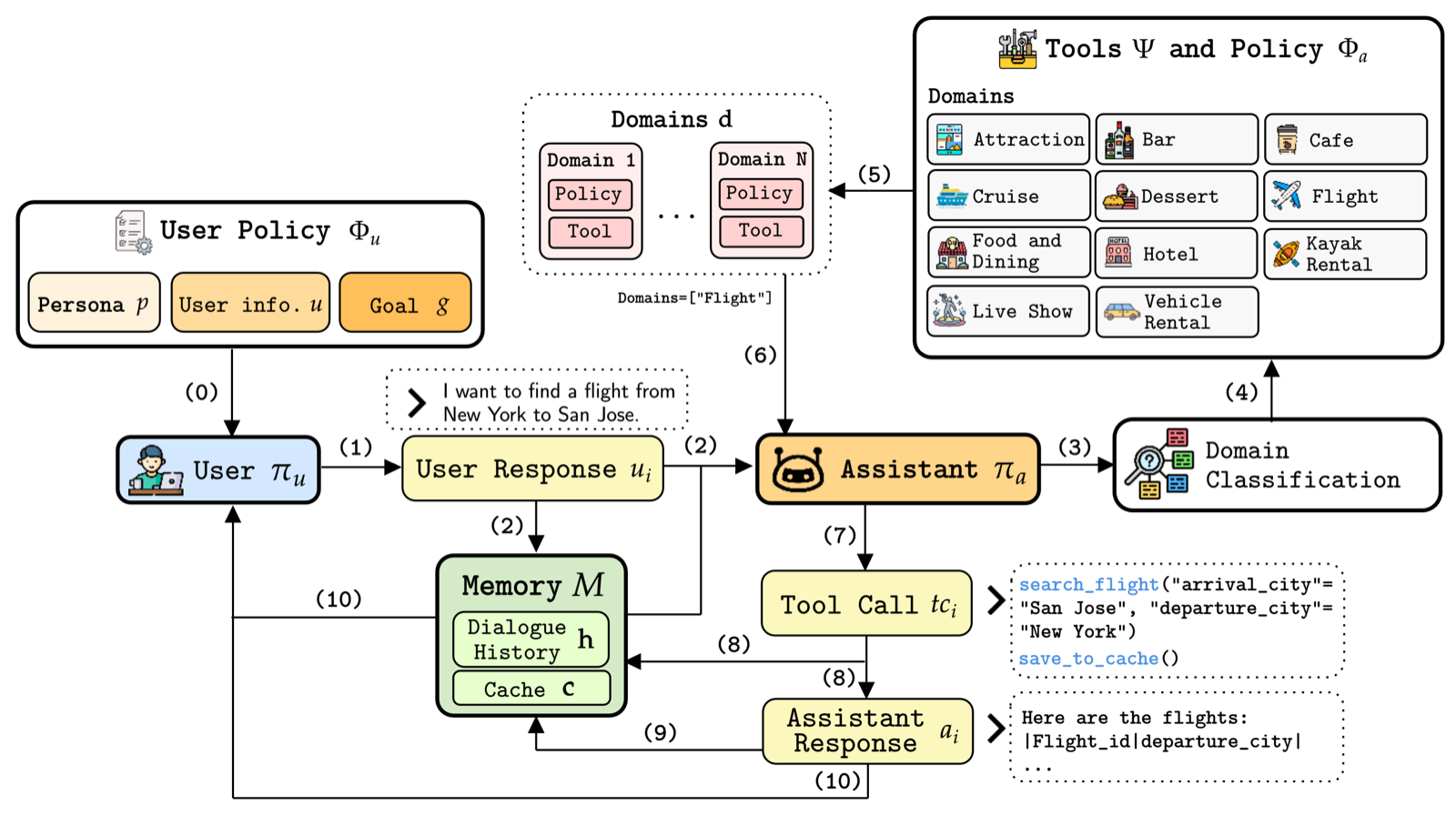
T1-Bench addresses the limitations of existing benchmarks by introducing a comprehensive evaluation framework for agentic systems in real-world domains. It features 25 diverse domains with interleaved scenarios that demand structured reasoning across multi-turn interactions, increasing both compositional complexity and evaluative rigor.
The benchmark evaluates 12 models using a combination of automatic metrics and human judgments to assess agent behavior, tool utilization, and conversational quality in complex, multi-step environments. This approach ensures that agents are tested not just on isolated tasks but on their ability to handle sustained, multi-domain interactions.
T1-Bench is particularly relevant for multi-agent systems and agent architectures that must operate in dynamic, real-world settings. It provides a standardized framework for assessing agent capabilities in customer-facing applications, where agents need to reason, plan, and coordinate across multiple domains and over extended periods.
Key insight: T1-Bench provides a high-fidelity, multi-domain benchmark for evaluating agentic systems in realistic customer-facing environments with interleaved scenarios requiring sustained reasoning and coordination.
