Google introduces the Gemini Enterprise Agent Platform with Agentic RAG capabilities for more dependable enterprise AI responses. ServiceNow AI releases EVA-Bench Data 2.0, expanding evaluation scenarios across three enterprise domains. A collection of papers advances agent skill evolution, continual learning, and formal theorem proving.
Google has launched the Gemini Enterprise Agent Platform, integrating Agentic RAG to deliver more reliable responses by enabling agents to perform complex reasoning and task execution across enterprise systems. This platform addresses key enterprise concerns around reliability and task execution that have limited broader adoption of AI agents in business settings. Concurrently, ServiceNow AI has released EVA-Bench Data 2.0, expanding from one to three enterprise domains including Airline Customer Service Management, Enterprise IT Service Management, and Healthcare HR Service Delivery, with 213 evaluation scenarios across 121 tools. In parallel, a series of papers advance the field of AI agents, including Tangram for efficient multi-turn LLM serving, SkillComposer for evolving agent skills, and Goedel-Architect for formal theorem proving. These developments collectively represent significant progress in making AI agents more capable, reliable, and adaptable across diverse enterprise and research applications.
Research Papers
Tangram: Unlocking Non-Uniform KV Cache for Efficient Multi-turn LLM Serving
Choi, Jungwook arXiv: 2606.06302
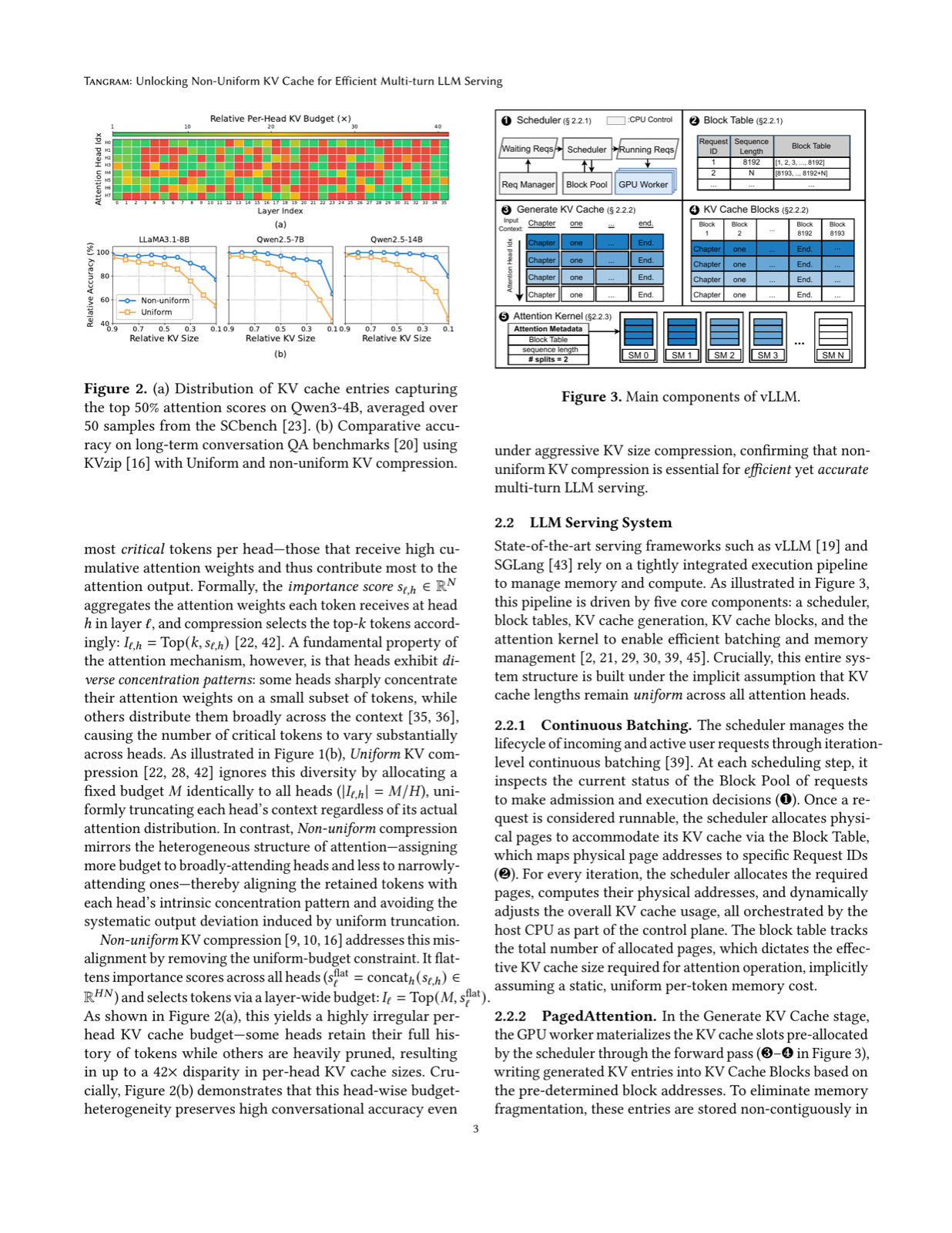
Tangram addresses a critical bottleneck in multi-turn LLM serving: the linear growth of Key-Value (KV) cache that strains GPU memory and bandwidth. The paper identifies that while non-uniform KV compression can preserve more information by considering individual importance, it introduces systemic inefficiencies such as memory fragmentation and scheduling complexities. These challenges have hindered practical adoption of more sophisticated KV cache strategies.
