NVIDIA has unveiled Nemotron 3 Ultra, a 550B-parameter Mixture-of-Experts model optimized for long-running agent workflows with hybrid Mamba-Transformer architecture and NVFP4 quantization. Meanwhile, a community-developed job search assistant demonstrates practical applications of distillation techniques and multi-stage prompting for real-world problem solving. These developments highlight progress in both foundational model capabilities and agent application frameworks.
NVIDIA's Nemotron 3 Ultra represents a significant advancement in agent orchestration capabilities, featuring hybrid Mamba-Transformer layers for efficient long-context handling, NVFP4 quantization for cross-architecture GPU deployment, and LatentMoE for expert routing. The model achieves 5x higher throughput compared to other open models in its class while delivering frontier accuracy on coding, instruction following, and long-horizon planning tasks. Concurrently, a community-built job search assistant showcases practical applications of distillation techniques using Hugging Face's ecosystem, processing resumes through LinkedIn-shaped queries and scoring matches across five dimensions including skills match and experience relevance. This demonstrates how lightweight, efficient AI agents can be constructed using existing open-source tools without requiring large-scale infrastructure. Additionally, several research papers present new benchmarks and frameworks for evaluating agent performance, including SubtleMemory for relational memory discrimination, ToolMaze for dynamic replanning, and OpenSkill for self-evolution in open-world settings.
Research Papers
SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
Yang, Yang arXiv: 2606.05761

The SubtleMemory benchmark introduces a novel approach to evaluating how long-running AI agents handle complex relational memory structures. Unlike traditional benchmarks that focus on isolated recall, this work emphasizes the importance of understanding how memories relate to one another over time. This is particularly critical for persistent agents like OpenClaw, which accumulate vast collections of related memories during extended interactions.
The benchmark constructs relation-controlled latent semantic artifacts embedded within realistic user-agent histories, requiring agents to recover distributed relational structures during later queries. This design reveals that current systems remain weak on fine-grained relational memory discrimination, indicating a gap in how existing models process and utilize the contextual relationships between stored information.
By introducing diagnostic protocols that distinguish capability profiles across memory preservation, retrieval, and downstream reasoning stages, SubtleMemory provides actionable insights for improving agent architectures. It highlights that while agents may excel at basic recall tasks, they often fail when faced with nuanced or conflicting relational contexts—a key challenge in real-world applications where memory integrity directly impacts decision-making quality.
Key insight: Current AI agents struggle with fine-grained relational memory discrimination, where the ability to distinguish nuanced or contradictory relationships between memories is crucial for long-term performance.
When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Yin, Dawei arXiv: 2606.05806

ToolMaze addresses a critical gap in existing benchmarks by focusing on real-world tool failures rather than idealized 'happy paths'. The benchmark's two-dimensional design—combining DAG-based topological complexity and a taxonomy of tool perturbations—enables nuanced evaluation of agent resilience under various failure conditions.
The findings show that performance degrades significantly under implicit semantic failures, where agents suffer from a 37% drop in Perturbation Recovery Rate (PRR). This highlights the danger of over-trust in corrupted outputs and underscores the need for robust error recovery mechanisms. The observation that dynamic replanning is slower than basic task execution further emphasizes its role as a distinct bottleneck.
This work has implications for agent design, suggesting that future systems must incorporate more sophisticated fault-tolerance strategies beyond simple prompting or scaling. ToolMaze provides a framework for evaluating and improving agents' ability to adaptively navigate complex tool interactions, which is essential for deploying LLMs in production environments where reliability is paramount.
Key insight: Dynamic replanning and anomaly recovery in tool-integrated reasoning agents is a distinct bottleneck that does not scale with model size, especially under implicit semantic failures.
OpenSkill: Open-World Self-Evolution for LLM Agents
Sun, Lichao arXiv: 2606.06741

OpenSkill presents a novel approach to self-evolving LLM agents in truly open-world settings, where no curated learning loops or verification signals are available. The framework bootstraps both knowledge acquisition and skill refinement using only open-world resources such as documentation, repositories, and web content.
By synthesizing grounded knowledge into transferable skills and then refining those skills against self-built virtual tasks, OpenSkill creates a closed-loop system that improves over time without relying on ground-truth outcomes. This is particularly valuable for deployment scenarios where target-task supervision is unavailable or impractical.
The framework's success across multiple benchmarks shows its ability to generalize skills across different models and maintain alignment with ground-truth outcomes despite never accessing them directly. This suggests a promising direction for autonomous agents that can continuously adapt and improve in real-world environments without human intervention.
Key insight: OpenSkill demonstrates that agents can bootstrap self-evolution without any target-task supervision by leveraging open-world resources and synthesizing skills from documentation and repositories.
Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
Qu, Lin arXiv: 2606.07412
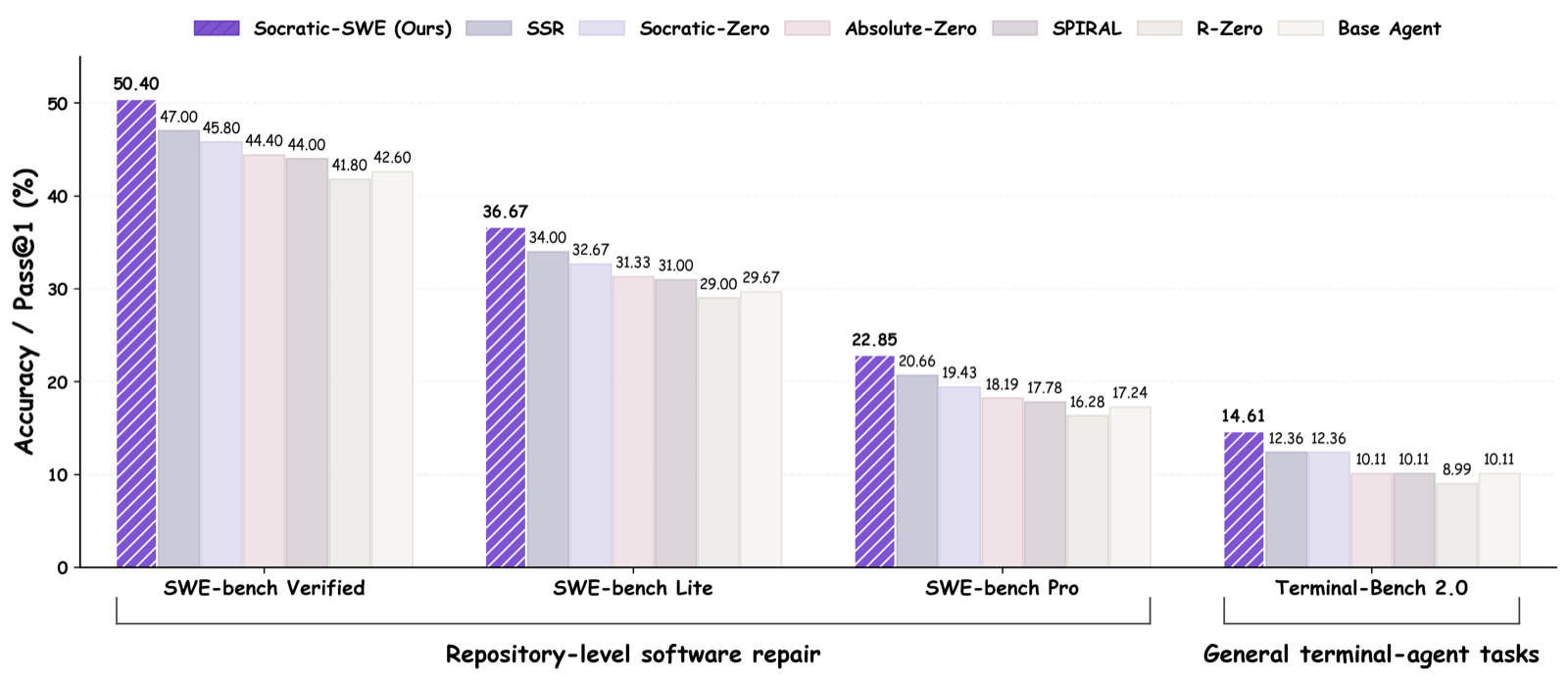
Socratic-SWE introduces a closed-loop mechanism that reuses an agent's own solving traces as training signals, addressing the limitation of synthetic data methods that are often independent of the agent's weaknesses. By distilling recurring failures and effective repair patterns into structured skills, it creates a curriculum that adapts to the agent's evolving capabilities.
