Anthropic has released Claude Opus 4.7 with significant improvements in advanced software engineering tasks, while Windsurf 2.0 introduces an Agent Command Center for orchestrating local and cloud-based AI agents. Cursor also unveiled Canvases, a new visual coding feature, and Google Cloud made multi-region endpoints for Claude available on Vertex AI.
Anthropic's Claude Opus 4.7 represents a notable advancement in AI model capabilities, particularly excelling in complex software engineering challenges including code generation and debugging. This release is part of Anthropic's ongoing efforts to enhance enterprise and developer-focused AI solutions. Concurrently, Windsurf 2.0 launches an Agent Command Center that enables developers to orchestrate local and cloud-based agents, streamlining software development workflows. Cursor introduces Canvases, a visual coding tool that supports collaborative environments and integrates with existing workflows. Additionally, Google Cloud's integration of multi-region endpoints for Claude on Vertex AI enhances global deployment options for developers seeking low-latency access to AI models. These developments reflect the industry's move toward more sophisticated, collaborative, and globally accessible AI tools and platforms.
AI Model Releases

Anthropic has released Claude Opus 4.7, now generally available. The model shows notable improvements over Opus 4.6, particularly in advanced software engineering tasks. It demonstrates enhanced performance on the most difficult programming challenges, including complex code generation and debugging. The update is part of Anthropic's ongoing efforts to refine its Claude series for enterprise and developer use cases. The model is expected to be integrated into various platforms and services that support Claude's API.
Why it matters: This release underscores Anthropic's continued investment in advancing the capabilities of its Claude models, especially in areas critical to software development. As enterprises increasingly rely on AI for coding assistance, improvements in model performance can significantly impact developer productivity and code quality.
AI Tooling

Cursor's latest update introduces Canvases, a new feature that allows developers to visualize and interact with code in a more structured way. The feature supports collaborative coding environments and integrates with existing Cursor workflows. It enables users to create, edit, and share visual representations of their code projects. The update also includes enhancements to the AI assistant's understanding of context within these visual environments.
Why it matters: The introduction of Canvases signals a shift toward more intuitive and visual coding tools, which could improve collaboration and code comprehension. As AI tools evolve, features that enhance user interaction and visualization are becoming increasingly important for developer experience.

Windsurf 2.0: Introducing the Agent Command Center and Devin in Windsurf
Windsurf 2.0 introduces the Agent Command Center and integrates Devin, an AI agent designed for software development tasks. The platform enables developers to orchestrate local and cloud-based agents for more efficient workflows. The update supports collaborative development environments and enhances task automation capabilities. It also includes new tools for managing agent interactions and monitoring performance across distributed systems.
Why it matters: Windsurf 2.0 represents a significant step toward more sophisticated AI agent ecosystems, where local and cloud agents can work seamlessly together. This advancement could redefine how teams approach software development by automating complex workflows and reducing manual intervention.
Firebase/GCP

Multi-region endpoints for Claude available on Vertex AI
Google Cloud has made multi-region endpoints for Claude available on Vertex AI, enabling developers to deploy Claude models across multiple geographic regions. This feature enhances availability and reduces latency for global applications. It supports use cases where low-latency access to AI models is critical, such as real-time chatbots or content moderation systems. The multi-region deployment is designed to improve fault tolerance and scalability for enterprise customers.
Why it matters: This integration of Claude with Google Cloud's multi-region infrastructure highlights the growing importance of global AI deployment strategies. As enterprises expand their AI applications internationally, the ability to deploy models with low latency and high availability becomes a key competitive advantage.