The core innovation of Tangram lies in three techniques: deterministic budget allocation that assigns static memory footprints to each attention head, head group page clustering that manages similar retention demands with independent vectorized page tables, and ahead-of-time load balancing that ensures uniform GPU utilization. These methods work synergistically to eliminate dynamic scheduling overhead and prefill stalls, while maximizing memory reclamation and kernel utilization.
Experimental validation shows that Tangram achieves up to 2.6x throughput improvement over existing baselines, demonstrating the practical viability of non-uniform KV cache strategies. The system's ability to fully preserve model accuracy while significantly improving efficiency makes it a compelling solution for real-world LLM serving applications, particularly in scenarios requiring sustained multi-turn conversations.
Key insight: Tangram introduces a novel approach to KV cache management in multi-turn LLM serving by implementing deterministic budget allocation, head group page clustering, and ahead-of-time load balancing to achieve up to 2.6x throughput improvement without sacrificing model accuracy.
SkillComposer: Learning to Evolve Agent Skills for Specification and Generalization
Zhao, Junbo arXiv: 2606.06079

SkillComposer tackles a fundamental challenge in agent skill construction: the trade-off between specificity and generalization. Current methods treat skill construction as one-shot extraction, leading to either overly task-specific skills that fail to transfer or abstract skills that provide insufficient guidance. The paper proposes a framework that decomposes skill construction into three learnable operations, enabling language models to evolve skills at inference time.
The framework supports three deployment modes: offline for building generalized libraries, online for task-specific refinement, and hybrid for combining both approaches. Comprehensive experiments across multiple benchmarks demonstrate that SkillComposer consistently outperforms baselines, with SkillComposer-4B improving a 27B executor by up to +4.5 on agent tasks and +3.4 on code tasks. This performance gain is particularly notable given the framework's ability to generalize across domains and task types unseen during training.
Analysis reveals that the merge and improve operations address orthogonal quality dimensions, suggesting that skill composition is a transferable meta-ability. This finding provides a practical recipe for skill-augmented inference and opens new avenues for developing more adaptable and capable AI agents that can evolve their capabilities in response to changing requirements.
Key insight: SkillComposer enables language models to self-evolve agent skills through three learnable operations (create, improve, merge) that address the fundamental tension between task-specific guidance and generalization, achieving significant performance gains across diverse domains.
