Google has introduced Deep Research and Deep Research Max AI agents capable of searching both web and private data sources, marking a significant step toward enterprise AI integration. Meanwhile, Meta is reportedly using employee tracking software to train AI agents, raising privacy concerns. Simultaneously, new research papers demonstrate advances in multimodal reasoning, financial AI, and virtual cell repositories.
Google's new Deep Research and Deep Research Max agents represent a major development in enterprise AI, combining web search capabilities with access to private data through the Gemini 2.0 model. These agents are designed to handle complex research tasks and support large-scale R&D workflows. Meta's reported use of employee tracking software for AI training highlights the growing tension between AI development needs and workplace privacy rights. In academic research, several papers advance the field of multimodal reasoning, including A-MAR for art retrieval, SafetyALFRED for embodied safety planning, and TSAG for financial time-series analysis. Additionally, work on visual semantic arithmetic and biological AI verification through AblateCell demonstrates progress in cross-modal reasoning and reproducibility in scientific AI applications.
AI Model Releases
Google’s new Deep Research and Deep Research Max agents can search the web and your private data
Google has unveiled two new AI agents, Deep Research and Deep Research Max, designed to search both public web content and private data sources. The agents are built on Google's Gemini 2.0 model and can perform complex research tasks by combining web searches with internal data access. Deep Research Max is specifically optimized for handling large-scale research projects, while Deep Research focuses on more targeted queries. These agents are part of Google's broader strategy to integrate AI into enterprise research and development workflows.
Why it matters: This development signals Google's aggressive push to integrate AI agents into enterprise environments, potentially reshaping how companies conduct research and access information. The ability to seamlessly blend public and private data sources could significantly enhance productivity for knowledge workers and R&D teams.
AI Tooling
Report: Meta will train AI agents by tracking employees' mouse, keyboard use
According to a report, Meta is planning to use employee tracking software to gather data for training AI agents. The tracking would capture mouse movements, keyboard usage, and other interaction patterns from employees' work sessions. This data would be used to teach AI systems how to perform tasks similar to human workers. The initiative is part of Meta's broader effort to develop more capable AI agents that can automate complex workflows.
Why it matters: This approach raises significant privacy concerns while demonstrating how companies are increasingly relying on human behavioral data to train AI systems. It highlights the growing tension between AI development needs and employee privacy rights in the workplace.
Firebase/GCP

GEAR up to get the most out of AI learning at Google Cloud Next ‘26 | Google Cloud Blog
Google Cloud has announced a comprehensive AI learning program for Google Cloud Next '26, designed to help developers and practitioners maximize their AI capabilities. The program includes hands-on workshops, certification tracks, and specialized training modules covering machine learning, generative AI, and AI-powered application development. Google is emphasizing practical skills development with real-world use cases and industry best practices. The learning path is structured to accommodate different skill levels from beginners to advanced practitioners.
Why it matters: This initiative reflects Google's commitment to building a skilled AI workforce and establishing itself as a leader in enterprise AI education. The focus on practical, hands-on training suggests a strategic move to support the growing demand for AI expertise in the market.
Research Papers
A-MAR: Agent-based Multimodal Art Retrieval for Fine-Grained Artwork Understanding
arXiv: 2604.19689

A-MAR introduces a novel agent-based framework for multimodal art retrieval that explicitly conditions retrieval on structured reasoning plans. This approach addresses a key limitation in current multimodal large language models (MLLMs), which rely on implicit reasoning and internalized knowledge, making their outputs less interpretable and harder to ground in explicit evidence. By decomposing complex tasks into structured steps, A-MAR enables targeted evidence selection and supports step-wise, grounded explanations.
The framework is evaluated using a new diagnostic benchmark, ArtCoT-QA, which focuses on multi-step reasoning chains for diverse art-related queries. This allows for granular analysis beyond simple final answer accuracy. Experimental results on SemArt and Artpedia datasets show that A-MAR consistently outperforms both static retrieval methods and strong MLLM baselines in terms of final explanation quality. These findings highlight the importance of reasoning-conditioned retrieval for knowledge-intensive multimodal understanding.
The implications of A-MAR extend beyond art domains, positioning it as a step toward interpretable, goal-driven AI systems. Its relevance to cultural industries underscores the potential for AI to support more transparent and accountable decision-making in domains where context and interpretation are paramount.
