Anthropic has released an updated Responsible Scaling Policy to address potential catastrophic risks from frontier AI systems. Simultaneously, new research papers advance the state-of-the-art in parallel reasoning, agent workflows, and adaptive inference-time scaling.
Anthropic's updated Responsible Scaling Policy establishes new governance frameworks for managing risks associated with increasingly powerful AI systems, emphasizing safety protocols and risk assessment procedures. In parallel, several key research papers present innovative approaches to improving AI reasoning capabilities. OpenDeepThink introduces a Bradley-Terry aggregation method for parallel reasoning that significantly boosts LLM performance without ground-truth verifiers. APWA presents a distributed architecture for efficient parallel execution of agentic workflows, overcoming coordination bottlenecks. Additional papers tackle traversal context in GraphRAG systems, dual-dimensional consistency for adaptive inference scaling, and case-based calibration for tool use in LLMs.
AI Model Releases

Announcing our updated Responsible Scaling Policy
Anthropic has published an updated Responsible Scaling Policy (RSP) to govern potential catastrophic risks from frontier AI systems. The policy outlines new governance frameworks for scaling AI capabilities while mitigating risks. It includes enhanced safety protocols and risk assessment procedures for AI development. The update comes as AI systems become increasingly powerful and potentially dangerous. Anthropic emphasizes the importance of responsible development practices in the face of advancing AI capabilities.
Why it matters: This policy update reflects growing industry consensus on the need for responsible AI development as systems approach more dangerous levels of capability. It sets a precedent for how major AI labs might manage the risks associated with increasingly powerful models.
Research Papers
OpenDeepThink: Parallel Reasoning via Bradley--Terry Aggregation
arXiv: 2605.15177

OpenDeepThink addresses a critical bottleneck in LLM reasoning: the selection of high-quality candidates from parallel reasoning traces. By employing a Bradley-Terry aggregation framework, it enables effective candidate selection without relying on noisy pointwise LLM judging. This method aggregates pairwise comparisons into a global ranking, preserving top candidates and mutating the best three quarters while discarding the bottom quarter. The approach is particularly effective in domains like Codeforces, where it boosts Gemini 3.1 Pro's effective Elo by 405 points over eight rounds of LLM calls.
The framework's strength lies in its ability to scale reasoning breadth without sacrificing quality, a common challenge in test-time compute scaling. It dynamically adapts to different models and domains, showing consistent gains in verifiable domains and diminishing returns in subjective ones. This suggests that the Bradley-Terry method is especially suited for tasks where objective correctness can be evaluated, making it a promising direction for improving reasoning in high-stakes applications.
The release of CF-73, a curated dataset of expert-rated Codeforces problems, further enhances the practical impact of OpenDeepThink. This dataset provides a standardized benchmark for evaluating reasoning systems, enabling more reliable comparisons and driving further research in parallel reasoning and candidate selection.
Key insight: OpenDeepThink introduces a Bradley-Terry aggregation method for selecting the best reasoning candidates in parallel, significantly improving LLM reasoning performance without requiring ground-truth verifiers.
APWA: A Distributed Architecture for Parallelizable Agentic Workflows
arXiv: 2605.15132

APWA tackles a major challenge in autonomous multi-agent systems: the inability to scale efficiently with increasing task complexity and parallelization needs. By decomposing workflows into independent subproblems, APWA allows for parallel execution without cross-communication, significantly improving throughput. This architecture supports heterogeneous data and processing patterns, making it adaptable to a wide range of domains.
The framework's ability to dynamically decompose complex queries into parallelizable workflows is a key innovation. It not only improves scalability but also ensures that systems can handle larger tasks without failing, which is a common limitation in prior multi-agent systems. This makes APWA particularly valuable for real-world applications where tasks are often complex and resource-intensive.
APWA's design emphasizes distributed execution and resource efficiency, which are crucial for deploying large-scale agentic systems. By enabling independent processing of subproblems, it reduces coordination overhead and allows for better resource utilization, paving the way for more robust and scalable multi-agent architectures.
Key insight: APWA presents a distributed architecture that enables efficient parallel execution of agentic workflows by decomposing tasks into non-interfering subproblems, overcoming coordination and scaling bottlenecks in multi-agent systems.
Why Neighborhoods Matter: Traversal Context and Provenance in Agentic GraphRAG
arXiv: 2605.15109

