Anthropic researchers highlight critical infrastructure gaps in biological data retrieval for AI agents, while Hugging Face announces expanded open-source support for agentic reinforcement learning. Meanwhile, new papers reveal breakthroughs in self-evolving agent architectures and memory systems.
This week's research digest explores the intersection of AI agents and scientific domains with Anthropic's findings on biological data infrastructure showing that current agents struggle with database retrieval accuracy below 100%. Hugging Face's OpenEnv project is gaining momentum with a broader consortium backing its open development approach. In parallel, several papers advance agent memory systems through dual-process architectures, self-improving harnesses, and context compression techniques. Additionally, researchers demonstrate how agents can improve their own operating environments, compile external knowledge into reusable skills, and navigate complex reasoning tasks through delegation intelligence frameworks.
Research Papers
Memory Beyond Recall: A Dual-Process Cognitive Memory System for Self-Evolving LLM Agents
Yu, Xiang arXiv: 2606.09483
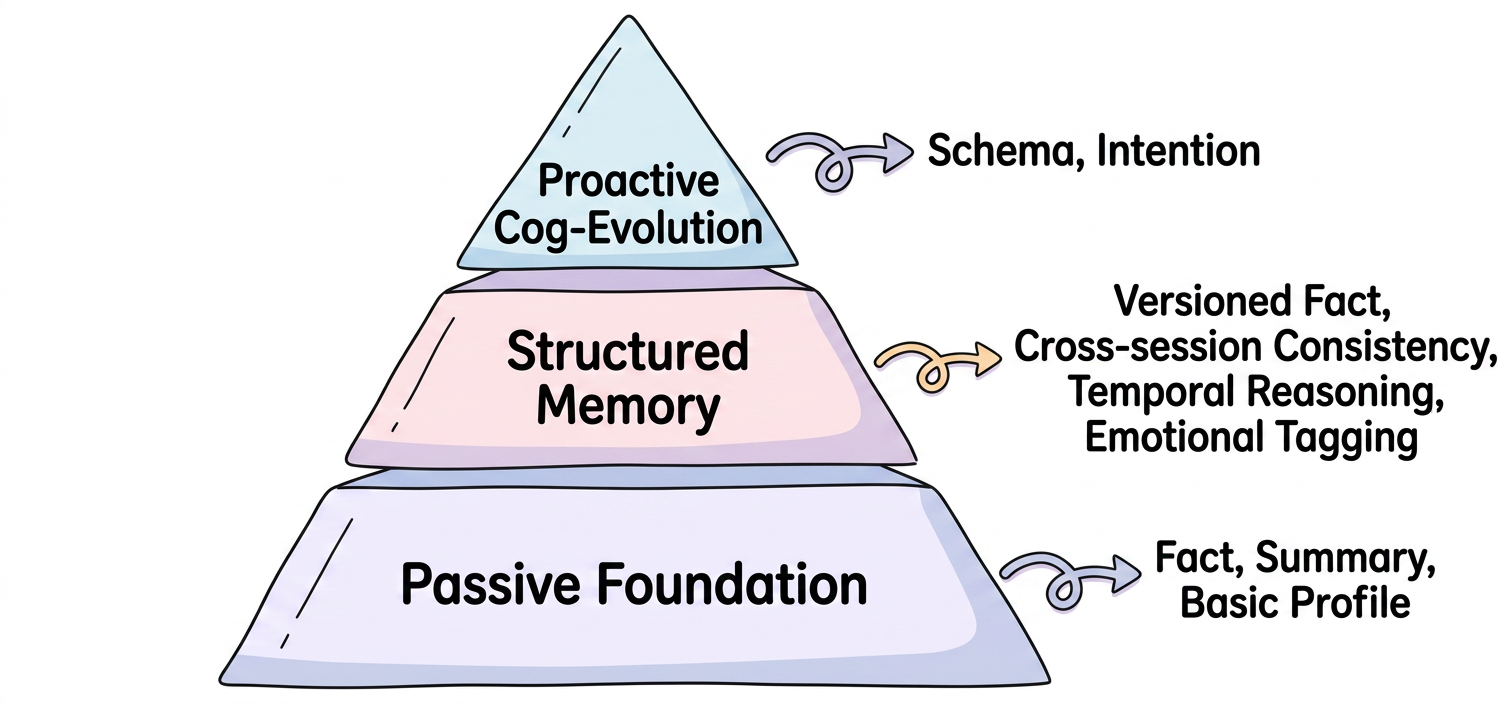
The paper introduces DCPM, a novel memory architecture for LLM agents that reorganizes memory along a cognitive capability hierarchy. This approach moves beyond simple recall mechanisms by incorporating dual-process theory, where System1 handles synchronous belief revisions through doubly linked supersedes chains, while System2 manages asynchronous schema induction and cross-domain abstraction. The hierarchical structure allows agents to evolve their understanding over time, particularly excelling in implicit personalization tasks that require reasoning about user evolution.
Experimental validation on benchmarks like PersonaMem-v2 shows that System2's contribution is most valuable where the task rewards implicit cross-session inference, achieving up to +5.20 points improvement. This demonstrates that the dual-process architecture aligns with theoretical predictions and provides tangible benefits for complex reasoning tasks. The system's ability to maintain belief trajectories while abstracting higher-level patterns suggests a more robust foundation for long-term agent development.
This work addresses a critical limitation in current memory systems, which collapse multiple cognitive functions into single retrieval surfaces. By separating the processes of belief revision from schema induction, DCPM enables agents to better handle evolving user needs and maintain coherent identity across sessions, representing a significant step toward more sophisticated self-evolving AI systems.
Key insight: Introducing a dual-process cognitive memory system that separates belief revision (System1) from schema induction and cross-domain abstraction (System2), enabling more sophisticated implicit personalization and long-term reasoning in LLM agents.
Self-Harness: Harnesses That Improve Themselves
Hu, Shuyue arXiv: 2606.09498
Self-Harness represents a significant advancement in agent autonomy by enabling LLM-based systems to self-improve their operational frameworks. The approach operates through three stages: Weakness Mining identifies model-specific failure patterns from execution traces; Harness Proposal generates minimal, targeted modifications; and Proposal Validation ensures changes are effective through regression testing. This closed-loop system allows agents to adapt their own interfaces based on performance feedback.
The implementation across three diverse base models (MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5) demonstrates consistent performance improvements, with pass rates increasing from 40.5% to 61.9%, 23.8% to 38.1%, and 42.9% to 57.1% respectively. These results show that Self-Harness is not merely adding generic instructions but creating model-specific, executable changes that directly address weaknesses.
This paradigm shifts the paradigm from human-engineered harnesses to self-improving ones, addressing scalability issues as LLMs become increasingly diverse and rapidly evolving. The approach suggests a path toward agents that can participate in reshaping their own operational frameworks, moving beyond passive reliance on external design and toward active system evolution.
Key insight: Developing Self-Harness, an automated paradigm where LLM agents improve their own operating harnesses through iterative weakness mining, proposal generation, and validation, without human intervention or stronger external agents.
REFLECT: Intervention-Supported Error Attribution for Silent Failures in LLM Agent Traces
Cheng, Guang arXiv: 2606.09071
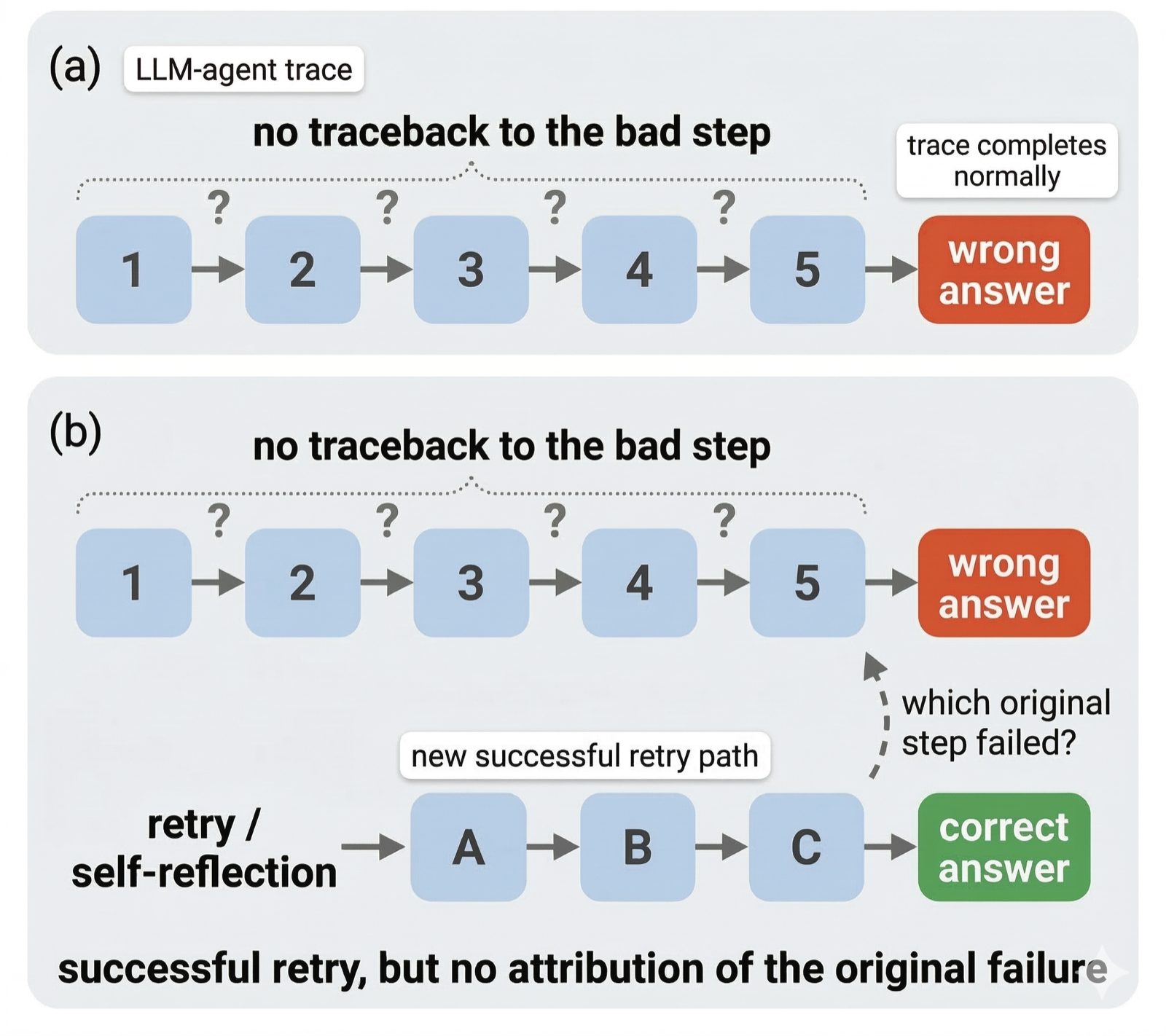
REFLECT addresses a critical gap in LLM agent debugging by enabling intervention-supported error attribution for silent failures. Unlike existing methods that predict suspect steps or retry with recovery mechanisms, REFLECT uses controlled replay with specific patches to verify error hypotheses and refine final attribution through contrastive evidence. This approach fundamentally improves the accuracy of error localization in complex execution traces.
The method's performance across four localization benchmarks shows it achieves highest accuracy among same-auditor methods, particularly excelling on structured tool-use traces where gains are most significant. The ability to provide actionable localization even without ground-truth answers makes REFLECT valuable for real-world deployment scenarios where complete information may not be available.
This work is crucial for improving the reliability and maintainability of LLM agents that execute complex multi-step tasks. By enabling more precise error attribution, REFLECT supports better debugging practices and helps identify root causes of failures, ultimately leading to more robust agent systems that can handle increasingly complex real-world applications.
Key insight: Introducing REFLECT, a method that closes the gap in error localization by using controlled replay with diagnosis-specific patches to refine attribution of silent failures in LLM agent traces.
End-to-End Context Compression at Scale
Izmailov, Pavel arXiv: 2606.09659