Key insight: A-MAR demonstrates that structured reasoning plans significantly improve the interpretability and evidence grounding of multimodal art retrieval, outperforming traditional static approaches.
SafetyALFRED: Evaluating Safety-Conscious Planning of Multimodal Large Language Models
arXiv: 2604.19638

SafetyALFRED addresses a critical gap in current safety evaluations of multimodal large language models (MLLMs) used in embodied environments. While existing benchmarks focus on hazard recognition through disembodied question answering (QA), SafetyALFRED evaluates models on both recognition and active risk mitigation through embodied planning. This shift is crucial because recognition alone does not ensure safe behavior in physical environments.
The benchmark introduces six categories of real-world kitchen hazards to ALFRED, a popular embodied agent benchmark. Evaluations of eleven state-of-the-art models from Qwen, Gemma, and Gemini families show that while these models perform well in QA settings, their success rates in actual risk mitigation are significantly lower. This alignment gap highlights the limitations of static QA-based safety assessments.
The work advocates for a paradigm shift toward benchmarks that emphasize corrective actions in embodied contexts, rather than just recognition. By emphasizing active safety planning, SafetyALFRED sets a new standard for evaluating the true safety capabilities of MLLMs in real-world applications, particularly in robotics and autonomous systems.
Key insight: SafetyALFRED reveals a significant gap between hazard recognition and active risk mitigation in multimodal LLMs, advocating for benchmarks that prioritize corrective actions in embodied contexts.
Time Series Augmented Generation for Financial Applications
arXiv: 2604.19633
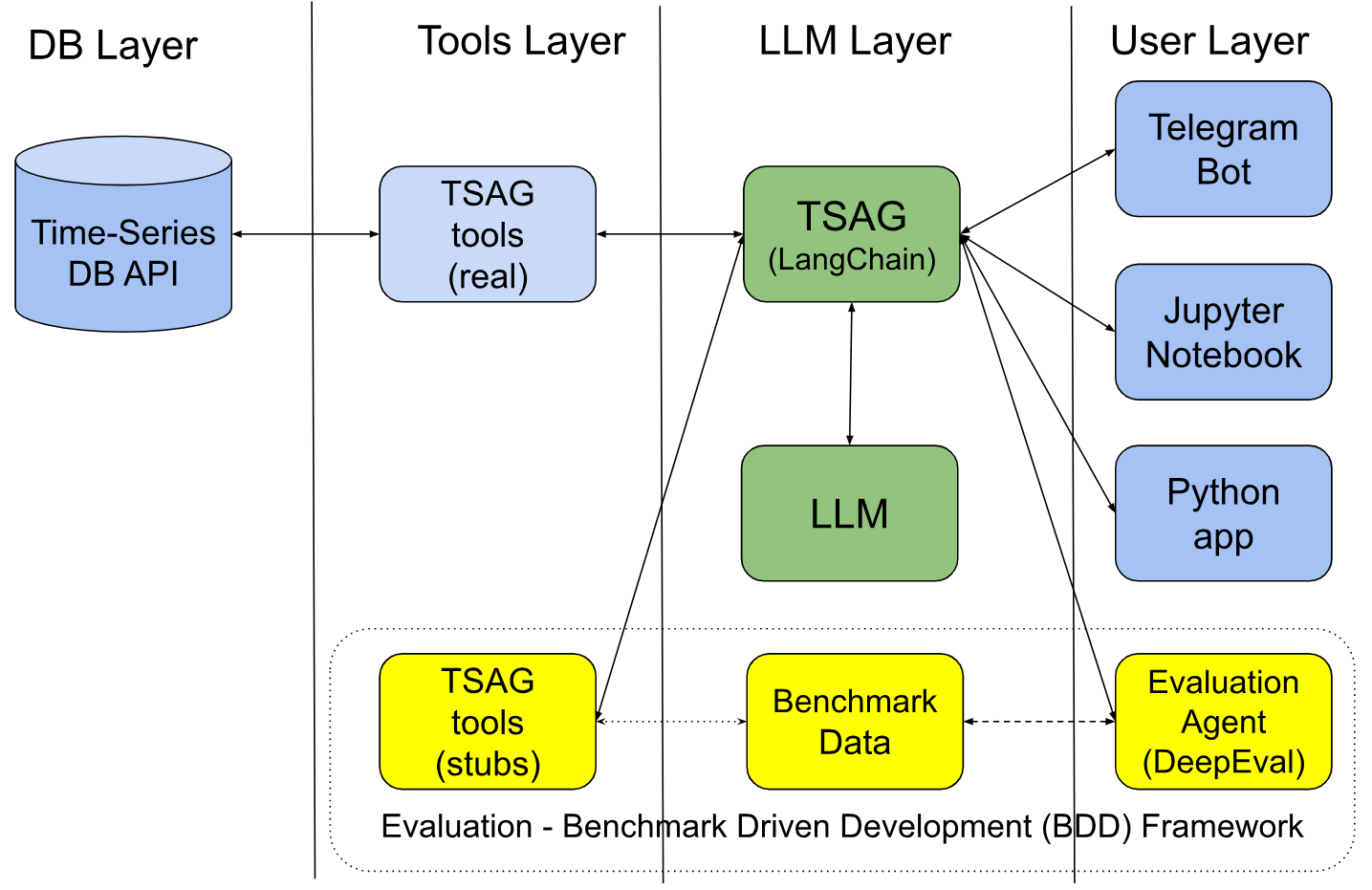
Time Series Augmented Generation (TSAG) presents a novel evaluation methodology for assessing LLM agents' reasoning capabilities in complex financial tasks. Unlike traditional benchmarks that may obscure an agent's core reasoning abilities, TSAG isolates the agent's ability to parse queries and orchestrate computations by delegating quantitative tasks to verifiable external tools.