The paper introduces a nuanced view of citation faithfulness in Agentic GraphRAG, arguing that faithful answers depend not only on cited evidence but also on the traversal context and surrounding graph structure. This challenges the traditional approach of evaluating citations in isolation and highlights the importance of provenance in retrieval trajectories.
Through controlled ablation experiments, the authors demonstrate that removing cited evidence significantly impacts answers and accuracy, but that uncited traversal context also plays a crucial role. This finding suggests that future evaluation metrics for GraphRAG systems must consider the broader retrieval process, not just the final cited sources.
The implications of this work extend beyond GraphRAG to any system that relies on graph-based retrieval and reasoning. It calls for a shift in how we think about citation and evidence in agentic systems, emphasizing the need for more comprehensive evaluation frameworks that account for the full context of the retrieval process.
Key insight: Agentic GraphRAG systems require a broader notion of citation faithfulness that accounts for traversal context and graph structure, not just cited evidence, to ensure accurate and faithful answers.
Dual-Dimensional Consistency: Balancing Budget and Quality in Adaptive Inference-Time Scaling
arXiv: 2605.15100

DDC addresses a fundamental trade-off in LLM reasoning: maximizing quality while minimizing computational cost. By coupling Confidence-Weighted Bayesian protocols with Trend-Aware Stratified Pruning, DDC ensures that computational resources are allocated to high-quality reasoning paths, filtering out hallucinations and accelerating consensus. This approach is particularly effective in reducing token consumption while maintaining or improving accuracy.
The framework's ability to adaptively terminate reasoning chains based on quality signals is a significant advancement. Unlike traditional methods that treat width and depth as orthogonal, DDC integrates both dimensions, leading to more efficient and effective reasoning. This is especially valuable in resource-constrained environments where inference-time scaling must be carefully managed.