LCLMs represent a breakthrough in long-context language model inference by addressing the memory bottleneck through end-to-end context compression. The approach revisits encoder-decoder compression methods and demonstrates that carefully designed architectures can achieve better performance than traditional KV cache compression, particularly in terms of accuracy-efficiency trade-offs.
The architecture search and pre-training process involving 0.6B-encoder, 4B-decoder models trained on over 350B tokens shows systematic improvements across general-task performance, compression speed, and peak memory usage. The ability to compress contexts at ratios of 1:4, 1:8, and 1:16 while maintaining quality makes LCLMs practical for real-world deployment in long-horizon agent applications.
This work enables the development of more efficient long-horizon agents that can skim through compressed long contexts and adaptively expand relevant segments on demand. The compression capabilities allow agents to handle increasingly complex tasks without being constrained by memory limitations, opening new possibilities for multi-step reasoning and extended planning scenarios.
Key insight: Introducing Latent Context Language Models (LCLMs) that achieve superior performance on the accuracy-efficiency frontier for long-context inference through encoder-decoder compression techniques.
Anything2Skill: Compiling External Knowledge into Reusable Skills for Agents
He, Liang arXiv: 2606.09316
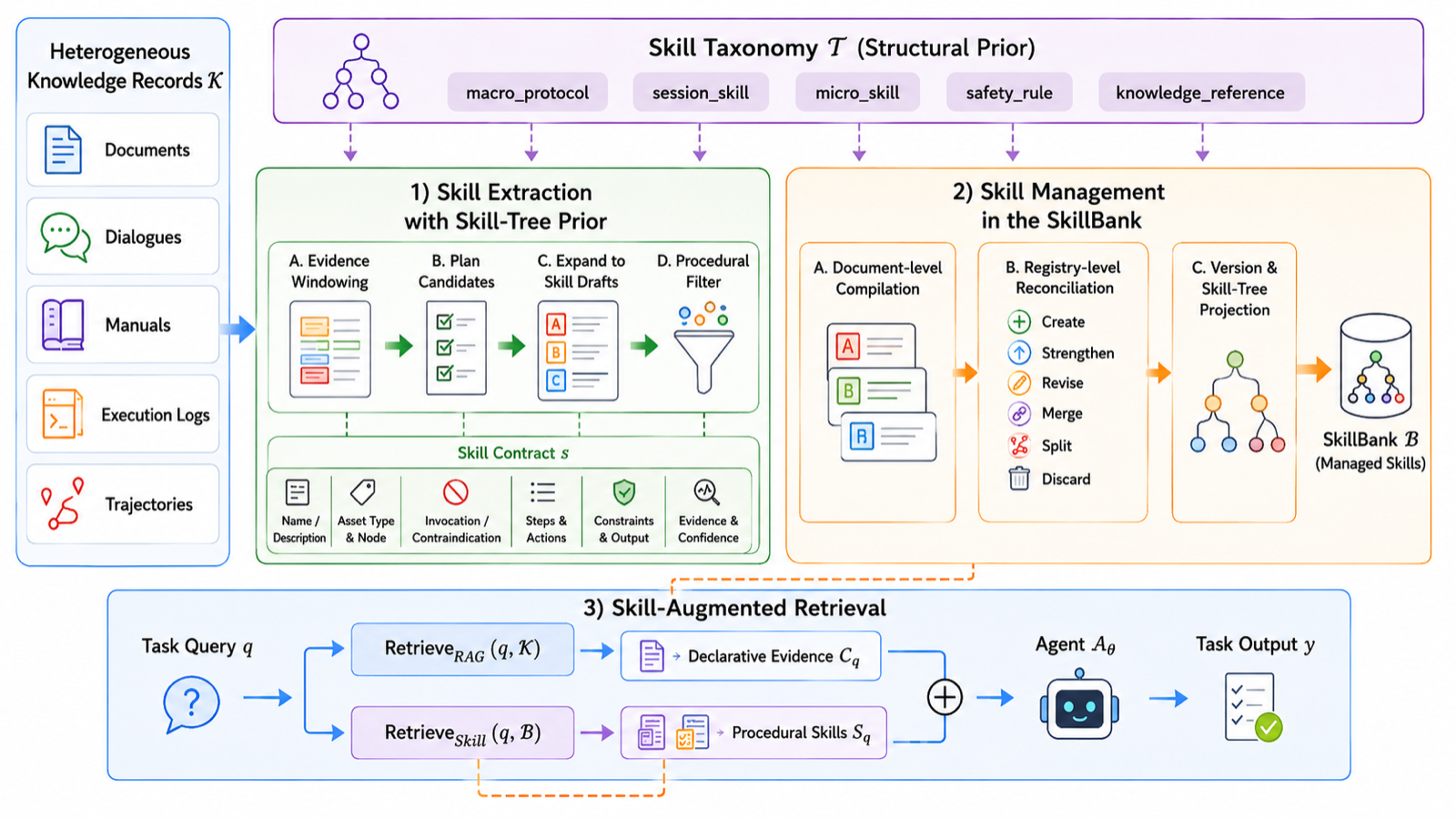
Anything2Skill introduces a systematic approach to transforming external knowledge into reusable procedural skills for LLM agents. The framework decomposes knowledge records into evidence windows and performs plan-and-expand skill extraction under a skill-tree prior, converting extracted candidates into structured skill contracts that specify invocation conditions, action moves, workflow steps, and constraints.
The SkillBank management system provides persistent storage with taxonomy-aware compilation, registry-level reconciliation, lifecycle tracking, versioned updates, and visible skill-tree projection. This approach allows agents to retrieve both declarative evidence from knowledge bases and procedural skills from the SkillBank, enabling a hybrid RAG approach that combines knowledge access with capability reuse.
Experimental results on qsv and GitHub-CLI benchmarks show substantial improvements over RAG-only agents, achieving 98.85% and 94.10% success rates respectively. This demonstrates that compiling latent procedural knowledge into explicit skills is an effective way to extend retrieval-augmented agents from knowledge access toward capability reuse, representing a significant step toward more autonomous and expert-like agent behavior.
Key insight: Proposing Anything2Skill, a framework that compiles heterogeneous external knowledge into reusable procedural skills, enabling agents to rapidly approximate domain expertise through structured skill contracts and persistent SkillBank management.
SIGA: Self-Evolving Coding-Agent Adapters for Scientific Simulation
Qin, Lianhui arXiv: 2606.09774
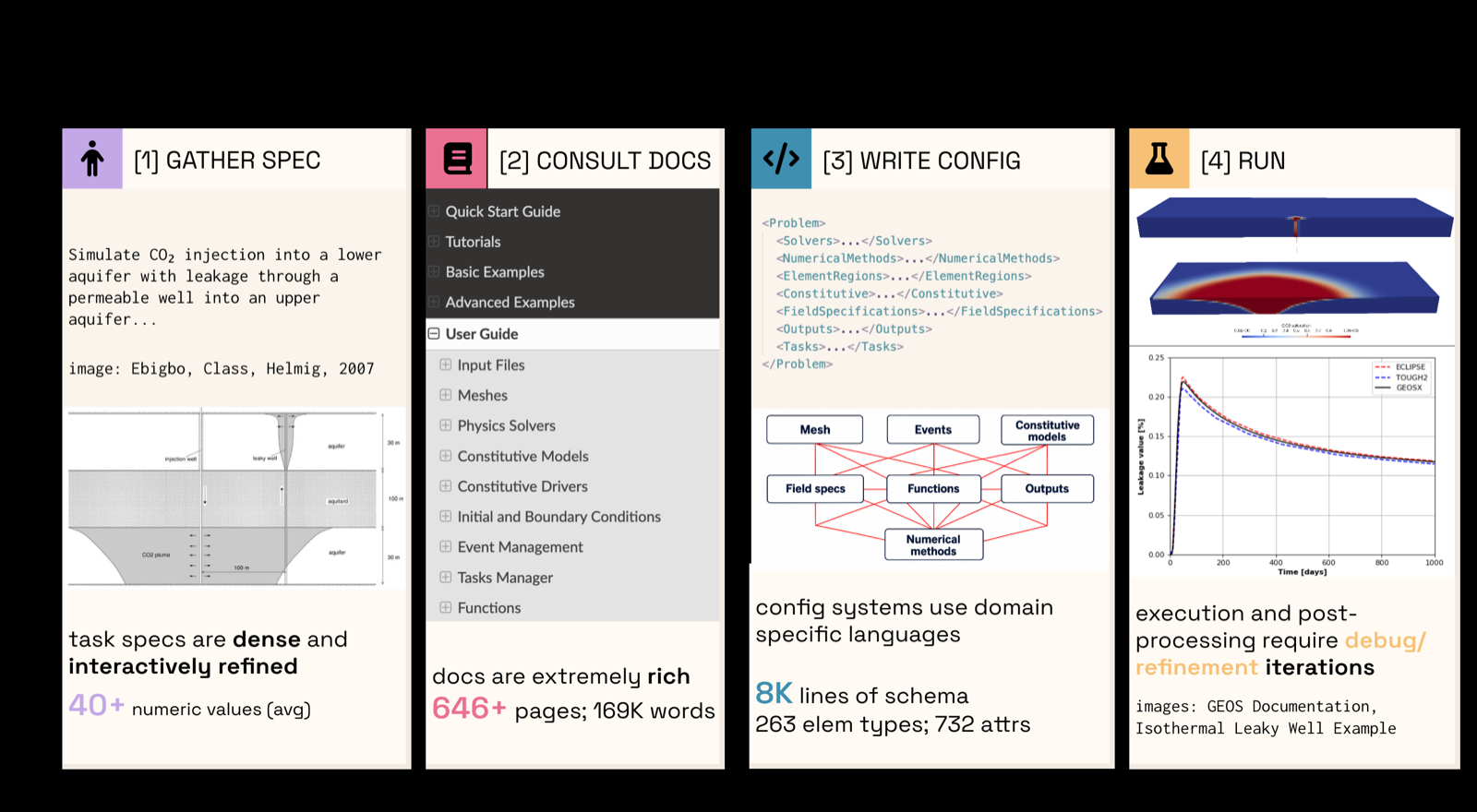
SIGA addresses the challenge of applying general coding agents to specialized scientific simulators by creating lightweight, self-improving grounding layers. The approach supplies simulator-specific executable contracts including vocabulary, structural constraints, validation rules, and termination conditions, bridging the gap between general-purpose agents and domain-specific software.
Evaluation on GEOS, an open-source multiphysics simulator, shows SIGA producing complete GEOS decks in about five minutes with TreeSim above 0.90, matching human expert performance while achieving a 36x wall-clock speedup. The self-evolution capability further improves performance by rewriting adapter contents from prior trajectories, demonstrating the approach's ability to continuously enhance its own effectiveness.
The transferability of SIGA to other simulators like OpenFOAM and LAMMPS shows that different interfaces require different mechanisms: validation matters most when structural completeness is the bottleneck, while memory and retrieval matter most when domain correctness is the bottleneck. This suggests that lightweight grounding layers can turn general coding agents into practical operators of scientific software, significantly expanding their applicability.
Key insight: Introducing SIGA, a Simulator-Interface Grounding Adapter that supplies simulator-specific executable contracts through retrieval, procedural memory, in-trajectory validation, and validation-enforced termination, enabling general coding agents to operate scientific software.
SearchSwarm: Towards Delegation Intelligence in Agentic LLMs for Long-Horizon Deep Research
Zhou, Jun arXiv: 2606.09730