The framework uses execution-based validation and solver-gradient alignment rewards to ensure that generated tasks are both verifiable and useful for improving the agent. This approach allows for continuous refinement of the agent's performance without requiring external supervision or large-scale human annotation.
Results show consistent improvement over self-evolving baselines across multiple SWE benchmarks, reaching 50.40% on SWE-bench Verified after three iterations. This demonstrates that solving traces can serve as a scalable substrate for self-evolving agents, offering a practical path toward more autonomous and capable software engineering systems.
Key insight: Socratic-SWE leverages historical solving traces to distill agent skills and generate targeted repair tasks, enabling scalable self-evolution in software engineering agents.
How AI Agents Reshape Knowledge Work: Autonomy, Efficiency, and Scope
Ma, Jerry arXiv: 2606.07489
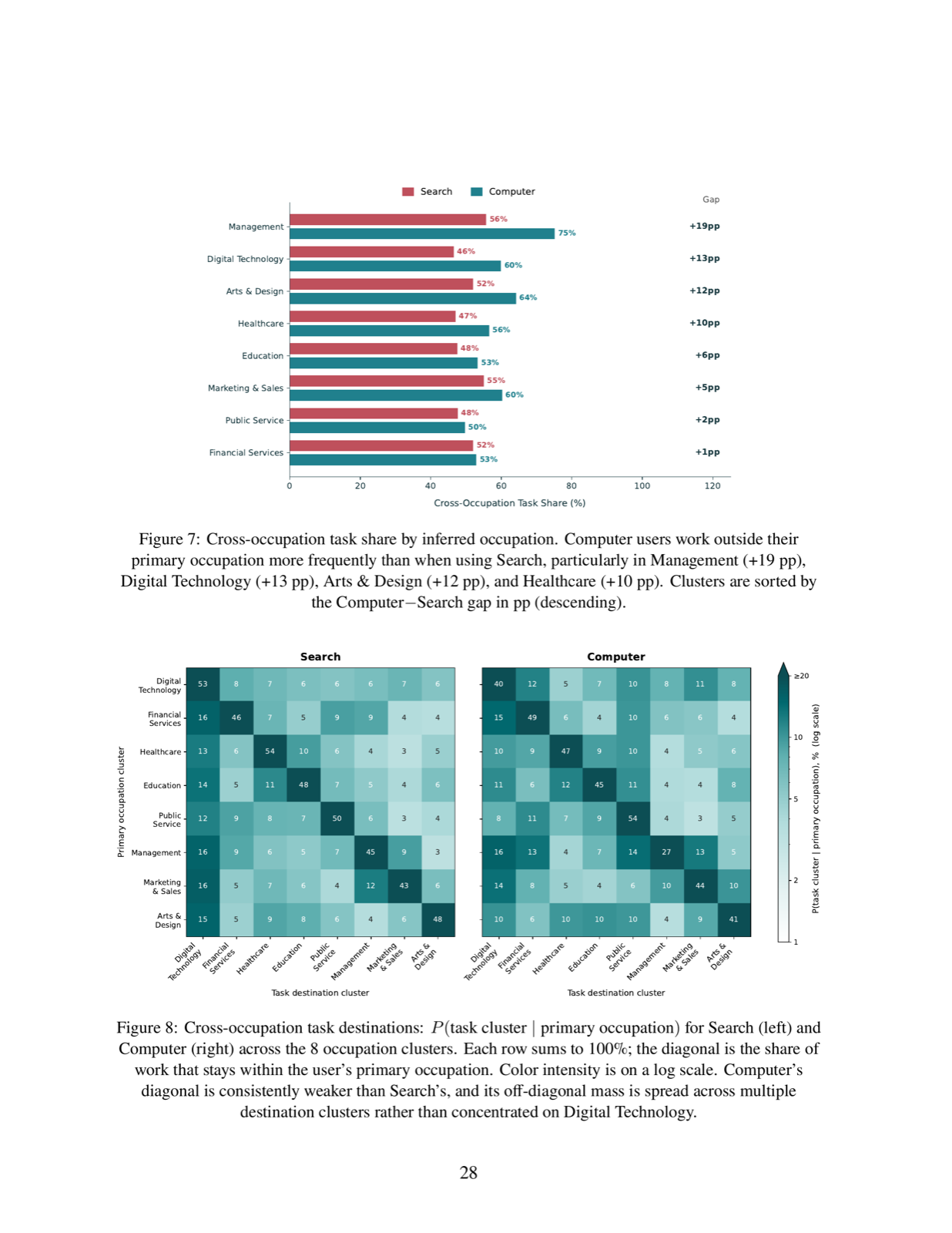
This empirical study using production data from Perplexity's Search and Computer products provides concrete evidence of how AI agents reshape knowledge work. The findings show that Computer, an autonomous agent, performs 26 minutes of autonomous work per session—compared to just 33 seconds for Search—indicating a substantial shift toward automation.
The study reveals that autonomy increases execution quality, with dissatisfaction rates 55% lower on Computer than on Search. Additionally, Computer reduces task completion time by 87% and cost by 94%, demonstrating clear efficiency gains over human workflows when equipped with Search alone.