Code2LoRA: Hypernetwork-Generated Adapters for Code Language Models under Software Evolution
Nie, Pengyu arXiv: 2606.06492
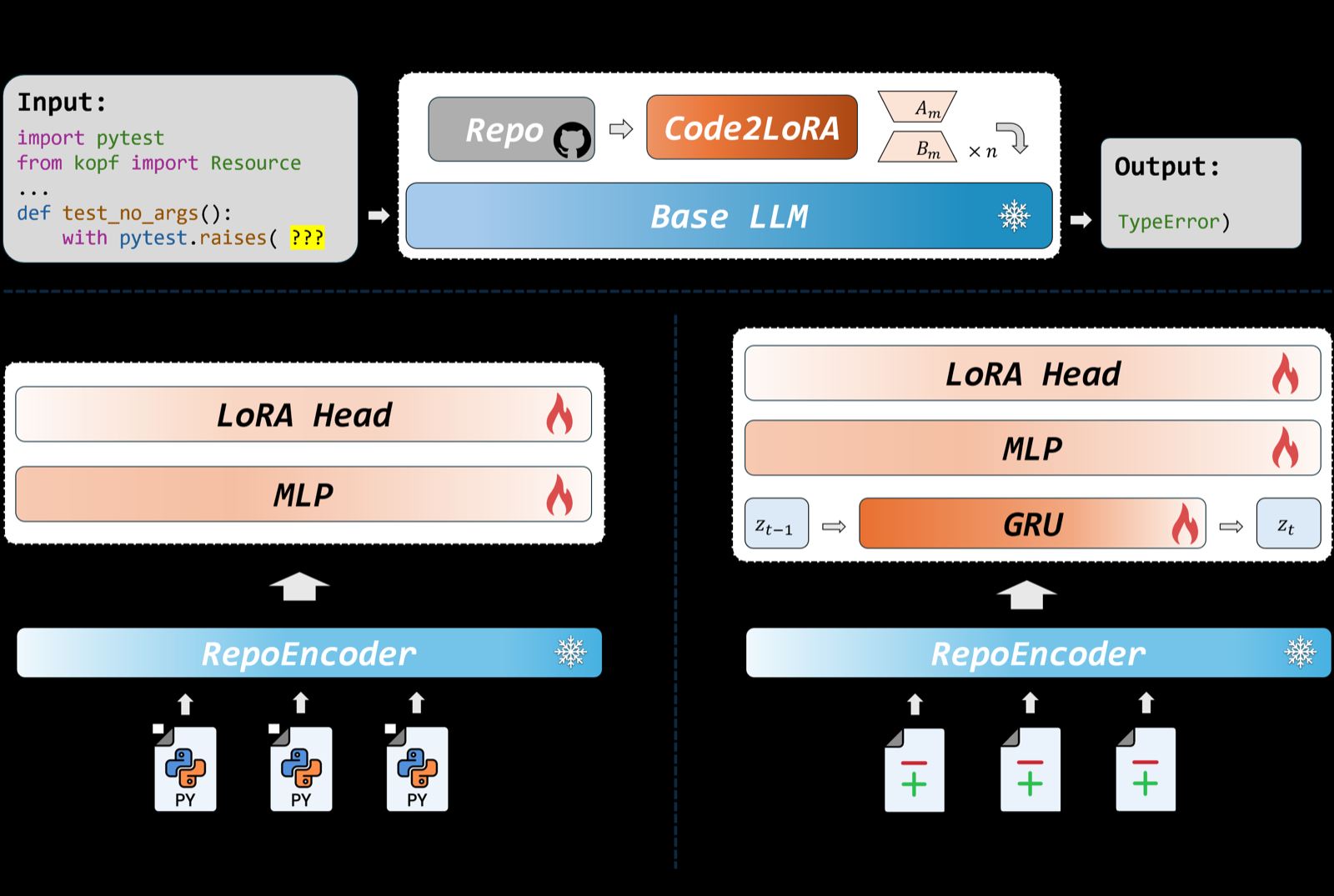
Code2LoRA addresses a significant challenge in code language models: the need for repository-level context to resolve imports, APIs, and project conventions. Traditional approaches either inject knowledge through long inputs or per-repository fine-tuning, which are costly and brittle to evolving codebases. The paper introduces a hypernetwork framework that generates repository-specific LoRA adapters, effectively injecting repository knowledge with zero inference-time token overhead.
The framework supports two usage scenarios: Code2LoRA-Static for stable codebases and Code2LoRA-Evo for active development of evolving codebases. The evolution track uses a GRU hidden state updated per code diff, making it suitable for dynamic environments. Evaluation on RepoPeftBench shows that Code2LoRA-Static achieves 63.8% cross-repo and 66.2% in-repo exact match, matching the per-repository LoRA upper bound, while Code2LoRA-Evo achieves 60.3% cross-repo exact match, outperforming a single shared LoRA by 5.2 percentage points.
This approach represents a significant advancement in parameter-efficient fine-tuning for code language models, particularly in software development environments where codebases are constantly evolving. The ability to maintain performance while reducing computational overhead makes Code2LoRA a promising solution for scalable code understanding and generation in real-world development scenarios.
