Google Cloud and Wiz have partnered to strengthen AI security for enterprises, while Firebase introduces AI Logic to accelerate mobile AI development. Meanwhile, new research reveals critical limitations in how LLMs interpret complex grammatical structures and demonstrates novel approaches to multimodal reasoning and preference modeling.
At Cloud Next 2026, Google Cloud and Wiz announced a strategic partnership to enhance AI security for enterprises, addressing growing concerns about AI security vulnerabilities and data governance in enterprise AI deployments. Firebase also unveiled AI Logic, a new tool that enables developers to integrate Gemini directly into mobile and web applications, reducing complexity and accelerating time-to-market. In parallel, cutting-edge research exposes fundamental limitations in LLMs' ability to interpret context-free grammars under complex structural conditions, while other studies advance hybrid intelligent systems through ontology construction, process-supervised multimodal reasoning, and situated conversational recommendation frameworks. These developments collectively highlight both the rapid evolution of AI infrastructure and the ongoing challenges in building reliable, interpretable AI systems.
AI Model Releases

Next26 Redefining Security For The AI Era With Google Cloud And Wiz
Google Cloud and Wiz announced a strategic partnership to enhance AI security for enterprises at Cloud Next 2026. The collaboration focuses on providing comprehensive security solutions for AI workloads, including threat detection, compliance monitoring, and risk assessment. The integrated platform will offer real-time visibility into AI model usage and data flows, helping organizations maintain security posture as they adopt AI technologies. This partnership addresses growing concerns about AI security vulnerabilities and data governance in enterprise AI deployments.
Why it matters: As AI adoption accelerates, security concerns are becoming paramount. This partnership demonstrates the industry's recognition that AI security must be built into the infrastructure from the ground up, rather than treated as an afterthought.
AI Tooling

Ship production AI features faster with Firebase AI Logic
Firebase announced AI Logic at Cloud Next 2026, a new tool that enables developers to integrate Gemini directly into mobile and web applications. The feature allows developers to access Gemini's capabilities through simple API calls, reducing the complexity of AI integration. Firebase AI Logic supports both text and multimodal inputs, enabling rich AI experiences in applications. It's designed to accelerate time-to-market for AI-powered features while maintaining Firebase's ease-of-use and scalability.