Perhaps most significantly, Computer changes the scope of work attempted by users, enabling queries that cross occupational boundaries, require higher-order cognition, and bundle interdependent subtasks into single queries. This suggests that AI agents not only automate existing tasks but also unlock entirely new categories of work that were previously infeasible or too time-consuming for humans.
Key insight: AI agents significantly accelerate workflows, enhance output quality, reduce costs, and expand the scope of automated work compared to traditional conversational assistants.
DuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
Yin, Dawei arXiv: 2606.07299

DuMate-DeepResearch represents a significant advancement in deep research systems by decoupling the agent core from an extensible tool ecosystem, enabling explicit traceability of every decision and tool invocation. This design enhances process auditability—a crucial requirement for complex, long-horizon tasks where transparency is essential.
The framework incorporates three key mechanisms: graph-based dynamic planning that expands and revises research roadmaps through reflection and re-planning; recursive two-level execution that delegates sub-tasks to inner agents, stabilizing long-horizon execution; and rubric-based test-time optimization that dynamically generates quality criteria for evidence-grounded synthesis.
These innovations lead to state-of-the-art results on deep research benchmarks, achieving 58.03% overall score on DeepResearch Bench and 61.95% on DeepResearch Bench II. The system's ability to rank first in information recall and analysis further validates its effectiveness in handling complex, multi-step research tasks while maintaining high-quality outputs.
Key insight: DuMate-DeepResearch introduces a multi-agent framework with recursive search and rubric-grounded reasoning to tackle complex research tasks with improved auditability and performance.
Beyond Post-hoc Explanation: Toward Glassbox AI via Probabilistic Mediation
Leonelli, Manuele arXiv: 2606.07113

The paper introduces the Glassbox Framework as a solution to the opacity problem in large language models (LLMs), particularly in high-stakes applications like healthcare and legal reasoning. Unlike traditional approaches that offer post-hoc explanations, this framework proposes Bayesian networks as transparent mediation layers that encode domain knowledge and causal assumptions before inference occurs.
This approach enables auditable reasoning traces, uncertainty quantification, and contestable outputs by structuring the reasoning process itself rather than merely explaining it afterward. The authors argue that the current lack of structured reasoning in LLMs is the root cause of accountability issues, not simply the absence of explanations.
The framework's grounding in a benefit eligibility scenario highlights its practical applicability while identifying key challenges such as semantic alignment, dynamic model construction, and human governance. This work represents a principled shift toward AI systems that are both powerful and fundamentally accountable, addressing institutional and legal requirements for transparency.
Key insight: Large language models need ante-hoc probabilistic mediation for accountability, not just post-hoc explanations.
DyCon: Dynamic Reasoning Control via Evolving Difficulty Modeling
Zhang, Min arXiv: 2606.07108
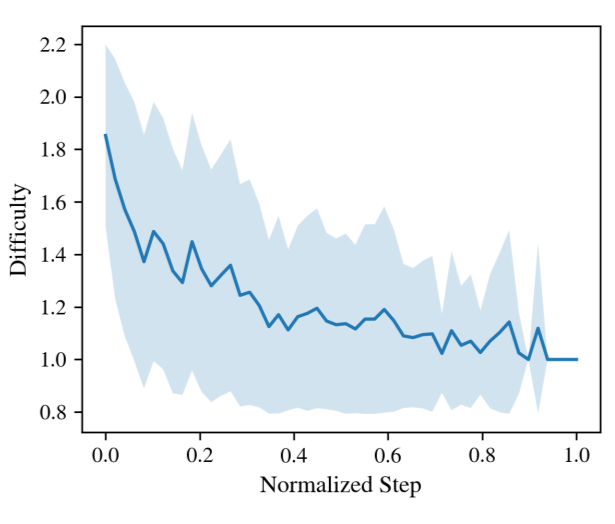
DyCon addresses the inefficiency of Large Reasoning Models (LRMs) by tackling the 'overthinking' problem through dynamic reasoning control. The key insight is that task difficulty evolves throughout the reasoning process and is linearly encoded in step-level embeddings, which can be leveraged for adaptive reasoning depth.
The framework operates training-free and uses latent step-level representations to model evolving task difficulty, enabling dynamic control of reasoning depth. This approach significantly reduces redundant steps across multiple benchmarks including math reasoning, general question answering, and coding tasks, while maintaining accuracy and generalization.
This work contributes to the broader goal of LLM efficiency by providing a method that adapts reasoning behavior in real-time based on internal representations, rather than relying on static difficulty estimates or task-specific training. It demonstrates how latent representations can be used for intelligent resource allocation during inference.
Key insight: Dynamic difficulty modeling can reduce overthinking in LLMs without sacrificing accuracy.
Agentopia: Long-Term Life Simulation and Learning in Agent Societies
Tao, Yunzhe arXiv: 2606.07513

Agentopia presents a comprehensive framework for long-term life simulation in multi-agent societies, where 100 agents pursue personal growth and develop social relationships over 10 simulated years. This approach explores how LLMs can learn from social experience to better replicate human behavior, addressing the question of whether LLMs can learn from such simulated social interactions.
The framework defines life reward to mirror human well-being and leverages this reward to train LLMs via rejection sampling. Extensive experiments show that agents exhibit rich emergent social behaviors, and life reward training effectively enhances the underlying LLM, leading to improved agent well-being in simulation and generalization to downstream role-playing benchmarks with a 15.6% improvement.
This work contributes significantly to multi-agent systems and agent architectures by demonstrating how long-term simulation can foster anthropomorphic capabilities in LLMs. It provides insights into social learning mechanisms that could inform future developments in autonomous agents capable of complex social interaction.
Key insight: Long-term life simulation in agent societies enables anthropomorphic capabilities through social learning.
Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
Yan, Rui arXiv: 2606.07502

EmbedFilter introduces a novel approach to refining text embeddings derived from LLMs by identifying and filtering out the subspace encoded in the unembedding matrix that excessively represents high-frequency tokens. This mechanism addresses a fundamental deficiency in how LLMs currently function as embedding models, where they struggle with nuanced semantics due to overrepresentation of frequent but uninformative tokens.
The method leverages the observation that text embeddings align with frequent tokens when projected onto vocabulary space, and by filtering this subspace, it enhances semantic representations. This approach not only improves downstream performance but also provides inherent dimensionality reduction, reducing index storage and speeding up retrieval while preserving embedding quality.
This work contributes to memory & tool use and LLM efficiency by offering a principled design for improving text embeddings without requiring additional training or complex architectures. It provides deeper insights into the mechanisms of LLM-based representations and inspires more effective approaches to text embedding training.
Key insight: Unembedding matrices in LLMs act as feature lenses that can be filtered to improve text embeddings.