Evaluations across multiple benchmarks confirm DDC's effectiveness, showing consistent improvements in accuracy and efficiency. The method's broad applicability across different LLMs and tasks underscores its potential as a general-purpose solution for adaptive inference-time scaling, making it a valuable tool for optimizing LLM reasoning in practical applications.
Key insight: Dual-Dimensional Consistency (DDC) unifies path quality and adaptive termination to balance computational budget and reasoning quality, achieving up to 10x token reduction without sacrificing accuracy.
Case-Based Calibration of Adaptive Reasoning and Execution for LLM Tool Use
arXiv: 2605.15041
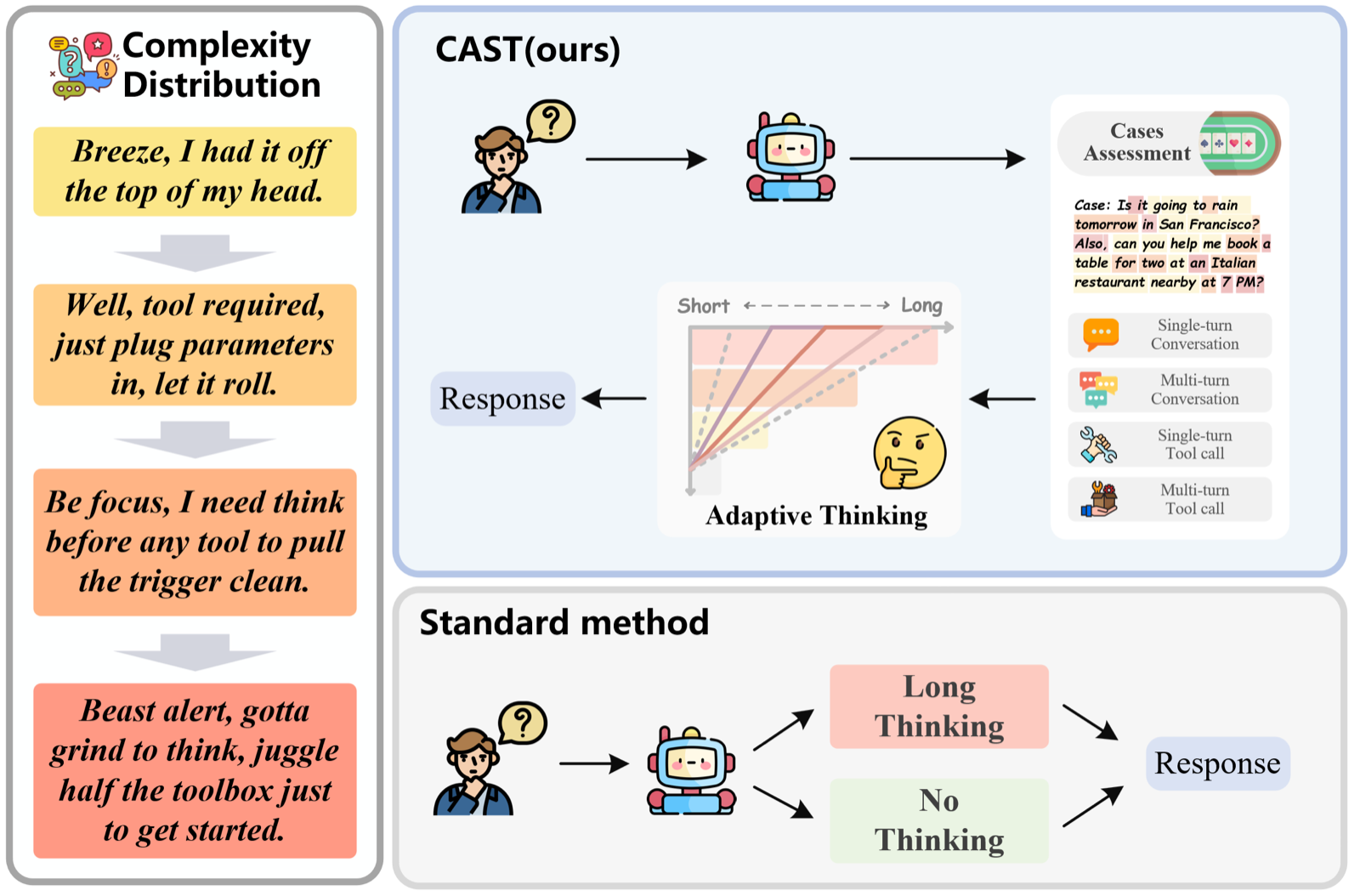
CAST introduces a case-based approach to tool use in LLMs, treating historical execution trajectories as structured cases to guide future reasoning and execution. Rather than reusing raw outputs, CAST extracts signals to estimate optimal reasoning strategies and identify potential structural breakdowns. This enables more informed and adaptive tool use, reducing both errors and unnecessary deliberation.
The framework's use of case-derived signals for reward design and reasoning adaptation is a key innovation. It allows models to autonomously internalize strategies from past executions, leading to improved performance in both schema-faithful execution and overall task success. This approach is particularly effective in reducing high-impact structural errors, which are common in tool-use scenarios.
Experiments on BFCLv2 and ToolBench demonstrate CAST's effectiveness, achieving significant gains in execution accuracy and reducing average reasoning length. This shows that leveraging historical execution cases can provide reusable adaptation knowledge, making CAST a promising direction for improving the reliability and efficiency of LLM tool use in complex environments.
Key insight: CAST uses historical execution cases to calibrate reasoning and execution in LLM tool use, improving both schema-faithful execution and task-level success while reducing unnecessary deliberation.