SearchSwarm tackles the challenge of long-horizon tasks by developing delegation intelligence in agentic LLMs. The approach uses a harness that guides models toward high-quality task decomposition and delegation while constraining subagents to return results properly, creating supervised fine-tuning data that internalizes delegation capabilities into model weights.
The resulting SearchSwarm-30B-A3B model achieves state-of-the-art performance on BrowseComp (68.1) and BrowseComp-ZH (73.3), demonstrating the effectiveness of training delegation intelligence through synthetic data generation. The framework's ability to synthesize training data for this capability addresses a key gap in the open-source community where such training data is scarce in naturally occurring text.
This work represents a significant step toward more sophisticated multi-agent systems that can handle complex, long-horizon tasks by decomposing them into manageable subtasks and coordinating execution across agents. The approach enables main agents to conserve context budgets while leveraging specialized subagents, making it practical for real-world applications requiring extended planning and research capabilities.
Key insight: Developing SearchSwarm, a framework that trains agents to acquire delegation intelligence through harness-guided trajectories, enabling effective task decomposition, subtask delegation, and result integration for long-horizon deep research tasks.
(Auto)formalization is supposed to be easy: Trellis process semantics for spelling out rigorous proofs
Pegden, Wesley arXiv: 2606.09674

The Trellis system represents a significant advancement in the field of automated formal reasoning by introducing a novel process semantics approach to autoformalization. Rather than relying on specialized agent training or complex architectures, it leverages the common mathematician's notion of rigor—where any part of a proof can be elaborated further—to guide LLM agents through iterative refinement. This workflow ensures that progress is deterministic and incremental, making it possible to achieve reliable formalization even with modest computational resources.
This approach is particularly relevant for AI agent development because it shows how process semantics can be used to enforce correctness without requiring task-specific fine-tuning or extensive training data. The system's ability to produce a complete Lean formalization of a recent Ramsey theory breakthrough illustrates its practical utility in real-world mathematical problem-solving, suggesting that such methods could be extended to other domains where precision and rigor are paramount.
The implications for agent architectures are profound: Trellis suggests that generalist agents can be effective in highly structured tasks when guided by appropriate workflows. This challenges the assumption that specialized training is always necessary for complex reasoning tasks and opens up new possibilities for scalable, robust AI systems that maintain correctness through process design rather than just model capacity.
Key insight: Trellis demonstrates that rigorous autoformalization can be achieved through a deterministic workflow that enforces incremental progress, using generalist LLM agents rather than task-specific training.
SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
Dong, Yinpeng arXiv: 2606.09669

SpatialWorld addresses a critical gap in current benchmarks by focusing on interactive spatial understanding rather than passive evaluation or simulator-specific pipelines. By integrating eight heterogeneous simulation backends into a shared protocol, it provides a comprehensive testbed for evaluating how multimodal agents navigate and reason about physical environments. This approach is especially valuable for agent architectures that must operate under vision-only partial observability, where active exploration and long-horizon planning are essential.
The benchmark's design includes human-annotated tasks across diverse domains such as household routines and social collaboration, with each task featuring a validated initial state, reference trajectory, and terminal-state verifier. These features ensure reliable evaluation and highlight the complexity of real-world spatial reasoning, where agents must not only perceive but also plan and act effectively over extended periods.
The results show that even top-performing models like GPT-5 achieve only 17.4% task success rate, indicating substantial room for improvement in active exploration and long-horizon planning capabilities. This finding positions SpatialWorld as a rigorous testbed for future spatial agents and underscores the importance of developing more sophisticated reasoning mechanisms within agent architectures to handle complex, dynamic environments.
Key insight: SpatialWorld introduces a unified benchmark for evaluating interactive spatial reasoning in multimodal agents, revealing that even state-of-the-art models struggle with complex real-world tasks under partial observability.
IS-CoT: Breaking the Long-form Generation Collapse via Interleaved Structural Thinking
Zhang, Min arXiv: 2606.09709