M$^3$Exam: Benchmarking Multimodal Memory for Realistic User-Agent Interactions
Zhou, Xiaofang arXiv: 2606.07402
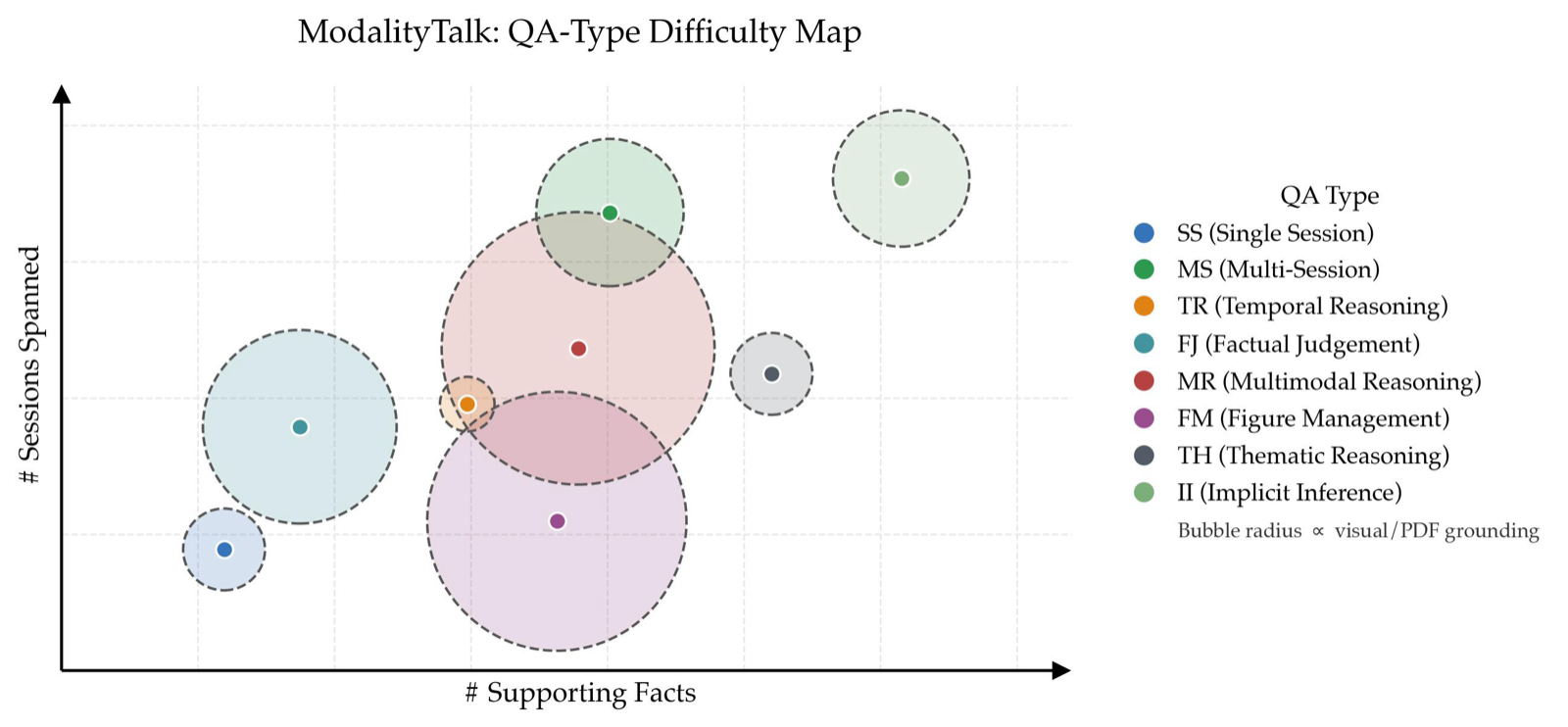
M$^3$Exam introduces a query-centric multimodal conversational memory benchmark designed to evaluate reasoning over authentic multimodal file interaction and interpretation of concealed user information, addressing limitations in existing benchmarks that assume human-human forms with sparse visuals.
The benchmark spans cross-modal grounding and implicit information inference across multi-dimensional evaluation, revealing persistent gaps in cross-modal grounding, cross-session reasoning, and the efficiency cost of accumulating multimodal context. This highlights the need for more realistic evaluation frameworks for multimodal memory systems.
The paper proposes M$^3$Proctor, a multimodal memory method that detects query modality bias and consumes raw visual sources only on demand, improving accuracy by 13% while cutting index-construction time and retrieved tokens by over 70%. This demonstrates practical improvements in efficiency and accuracy for real-world multimodal agent applications.
Key insight: Realistic user-agent interactions require new benchmarks for multimodal memory evaluation.
LLM-Guided Evolution for Medical Decision Pipelines
Nesterov, Aleksandr arXiv: 2606.07342
This paper introduces a novel approach to adapting large language models (LLMs) for clinical workflows using MAP-Elites evolution. Rather than relying on costly fine-tuning or manual prompt engineering, the authors frame medical decision-making as evolutionary searches over executable artifacts optimized by task-specific fitness functions. This method demonstrates significant improvements in accuracy and safety across three distinct medical domains: urgency triage, interactive consultation, and medical image classification.
In the urgency triage setting, evolved programs improved Semigran accuracy from 77.3% to 87.1% and emergency recall from 0.60 to 0.97, while also enhancing safety-weighted held-out MIMIC-ESI performance. The interactive consultation experiments showed that evolved policies improved the accuracy-cost frontier across multiple LLMs (Llama-3, Qwen-3.5, Gemma-4) and transferred well to held-out datasets. In medical image classification using PneumoniaMNIST, prompt-only evolution enhanced frozen MedGemma VLMs while preserving strict JSON outputs.
Qualitative analysis reveals that the gains stem from interpretable program-level mechanisms such as calibrated triage boundaries, targeted evidence acquisition, selective commitment, and finding-oriented visual decision rules. These findings suggest that evolutionary approaches can produce not just better performance but also more transparent and explainable solutions for safety-critical applications like healthcare, where understanding how decisions are made is as important as the decisions themselves.
Key insight: LLM-guided evolutionary algorithms can discover effective, interpretable medical decision strategies that outperform manual baselines in triage, consultation, and image classification tasks.
SV-Detect: AI-generated Text Detection with Steering Vectors
Gaintseva, Tatiana arXiv: 2606.07313

The paper proposes SV-Detect, a fake-text detection method that leverages steering vectors derived from the hidden representations of a frozen language model. At each layer, the approach constructs directions that separate human-written from machine-generated text and represents inputs by their alignment with these directions. A lightweight classifier trained on these projection features yields final detection scores.
This method achieves strong performance both in-distribution and under distribution shift, including across domains, source models, and machine-editing transformations such as polishing and rewriting. The key innovation lies in treating fake-text detection as a representation-space probing problem, where steering vectors capture stylistic cues beyond surface features. Interpretation analyses confirm that the learned directions align with recognizable stylistic patterns while capturing substantial additional signal.