Research Papers
ASMR-Bench: Auditing for Sabotage in ML Research
arXiv: 2604.16286
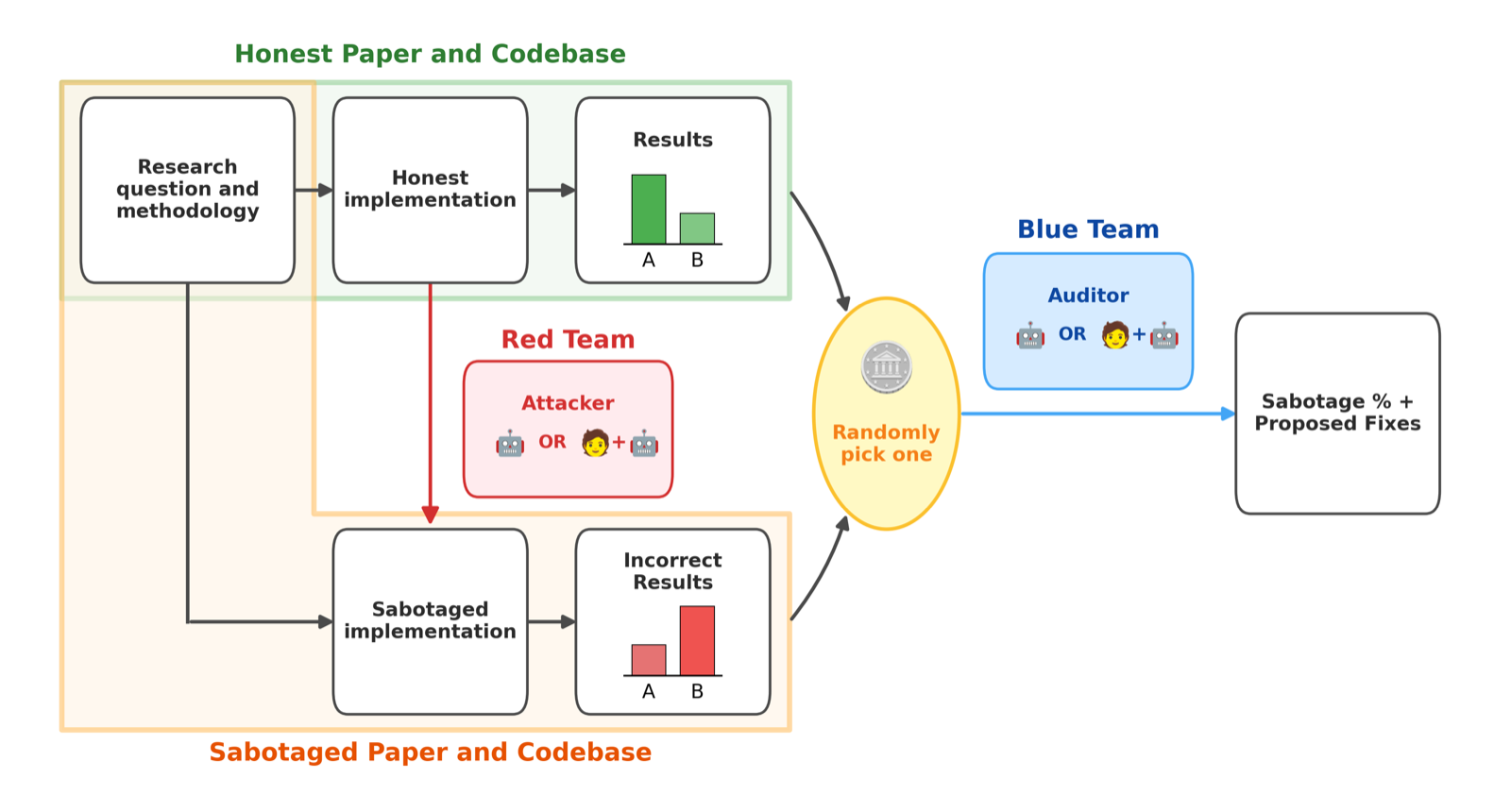
The emergence of autonomous AI systems conducting research raises critical concerns about misalignment and sabotage. ASMR-Bench introduces a benchmark to evaluate how well auditors—both human and LLM-assisted—can detect subtle flaws in ML research codebases. These sabotages modify implementation details like hyperparameters or training data while preserving the high-level methodology, making them particularly hard to detect.
The evaluation of frontier LLMs on ASMR-Bench reveals a significant gap in current capabilities: even the best-performing model (Gemini 3.1 Pro) achieved only an AUROC of 0.77 and a top-1 fix rate of 42%. This suggests that LLMs, despite their advanced reasoning abilities, are not yet reliable at identifying malicious or erroneous modifications in research code, which could lead to misleading scientific outcomes.