Why it matters: Firebase AI Logic bridges the gap between Firebase's developer-friendly ecosystem and advanced AI capabilities, potentially democratizing AI integration for smaller teams and mobile developers who may not have deep AI expertise.
Research Papers
Diagnosing CFG Interpretation in LLMs
arXiv: 2604.20811
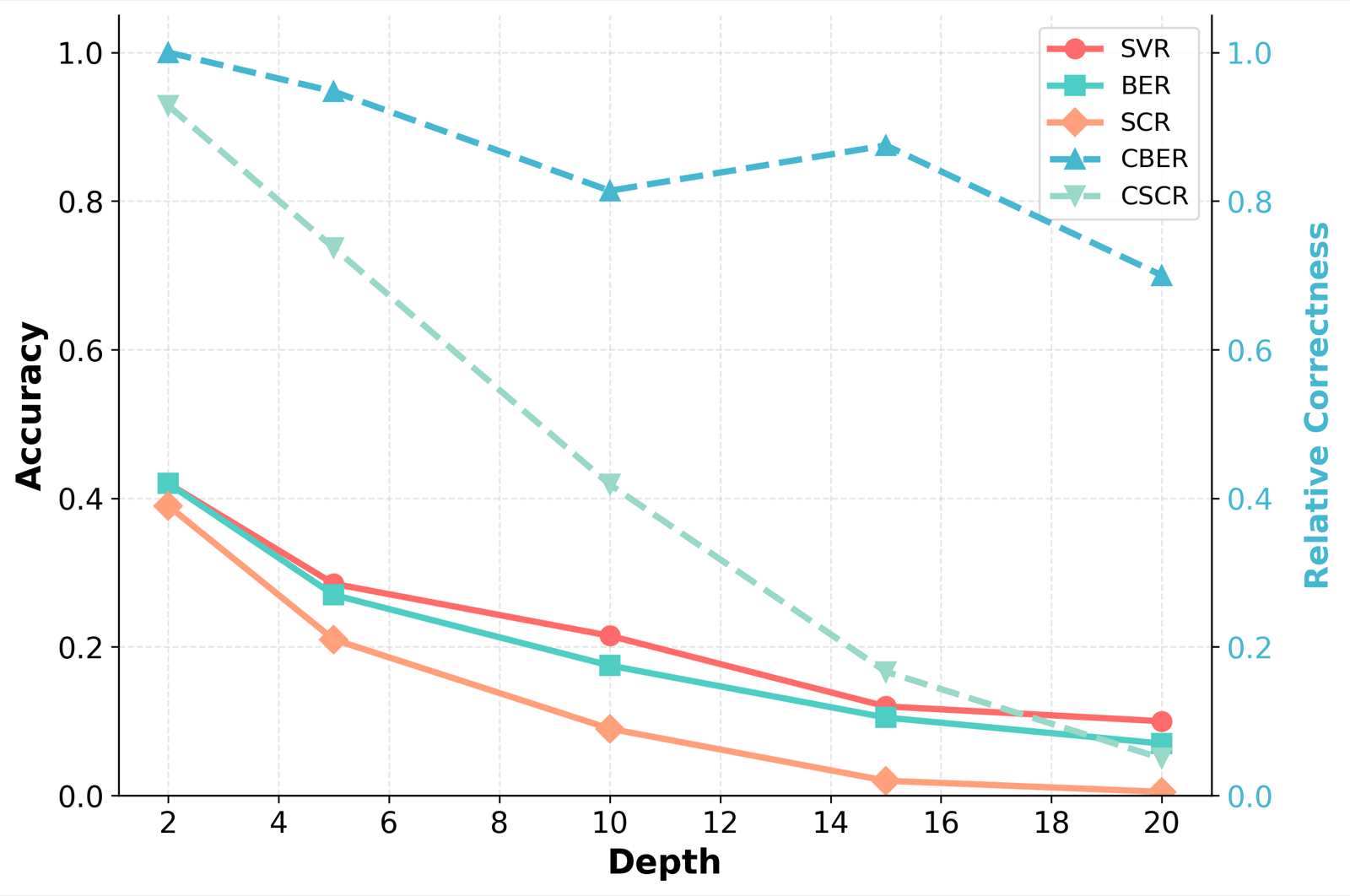
The paper 'Diagnosing CFG Interpretation in LLMs' reveals a critical limitation in how large language models (LLMs) interpret context-free grammars, particularly under complex structural conditions. While LLMs can often reproduce surface syntax, they consistently fail to preserve the deeper semantic structure required for reliable agent behavior. This degradation becomes especially pronounced with deep recursion and high branching, indicating that current models lack the hierarchical state-tracking necessary for robust, grammar-agnostic agent systems.
The authors introduce RoboGrid, a framework that systematically tests LLMs on syntax, behavior, and semantics through controlled stress-tests. Their findings show that even with Chain-of-Thought reasoning, performance collapses under structural density. This suggests that LLMs rely heavily on keyword-based semantic bootstrapping rather than pure symbolic induction, which undermines their ability to function as interpreters in dynamic, machine-interpretable interfaces.
These results have significant implications for agentic systems, where LLMs must reliably interpret and execute dynamically defined interfaces. The inability to maintain structural semantics under complexity points to a fundamental gap in current architectures, necessitating new approaches to hierarchical state management and symbolic reasoning in LLMs.
Key insight: LLMs struggle with deep recursion and high branching in context-free grammar interpretation, failing to maintain structural semantics even with Chain-of-Thought reasoning.
Automatic Ontology Construction Using LLMs as an External Layer of Memory, Verification, and Planning for Hybrid Intelligent Systems
arXiv: 2604.20795
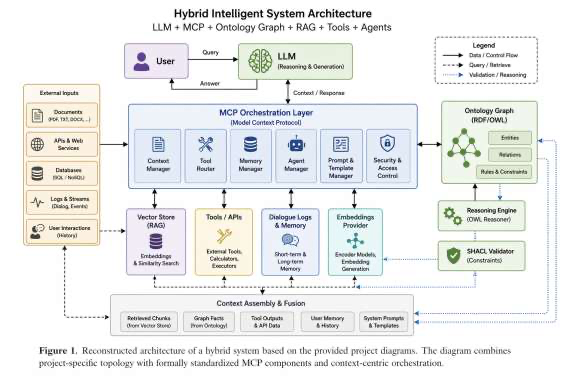
The paper presents a hybrid architecture that extends LLMs with an external ontological memory layer using RDF/OWL representations. This approach addresses key limitations of current LLM-based systems, including lack of long-term memory, weak structural understanding, and limited reasoning capabilities. By constructing and maintaining a structured knowledge graph, the system enables persistent, verifiable, and semantically grounded reasoning.