The approach positions itself as a simple yet effective solution for AI-generated text detection, particularly relevant in contexts where distributional shifts are common. By focusing on representation space rather than superficial textual features, SV-Detect offers a more robust and generalizable framework that could be valuable for content verification, plagiarism detection, and ensuring authenticity in digital communications.
Key insight: Steering vectors extracted from frozen language model hidden representations provide a robust and effective solution for detecting AI-generated text under distribution shifts.
When Large Language Models Fail in Healthcare: Evaluating Sensitivity to Prompt Variations
Alkaeed, Mahdi arXiv: 2606.07237
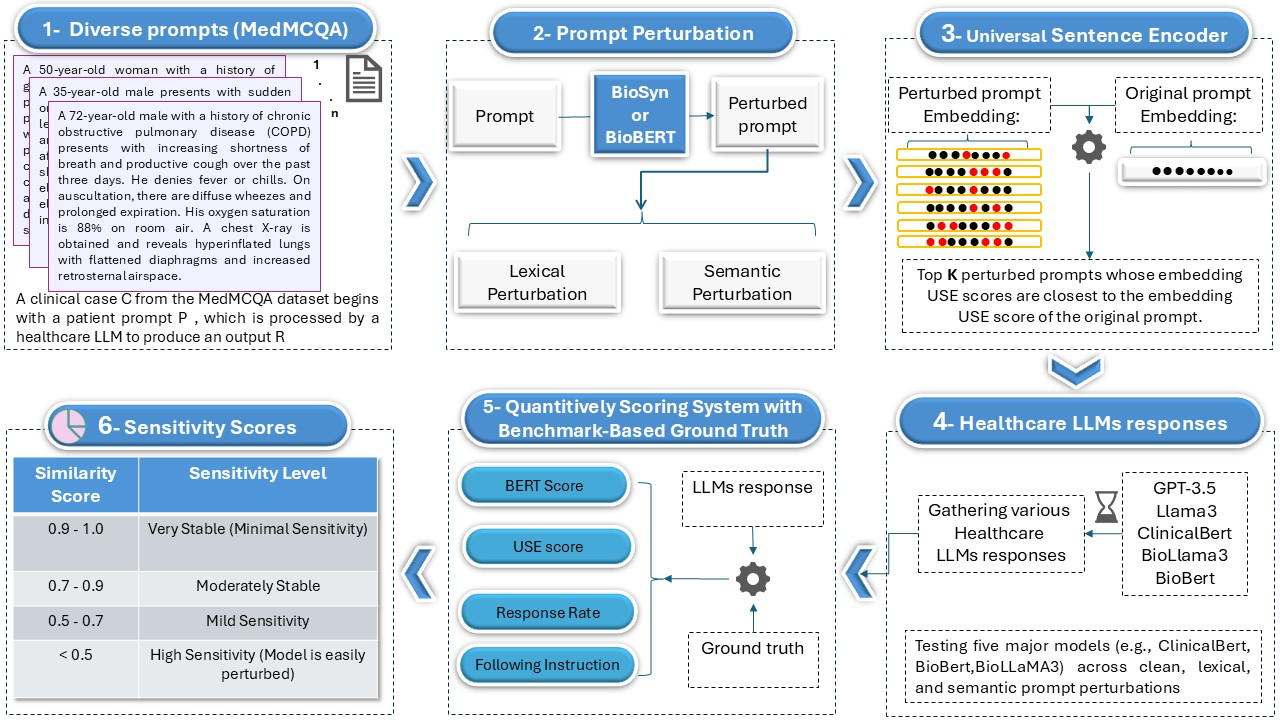
This study systematically evaluates the robustness of both general-purpose and medical-specific LLMs against prompt variations using the MedMCQA benchmark. The research reveals that LLMs are not intrinsically safe in healthcare settings, as even minor lexical or syntactic changes can alter clinical advice significantly. This sensitivity poses serious risks in safety-critical applications where reliability is paramount.
The findings show that while models may be resilient to simple lexical substitutions or paraphrasing, they often break down under syntactic reordering or misleading contextual cues. Adversarial manipulations were found to lead to clinically dangerous outputs such as recommending incorrect dosages or omitting critical findings. This fragility was observed across both general-purpose and domain-specific LLMs, indicating that the problem is not limited to particular model architectures or training methods.
These results highlight a fundamental challenge in deploying LLMs for healthcare applications: ensuring consistent and reliable performance under varying input conditions. The study underscores the need for more robust prompting strategies, better evaluation frameworks, and potentially new model architectures that can maintain stability and safety even when faced with subtle prompt variations.
Key insight: LLMs are highly sensitive to subtle prompt variations, especially in healthcare applications, where even minor rephrasing can lead to dangerous clinical outputs.
Sparse Subspace-to-Expert Sharing for Task-Agnostic Continual Learning
Jannesari, Ali arXiv: 2606.07500

The paper introduces SETA (Sparse Experts for Task Agnostic Continual Learning), a novel framework addressing the plasticity-stability dilemma in LLM continual learning. Unlike existing methods that treat all parameters uniformly, SETA performs adaptive sparse subspace decomposition into task-specific expert modules and shared experts, effectively isolating knowledge.
The approach uses adaptive elastic anchoring and routing-aware regularization to protect shared knowledge at both weight and routing levels, while enabling a unified gating network for automatic expert combination during inference. This structure allows the model to maintain early-task knowledge and improve backward transfer on benchmarks like LLaMA-2 7B and Qwen3-4B.
SETA's key innovation lies in its ability to separate specific task knowledge from shared capabilities, thereby mitigating catastrophic forgetting without sacrificing performance gains from new tasks. This method represents a significant step forward in developing LLMs that can continuously learn and adapt while retaining previously acquired knowledge—a crucial capability for real-world deployment scenarios.
Key insight: SETA framework enables task-agnostic continual learning by decomposing parameters into sparse subspaces, separating task-specific and shared knowledge to prevent catastrophic forgetting.