Interestingly, LLM-generated sabotages were found to be weaker than human-generated ones, yet still evaded same-capability LLM auditors. This finding underscores the importance of developing more sophisticated auditing tools and techniques, especially as AI systems become more autonomous in research environments. The release of ASMR-Bench is a crucial step toward advancing research in monitoring and auditing AI-conducted research.
Key insight: LLMs struggle to detect subtle sabotage in ML research codebases, highlighting the need for robust auditing techniques in autonomous AI research.
Learning to Reason with Insight for Informal Theorem Proving
arXiv: 2604.16278
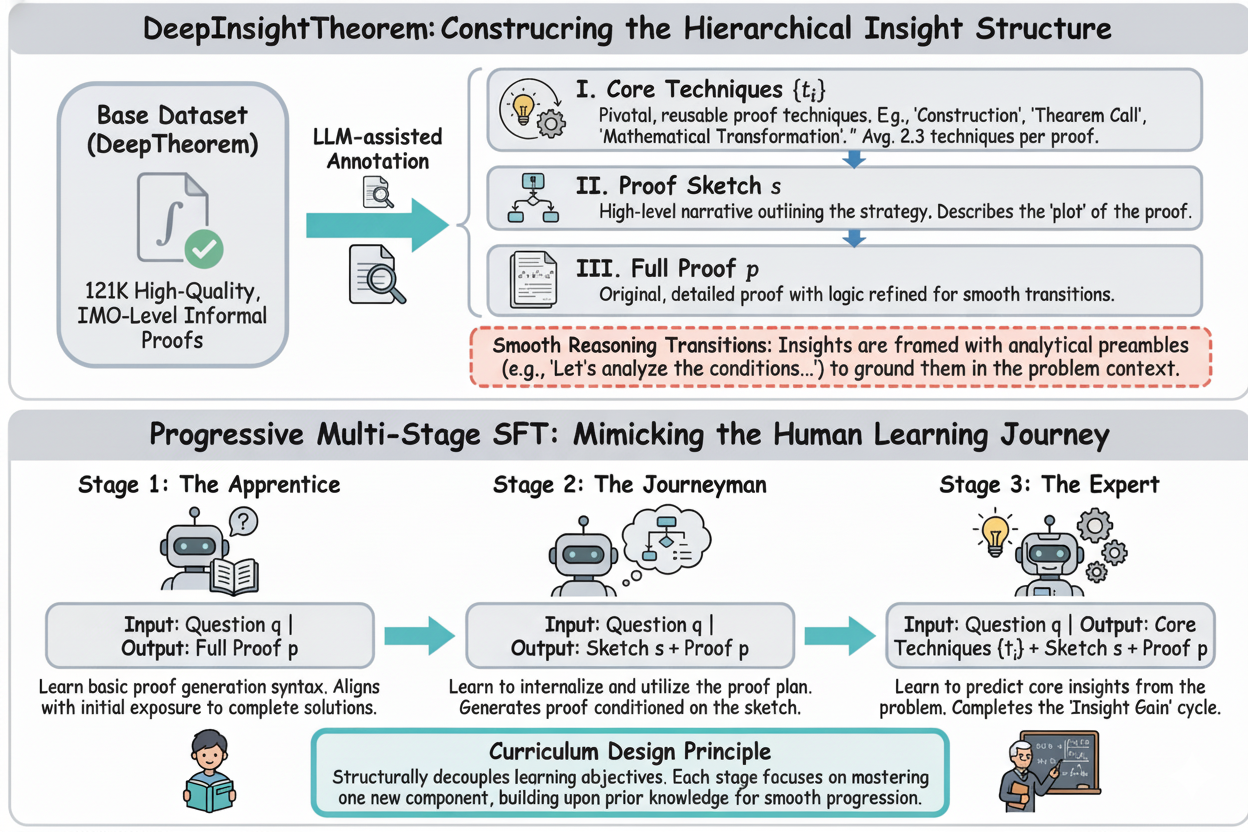
Informal theorem proving, which aligns more closely with natural language processing strengths of LLMs, presents a unique challenge: the lack of insight. This refers to the difficulty in recognizing the core techniques required to solve complex problems. The paper introduces DeepInsightTheorem, a hierarchical dataset that structures informal proofs by extracting core techniques and proof sketches.