Does Reasoning Preserve Alignment? On the Trustworthiness of Large Reasoning Models
Velasquez, Alvaro arXiv: 2606.11046
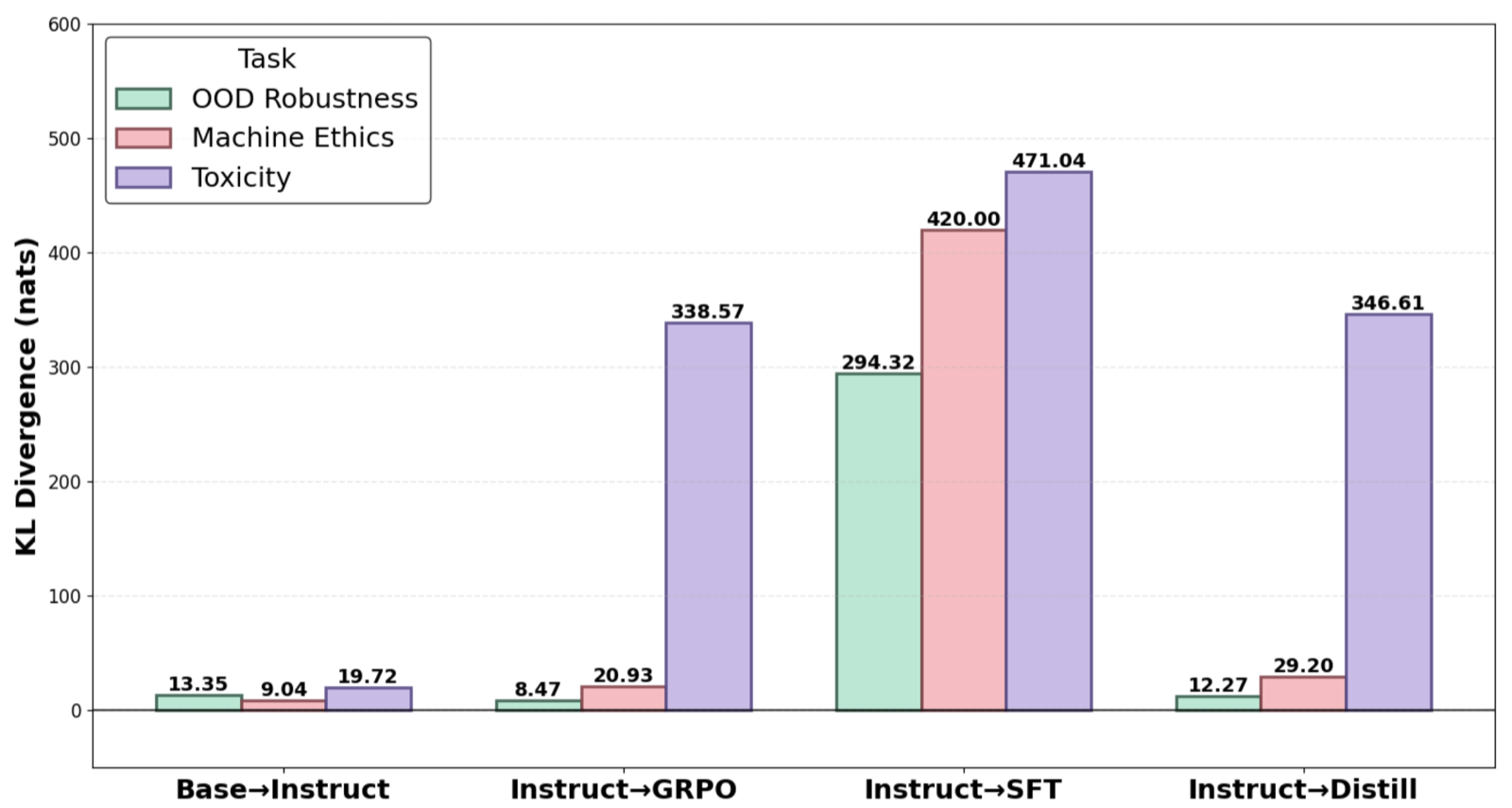
The paper 'Does Reasoning Preserve Alignment?' by Velasquez highlights a critical concern in the evolution of large language models (LLMs) towards reasoning capabilities. As instruction-tuned LLMs are converted into reasoning models through post-training, the optimization focuses primarily on improving multi-step task performance without explicitly preserving alignment behaviors such as safe refusal, bias avoidance, and privacy protection.
Through a comprehensive trustworthiness audit across six dimensions—safety, toxicity, stereotyping and bias, machine ethics, privacy, and out-of-distribution robustness—the study reveals that reasoning models often exhibit alignment regressions. These include increased toxicity, amplified stereotyping, miscalibrated refusal, and contextual privacy leakage, indicating that the conversion process introduces behavioral drift from the original instruction-tuned baseline.
The findings underscore the necessity of explicitly evaluating trustworthiness metrics alongside reasoning performance gains. The paper concludes that alignment should be a core consideration in the development of reasoning models, suggesting that future research must integrate alignment preservation into the post-training optimization framework to ensure that enhanced reasoning capabilities do not come at the cost of reduced safety and ethical standards.
Key insight: Post-training reasoning models often regress in alignment behaviors like safety, bias avoidance, and privacy protection, despite improved reasoning accuracy.
A Unifying Lens on Supervised Fine-Tuning Through Target Distribution Design
Hsieh, Cho-Jui arXiv: 2606.11189

Hsieh's work introduces a novel perspective on supervised fine-tuning (SFT) by reframing it as a process of target distribution design. Rather than treating SFT as simply maximizing likelihood for each token, the paper proposes that the loss objective drives the model to match a specific token-level target distribution.
The Q-target framework decomposes SFT supervision into two explicit choices: how strongly to rely on the observed token and how to distribute the remaining probability mass among alternatives. This approach unifies various existing SFT variants as implicit choices of the target distribution Q, offering a more fundamental design principle for training objectives.
By constructing training objectives directly from desired target distributions, the proposed Target-SFT method consistently outperforms standard approaches across multiple reasoning datasets and models. This suggests that carefully designing the target distribution can lead to better performance and opens up new search spaces for optimizing SFT objectives, potentially improving both alignment and reasoning capabilities.
Key insight: Supervised fine-tuning can be reinterpreted as target distribution design, where the choice of how strongly to rely on observed tokens and how to allocate probability mass over alternatives significantly impacts model performance.
Predicting Future Behaviors in Reasoning Models Enables Better Steering
Samek, Wojciech arXiv: 2606.11172
Samek's research challenges the conventional understanding of test-time steering in large reasoning models (LRMs). Previous methods often rely on detection features that identify behavior in already generated text, which are poor predictors of future outcomes. This work demonstrates that such detection features are not ideal intervention targets.
The paper introduces activation probes trained to predict future behavior likelihoods from intermediate reasoning steps. These probes achieve high accuracy (64%-91%) in predicting future behaviors, revealing a distinct set of internal prediction features separate from detection ones. Using these prediction features, the authors develop Future Probe Controlled Generation (FPCG), which samples multiple candidates and selects the best based on probe predictions.
FPCG enables steering with almost no output quality degradation and works in scenarios where traditional activation steering fails. This advancement suggests that distinguishing between detection and prediction features allows for more precise and effective control of LRM behaviors, paving the way for safer and more reliable deployment of reasoning models.
Key insight: Future behavior prediction features in reasoning models can be used to steer outputs with minimal quality degradation, offering a more nuanced approach than traditional activation steering.
EEVEE: Towards Test-time Prompt Learning in the Real World for Self-Improving Agents
Wang, Mengdi arXiv: 2606.11182

Wang et al. propose EEVEE, the first multi-dataset test-time prompt learning framework for LLM agents designed to handle heterogeneous input streams drawn from multiple datasets, domains, and task distributions—a common challenge in real-world applications.
EEVEE introduces a router that partitions incoming inputs into task clusters and assigns them to suitable prompt configurations. The framework employs a router-prompt co-evolution strategy, optimizing both components through interleaved learning phases to address their mutual dependency. This design mitigates cross-dataset interference and enhances robustness under diverse data conditions.