The core contribution is an automated pipeline for ontology construction from heterogeneous data sources, including documents, APIs, and dialogue logs. This pipeline performs entity recognition, relation extraction, normalization, and triple generation, followed by validation using SHACL and OWL constraints. During inference, LLMs operate over a combined context that integrates vector-based retrieval with graph-based reasoning and external tool interaction.
Experimental results on planning tasks, including the Tower of Hanoi benchmark, show that ontology augmentation improves performance in multi-step reasoning scenarios compared to baseline LLM systems. Additionally, the ontology layer enables formal validation of generated outputs, transforming the system into a generation-verification-correction pipeline. This architecture provides a foundation for building agent-based systems, robotics applications, and enterprise AI solutions that require persistent knowledge, explainability, and reliable decision-making.
Key insight: Integrating LLMs with external ontological memory layers enhances reasoning, planning, and verification capabilities in hybrid intelligent systems.
SWE-chat: Coding Agent Interactions From Real Users in the Wild
arXiv: 2604.20779

'SWE-chat' presents the first large-scale dataset of real coding agent sessions collected from open-source developers, containing 6,000 sessions with over 355,000 agent tool calls. This dataset provides empirical evidence of how people actually use coding agents in practice, revealing significant inefficiencies in current systems. Despite rapidly improving capabilities, coding agents remain inefficient in natural settings, with only 44% of agent-produced code surviving into user commits.
The study identifies two dominant coding patterns: in 41% of sessions, agents author virtually all committed code ('vibe coding'), while in 23%, humans write all code themselves. However, agent-written code introduces more security vulnerabilities than human-authored code, and users push back against agent outputs in 44% of all turns through corrections, failure reports, and interruptions. These findings highlight the gap between curated benchmarks and real-world performance.
By capturing complete interaction traces with human vs. agent code authorship attribution, SWE-chat provides an empirical foundation for moving beyond curated benchmarks towards an evidence-based understanding of AI agent performance in real developer workflows. This dataset is crucial for developing more effective and reliable coding agents that can integrate seamlessly into actual development practices.
Key insight: Real-world coding agent usage reveals significant inefficiencies, with only 44% of agent-produced code surviving into user commits and higher security vulnerabilities than human-authored code.
V-tableR1: Process-Supervised Multimodal Table Reasoning with Critic-Guided Policy Optimization