CoMetaPNS: Continually Meta-learning Personalized Neural Surrogates for Cardiac Electrophysiology Simulations
Wang, Linwei arXiv: 2606.07488
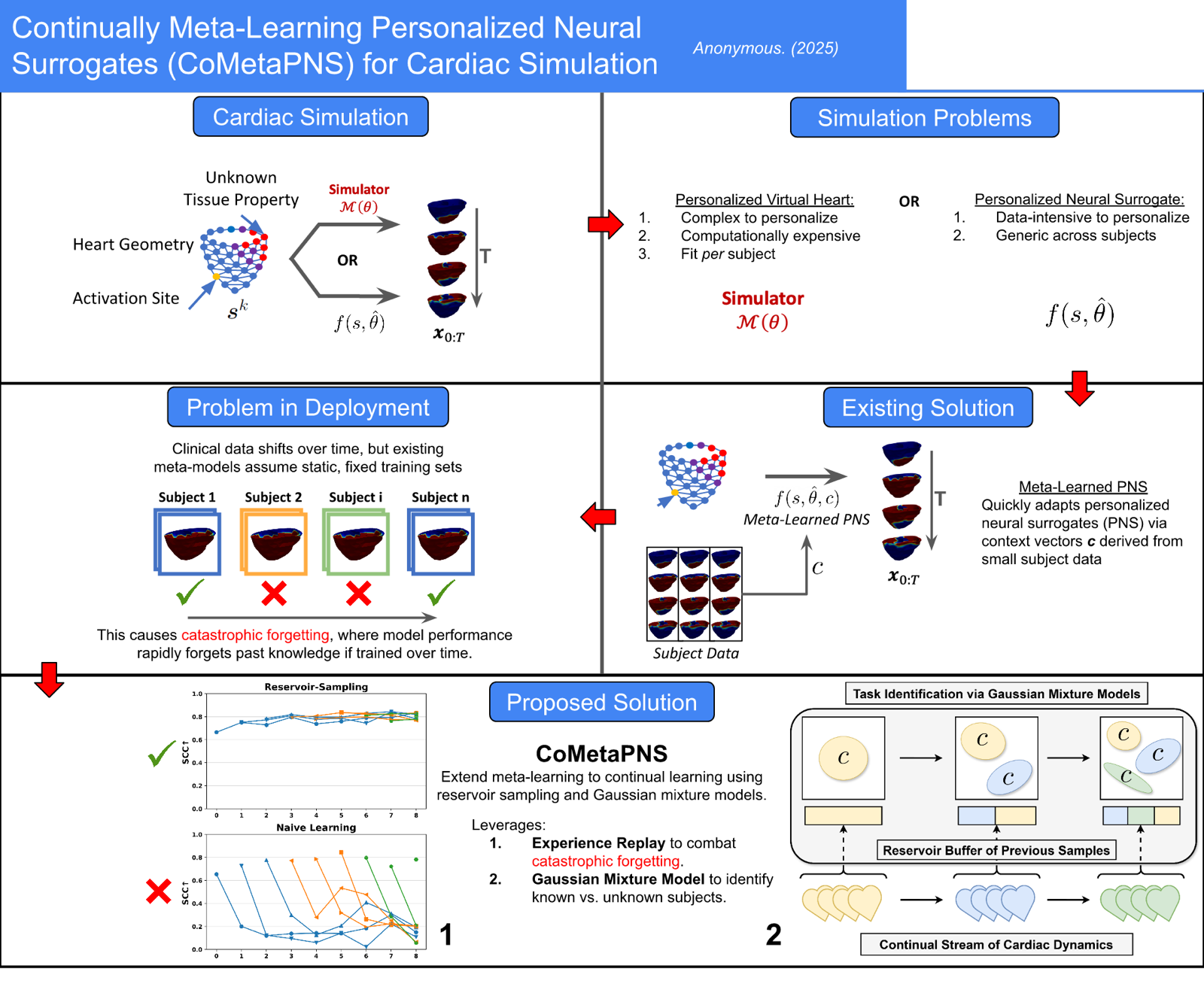
This paper presents CoMetaPNS, a novel continual meta-learning framework for personalized cardiac electrophysiology simulations. The approach addresses the challenge of model personalization and computational cost in virtual heart simulations by learning to personalize surrogates using limited subject-specific context data through few-shot generative modeling.
The key innovation is the use of a continual Bayesian Gaussian Mixture Model over a memory buffer to infer identifiers and relationships of incoming data over time, enabling effective meta-learning even when new data arrives sequentially. This allows the framework to not only continually integrate information but also identify whether incoming data stems from known or unknown dynamics sources.
Empirical results on synthetic cardiac data demonstrate superior simulation forecasting, computational scalability, and resilience to catastrophic forgetting compared to existing baselines. The method's ability to handle unlabeled sequential data without requiring full retraining makes it particularly suitable for clinical settings where data arrives incrementally and retraining is infeasible.
Key insight: A continual meta-learning framework enables personalized neural surrogates that can integrate new data without catastrophic forgetting and identify unknown dynamics sources.
Unsupervised Continual Clustering via Forward-Backward Knowledge Distillation
Armanfard, Narges arXiv: 2606.07474
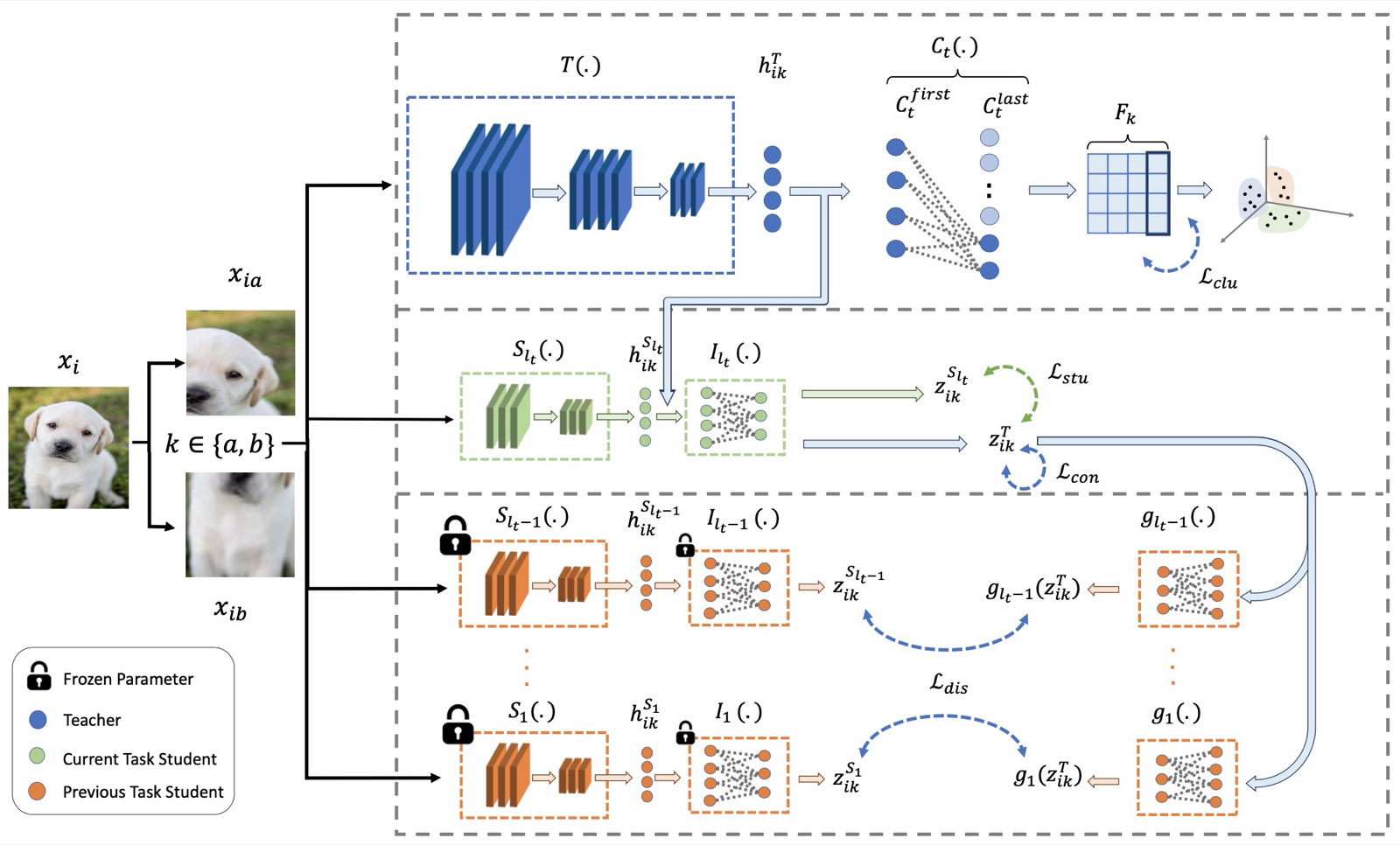
The paper addresses a critical challenge in unsupervised continual learning (UCL): catastrophic forgetting, where models lose previously learned information when encountering new tasks. Unlike traditional approaches that rely on replay buffers or explicit labels, this work proposes Unsupervised Continual Clustering (UCC) with Forward-Backward Knowledge Distillation for Continual Clustering (FBCC). FBCC employs a continual teacher network equipped with a clustering projector and lightweight task-specific student networks.