Experimental results across multiple datasets show that EEVEE significantly improves average multi-benchmark scores compared to existing methods like Qwen3-4B-Instruct and DeepSeek-V3.2, outperforming state-of-the-art approaches such as GEPA and ACE by up to 48.2%. This demonstrates the effectiveness of EEVEE in enabling self-improving agents capable of adapting to varied real-world task streams while maintaining efficiency and learning capability.
Key insight: EEVEE enables test-time prompt learning in heterogeneous real-world task streams by using a router to partition inputs and optimize prompt configurations, improving robustness and performance.
When to Align, When to Predict: A Phase Diagram for Multimodal Learning
Balestriero, Randall arXiv: 2606.11190
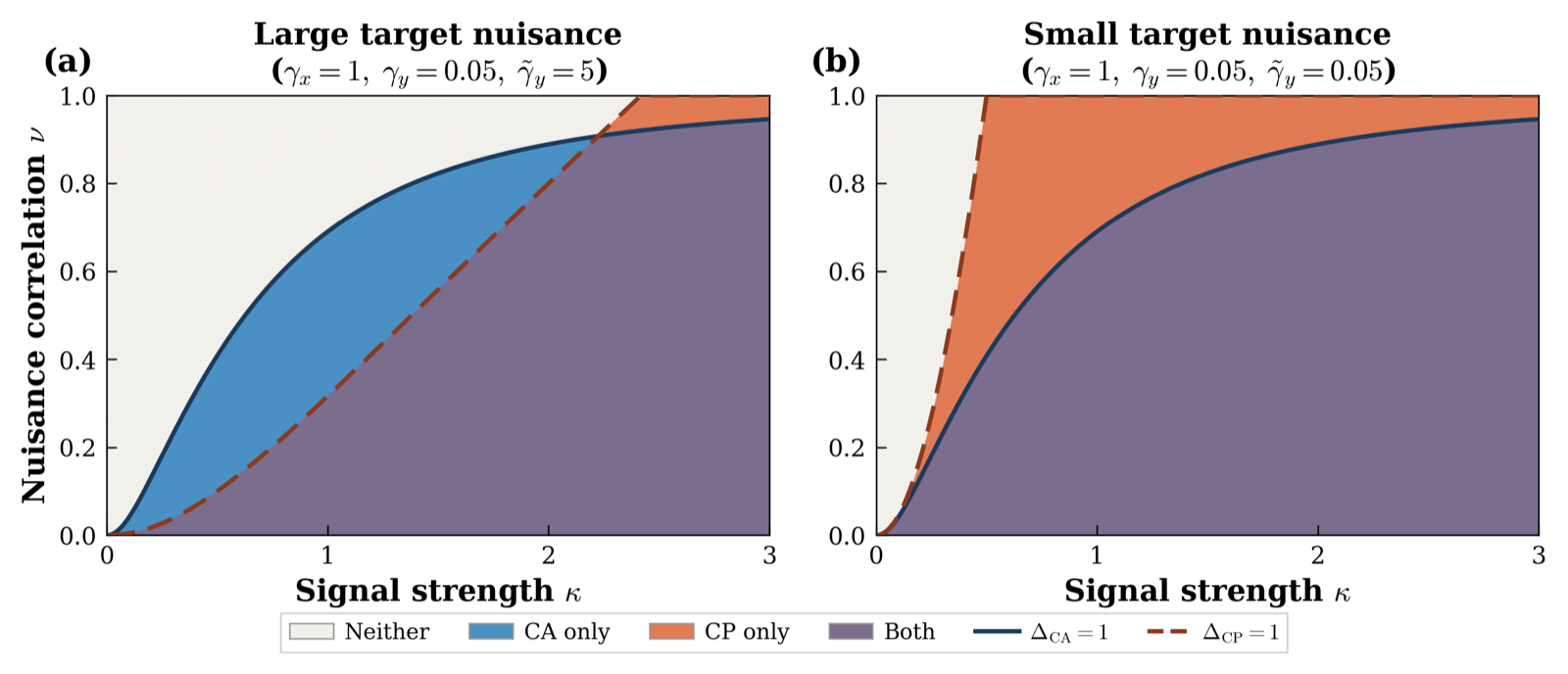
Balestriero's work develops a unified linear framework for understanding when cross-modal alignment (CA) and prediction (CP) succeed or fail in multimodal representation learning. The framework addresses a gap in systematic understanding of these paradigms, particularly in scientific domains like biomedicine and astrophysics where practitioners face heterogeneous instruments and measurement levels.
Under a spiked signal-plus-noise model with structured cross-modal nuisance correlation, the study derives separation ratios for both objectives, exposing complementary failure modes. Alignment whitens each modality but fails when nuisances are strongly correlated; prediction encodes what is cross-predictable through one-sided whitening, governed by source-modality quality.
The resulting phase diagram partitions multimodal problems into four regimes: Both, CA only, CP only, and Neither. The framework also presents a data-driven procedure to locate real-world datasets in this diagram using a small labeled subsample, identifying the preferred objective and prediction direction before any training. This approach helps practitioners diagnose their multimodal problem and choose the right objective, potentially avoiding harmful cross-modal training scenarios.
Key insight: A unified linear framework provides a phase diagram that identifies when cross-modal alignment or prediction is optimal, enabling practitioners to choose the right objective before training.
TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
Ji, Xiangyang arXiv: 2606.11119
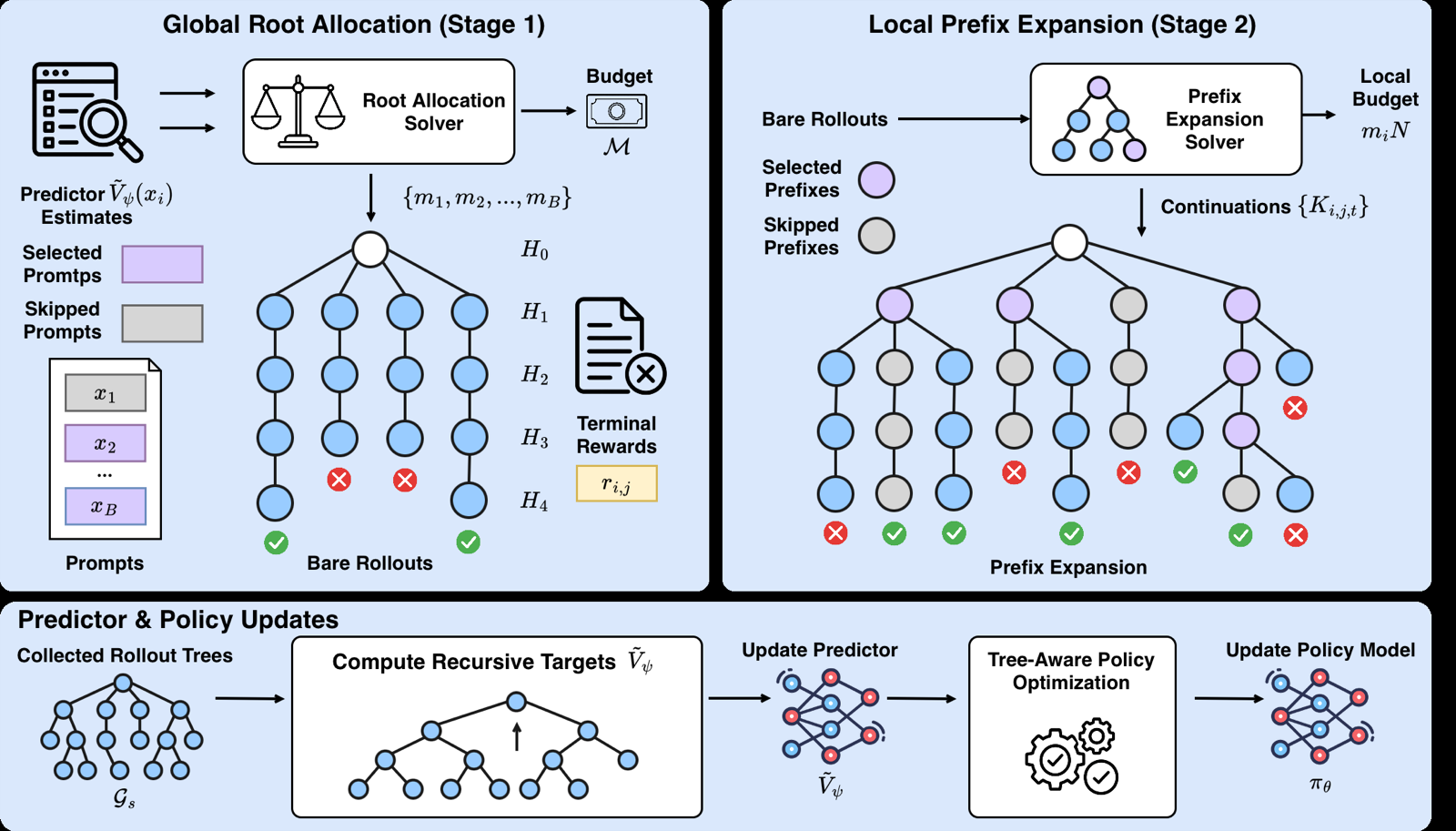
The paper addresses a critical challenge in reinforcement learning with verifiable rewards (RLVR) where rollout-intensive optimization is limited by insufficient reward contrast. Traditional approaches allocate resources only at the prompt level, missing variations within multi-turn rollouts. TRACE proposes a novel framework that models each ReAct-style thought-action-observation turn as a semantically distinct node, enabling budget allocation from prompt roots to intermediate prefixes with further continuations.
By treating each turn as a node in a tree structure, TRACE allows for more granular control over resource allocation, which is particularly important in multi-turn agentic tasks. The framework uses a shared predictor to estimate conditional success probability at these anchors, guiding the allocation process based on prefix histories. This approach naturally forms tree-structured rollouts that enrich outcome-only feedback and amplify policy-update signals.
Empirically, TRACE achieves competitive performance and efficiency gains on typical agentic benchmarks, such as improving Qwen3-14B Multi-Hop QA average accuracy by 2.8 points over baselines at equal sampling cost. This demonstrates the practical value of the framework in enhancing both accuracy and computational efficiency in agentic reinforcement learning.
Key insight: TRACE introduces a tree-structured rollout allocation framework that improves reward contrast in agentic RL by dynamically allocating budget to both prompt roots and intermediate prefixes, enhancing policy updates through adaptive tree structures.
SkillAxe: Sharpening LLM-Authored Agent Skills Through Evaluation-Guided Self-Refinement
Gulwani, Sumit arXiv: 2606.10546
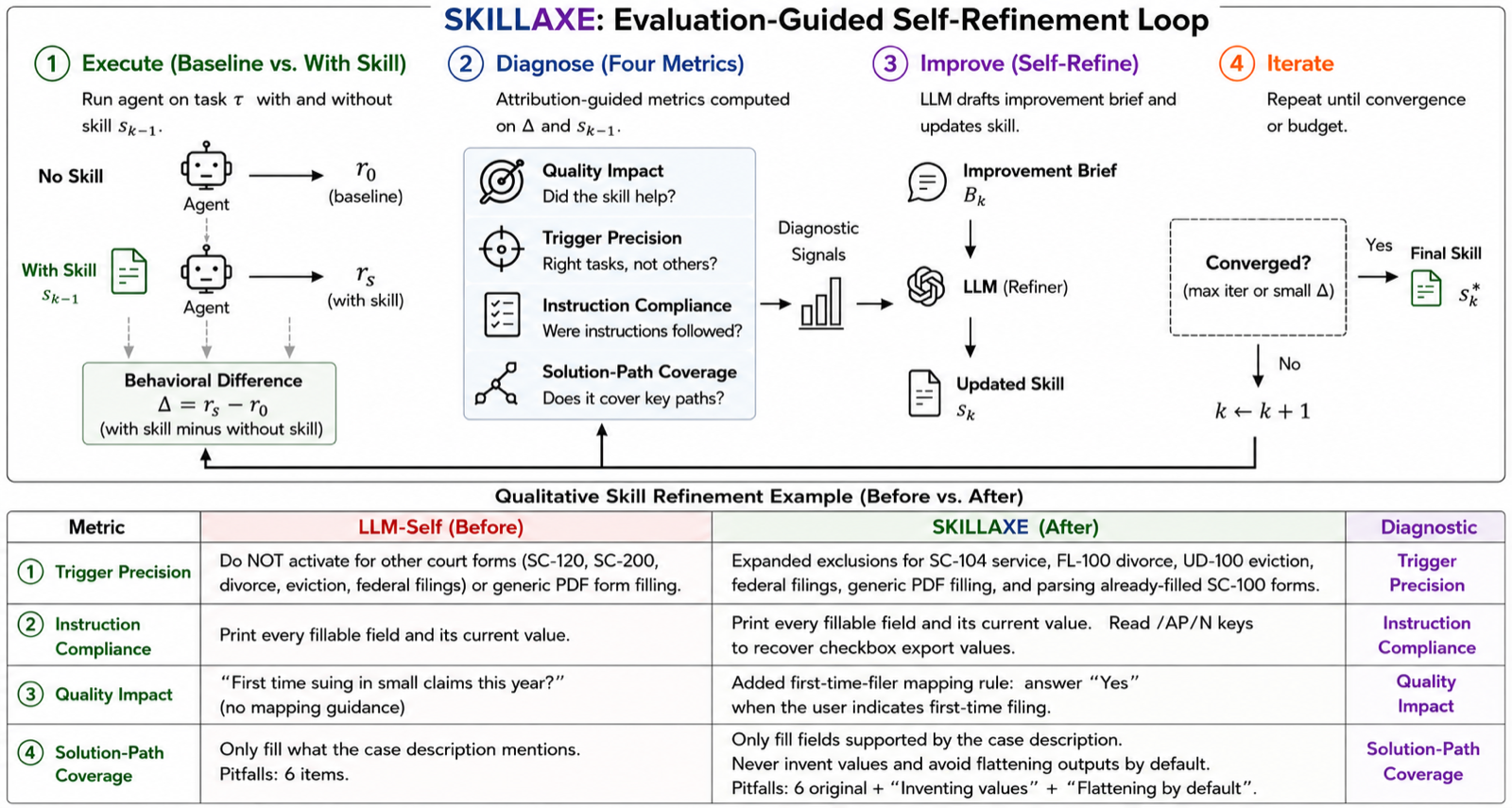
The paper tackles the problem of LLM-generated skills that often fail to perform well in practice. While human-authored skills improve pass rates by 16.2 percentage points, LLM-authored skills provide no measurable gain. SkillAxe introduces a fully unsupervised framework that allows LLMs to self-improve their skills through iterative diagnosis and refinement.