Key insight: Code2LoRA introduces a hypernetwork framework that generates repository-specific LoRA adapters, enabling efficient code language model adaptation to evolving codebases with zero inference-time token overhead.
Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Arora, Sanjeev arXiv: 2606.06468
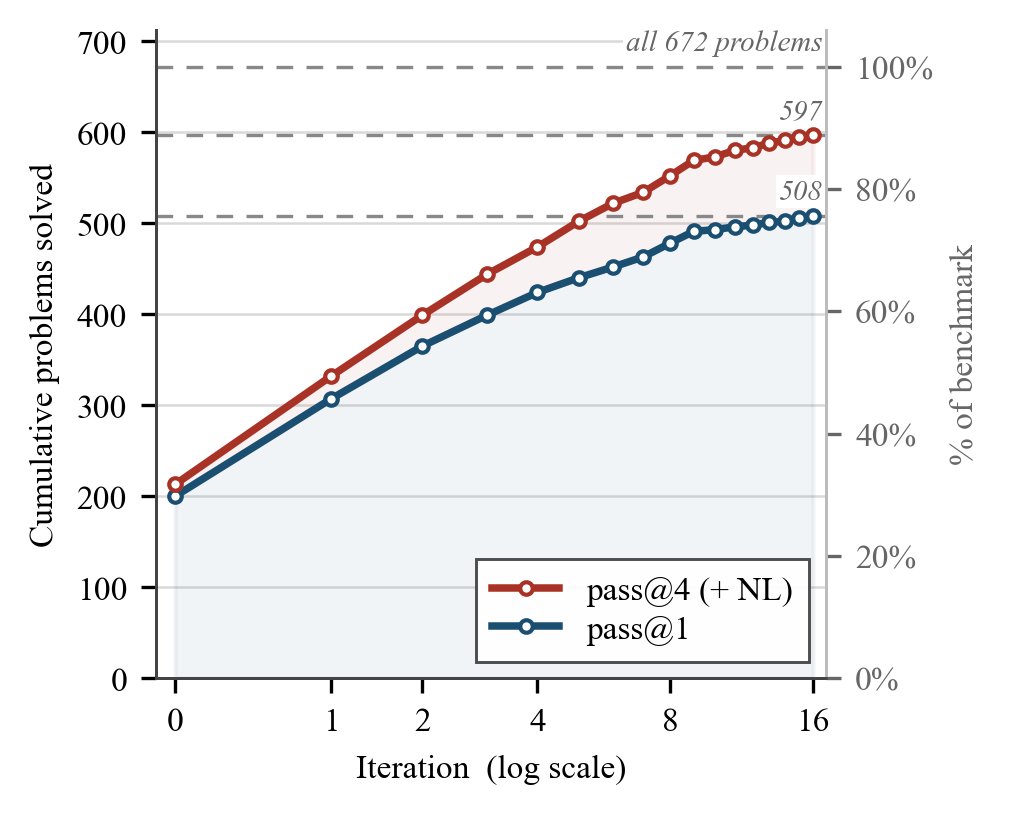
Goedel-Architect presents a novel agentic framework for formal theorem proving in Lean 4 that centers on blueprint generation and refinement. Unlike traditional approaches that use recursive lemma decomposition, this framework generates a dependency graph of definitions and lemmas that builds up to the main theorem, then closes each open lemma node in parallel using relevant dependencies.
The approach's key innovation lies in its blueprint refinement strategy, where failed lemmas drive refinement of the global blueprint, avoiding inefficient loops on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect achieves remarkable results: 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With natural-language proof seeding, it further improves to 100% on MiniF2F-test, 88.8% on PutnamBench, and solves significant portions of IMO 2025, Putnam 2025, and USAMO 2026.
The framework's performance represents a significant leap forward for open-source theorem proving pipelines, achieving state-of-the-art results at a price point up to 500x less than comparable approaches. This makes advanced formal theorem proving accessible to a broader research community and demonstrates the potential of agentic frameworks in solving complex mathematical reasoning tasks.
Key insight: Goedel-Architect revolutionizes formal theorem proving by introducing blueprint generation and refinement, achieving state-of-the-art performance on challenging benchmarks with significantly reduced computational requirements compared to previous approaches.