The framework is evaluated using a benchmark of 100 financial questions, comparing multiple SOTA agents including GPT-4o, Llama 3, and Qwen2. Results show that capable agents can achieve near-perfect tool-use accuracy with minimal hallucination, validating the effectiveness of the tool-augmented paradigm. This approach not only improves reliability but also provides a standardized way to measure agent performance in financial AI.
TSAG's contribution lies in its rigorous evaluation framework and empirical insights into agent performance, which are crucial for advancing reliable financial AI. By releasing the framework publicly, the authors foster standardized research and encourage further development of robust, verifiable AI systems for financial applications.
Key insight: TSAG framework demonstrates that LLM agents can achieve high accuracy in tool selection and minimal hallucination when performing financial time-series analysis through verifiable external tools.
Multi-modal Reasoning with LLMs for Visual Semantic Arithmetic
arXiv: 2604.19567

Visual semantic arithmetic represents a challenging domain where LLMs must infer relationships from images, requiring both commonsense knowledge and the ability to extract concise concepts from irrelevant visual details. The paper introduces two novel tasks—two-term subtraction and three-term operations—and constructs the Image-Relation-Pair Dataset (IRPD) for benchmarking.
The proposed Semantic Arithmetic Reinforcement Fine-Tuning (SAri-RFT) method post-trains large vision-language models (LVLMs) using a verifiable function and Group Relative Policy Optimization (GRPO). This approach addresses the modality gap that plagues prior methods and achieves state-of-the-art results on both IRPD and the Visual7W-Telling dataset. The work demonstrates that LVLMs can be effectively equipped with robust cross-modal relational reasoning capabilities.
These advancements are particularly impactful for service and domestic robotics, where robots must infer semantic relationships among objects, agents, and actions in unstructured environments. By grounding symbolic reasoning in perception, the method enhances decision-making, tool adaptability, and human-robot interaction, paving the way for more intelligent and autonomous robotic systems.
Key insight: SAri-RFT enhances LVLMs' ability to perform visual semantic arithmetic, bridging modality gaps and enabling more robust cross-modal relational reasoning in robotics.