SkillAxe decomposes skill quality into four interpretable dimensions: quality impact, trigger precision, instruction compliance with fault attribution, and solution-path coverage. This structured approach produces improvement briefs without requiring ground-truth labels, test suites, or environment rewards. The framework is validated on SkillsBench, where it improves pass rates by 28% relative to unimproved LLM skills and closes 47-67% of the gap to human-authored skills.
The approach also demonstrates its effectiveness in real-world applications through SpreadsheetBench, where a SkillAxe-built skill library learns from past agent trajectories and raises pass rate from 16.0% to 52.0% using only 22 skills. This shows that SkillAxe can serve as a continuous improvement engine for LLM agents, enhancing their performance over time without external supervision.
Key insight: SkillAxe enables LLMs to iteratively diagnose and refine their own skills using a fully unsupervised framework that decomposes skill quality into interpretable dimensions, significantly improving pass rates on benchmark tasks.
Decoupling Thought from Speech: Knowledge-Grounded Counterfactual Reasoning for Resilient Multi-Agent Argumentation
Chudziak, Jarosław A. arXiv: 2606.10475

The paper addresses the stability issues in multi-agent debate frameworks where long-horizon exchanges often experience logic degradation, argument repetition, and role drift. KG-CFR proposes a dual-stage architecture that enforces strict separation between a private, retrieval-augmented planning buffer and a public execution layer.
This architectural decoupling ensures that agents can maintain consistency with their original plans while engaging in dynamic argumentation. The system is evaluated in a 1v1v1 Dynamic Resource Allocation under Uncertainty (DRAU) environment, where KG-CFR prevents critical post-shock degradation in over 95% of perturbed runs, increasing overall argument quality from 0.694 to 0.822.
The contribution is significant as it demonstrates that architectural decoupling can be a key factor in enhancing systemic resilience under sustained pressure without compromising quality. Additionally, KG-CFR introduces custom vector metrics for discourse divergence and plan-execution alignment, providing strong evidence of operational stability. Ablation experiments confirm that doctrinal grounding is equally important for argument quality as prospective planning.
Key insight: KG-CFR introduces a dual-stage architecture that decouples private planning from public execution, enhancing resilience in multi-agent argumentation by maintaining process fidelity under sustained perturbations.
Game-Theoretic Multi-Agent Control for Robust Contextual Reasoning in LLMs
Khomh, Foutse arXiv: 2606.10322
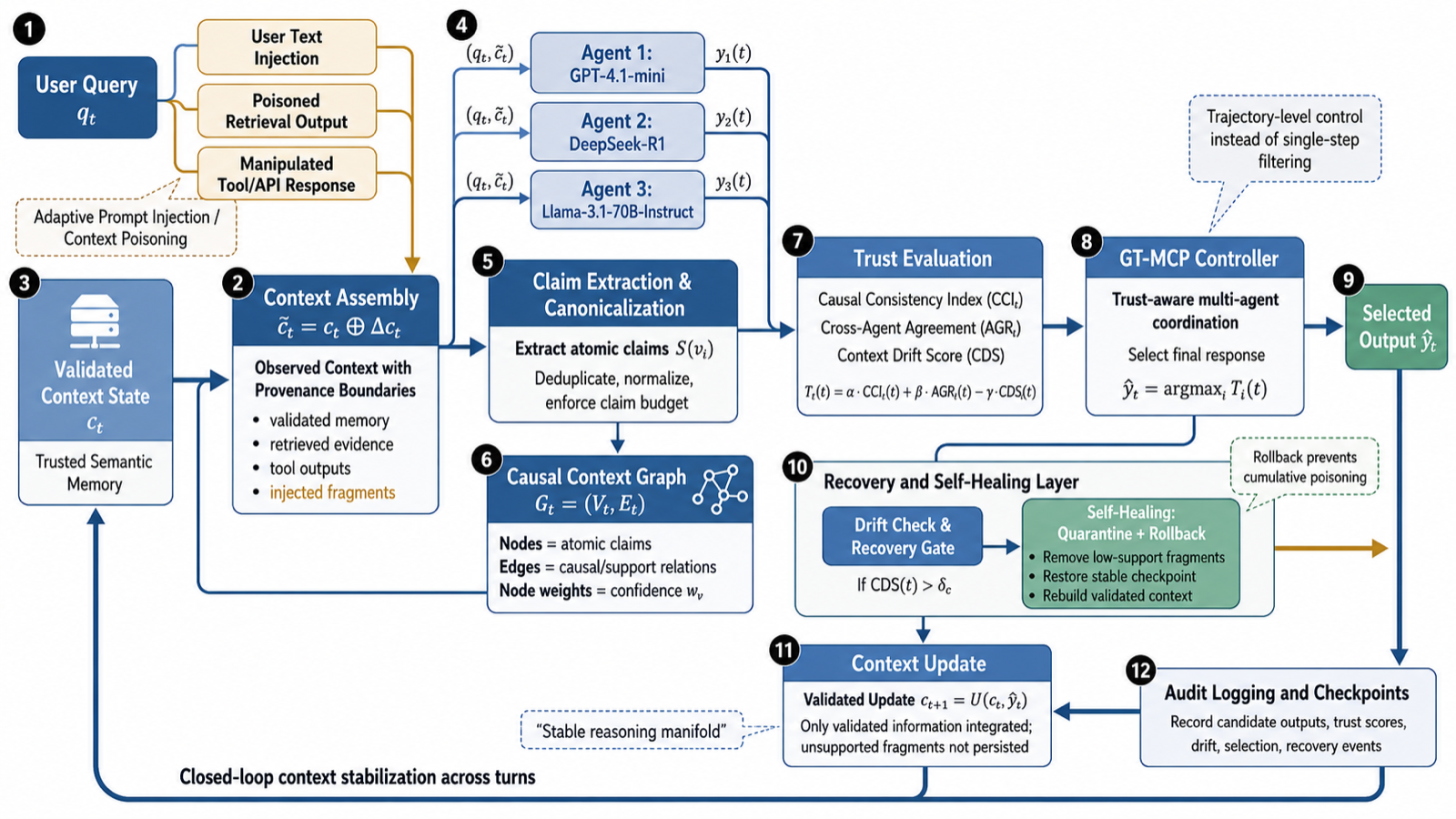
The paper identifies vulnerabilities in LLMs during multi-turn interactions where context evolution makes them susceptible to prompt-injection and context-poisoning attacks. Existing defenses often ignore context evolution, leaving long-horizon reasoning exposed. GT-MCP introduces a controller-driven multi-agent method that treats context management as a closed-loop process.