Benchmark Everything Everywhere All at Once
Yue, Xiangyu arXiv: 2606.06462

Benchmark Agent tackles fundamental challenges in benchmark construction: labor-intensive creation, difficulty in reuse, and performance saturation. The paper introduces a fully autonomous agentic system that orchestrates the complete benchmark construction pipeline, from user query analysis to data annotation and quality control. This approach addresses the sustainability and scalability concerns that have plagued existing benchmark development efforts.
The framework was implemented to produce 15 representative benchmarks spanning diverse evaluation scenarios including text understanding, multimodal understanding, and domain-specific reasoning. Extensive experiments with human evaluation, LLM-as-a-judge assessment, and consistency checks demonstrate that Benchmark Agent can generate high-quality benchmark samples with minimal human involvement. The system's ability to rapidly evolve benchmarks provides valuable insights into current model capabilities and limitations.
The paper's contribution extends beyond technical innovation to include a demonstration of how autonomous systems can contribute significantly to the research community by rapidly generating evolving benchmarks. This approach addresses the critical need for continuously updated evaluation metrics that can effectively discriminate among state-of-the-art models, ensuring that benchmarking remains a driving force for continued advancement in AI research.
Key insight: Benchmark Agent introduces a fully autonomous agentic system for benchmark construction that can generate high-quality benchmarks with minimal human involvement, addressing sustainability and scalability challenges in benchmark development.
A Komi-Yazva--Russian Parallel Corpus and Evaluation Protocol for Zero- and Few-Shot LLM Translation
Parshakov, Petr arXiv: 2606.06420
This paper introduces a novel Komi-Yazva--Russian parallel corpus designed for evaluating LLM translation in endangered language settings, where data scarcity is a major challenge. The authors emphasize the importance of rigorous evaluation protocols that account for leakage, deterministic retrieval, and story-level uncertainty estimates. Their findings reveal that while LLMs can produce non-trivial translations in zero-shot settings, performance is highly dependent on both the model architecture and the prompting strategy used.
The study demonstrates that retrieval-based few-shot prompting consistently improves over zero-shot prompting, but gains beyond a small retrieved context remain limited. This suggests that in low-resource scenarios, the effectiveness of LLMs is constrained not just by model capacity, but also by the availability and quality of supporting data. The paper's emphasis on evaluation methodology is particularly valuable for researchers working on under-resourced languages, as it highlights how metric choice and failure handling can significantly influence conclusions.
By framing their corpus as both a dataset contribution and a reproducible evaluation testbed, the authors provide a framework that can be extended to other endangered languages. This approach is crucial for advancing machine translation in low-resource settings, where traditional benchmarking methods often fail due to the lack of sufficient parallel data. The work underscores the need for more nuanced evaluation practices that account for the inherent variability in such domains.
Key insight: Zero-shot and few-shot LLM translation performance varies significantly by model family and prompting regime, with retrieval-based few-shot prompting offering consistent but limited gains over zero-shot approaches in extremely low-resource settings.
Emergent Language as an Approach to Conscious AI
Xiao, Chuan arXiv: 2606.06380

This paper proposes a novel approach to studying artificial consciousness through emergent language in multi-agent reinforcement learning. By starting agents with minimal language capabilities and allowing them to develop communication under task pressure alone, the authors aim to isolate causal attributability to task demands rather than inherited human priors. This methodology is particularly relevant for AI agent development, as it offers a way to investigate the emergence of complex cognitive structures without relying on pre-defined architectures or linguistic assumptions.
The proof-of-concept experiment demonstrates that agents can develop self-referential communication, including an echo-mismatch detection circuit that emerges from specific environmental affordances. This finding suggests that consciousness-like phenomena may arise from task-driven interaction rather than explicit design, opening new avenues for understanding how artificial systems might develop self-awareness or reflective capabilities.
The paper positions emergent language as a generative tool for studying consciousness-relevant structures, including the role of environment complexity and the interpretation of emergent communication. This approach could be instrumental in designing AI systems that exhibit more sophisticated forms of reasoning and self-modeling, potentially leading to more robust and adaptive agents in complex environments.
Key insight: Emergent language in multi-agent reinforcement learning provides a generative methodology for studying consciousness-relevant structures, enabling agents to develop self-referential communication without human language priors.