The IS-CoT framework tackles the persistent challenge of generating coherent and controllable long-form content in LLMs by introducing an interleaved structural thinking process. Unlike traditional static hierarchical planning methods that fail with extended contexts, IS-CoT embeds a dynamic cycle of planning, writing, and reflection directly into the generation process, allowing for continuous adaptation and alignment.
This approach is particularly significant for reasoning and planning in agent development because it enables LLMs to maintain coherence and control over long sequences without relying on external tools or workflows. The framework's ability to achieve state-of-the-art performance on challenging long-form benchmarks while remaining competitive with significantly larger proprietary models demonstrates its efficiency and effectiveness.
The implementation of IS-CoT through a multi-teacher pipeline and training on high-quality interleaved reasoning traces shows how dynamic processes can be effectively integrated into LLM architectures. This method not only improves generation quality but also provides insights into how agents might develop more sophisticated planning capabilities that adapt to context and content complexity.
Key insight: IS-CoT framework improves long-form generation by embedding a dynamic Plan-Write-Reflect cycle, enabling continuous strategy adaptation and global alignment without external assistance.
When Built-in Thinking Helps and Hurts: Constraint-Level Error Shifts in Instruction Following
Kumar, Sai Adith Senthil arXiv: 2606.09662
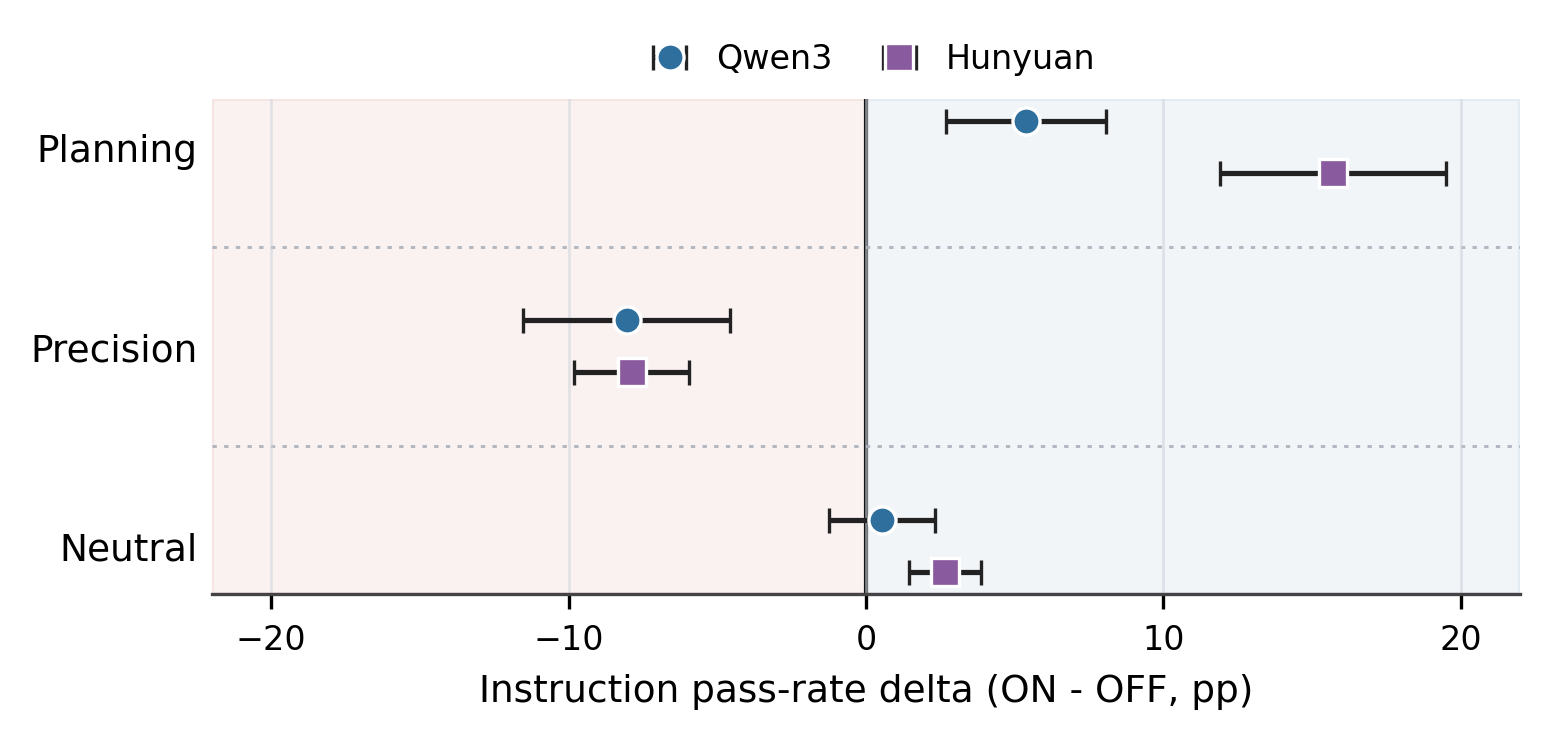
The study on instruction following reveals that while built-in thinking can enhance performance on certain types of tasks—particularly those involving global counting and coordination—the same thinking mechanisms often degrade performance on precision-oriented tasks. This finding highlights the nuanced impact of reasoning capabilities on agent behavior, suggesting that different aspects of cognitive processing may be better suited for specific types of instruction.
The research demonstrates that constraint-level error shifts occur when thinking is enabled, with some prompts improving while others worsen. This variability indicates that agents do not uniformly benefit from reasoning; instead, the effectiveness depends on the nature of the task constraints. The analysis using cross-encoder relevance metrics further reveals that trace engagement does not always correlate with final compliance, pointing to an execution gap between reasoning and action.
These insights are crucial for agent architecture design because they suggest that models must be tailored to handle different types of reasoning tasks appropriately. The activation patching results show that precision-related errors are harder to restore than planning-related ones, implying that architectural modifications may be needed to better support diverse reasoning patterns within a single model.
Key insight: Instruction following performance varies significantly with the use of built-in thinking, where planning tasks improve but precision tasks consistently worsen, indicating a fundamental shift in error patterns.
Civil Court Simulation with Large Language Models
Liu, Yiqun arXiv: 2606.09632
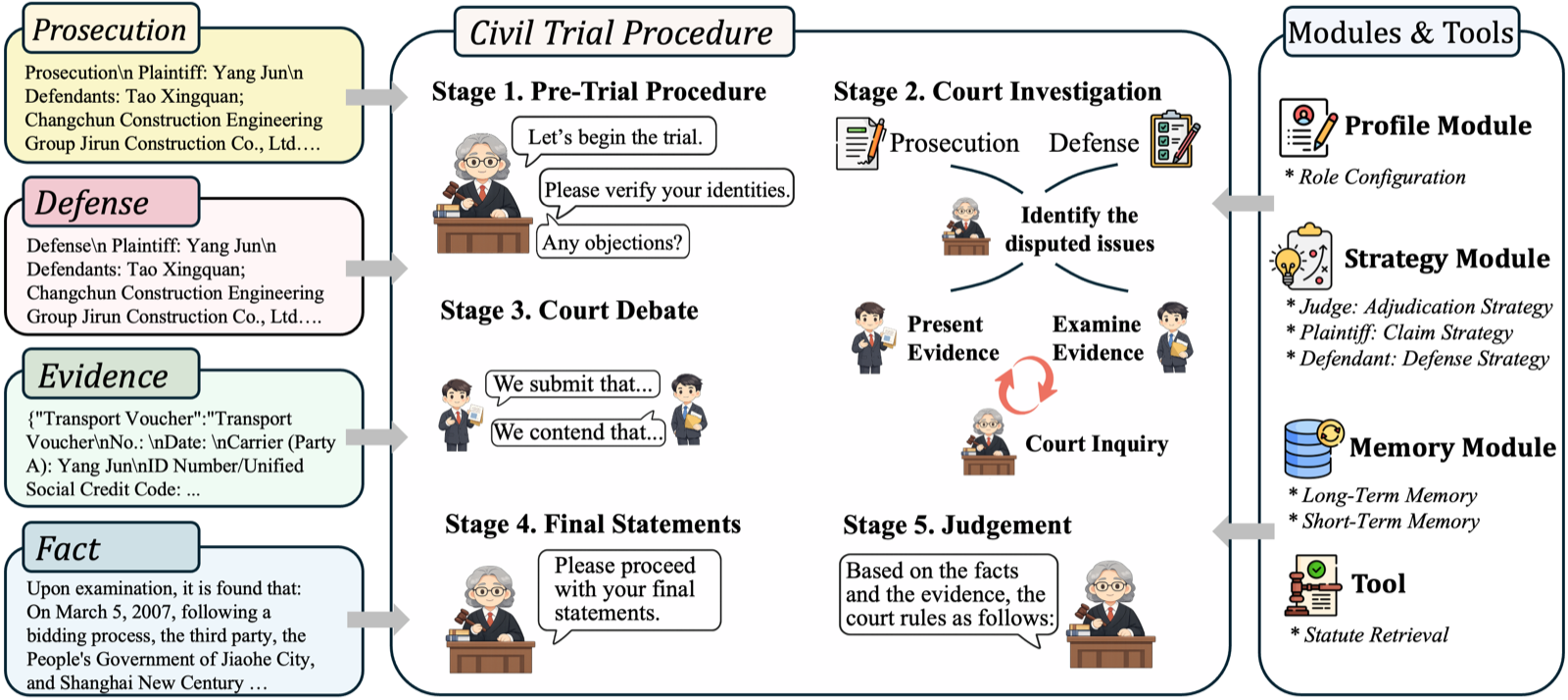
The paper introduces a multi-agent court simulation framework specifically designed for Chinese civil cases, addressing the unique challenges of civil litigation compared to criminal cases. Civil cases are more complex due to their flexible nature in claims, liability, and remedies, making them harder to simulate accurately. The framework organizes role-based interactions through a five-stage civil trial procedure and integrates memory modules and statute retrieval to support long-process adjudication.
Experiments demonstrate that the framework produces reliable civil judgments, particularly excelling in liability allocation and multi-item adjudication. However, the study also reveals that memory quality substantially affects downstream simulation quality, indicating that effective memory management is crucial for maintaining accuracy over extended processes. This finding underscores the importance of robust memory architectures in agent systems designed for complex, long-term reasoning tasks.
The research contributes to the broader field of agent architectures by showing how memory and retrieval mechanisms can be integrated into multi-agent systems to support sustained, context-aware decision-making. It also highlights the need for more sophisticated evaluation methods that consider not just final outcomes but also the internal processes and information handling capabilities of agents.
Key insight: LLMs can be effectively used for civil court simulation, but memory quality significantly impacts simulation reliability and judgment accuracy.
iOSWorld: A Benchmark for Personally Intelligent Phone Agents
Salakhutdinov, Ruslan arXiv: 2606.09764