The dual-phase forward-backward distillation process allows the teacher to learn new clusters while preserving previously discovered cluster structures. This is achieved without storing past data, which is particularly valuable for privacy-sensitive applications. The method demonstrates superior performance across four benchmark datasets, consistently outperforming existing continual learning baselines in clustering accuracy.
FBCC represents a pioneering approach to UCC and offers practical advantages over current methods that often struggle with memory constraints or privacy concerns. By focusing on clustering-specific objectives rather than generic learning strategies, it opens new avenues for developing more robust and scalable unsupervised continual learning systems.
Key insight: FBCC introduces a novel forward-backward knowledge distillation approach for unsupervised continual clustering that preserves past cluster structures without storing historical data, significantly reducing catastrophic forgetting.
Hierarchical Certified Semantic Commitment for Byzantine-Resilient LLM-Agent Collaboration
Wang, Xianbin arXiv: 2606.07316

This paper presents Hierarchical Certified Semantic Commitment (H-CSC), a Byzantine fault tolerance-inspired protocol designed specifically for large language model (LLM) agent collaboration. Unlike naive aggregation methods that hide decision-making behind single verdicts, H-CSC provides typed outcomes—semantic_commit, verdict_commit, or explicit abort—based on embedding-derived signals over structured proposals.
The protocol's key innovation lies in its ability to handle stochastic, structured natural-language inputs while maintaining robustness against Byzantine agents. It achieves low angular deviation (0.31 to 2.04 degrees) in BFT-feasible buckets and correctly aborts beyond-BFT rounds (n<3f+1). In real-world benchmarks like MVR-50, H-CSC commits with high accuracy (0.90/0.92) while maintaining strong safety floors (<0.04).
H-CSC also emits embedding-backed semantic_commit digests on 74%/72% of rounds, offering typed provenance—a feature absent in simpler verdict-only baselines. This capability is crucial for enabling trust and accountability in multi-agent systems where agents must collaborate reliably despite adversarial behavior.
Key insight: H-CSC introduces a typed finality mechanism for Byzantine-resilient LLM agent collaboration, enabling semantic commitments with distinct outcomes (commit, verdict_commit, abort) based on structured natural-language proposals.
Learning Multi-Agent Communication Protocol: Study on Information Entropy Efficiency in MARL
Yu, Jiadong arXiv: 2606.07200

The paper introduces the Information Entropy Efficiency Index (IEI), a novel metric for evaluating communication efficiency in multi-agent reinforcement learning (MARL). IEI quantifies the ratio between message entropy and task performance, encouraging agents to develop compact yet effective communication strategies.
By incorporating IEI into training loss functions, the authors demonstrate that agents can achieve equivalent or superior task performance compared to baseline methods while significantly improving communication efficiency. This challenges prevailing assumptions in MARL that performance gains are only possible through complex architectures or increased communication overhead.
The findings suggest a promising direction for scalable MAS development, where efficient information exchange becomes as important as raw performance. The approach could be particularly valuable in resource-constrained environments or applications requiring real-time decision-making and minimal communication latency.
Key insight: IEI metric enables agents to learn efficient communication protocols by balancing task performance and information compactness, challenging the assumption that better performance requires increased complexity or overhead.
From Privacy to Workflow Integrity: Communication-Graph Metadata in Autonomous Agent Interoperability
Dangol, Bijaya arXiv: 2606.07150
This paper redefines the threat landscape in autonomous agent interoperability by shifting focus from privacy alone to workflow integrity. While traditional transport protocols protect message content, they leave communication graphs—indicating which agents contact whom, when, and how often—in the clear.
The authors argue that these graphs are semantically rich and prospectively informative, allowing observers to infer pending workflows, tasks being assembled, and likely actions. At machine speed, this predictive leverage can be exploited by adversaries to interfere with autonomous operations before they complete.
Through a case study using an A2A capture, the paper demonstrates how metadata alone—without payloads—can classify task classes well above chance. The implications are profound: protecting communication metadata is not just about privacy but about safeguarding the integrity of complex workflows and preventing pre-emptive interference.
Key insight: Agent communication graphs reveal more than just privacy concerns—they expose workflow integrity risks, where metadata can be leveraged to predict and act upon future actions before they occur.