TailLoR: Protecting Principal Components in Parameter-Efficient Continual Learning
Brad, Florin arXiv: 2606.06494
TailLoR addresses a critical challenge in continual learning: how to preserve important information from previous tasks while adapting to new ones. By utilizing the singular bases U and V of pre-trained weights as a fixed reference frame, the method learns a low-rank update applied to the singular value matrix. This approach ensures that dominant singular directions are protected from updates, reducing interference while allowing fine-grained adaptation in long-tail spectral coordinates.
The soft spectral penalty discourages updates aligned with dominant singular directions, which is crucial for maintaining performance on previously learned tasks. This mechanism is particularly valuable in parameter-efficient fine-tuning methods, where the goal is to minimize memory and computational overhead while preserving model capabilities. The method's ability to route adaptation into flexible, long-tail coordinates suggests a promising direction for scalable continual learning.
The paper's contribution lies in its novel approach to balancing stability and plasticity in continual learning. By decoupling the representation from the update mechanism, TailLoR offers a principled way to manage catastrophic forgetting while maintaining the flexibility needed for new learning. This is especially relevant for AI agents that must continuously adapt to changing environments without losing previously acquired knowledge.
Key insight: TailLoR uses singular bases as a fixed reference frame to learn low-rank updates, protecting principal components while enabling flexible adaptation in continual learning scenarios.
Regret Minimization with Adaptive Opponents in Repeated Games
Zhang, Kaiqing arXiv: 2606.06486

This paper introduces Repeated Policy Regret (RP-Regret) as a novel metric for regret minimization in repeated games with adaptive opponents. Unlike standard external regret, RP-Regret accounts for players' counterfactual reasoning by measuring the difference between realized and best-in-hindsight accumulated utility when all players can respond to the history of play. This approach is particularly relevant for AI agent development, where agents must learn to adapt to dynamic, strategic opponents.
The authors identify necessary conditions for achieving sublinear RP-Regret, including variations in comparator strategies and opponent memories. They propose three algorithms to minimize RP-Regret, including one based on optimization oracles, another using convex surrogates, and a third that directly minimizes RP-Regret when opponents change slowly. These methods offer practical solutions for implementing robust learning in adversarial environments, which is essential for multi-agent systems.
Experimental results show that minimizing RP-Regret leads to more cooperative solutions with higher utility in games like Stag-Hunt. This suggests that RP-Regret can be a powerful tool for designing AI agents that not only optimize their own performance but also consider the strategic behavior of others. The framework's ability to learn subgame perfect equilibria when all players minimize RP-Regret makes it a promising approach for developing more sophisticated and adaptive multi-agent systems.
Key insight: Repeated Policy Regret (RP-Regret) provides a game-theoretic framework for regret minimization in repeated games with adaptive opponents, enabling stronger comparators and equilibria learning.
Pretraining Recurrent Networks without Recurrence
Isola, Phillip arXiv: 2606.06479

Supervised Memory Training (SMT) presents a novel approach to training recurrent neural networks (RNNs) that sidesteps the challenges of sequential backpropagation through time (BPTT). By reducing RNN training to supervised learning on one-step memory transition labels, SMT decouples what to remember from how to update memory. This approach enables time-parallel training with a stable O(1) length gradient path between any two tokens, overcoming the vanishing or exploding gradient problems that plague traditional RNN training.
The method leverages a Transformer-based encoder trained on a predictive state objective to acquire memory labels, retaining only information necessary to predict the future. This allows nonlinear RNNs to better capture long-range dependencies while training in parallel, potentially unlocking the scaling of models that build temporal abstractions of past experience. The experimental results show that SMT outperforms BPTT on language modeling and pixel sequence modeling tasks, demonstrating its effectiveness in handling long-range dependencies.
SMT's ability to train RNNs in parallel while maintaining stable gradients is particularly valuable for AI agent development, where efficient and scalable training is crucial. The approach opens new possibilities for training complex temporal models that can learn from extended sequences without the computational bottlenecks associated with traditional RNN training methods. This advancement could significantly impact how agents process and learn from sequential data in real-world applications.
Key insight: Supervised Memory Training (SMT) enables time-parallel RNN training by decoupling memory updates from what to remember, achieving stable gradient paths without sequential backpropagation.
The Post-GCN Decade Revisited: Curvature-Stratified Evaluation of Relational Learning
Kang, Zhao arXiv: 2606.06397
This paper challenges the conventional approach to evaluating relational learning models by introducing a curvature-stratified evaluation framework that partitions datasets into positive, negative, and near-zero curvature regimes. The authors demonstrate that model rankings are highly stable within each curvature regime but shift significantly across regimes, indicating that performance is fundamentally geometry-dependent rather than universally transferable. This finding has profound implications for AI agent development, particularly in domains where relational structures vary significantly.