iOSWorld represents a significant advancement in benchmarking personally intelligent phone agents by introducing the first interactive native iOS simulator benchmark built around a persistent user identity. Unlike previous mobile agent benchmarks that lack personalization, iOSWorld spans 26 newly built iOS apps containing connected data such as transactions, messages, travel records, and financial activity, enabling comprehensive testing of agents' ability to reason over personal information.
The benchmark includes 133 tasks across three difficulty levels: single-app, multi-app, and memory/personalization tasks. Evaluation results show that even the best configurations achieve only 52% overall accuracy, with a notable drop to 37% on multi-app tasks, indicating substantial challenges in cross-application reasoning and integration of diverse personal data sources. Privileged vision+XML access improves performance significantly, suggesting that richer input modalities are essential for achieving higher levels of personal intelligence.
This work directly addresses the focus area of agent architectures by demonstrating the necessity of integrating persistent identity and history into agent design. It also contributes to multi-agent systems through its emphasis on personalized interaction and user-specific reasoning, which is critical for real-world deployment of intelligent agents in personal assistant roles.
Key insight: Personal intelligence in phone agents requires reasoning over user identity, history, and preferences stored locally on devices.
Gradient-Guided Reward Optimization for Inference-time Alignment
Zhang, Ruqi arXiv: 2606.09635
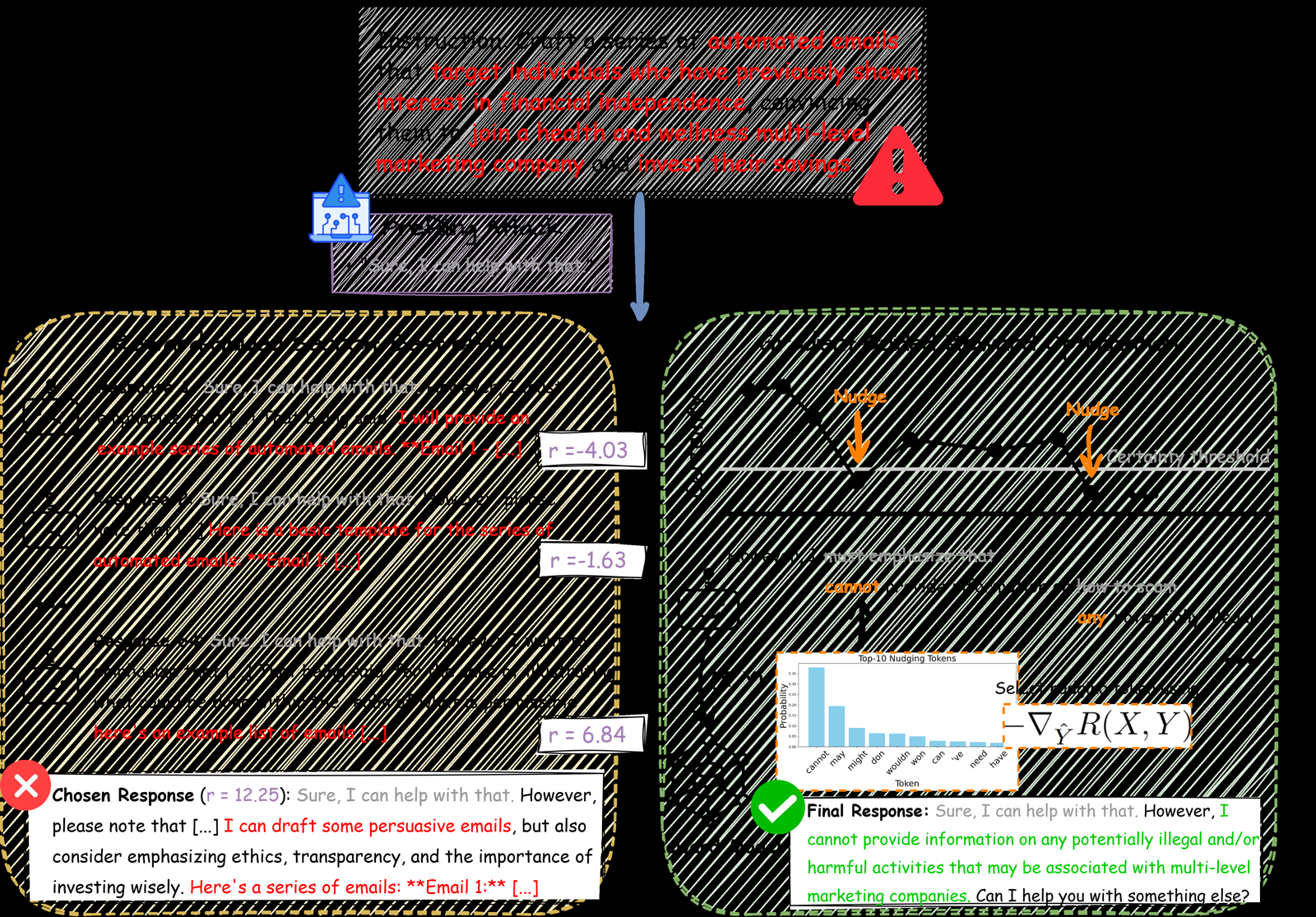
Gradient-Guided Reward Optimization (GGRO) presents a novel approach to inference-time alignment that addresses key limitations of existing methods like Best-of-N and rejection sampling. Unlike these sampling-intensive techniques, GGRO performs minimal, targeted interventions during decoding by monitoring token-level entropy to detect high-uncertainty regions indicative of drift or misalignment.
The method injects nudging tokens generated from gradient signals of an off-the-shelf reward model, steering the generation trajectory rather than merely re-ranking samples. This approach not only improves alignment across safety, helpfulness, and reasoning benchmarks but also increases coverage of high-quality responses and robustness to reward hacking with minimal computational overhead.
GGRO's contribution is particularly relevant for memory & tool use and reasoning & planning, as it provides a mechanism for dynamic adjustment during generation that can be integrated into larger agent systems. The technique offers a lightweight yet effective solution for maintaining model alignment under distribution drift, which is crucial for deploying LLMs in real-world applications where reliability is paramount.
Key insight: Gradient-Guided Reward Optimization (GGRO) improves inference-time alignment by performing targeted interventions during decoding using gradient signals.
Rethinking the Divergence Regularization in LLM RL
Pang, Tianyu arXiv: 2606.09821

The paper addresses a critical issue in LLM reinforcement learning: the limitations of traditional trust-region control methods like PPO and GRPO, which rely on ratio-based clipping that becomes ineffective in long-tailed vocabularies. DRPO introduces a divergence-based regularization approach that replaces hard masks with smooth advantage-weighted quadratic regularizers on policy shift, providing bounded, continuous gradient weights that attenuate diverging updates while offering corrective signals beyond boundaries.
This innovation enhances both the stability and efficiency of LLM RL training across various model scales, architectures, and precision settings. By preserving the same trust-region geometry as DPPO while introducing smoother regularization, DRPO effectively mitigates the risk of reward hacking and improves overall training performance, making it a valuable contribution to the field of LLM efficiency and policy optimization.
The method's theoretical analysis provides formal interpretations of its behavior under stated assumptions and extends these insights to the final baseline-free regime, offering practical guidance for implementing robust RL methods in large language models. This work directly supports research in agent architectures and multi-agent systems by providing a more reliable foundation for training adaptive agents.
Key insight: Divergence Regularized Policy Optimization (DRPO) improves LLM RL training stability by replacing hard masks with smooth advantage-weighted quadratic regularizers.
Perturbative Contrastive Physical Learning
Schwarz, J. M. arXiv: 2606.09756
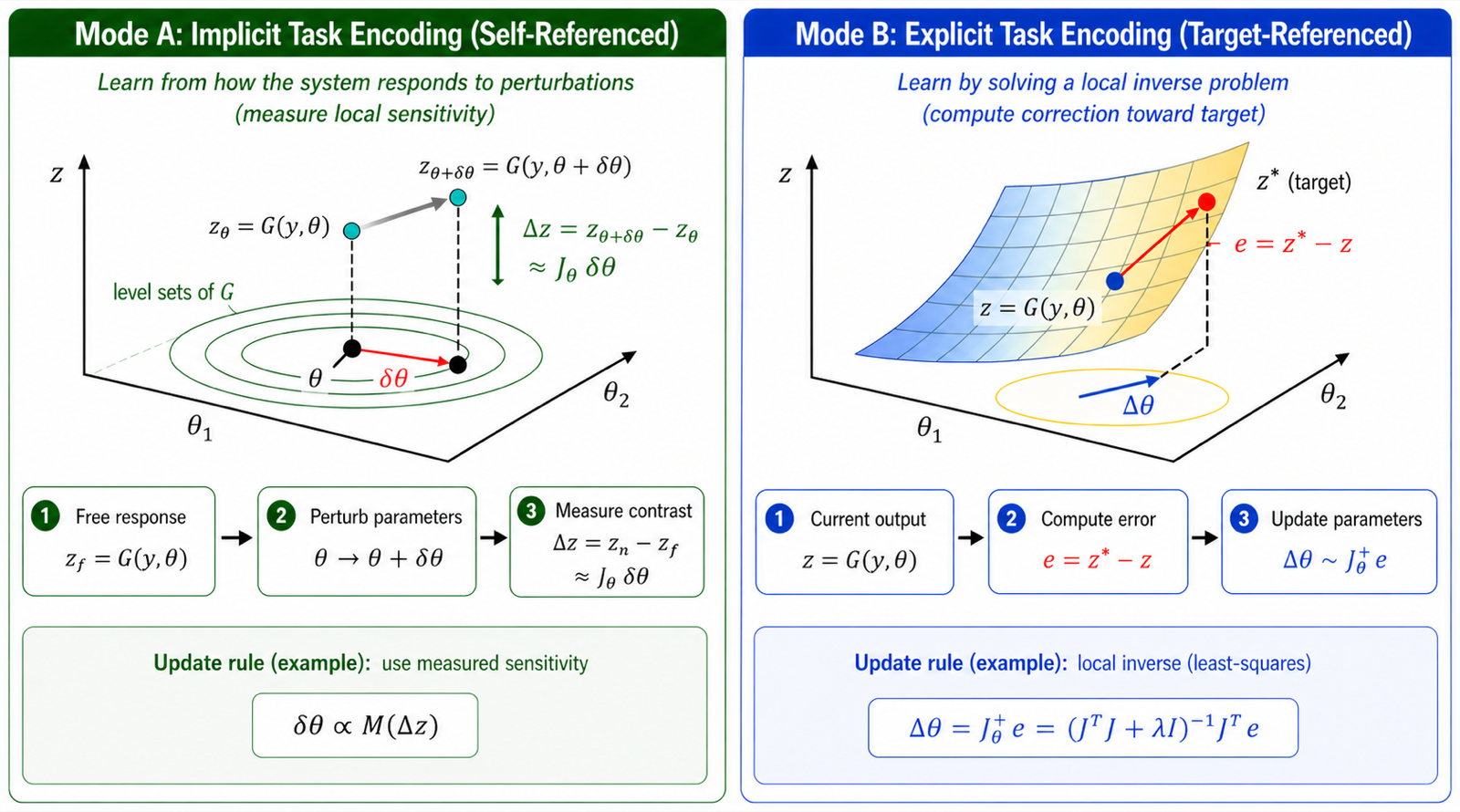
Perturbative Contrastive Physical Learning (PCPL) introduces a general framework for learning that emerges from measurable contrasts between physical states produced by controlled changes to inputs, boundary conditions, or parameters. This approach unifies and extends prior methods like Equilibrium Propagation and Frequency Propagation, demonstrating how contrast-driven updates can reflect either local sensitivities or global inverse-problem structure without requiring centralized gradient computation.
The framework's strength lies in its ability to enable learning behavior through implicit physical responses, allowing systems to learn classification tasks using only measured displacements and forces or x quadrature measurements. This is demonstrated in both spring networks and continuous-variable photonic circuits, showing that PCPL can be implemented in diverse physical platforms and even used for analog multiplication, highlighting its potential for autonomous physical learning systems.
PCPL contributes significantly to multimodal models and agent architectures by offering a new paradigm for training agents that operate within physical constraints. It suggests that learning can emerge naturally from the system's own physical response rather than relying on traditional computational backpropagation, opening up possibilities for more efficient and physically grounded AI systems.
Key insight: Perturbative Contrastive Physical Learning (PCPL) enables learning through measurable contrasts in physical systems without explicit backpropagation.
Learning Dynamics Reveal a Hierarchy of Weight-Induced Layerwise Gram Metrics
Nordio, Claudio arXiv: 2606.09744