GT-MCP coordinates three heterogeneous LLM agents and selects outputs through a trust function that jointly evaluates causal consistency against a validated context graph, semantic agreement among agents, and distributional drift over time. When instability is detected, a rollback-based self-healing mechanism restores the validated context and prevents unsupported fragments from propagating.
Empirical evaluation over 500 interaction turns under an adaptive adversarial threat model shows that contextual drift remains bounded in 99.6% of turns, with recovery required only in 0.4%. Per-turn utility remains tightly concentrated, indicating robustness against adversarial attacks. The approach maintains stable win rates above 98% and keeps computational overhead predictable, making it suitable for deployment in real-world applications.
Key insight: GT-MCP treats context management as a closed-loop dynamical process, coordinating heterogeneous LLM agents to maintain contextual stability and prevent prompt-injection attacks through trust functions and rollback mechanisms.
What Spatial Memory Must Store: Occlusion as the Test for Language-Agent Memory
Bang, Junho arXiv: 2606.10299
The paper challenges the conventional approach of blending spatial proximity with recency and importance in memory-palace systems. Through a pre-registered recall experiment, it demonstrates that the default linear blend fails to improve recall performance and can even hurt it. Instead, geometry-led weighting decisively outperforms the baseline, showing that spatial memory must lead recall when queries are spatial.
A key insight is the separation of memory recall and visibility. Recall is occlusion-blind by design, while visibility is a perception predicate over stored geometry that the live system never computes. The paper introduces a one-line ray-versus-voxel DDA to efficiently compute visibility, achieving high accuracy (0.982) on behind-wall targets compared to text-only methods (0.000). This approach also resolves near-duplicate locations more effectively than cosine similarity.
The findings are validated through a comprehensive study with automated oracle scoring across scripted worlds, confirming that occlusion-needs-geometry is indeed a critical requirement for effective spatial memory in language agents. The contribution lies in the measurement and isolation of what spatial memory must store versus how it is read, laying the groundwork for future research in agent memory systems.
Key insight: Occlusion tests reveal that spatial memory must store geometric information to distinguish between visible and occluded locations, with a one-line ray-versus-voxel digital differential analyzer (DDA) providing efficient visibility predicates.
Deployment-Time Memorization in Foundation-Model Agents
Ting, Jerry arXiv: 2606.10062

The paper shifts the focus from parametric memorization or fixed memory configurations to deployment-time memorization, recognizing that foundation-model agents remember users across interactions. It formulates agent memory as a privacy-utility frontier measured by Personalization Recall (PR) and Adversarial Extraction Rate (AER), sweeping three memory-design knobs: summarization aggressiveness, retrieval breadth (k), and deletion mode.
Key findings reveal that key-fact summarization reduces canary extraction by 76% on Gemma 3 12B and 64% on GPT-4o-mini while preserving nearly all personalization recall. However, increasing k no longer restores leakage once content is compressed away. This highlights the importance of compression in balancing utility and security.
The study also introduces the Forgetting Residue Score (FRS) to quantify whether deleted information remains recoverable from derived memory tiers. Raw-only deletion leaves derived summary copies recoverable in approximately 20% of instances, while only full-pipeline purge or tombstone redaction drives worst-tier residue to zero. These results establish that persistent agent memory must be evaluated as a first-class memorization mechanism, assessed by what it helps agents recall, what it makes extractable, and what it can truly erase.
Key insight: Deployment-time memorization must be evaluated as a first-class mechanism, considering personalization utility, extraction risk, and deletion fidelity, with key findings showing that summarization aggressiveness and deletion mode significantly impact these trade-offs.
Overcoming Rank Collapse in Feedback Alignment
Clopath, Claudia arXiv: 2606.11123
The paper investigates the limitations of Feedback Alignment (FA), a biologically plausible alternative to backpropagation that uses fixed random feedback weights. While FA works well in shallow networks, it fails to scale to deeper architectures due to rank collapse, where the error signal becomes constrained to a lower-dimensional subspace, limiting parameter space exploration.
To address this issue, the authors evaluate two mechanisms for increasing the effective dimensionality of FA: Muon, an optimizer that orthogonalizes weight updates, and hidden activity normalization, which promotes activation orthogonality. These methods consistently improve over FA baselines across larger architectures and benchmarks, achieving a 9 percentage point accuracy increase on CIFAR100 with ResNet-18.
The results identify low-dimensional gradient dynamics as a key obstacle to scaling FA and suggest that inducing higher-dimensional update geometry is a promising route toward scalable alternatives to backpropagation. This work provides valuable insights into how to overcome fundamental limitations in biologically inspired learning algorithms.
Key insight: Feedback Alignment (FA) suffers from rank collapse in deeper architectures, limiting exploration of parameter space; introducing Muon optimizer and hidden activity normalization significantly improves FA performance on benchmarks like CIFAR100.