arXiv: 2604.20755
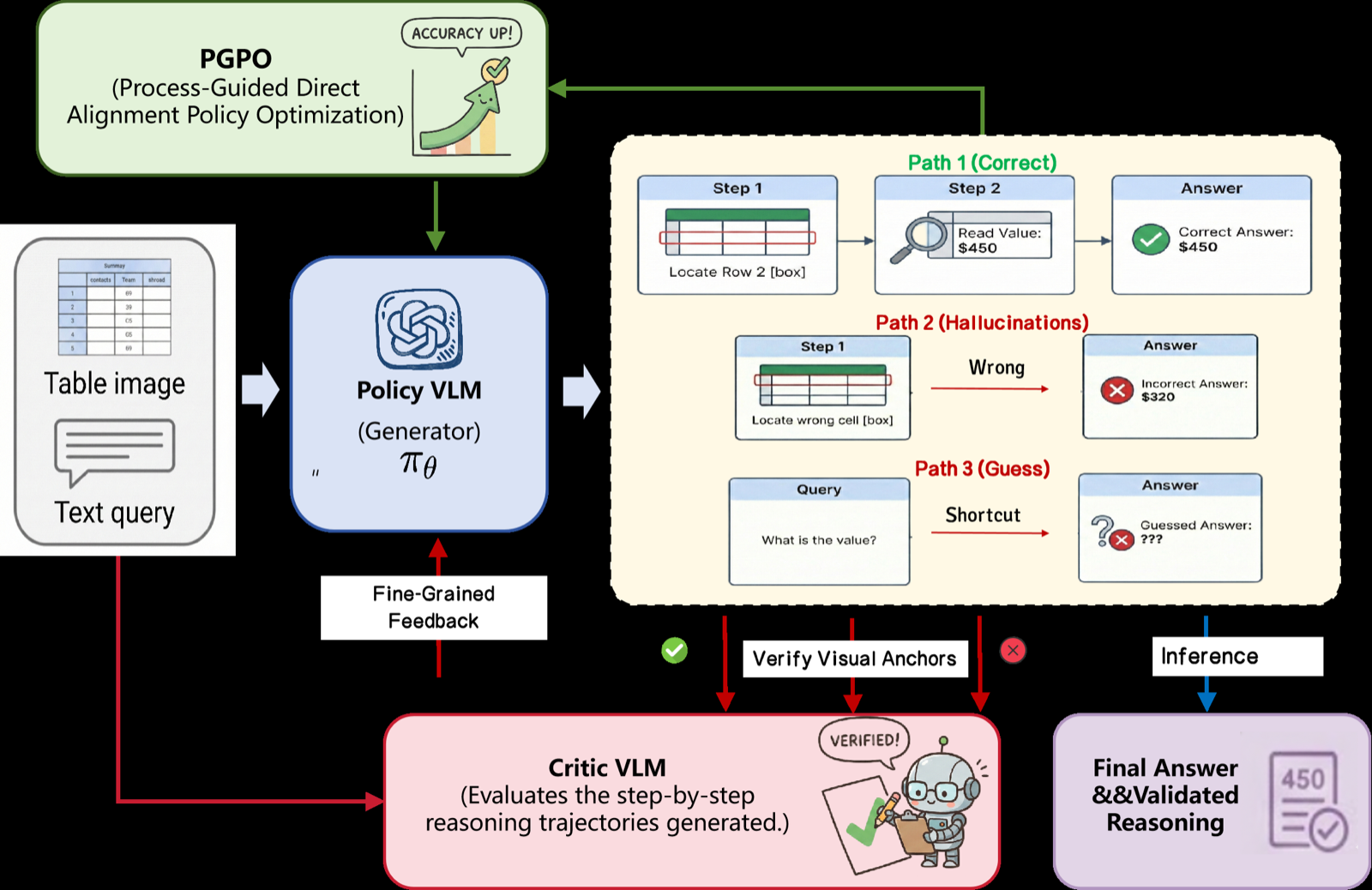
V-tableR1 introduces a process-supervised reinforcement learning framework that elicits rigorous, verifiable reasoning from multimodal large language models (MLLMs). Unlike traditional MLLMs trained solely on final outcomes, which often rely on superficial pattern matching, V-tableR1 enforces transparent reasoning trajectories using a specialized critic VLM to provide dense, step-level feedback on visual chain-of-thought.
The framework employs a novel RL algorithm called Process-Guided Direct Alignment Policy Optimization (PGPO), which integrates process rewards, decoupled policy constraints, and length-aware dynamic sampling. This approach explicitly penalizes visual hallucinations and shortcut guessing, fundamentally shifting multimodal inference from black-box pattern matching to verifiable logical derivation.
Extensive evaluations demonstrate that V-tableR1 establishes state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforming models up to 18x its size and improving over its SFT baseline. This represents a significant advancement in multimodal reasoning, showing that process supervision can dramatically improve the reliability and accuracy of MLLMs in structured reasoning tasks.
Key insight: V-tableR1 uses process-supervised reinforcement learning to enforce rigorous, verifiable reasoning in multimodal models, outperforming larger models on tabular benchmarks.
Where and What: Reasoning Dynamic and Implicit Preferences in Situated Conversational Recommendation
arXiv: 2604.20749

The paper introduces SiPeR (Situated Preference Reasoning), a novel framework for situated conversational recommendation that addresses the complexity of dynamic and implicit user preferences in real-world environments. Unlike traditional recommendation systems, SiPeR recognizes that user preferences evolve across conversations and are influenced by the surrounding visual scene.
The framework integrates two core mechanisms: Scene transition estimation, which estimates whether the current scene satisfies user needs and guides users toward more suitable scenes, and Bayesian inverse inference, which leverages multimodal large language models to predict user preferences about candidate items within the scene. This dual approach enables more accurate and contextually appropriate recommendations.
Extensive experiments on two representative benchmarks demonstrate SiPeR's superiority in both recommendation accuracy and response generation quality. The framework's ability to model implicit preferences and adapt to changing user needs makes it particularly valuable for real-world applications where context and conversation dynamics play crucial roles in recommendation effectiveness.
Key insight: SiPeR framework improves conversational recommendation by integrating scene transition estimation and Bayesian inverse inference for dynamic preference modeling.