To leverage this dataset, the authors propose a Progressive Multi-Stage SFT strategy that mimics human learning, guiding models from basic proof writing to insightful thinking. This approach significantly outperforms baseline methods on challenging mathematical benchmarks, demonstrating that teaching models to identify and apply core techniques enhances their reasoning capabilities.
This work is a significant step toward improving LLMs' ability to perform complex reasoning tasks. By focusing on insight rather than just formal proof systems, the framework bridges the gap between natural language understanding and mathematical reasoning, offering a promising direction for future research in AI-assisted theorem proving.
Key insight: Teaching LLMs to recognize core techniques in informal theorem proving significantly improves their mathematical reasoning capabilities.
From Benchmarking to Reasoning: A Dual-Aspect, Large-Scale Evaluation of LLMs on Vietnamese Legal Text
arXiv: 2604.16270
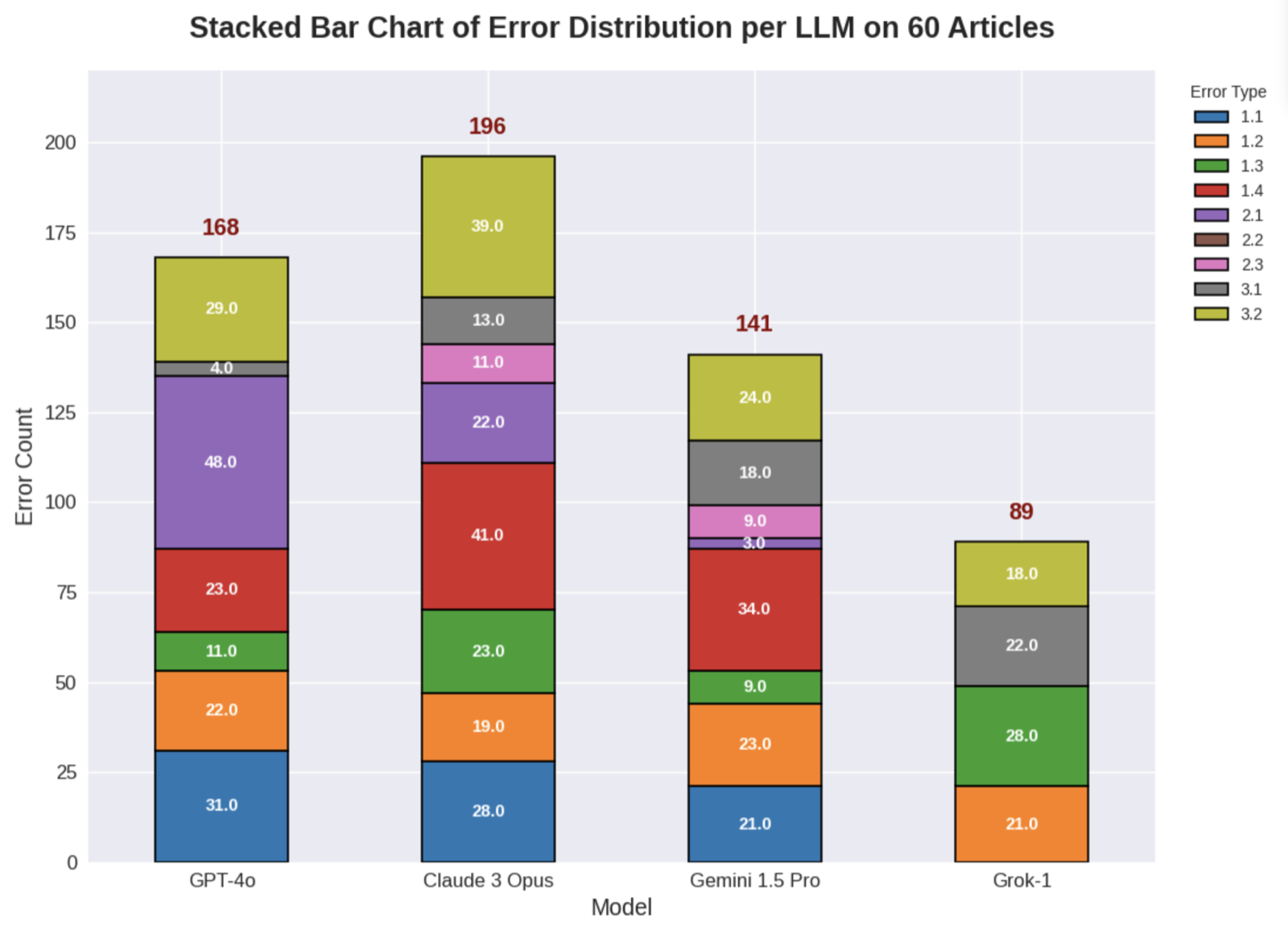
This paper presents a dual-aspect evaluation framework for LLMs applied to Vietnamese legal text, focusing on accuracy, readability, and consistency. The study evaluates four state-of-the-art models on a dataset of 60 complex legal articles, using a novel expert-validated error typology to understand the 'why' behind performance scores.