AblateCell: A Reproduce-then-Ablate Agent for Virtual Cell Repositories
arXiv: 2604.19606
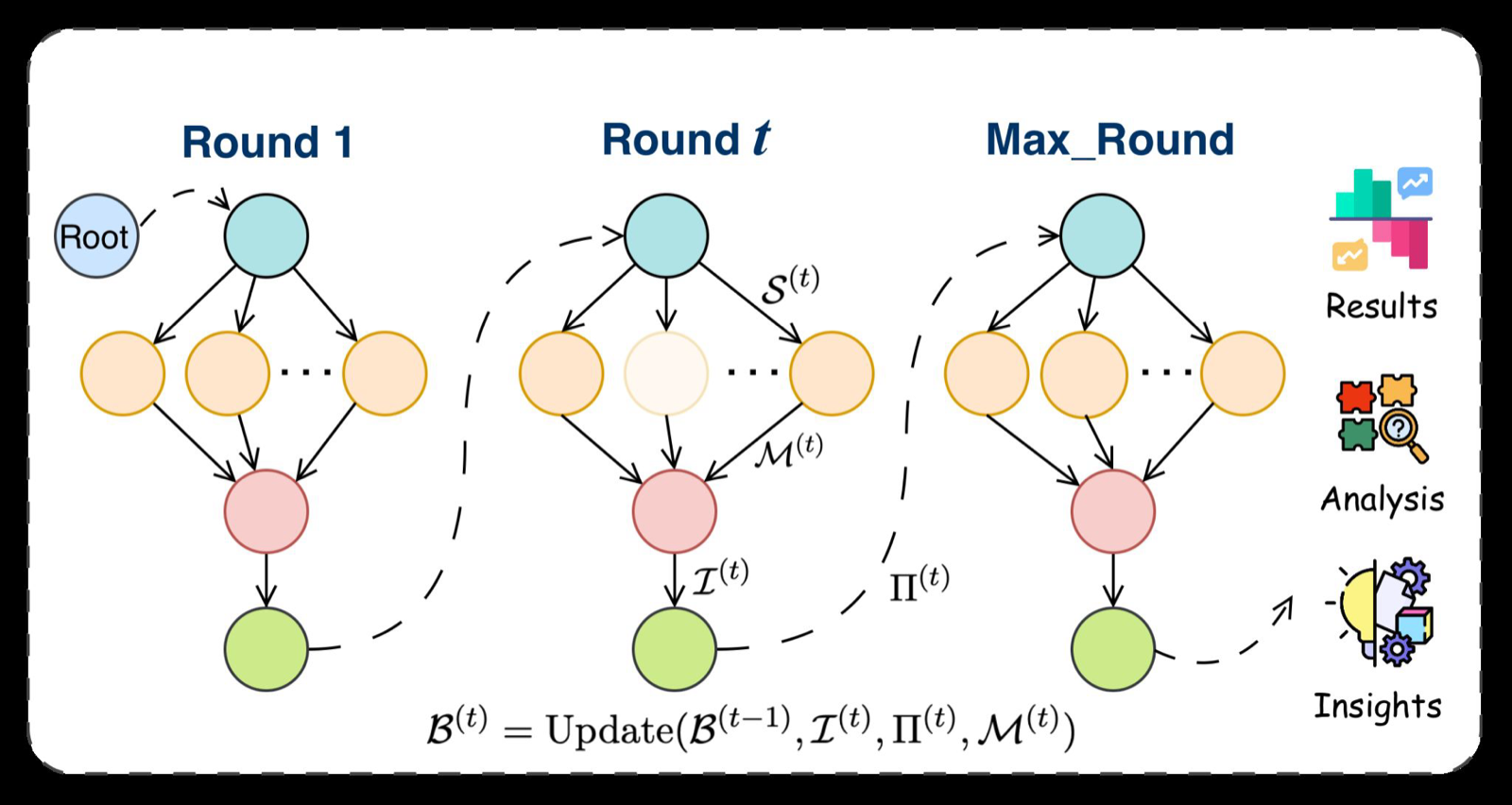
AblateCell tackles a critical challenge in AI virtual cells: the lack of systematic ablations due to under-standardized and tightly coupled biological repositories. While coding agents can translate ideas into implementations, they often stop short of verifying baselines and rigorously testing which components truly matter.
The agent automates the entire process of reproducing reported baselines end-to-end, including auto-configuring environments, resolving dependencies, and rerunning official evaluations. It then conducts closed-loop ablation by generating a graph of isolated repository mutations and adaptively selecting experiments under a reward that balances performance impact and execution cost.
Evaluated on three single-cell perturbation prediction repositories (CPA, GEARS, BioLORD), AblateCell achieves 88.9% end-to-end workflow success and 93.3% accuracy in recovering ground-truth critical components. These results demonstrate the potential for scalable, repository-grounded verification and attribution directly on biological codebases, significantly advancing the reliability and reproducibility of AI in biological research.
Key insight: AblateCell enables scalable, repository-grounded verification and attribution in biological AI by automating the reproduction and ablation of virtual cell repositories.