The benchmark evaluates 18 representative models including Graph Convolutional Networks (GCNs), Graph Foundation Models (GFMs), and tabular learning methods across 14 datasets, revealing that GFMs offer diminishing returns compared to geometry-aligned GNNs in certain regimes. This insight suggests that model selection should be informed by the geometric properties of the data rather than relying on aggregated metrics that obscure critical performance trade-offs.
The proposed geometry-aware evaluation protocol offers a more reliable and interpretable comparison of relational learning methods, providing a foundation for more robust and principled model selection. For AI agents operating in complex, relational environments, understanding how model performance varies with data geometry is crucial for designing systems that can adapt effectively to diverse structural challenges.
Key insight: Curvature-stratified evaluation reveals that model performance in relational learning is fundamentally geometry-dependent, challenging the assumption of universal transferability across datasets.
Learning to Contest: Decentralized Robust Fairness in Cooperative MARL via Cross-Attention
Savcı, Can arXiv: 2606.06162
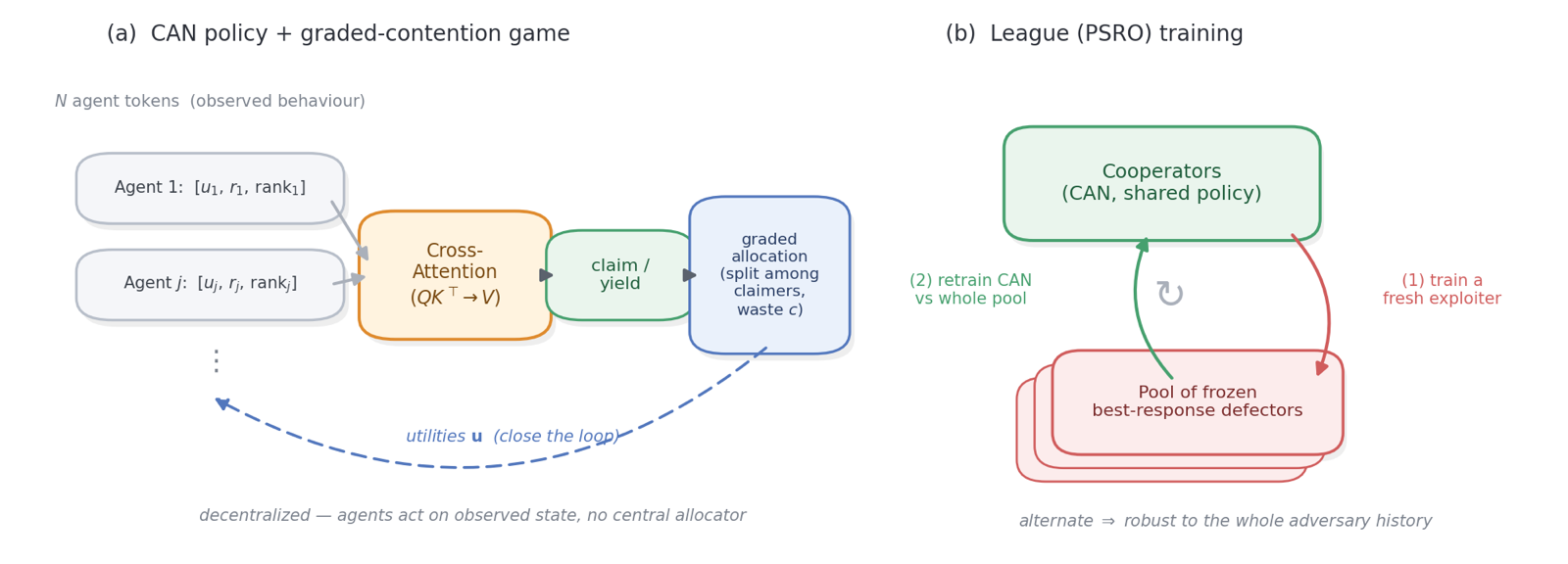
CAN addresses a fundamental challenge in cooperative multi-agent reinforcement learning (MARL): how to maintain fairness in the presence of selfish agents without centralized control. The policy uses permutation-equivariant cross-attention to infer the number of free-riders and respond proportionally, implementing turn-taking when none and contesting just enough when some. This approach enables decentralized leverage for fairness, which was previously thought to be impossible without central allocation.