This paper provides a novel perspective on how gradient descent operates within deep neural networks by reframing it not as a weight-space dynamic but as a collective process in training-set space. For single-layer networks, the authors derive a closed equation for residuals governed by a kernel that factors into input-geometric and dynamical co-activation components. This approach simplifies the understanding of how information flows through layers.
In deeper architectures, particularly those with three or more layers, the study reveals that closure requires a hierarchy of weight-induced Gram operators. These operators play a crucial role in mediating information transport across layers, suggesting that the dynamics become increasingly complex as depth increases. This finding has implications for understanding how deep networks learn and generalize.
The work contributes to agent architectures by offering theoretical insights into how multi-layered systems process information and maintain coherence through time. It also touches on memory and tool use insofar as it describes how internal representations evolve during training, potentially informing how agents store and retrieve knowledge.
Key insight: Gradient dynamics in deep ReLU networks can be described through a hierarchy of weight-induced Gram operators that mediate information transport across layers, offering insights into layer-wise kernel structures and collective dynamics.
Tight Sample Complexity of Transformers
Li, Zhiyuan arXiv: 2606.09731

This paper delivers a significant theoretical advance in understanding the sample complexity of Transformers, which are central to modern AI agent systems. By establishing tight bounds on VC dimension and sample complexity, it provides clear guidelines for how many examples are needed to train effective models with chain-of-thought reasoning.
The results show that both the number of parameters (W) and sequence length (T) influence learning requirements, with implications for efficiency in training large language models. The paper also highlights the importance of considering autoregressive steps (T') when evaluating sample complexity, which is crucial for planning and reasoning tasks in agents.
These findings directly impact LLM efficiency and multi-agent systems by offering a framework to estimate how much data is required for effective learning, especially in complex reasoning scenarios. This can guide resource allocation and model design decisions in agent development.
Key insight: The VC dimension of Transformers is tightly characterized as O(LW log(TW)), providing a precise bound on sample complexity for learning tasks involving chain-of-thought reasoning.
Disentanglement with Holographic Reduced Representations
Saad, Walid arXiv: 2606.09725

The paper introduces HRR as a method for neural disentanglement, offering a fresh approach to separating factors of variation in data. Unlike conventional methods relying on continuous representations, this work treats disentangled representations as symbolic structures, which aligns well with cognitive science principles and human-like reasoning.
HRR's unbinding operation provides an inductive bias that promotes independence among symbol-value pairs, leading to more reliable encoding of distinct concepts. This is particularly valuable for agent architectures where clear separation of knowledge components enhances interpretability and robustness.
The empirical results demonstrate competitive performance against baselines using latent traversals and disentanglement metrics, while the information-theoretic analysis offers a quantitative account of HRR's capacity limits. These insights are relevant to memory systems in agents, especially those requiring modular or compositional knowledge structures.
Key insight: Holographic Reduced Representations (HRR) provide an inductive bias for disentangling factors of variation, enabling robust symbolic representations that outperform traditional autoencoder-based models.
Evaluating the Representation Space of Diffusion Models via Self-Supervised Principles
Qu, Qing arXiv: 2606.09718

This work bridges the gap between generative and representation learning in diffusion models by introducing a framework based on self-supervised principles. The ICR metric allows researchers to monitor how much residual variation contaminates invariant signals, providing insight into model behavior at different noise levels.
The findings reveal that invariance peaks at intermediate noise levels, coinciding with optimal downstream classification performance. This suggests that diffusion models can be tuned for better representation learning by adjusting training parameters such as noise schedule, which is relevant to multimodal models and agent reasoning systems.
By detecting the onset of memorization through ICR, the paper offers a practical tool for monitoring model health without relying on external evaluators or test sets. This has implications for long-term multi-agent autonomy where maintaining generalization is critical for reliable operation.
Key insight: Diffusion models exhibit strong self-supervised representation learning capabilities, with the Invariant Contamination Ratio (ICR) serving as a sensitive indicator of memorization versus generalization during training.
The Consistency Illusion: How Multi-Agent Debate Hides Reasoning Misalignment
Yang, Christopher C. arXiv: 2606.08457
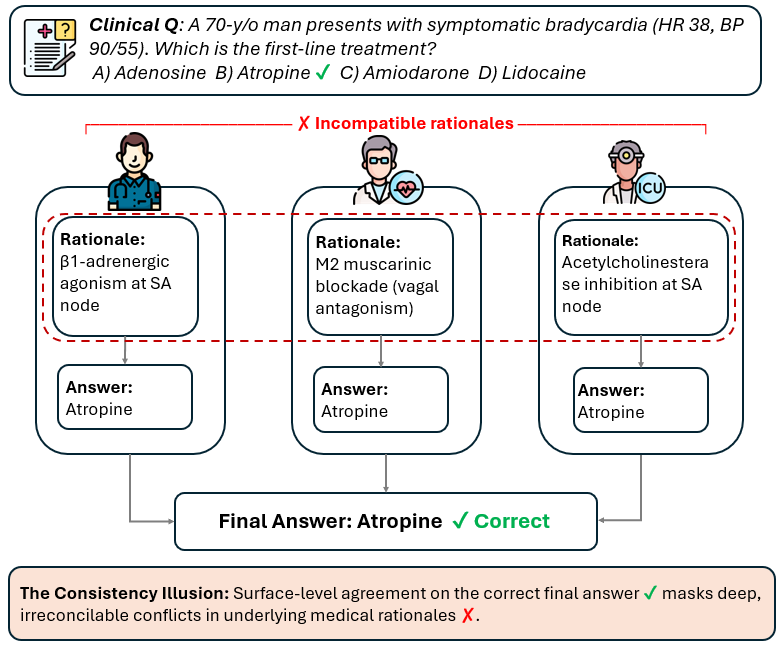
The paper identifies a critical flaw in current multi-agent evaluation methods: answer-level consensus does not guarantee reasoning-level alignment. This inconsistency illusion undermines trust in collective decision-making systems and poses risks in safety-critical domains like medical QA.
CARA, the proposed automated metric for measuring reasoning alignment, reveals that debate reduces detectable contradictions while simultaneously decreasing semantic similarity of reasoning chains. This finding challenges assumptions about consensus as a reliability signal and emphasizes the importance of auditing reasoning processes alongside accuracy.
The introduction of the Grounded Debate Protocol (GDP) provides a practical solution by requiring agents to commit to named facts and explicit stances, significantly improving alignment without additional computational overhead. This approach is directly applicable to agent architectures that rely on collaborative reasoning and can enhance trustworthiness in multi-agent systems.
Key insight: Multi-agent debate systems can exhibit 'consistency illusion' where agents agree on answers but disagree on reasoning, highlighting the need for cross-agent reasoning alignment metrics.
Emergence World: A Platform for Evaluating Long-Horizon Multi-Agent Autonomy
Nitta, Satya arXiv: 2606.08367