The Three-Ring Architecture: Governing Agents in the Era of On-Platform Organisations
Diez-Fernandez, Marta arXiv: 2606.07119
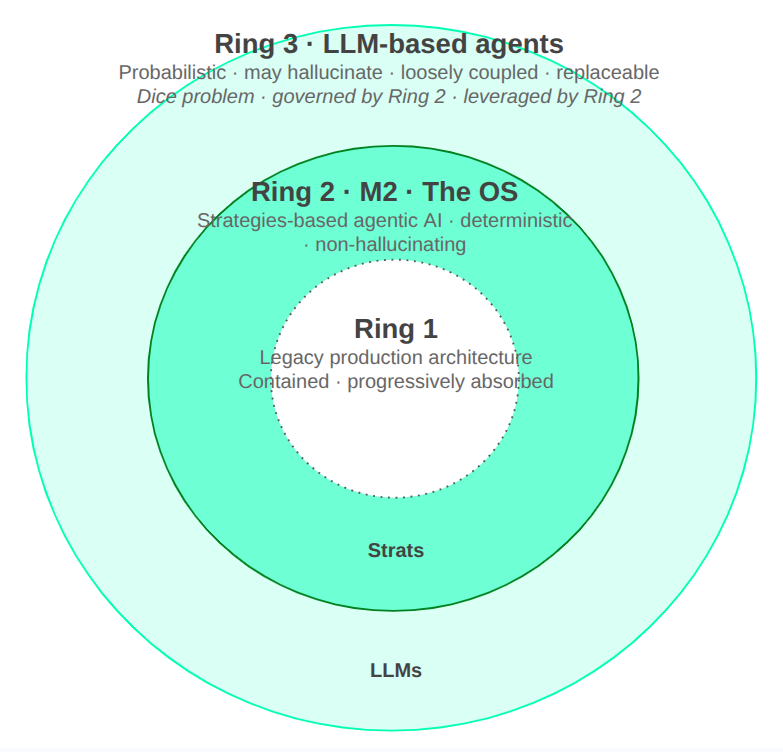
This paper proposes the Three-Ring Architecture as a governing framework for enterprise AI deployment, addressing structural failures in current agentic capabilities. Ring 1 represents existing production architecture; Ring 2 is the M2 federation layer built on strategies-based agentic AI; and Ring 3 is the LLM-based frontier intelligence layer.
The key contribution is the formal distinction between risk profiles of Ring 2 (deterministic, traceable, recoverable) and Ring 3 (non-deterministic, untraceable deviations). Ring 2 functions as the operating system of the agentic enterprise, performing resource abstraction, process coordination, and permission enforcement at the organizational level.
The architecture is validated across sectors including financial services, government, and compliance. It highlights that as LLM capabilities increase, so does the need for robust governance structures. More capable non-deterministic actors produce larger consequences when they deviate, making Ring 2 not an add-on but a necessary condition for control and compliance.
Key insight: The Three-Ring Architecture formalizes governance infrastructure for on-platform organizations, distinguishing deterministic strategies-based agents (Ring 2) from non-deterministic LLM-based agents (Ring 3), each with distinct risk profiles.
Learn to Match: Two-Sided Matching with Temporally Extended Feedback
Jaques, Natasha arXiv: 2606.06744
The paper introduces Learn2Match, a multi-agent reinforcement learning benchmark for dynamic matching markets characterized by temporally extended feedback. Unlike traditional models that assume immediate sub-Gaussian feedback, this framework captures settings where payoff-relevant information unfolds gradually through interviews, repeated interactions, and evolving latent profiles.
Learn2Match supports decentralized decision-making over whom to interview, match with, and when to dissolve a match, evaluating policies using regret, social welfare, and an information-friction loss. Independent PPO agents achieve higher cumulative social welfare and lower regret than CA-ETC under temporally extended feedback, demonstrating the promise of MARL for dynamic matching markets.
However, PPO still incurs higher information-friction loss, indicating that end-to-end MARL lacks the coordinated exploration structure of matching-bandit methods. This suggests a path forward: developing algorithms that combine RL adaptability with statistical discipline and structural awareness to better handle complex, evolving matching environments.
Key insight: Learn2Match framework models dynamic two-sided matching markets with temporally extended feedback, showing that MARL agents can adapt to evolving preferences and improve social welfare over time.
A Swarm Approach to Public Transit Using On-demand Routing in a Slime-Mold-Inspired Framework
Swissler, Petras arXiv: 2606.06189
This paper introduces an innovative application of bio-inspired algorithms to public transit systems, leveraging the collective behavior of slime molds to optimize on-demand routing. The core innovation lies in transitioning from centralized, manually-scheduled DRT systems to a distributed swarm framework where vehicles dynamically bid for passenger allocations and perform dynamic transfers. This approach directly addresses key limitations of traditional transit models—high operating costs and low reliability—by enabling adaptive network responses to varying demand patterns.
The experimental validation across suburban, urban, and semi-rural scenarios demonstrates substantial performance gains, with passenger delivery rates increasing by 28% to 101% compared to fixed-network approaches. These results suggest that swarm intelligence can be effectively applied to real-world transportation challenges, offering a scalable solution for optimizing resource allocation in complex environments. The use of OpenStreetMap data ensures the approach's applicability to diverse geographic contexts.
While this work focuses on transit optimization rather than AI agent development per se, it exemplifies how multi-agent systems principles can be adapted to solve practical problems. The cooperative bidding mechanism and dynamic transfer protocols mirror key concepts in multi-agent coordination, making this research relevant for understanding distributed decision-making in agent-based systems. The framework's potential integration with LLMs for more sophisticated route planning or passenger interaction further underscores its significance for future AI agent architectures.
Key insight: A slime-mold-inspired swarm approach for demand-responsive transit significantly improves passenger delivery rates and reduces walking time by enabling dynamic, cooperative vehicle routing through a bidding process.
AI Model Releases

NVIDIA has released Nemotron 3 Ultra, a 550B-parameter Mixture-of-Experts model with 55B active parameters, optimized for long-running agent workflows. The model features hybrid Mamba-Transformer layers for efficient long-context handling, NVFP4 quantization for cross-architecture GPU deployment, LatentMoE for expert routing, and multi-token prediction for improved generative speed. Benchmarks show it achieves 5x higher throughput compared to other open models in its class while delivering frontier accuracy on tasks like coding, instruction following, and long-horizon planning. It also reduces task completion costs by up to 30%.
Why it matters: This represents a significant advancement in agent orchestration capabilities, enabling more efficient and cost-effective execution of complex multi-turn workflows that are essential for real-world AI applications. The model's architectural innovations address key bottlenecks in long-running agent systems, potentially setting new standards for performance and efficiency.
Agent Frameworks & SDKs

A community-built job search assistant called 'Job Searcher' has been developed using Hugging Face's ecosystem. The system uses a two-stage approach with DeepSeek V4 Pro as the teacher model for generating structured labels and Qwen3-8B as the student model for fine-tuning. It processes resumes through LinkedIn-shaped search queries, scrapes job postings via JobSpy, and scores matches across five dimensions including skills match, experience relevance, and seniority alignment. The assistant runs on Hugging Face Spaces with llama.cpp inference and provides streaming reasoning outputs to users.
Why it matters: This demonstrates how lightweight, efficient AI agents can be built using existing open-source tools and frameworks, making sophisticated job search capabilities accessible to developers without requiring large-scale infrastructure. It showcases practical applications of distillation techniques and multi-stage prompting for real-world problem solving.