The method's performance is evaluated against an adversarial league (PSRO), showing that CAN maintains low exploitability (ρ≈1.2-1.5) across the contention range, wasting almost nothing at D=0 and retaining most efficiency at D≥1. This demonstrates that CAN can approach centralized oracle performance on both efficiency and fairness axes, making it a powerful tool for designing robust multi-agent systems that can operate effectively in adversarial environments.
CAN's ability to balance efficiency and fairness in cooperative MARL settings is particularly relevant for AI agents that must coordinate in complex, dynamic environments. The framework's success in multiple games shows its potential for broader applications, though the paper notes that its robustness depends on the contest leverage available. This suggests that CAN is most effective when there is sufficient strategic room for agents to contest resources, which is a key consideration for practical deployment.
Key insight: CAN, a cross-attention policy for cooperative MARL, enables robust fairness by inferring free-rider numbers and responding proportionally, achieving efficiency comparable to centralized oracles without central allocation.
AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
Ji, Heng arXiv: 2606.05622

The emergence of AdaPlanBench marks a significant step forward in evaluating the robustness of LLM agents in real-world planning scenarios. Unlike traditional benchmarks that assume static constraints, this work introduces a dynamic environment where both world and user constraints are progressively revealed during interaction. This setup more accurately reflects real-world complexity, where agents must continuously adapt their plans as new information becomes available.
Experiments with ten leading LLMs reveal that even state-of-the-art models face substantial challenges in maintaining accurate planning under dual constraints. The 67.75% accuracy achieved by the best model underscores a critical gap in current agent architectures—particularly in their ability to infer hidden constraints from feedback and revise plans effectively. This limitation is exacerbated by the accumulation of constraints, with user constraints proving especially difficult to handle.
The findings suggest that while LLMs excel in many reasoning tasks, they still lack the physical grounding and contextual adaptability required for reliable dual-constrained planning. This work not only establishes a new benchmark but also highlights the urgent need for agent designs that can better integrate feedback loops, improve constraint tracking, and enhance plan robustness in dynamic environments.
Key insight: LLM agents struggle with adaptive planning under dynamically revealed world and user constraints, highlighting the need for better constraint inference and plan revision mechanisms.
AI Model Releases
Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG
Google has announced the release of the Gemini Enterprise Agent Platform, which introduces Agentic RAG (Retrieval-Augmented Generation) capabilities. This platform is designed to provide more dependable responses by enabling agents to perform complex reasoning and task execution. The system integrates with existing enterprise tools and workflows, allowing for more sophisticated agent behavior. It's built to handle multi-step tasks and complex queries that require accessing external data sources and performing actions across different systems. The platform is positioned as a solution for enterprises seeking to deploy AI agents that can reliably interact with business-critical applications.
Why it matters: This represents a significant step forward in enterprise AI deployment, moving beyond simple chatbots to sophisticated agents capable of complex workflows. The integration of Agentic RAG suggests Google is addressing key enterprise concerns around reliability and task execution that have limited broader adoption of AI agents in business settings.

Startup Battlefield 200 applications officially close in 3 days
Source: TechCrunch.
Agent Frameworks & SDKs
EVA-Bench Data 2.0: 3 Domains, 121 Tools, 213 Scenarios
ServiceNow AI has released EVA-Bench Data 2.0, expanding from one to three enterprise domains: Airline Customer Service Management (CSM), Enterprise IT Service Management (ITSM), and Healthcare HR Service Delivery (HRSD). The dataset now includes 213 evaluation scenarios across 121 tools, representing a roughly 4x increase in scenario coverage from the original release. Each scenario was validated for solvability against three frontier models (OpenAI GPT-5.4, Google Gemini 3.1 Pro, and Anthropic Claude Opus 4.6) ensuring the benchmark is both challenging and fair. All three datasets are open-source and available for download through the Hugging Face platform, with code examples provided for loading the datasets.
Why it matters: This benchmark expansion provides the AI community with a more comprehensive and realistic evaluation framework for voice agents across multiple enterprise domains. The open-source nature and validation against leading models make it a valuable resource for both researchers and practitioners working on enterprise AI agent development.