LLM-Mediated Demand Response Coordination in Smart Microgrids
de Zarzà, I. arXiv: 2606.11050
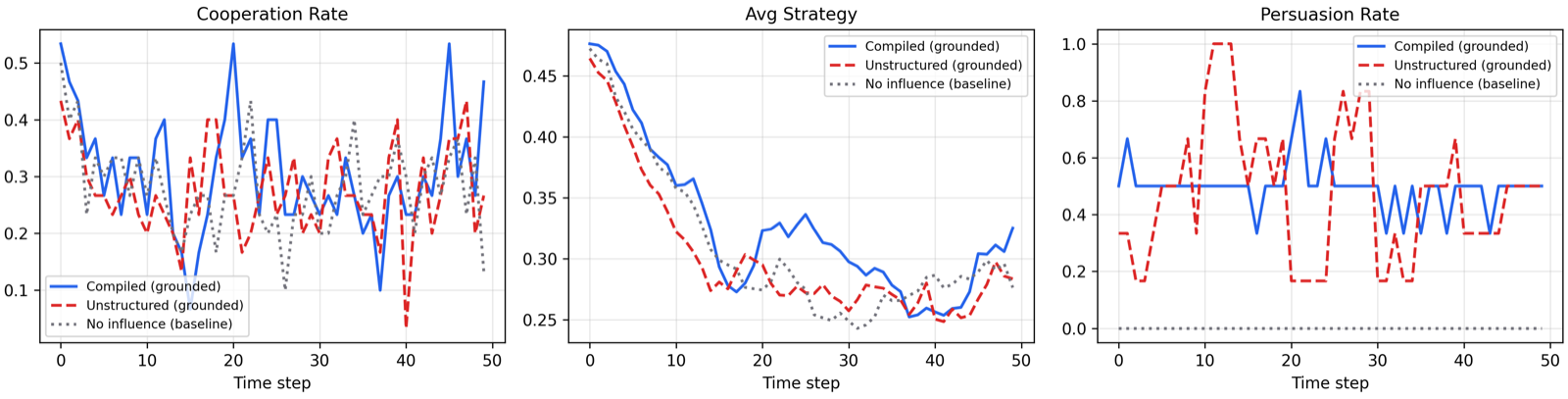
The paper presents a multi-agent simulation where a Large Language Model (LLM) Influence Compiler issues structured demand-response directives to heterogeneous prosumer agents. Each agent combines game-theoretic base probability (derived from payoff history, neighbor imitation, and exploitation memory) with LLM narrative evaluation of incoming coordination signals.
This hybrid architecture resolves the cooperation bias inherent in direct LLM decision-making, which produces flat dynamics regardless of grid conditions. The model generates realistic prosumer behavior across six personality archetypes, achieving baseline cooperation near 50% and clear differentiation under influence. Structured directives achieve 33.3% demand-curtailment cooperation versus 27.0% for unstructured messaging and 28.0% for no intervention.
Hub-targeted dissemination via high-centrality network nodes outperforms peripheral or random targeting, confirming that grid topology provides mechanistic amplification independent of message content. These results suggest that structured LLM compilation, grounded agent reasoning, and network-aware targeting are complementary design principles for scalable, interpretable demand-response coordination in smart-city energy systems.
Key insight: LLM-mediated coordination in smart microgrids improves demand response through structured directives, hybrid decision architectures combining game-theoretic base probabilities with LLM narrative evaluation, and network-aware targeting strategies.
Decentralized Multi-Agent Systems with Shared Context
Mirhoseini, Azalia arXiv: 2606.10662

The paper proposes Decentralized Language Models (DeLM), a framework that decentralizes coordination in multi-agent systems by using parallel agents, a shared verified context, and a task queue. Unlike traditional centralized orchestration where a main agent assigns work and collects outputs, DeLM allows agents to asynchronously claim subtasks, read accumulated progress, perform local reasoning, and write back compact verified updates.
The shared context acts as a common communication substrate, enabling agents to build on one another's verified progress without routing every update through a central controller. This approach significantly reduces bottlenecks in coordination and improves scalability. Empirically, DeLM achieves the best performance across Avg.@1, Pass@2, and Pass@4 on SWE-bench Verified, with gains of up to 10.5 percentage points over the strongest baseline, while reducing cost per task by roughly 50%.
On LongBench-v2 Multi-Doc QA, DeLM achieves the highest average accuracy across four frontier model families, improving over the strongest baseline by up to 5.7 percentage points. The framework demonstrates that decentralization can enhance both software-engineering test-time scaling and long-context reasoning, making it a promising approach for large-scale agent systems.
Key insight: DeLM decentralizes multi-agent coordination through parallel agents, shared verified context, and task queues, improving both software-engineering test-time scaling and long-context reasoning compared to centralized approaches.
TRAPS: Therapeutic Response Analysis via Pathway-informed Stratification
Roy, Tirtho arXiv: 2606.09898
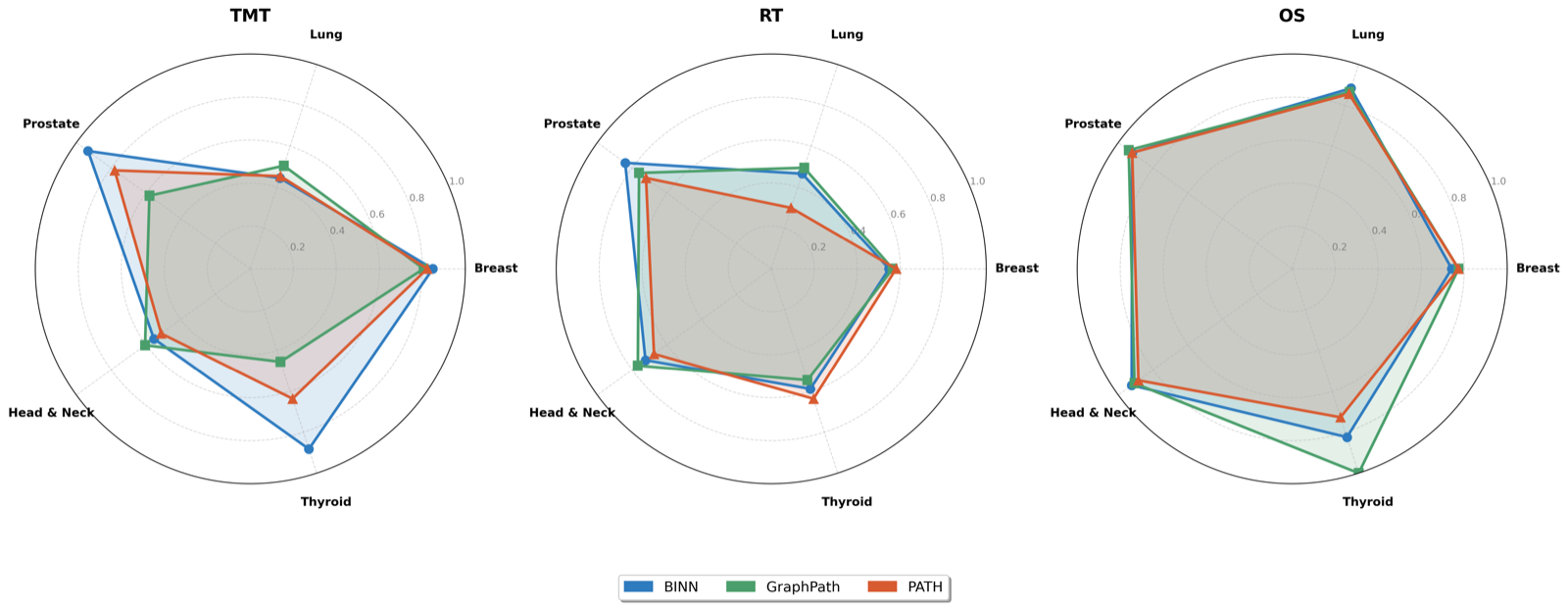
The paper introduces TRAPS, a unified benchmark for pathway-guided therapy response modeling that evaluates three biologically informed architectures—BINN, GraphPath, and PATH—across five cancer cohorts. This is a significant step forward in comparing models that are designed to leverage biological pathways, which is particularly relevant for AI agent development in healthcare domains where domain-specific knowledge integration is crucial.