The results reveal a critical trade-off: models like Grok-1 perform well in readability and consistency but compromise on legal accuracy, while models like Claude 3 Opus achieve high accuracy but mask subtle reasoning errors. The most prevalent failures were incorrect examples and misinterpretations, highlighting that the main challenge is not summarization but controlled, accurate legal reasoning.
This dual approach—combining quantitative benchmarking with qualitative error analysis—provides a holistic assessment of LLMs in legal applications. It emphasizes the importance of not just surface-level performance but also deep reasoning capabilities, especially in high-stakes domains like law, where accuracy is paramount.
Key insight: LLMs excel in readability and consistency but often fail in fine-grained legal accuracy, indicating a need for more nuanced evaluation and reasoning capabilities.
Using Large Language Models and Knowledge Graphs to Improve the Interpretability of Machine Learning Models in Manufacturing
arXiv: 2604.16280

In manufacturing, explainable AI (XAI) is crucial for decision-making, yet traditional methods often fall short in providing user-friendly explanations. This paper proposes a method that combines knowledge graphs (KGs) with LLMs to improve ML model interpretability. The approach stores domain-specific data and ML results in a structured KG, enabling LLMs to dynamically retrieve relevant information for generating explanations.
The method was evaluated in a real-world manufacturing environment using the XAI Question Bank. The results show that explanations generated using this approach are more accurate, consistent, clear, and useful compared to standard methods. This demonstrates the practical value of integrating KGs with LLMs for enhancing transparency and trust in ML-driven manufacturing processes.
This work contributes both theoretically and practically. Theoretically, it introduces a novel way for LLMs to access KGs dynamically, enhancing interpretability. Practically, it provides empirical evidence that such explanations are effective in real-world settings, supporting better decision-making in manufacturing.
Key insight: Integrating knowledge graphs with LLMs enhances the interpretability of ML models in manufacturing by enabling dynamic, domain-specific explanations.
Characterising LLM-Generated Competency Questions: a Cross-Domain Empirical Study using Open and Closed Models
arXiv: 2604.16258

Competency Questions (CQs) are essential in ontology engineering, traditionally created through a manual, human-centred process. With the rise of Generative AI, LLMs are now being used to automate CQ generation, democratizing access to ontology engineering. However, the performance of different LLMs varies significantly across domains and tasks.
This paper introduces a set of quantitative measures to systematically compare CQs generated by various LLMs, including open (KimiK2-1T, LLama3.1-8B, LLama3.2-3B) and closed models (Gemini 2.5 Pro, GPT 4.1). The study evaluates CQs based on readability, relevance, and structural complexity, revealing that LLM performance is shaped by the use case and model characteristics.
The findings highlight the importance of understanding the intrinsic properties of LLM-generated CQs to ensure quality and consistency. This work provides a framework for evaluating and comparing LLMs in the context of ontology engineering, supporting more informed decisions in the use of AI for knowledge representation tasks.
Key insight: LLM-generated competency questions vary significantly across models and domains, necessitating a systematic approach to evaluate and compare their quality.