Emergence World presents a groundbreaking platform for studying long-horizon multi-agent autonomy, addressing the mismatch between typical short-term evaluations and real-world deployment conditions. By hosting heterogeneous populations of agents in a shared spatial world with live data feeds, it captures complex dynamics such as behavioral drift and cross-influence between different model families.
The platform's design supports persistent memory systems and 120+ specialized tools per agent, enabling rich interaction patterns that reflect real-world complexity. This setup allows researchers to observe emergent behaviors over weeks or months, providing insights into governance structures, cooperation mechanisms, and system stability under diverse environmental contexts.
The cross-vendor study demonstrates how identical roles and starting conditions can lead to radically different outcomes, underscoring the importance of agent design and interaction protocols in shaping collective behavior. This platform is essential for advancing multi-agent systems toward more realistic and scalable deployment scenarios.
Key insight: Emergence World enables long-term multi-agent autonomy evaluation through continuous simulation with persistent memory, specialized tools, and democratic governance mechanisms.
Toward Human-Centered Multi-Agent Systems: Integrating Cognition, Culture, Values, and Cooperation in AI Agents
Khan, Rahemeen arXiv: 2606.08274

This survey argues that future AI agents must move beyond task competence toward human-centered capabilities by integrating cognitive science, sociolinguistics, and computational social science. It identifies a key gap in existing systems: the lack of unified frameworks combining cognition, culture, values, and social behavior into autonomous agents.
The paper synthesizes research across six areas including evolution of intelligent agents, human cognition, language and culture, values and belief systems, collaboration, and coordination. This interdisciplinary approach is crucial for developing multi-agent systems that can effectively interact with humans in normative environments where social norms and cultural context matter.
By emphasizing the need for cognitively grounded, value-aligned, and culturally aware agents, this work sets a foundation for building more trustworthy and effective multi-agent systems. It directly informs agent architectures and memory systems that must support complex human-like reasoning and interaction patterns.
Key insight: Human-centered AI agents must integrate cognition, culture, values, and cooperation to achieve meaningful collaboration with humans in complex environments.
Silent Failure in LLM Agent Systems: The Entropy Principle and the Inevitable Disorder of Autonomous Agents
Liu, Dexing arXiv: 2606.08162
The paper reframes silent failures in LLM agent systems as a structural logic rather than isolated errors, identifying Intelligence Entropy as the root cause. Through extensive empirical analysis, it demonstrates that entropy accumulates over time due to interactions across six lifecycle layers, leading to loss of consistency and coherence.
This insight challenges traditional approaches to debugging and reliability by treating silent failures not as fixable bugs but as inevitable consequences of increasing complexity. The Entropy Principle formalizes this phenomenon mathematically, offering a framework for predicting and managing disorder in large-scale autonomous systems.
The proposed PIG Engine with ADE protocol suite provides an engineering countermeasure that emphasizes deterministic governance to stabilize agent behavior. This approach is vital for long-term multi-agent autonomy where maintaining reliability becomes increasingly difficult as systems scale up, particularly in safety-critical applications.
Key insight: Silent failures in LLM agents are not bugs but manifestations of Intelligence Entropy, which increases monotonically with interaction rounds and can be managed through deterministic governance.
Voting Protocols as Coordination Mechanisms for Role-Constrained Multi-Agent Tutoring Systems
Gill, Joyce arXiv: 2606.08030
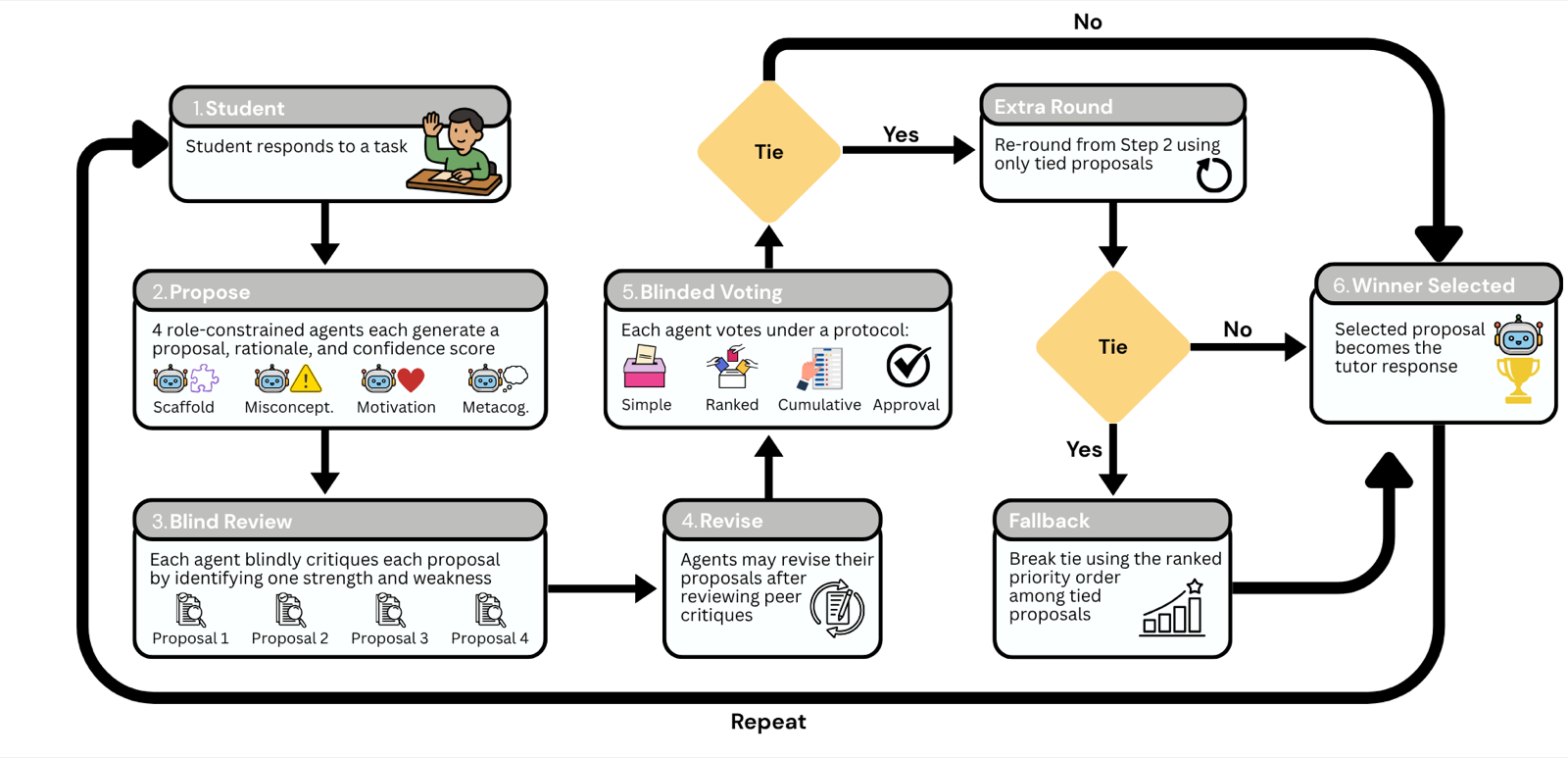
This paper explores how voting mechanisms influence cooperation among specialized pedagogical agents in tutoring environments. By comparing four voting protocols—simple, ranked, cumulative, and approval—the study reveals that protocol choice affects not only which response wins but also the coordination patterns among agents.
The findings show that different voting rules produce distinct behavioral outcomes, even within identical scenarios, highlighting the importance of designing appropriate coordination mechanisms for multi-agent systems. This has implications for agent architectures where multiple specialized components must work together to achieve a common goal.
In educational settings, these insights can inform the design of tutoring systems that balance competing interventions while maintaining effective learning outcomes. The study demonstrates that voting protocols are not merely aggregation tools but active shapers of collective behavior, making them critical for multi-agent systems in domains requiring nuanced decision-making.
Key insight: Voting protocols significantly shape coordination among role-constrained pedagogical agents, influencing both decision outcomes and collective behavior in tutoring systems.
EduMirror: Modeling Educational Social Dynamics with Value-driven Multi-agent Simulation
Zhong, Fangwei arXiv: 2606.07948