The findings reveal that no single architecture excels across all tasks, with each model performing best on specific outcomes. GraphPath's superior performance in prostate targeted molecular therapy prediction (AUROC of 0.92) underscores the value of leveraging lateral co-regulation structures when the data aligns with the biological context, even under extreme class imbalance. This suggests that agent architectures must be carefully matched to their domain-specific tasks for optimal performance.
Notably, the study also highlights limitations in using gene expression data alone for radiation therapy prediction, indicating that clinical variables beyond molecular profiles are essential. This finding has implications for multi-agent systems and memory architectures that must integrate heterogeneous data sources effectively, emphasizing the need for modular agent designs that can selectively incorporate relevant information.
Key insight: Pathway-informed deep learning models show varying performance across different cancer treatment outcomes, with GraphPath achieving the highest AUROC of 0.92 for prostate targeted molecular therapy prediction, highlighting the importance of architectural alignment with biological data structure.
AI Model Releases

Introducing North Mini Code: Cohere’s First Model For Developers
Cohere has released North Mini Code, a 30B-parameter Mixture-of-Experts model optimized for agentic software engineering tasks. The model achieves strong performance in coding benchmarks, outperforming several open-source models of similar size including Qwen3.5 and Gemma 4. It was trained using a two-stage cascaded supervised fine-tuning followed by reinforcement learning with verifiable rewards, focusing on terminal-based agentic tasks and software engineering workflows.
Why it matters: North Mini Code represents a significant advancement in open-source coding models, particularly for agentic tasks that require robustness across different environments. Its release contributes to the growing trend of specialized models tailored for developer workflows, potentially influencing how AI agents are built and deployed in software development contexts.

Claude Fable 5 and Claude Mythos 5
Anthropic has launched Claude Fable 5, a Mythos-class model made safe for general use. The model exceeds previous capabilities across software engineering, knowledge work, vision, and scientific research. It demonstrates exceptional performance on complex tasks, with longer and more complex queries showing larger advantages over other models. For cybersecurity applications, Anthropic also released Claude Mythos 5, which has safeguards lifted in some areas and is initially deployed through Project Glasswing in collaboration with the US government. Fable 5 and Mythos 5 are priced at $10/million input tokens and $50/million output tokens.
Why it matters: These launches represent a significant step toward making advanced AI capabilities more broadly accessible while maintaining safety standards. The introduction of Claude Mythos 5 specifically addresses cybersecurity needs, showing how frontier models can be tailored for specialized applications. This development advances the practical deployment of powerful AI systems in both general and high-stakes domains.
AI Tooling

Google just fired a warning shot in the AI subscription price wars
Google has reduced the monthly price of its Google AI Plus subscription from $7.99 to $4.99, while doubling the included storage from 200 gigabytes to 400 gigabytes. The move targets individual users and students rather than enterprise customers, positioning Google AI Plus as the most affordable paid AI subscription in the U.S. market. This price cut follows similar moves by OpenAI and Google in emerging markets like India, signaling a broader trend toward commoditization of AI infrastructure.
Why it matters: This pricing strategy reflects the intensifying competition in the AI subscription space, particularly as providers seek to capture users early before rivals can respond. It signals a shift toward more accessible AI tools for everyday consumers and could pressure other players like Anthropic and OpenAI to reconsider their pricing strategies.
Firebase/GCP

Cloud Fable 5 on Google Cloud | Google Cloud Blog
Google Cloud has made Claude Fable 5, Anthropic's latest frontier model, generally available through the Agent Platform. The model is designed for complex, multi-step reasoning and excels in advanced software development, long-horizon agents, and deep multimodal document analysis. It brings strong safeguards to make it safe for general use. Customers can now access Claude Fable 5 alongside other Anthropic models like Claude Opus 4.8 and Claude Sonnet 4.6 on Google Cloud's Agent Platform.
Why it matters: This availability on Google Cloud expands the reach of Claude Fable 5 to enterprise users, reinforcing the platform's commitment to providing access to cutting-edge AI capabilities. It also highlights the growing importance of model interoperability and platform partnerships in the AI ecosystem.
Gemini in Apple's Foundation Models framework
Firebase has enabled developers to bring Gemini cloud models into Apple's Foundation Models framework starting with iOS 27, macOS 27, iPadOS 27, watchOS 27, and visionOS 27. The integration allows developers to use the same API for both on-device Apple models and cloud-hosted Gemini models, enabling seamless switching between local and cloud inference based on app requirements. Firebase AI Logic handles requests and enforces security through Firebase App Check, ensuring that only legitimate clients can access Gemini APIs from Apple apps.
Why it matters: This integration bridges the gap between Apple's native Foundation Models framework and Google's powerful Gemini models, offering developers a unified approach to building generative AI features. It enables hybrid inference strategies that balance privacy, cost, and capability, which is crucial for enterprise adoption of AI in mobile environments.