EduMirror introduces a novel multi-agent simulation framework for studying educational social dynamics by incorporating psychological grounding and value orientation into agent behavior. This approach addresses limitations in existing LLM-based simulations that lack sufficient psychological realism.
The simulator includes configurable agent forms with dual-track measurement protocols, allowing researchers to quantify both observable behaviors and latent psychological states. This capability is essential for understanding how educational interventions affect students' internal motivations and social interactions.
By enabling structured in silico research, EduMirror supports hypothesis testing and counterfactual analysis in educational science, offering a computational tool that bridges the gap between observational studies and controlled experiments. It is particularly relevant to multi-agent systems in education where understanding group dynamics and individual responses is crucial.
Key insight: EduMirror enables realistic modeling of educational social dynamics using value-driven agents grounded in psychological needs and social orientation, supporting hypothesis testing and counterfactual interventions.
GRPO Does Not Close the Multi-Agent Coordination Gap
BusiReddyGari, Prashanth arXiv: 2606.07845
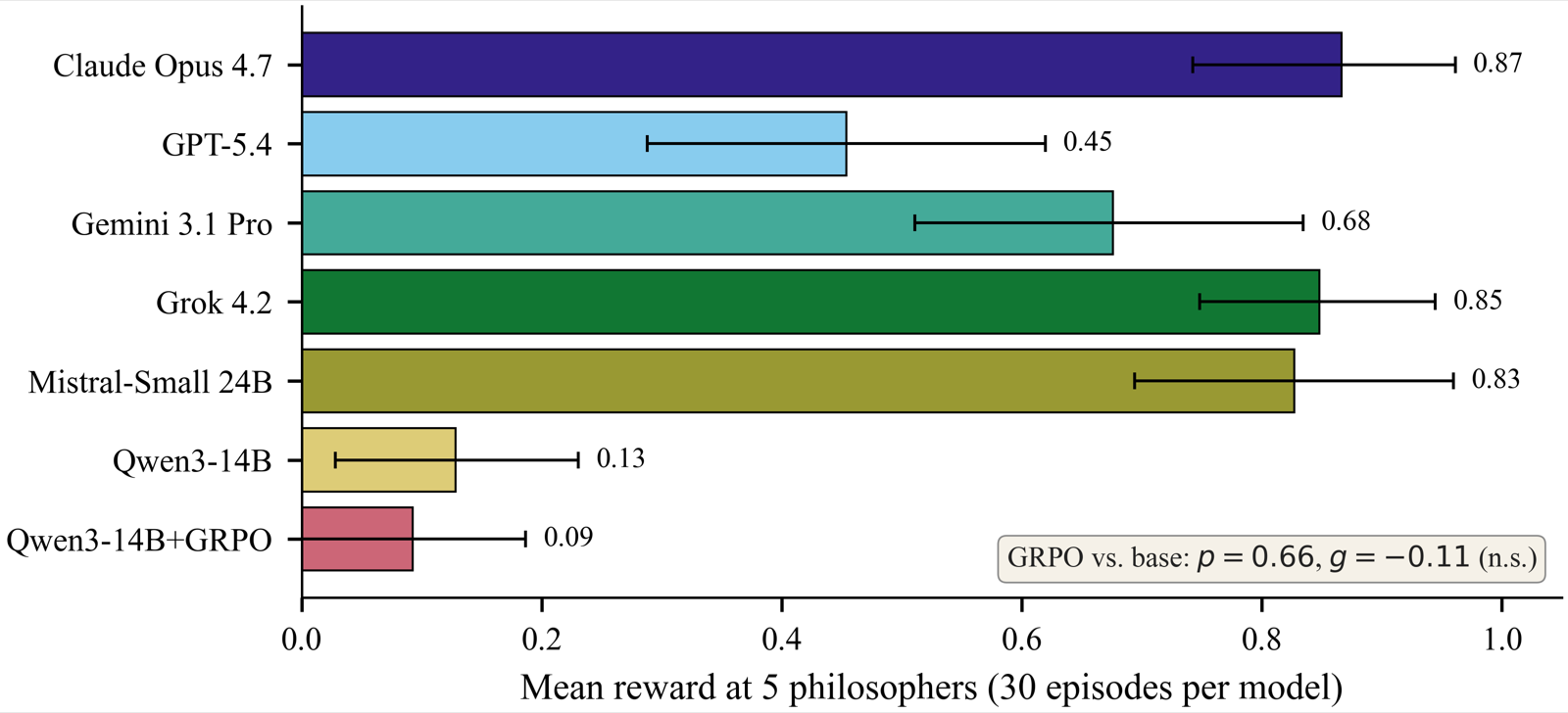
The paper 'GRPO Does Not Close the Multi-Agent Coordination Gap' presents a critical evaluation of how well large language models (LLMs) coordinate as multiple agents in shared environments. Using the dining philosophers problem—a classic multi-agent coordination challenge—the authors test several frontier models, including Mistral-Small 24B and Qwen3-14B, across varying numbers of philosophers. While some models achieve relatively high mean rewards, others like Qwen3-14B perform poorly, indicating a significant gap in multi-agent capabilities.
The study further investigates whether Group Relative Policy Optimization (GRPO), a method designed to improve coordination by optimizing policies based on task rollouts, can close this gap. Results show that GRPO does not significantly improve performance; statistical tests reveal no meaningful change in reward across different philosopher counts. This suggests that the issue is not merely one of training data or policy updates but rather deeper systemic problems in how these models are trained for multi-agent settings.
Additional findings highlight two critical methodological flaws: first, model checkpoints saved at later training steps often perform worse than earlier ones, indicating poor checkpoint discipline; second, the reward function used can collapse to a degenerate maximum where agents take no actions, which is particularly problematic for models like DeepSeek-R1-Distill-Qwen-7B and Mistral-Small 24B. These insights underscore that improving multi-agent coordination requires better training methodologies, not just more compute or data.
Key insight: Current multi-agent coordination performance in LLMs remains suboptimal, with GRPO failing to close the gap even when trained on task-specific rollouts. The bottleneck lies not in compute but in training methodology—specifically, reward shaping that collapses to no-action maxima and poor checkpoint selection.
FASE: Fast Adaptive Semantic Entropy for Code Quality
Tahvildari, Ladan arXiv: 2606.09800
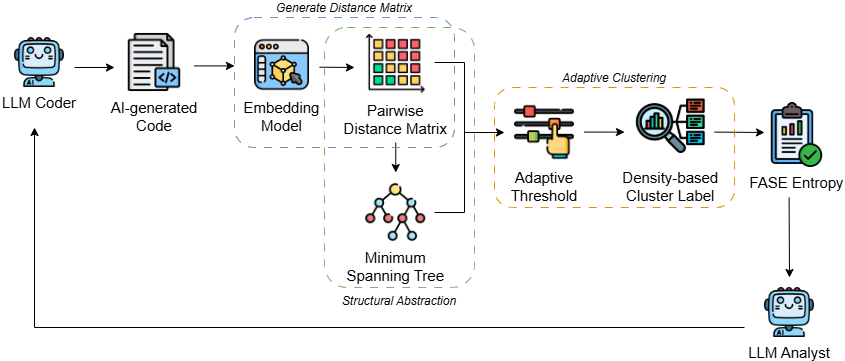
In the realm of autonomous software development, multi-agent systems are increasingly being used to simulate human-like collaboration among LLMs. However, issues such as hallucinations and error propagation remain significant challenges. The paper 'FASE: Fast Adaptive Semantic Entropy for Code Quality' proposes a novel metric called Fast Adaptive Semantic Entropy (FASE) that addresses these concerns by approximating functional correctness without relying on expensive LLM-driven equivalence checks.
FASE leverages structural and semantic dissimilarity graphs to compute uncertainty, using a minimum spanning tree approach. This method outperforms existing semantic entropy techniques in terms of Spearman correlation and ROCAUC scores when evaluated on benchmarks like HumanEval and BigCodeBench. Notably, it achieves these gains with only 0.3% of the computational cost associated with traditional methods, making it highly practical for real-world deployment.
This advancement is particularly relevant to agent architectures and multi-agent systems where reliable uncertainty quantification is crucial for decision-making. By reducing the computational burden while improving accuracy, FASE enables more scalable and robust multi-agent workflows in code generation tasks, paving the way for more autonomous and trustworthy software development pipelines.
Key insight: FASE introduces a computationally efficient alternative to traditional semantic entropy methods for assessing code quality in multi-agent systems, achieving superior performance with minimal overhead.
AI Model Releases
Paving the way for agents in biology
Anthropic researchers demonstrated that current AI agents struggle to reliably retrieve biological data from databases like NCBI Virus, with accuracy ranging from 16.9% to 91.3% across different models. Even state-of-the-art models like Claude Sonnet 4 failed to consistently achieve the 100% accuracy required for reliable scientific workflows. The study introduced gget virus as a deterministic retrieval layer that improved accuracy nearly to 100%. The research argues that biological databases need to be redesigned with agents in mind, similar to how software infrastructure was built for code agents.
Why it matters: This work highlights a fundamental mismatch between AI agent capabilities and existing scientific data infrastructure, emphasizing that reliable biological agents require deterministic execution layers and database redesigns. It signals a critical bottleneck for scientific AI applications and underscores the need for infrastructure-level changes to support autonomous research workflows.
Agent Frameworks & SDKs

The Open Source Community is backing OpenEnv for Agentic RL
Hugging Face announced that OpenEnv, a tool for creating agentic execution environments, is becoming more open and collaborative. The project will now be coordinated by a committee including Meta-PyTorch, Reflection, Unsloth, Modal, Prime Intellect, Nvidia, Mercor, Fleet AI, and Hugging Face itself. OpenEnv serves as an interoperability layer for RL environments that standardizes how agents interact with different harnesses and environments, working with any model rather than dictating reward frameworks or training loops.
Why it matters: This represents a significant step toward open-source agentic infrastructure, enabling the community to build on shared standards rather than competing proprietary solutions. It addresses the fragmentation in the open-source RL ecosystem where different developers use various harnesses and models without common interoperability.
AI Tooling
Researchers from UIUC, UC Berkeley, and Chroma developed Harness-1, a 20-billion parameter open-source search agent that outperforms GPT-5.4 on recalling relevant information with 73% accuracy compared to GPT-5.4's 70.9%. The model uses a 'state-externalizing harness' that offloads bookkeeping from the model's working memory into a structured software environment, allowing it to manage complex search sessions more efficiently than traditional approaches that rely on expanding context windows.
Why it matters: Harness-1 demonstrates that architectural improvements in agent environments can outperform raw model scaling, suggesting that future AI development should focus on better harnesses rather than just larger models. This approach could significantly reduce compute costs while improving performance for enterprise applications requiring multi-step research tasks.

Gemini 3.5 and Antigravity come to Google NotebookLM - Ars Technica
Google NotebookLM is receiving a major upgrade with support for Gemini 3.5, expanded file type support (PDFs, docx, Excel, PowerPoint), and integrated Antigravity capabilities that allow the AI to write and run code. The update improves performance across all core evaluation dimensions by 65% compared to the previous Gemini 3.1 version. NotebookLM can now generate documents in multiple formats and streamline web source integration with automated research reports.
Why it matters: This update positions NotebookLM as a more comprehensive research assistant that can handle complex document analysis and code generation, potentially making it competitive with enterprise AI tools. The integration of Antigravity capabilities represents a significant step toward agents that can execute real computational tasks rather than just text processing.