Meta introduces Muse Spark, a step toward personal superintelligence, while OpenAI expands AI capabilities to enterprise workflows. Meanwhile, new research benchmarks and tooling updates advance the field of AI agent design and fairness.
Meta's Muse Spark represents a significant leap in personal AI systems, aiming to scale toward superintelligence through advanced scaling techniques and privacy safeguards. OpenAI's announcement of the next phase of enterprise AI focuses on deploying AI agents company-wide, making AI more accessible across organizational functions. In research, new benchmarks like EVGeoQA and A-MBER are pushing the boundaries of spatial reasoning and affective memory in LLMs, while papers on self-revising agents and policy optimization offer insights into more efficient and interpretable AI architectures. Additionally, Cursor and Figma are enhancing their AI tooling with improved debugging capabilities and scalable design workflows, respectively.
AI Model Releases
Introducing Muse Spark: Scaling Towards Personal Superintelligence
Meta introduced Muse Spark, a new AI system designed to scale towards personal superintelligence. The announcement detailed how Muse Spark builds upon existing Meta AI research to create more capable and personalized AI experiences. The system is positioned as a step toward more advanced personal AI assistants that can handle complex tasks and interactions. Muse Spark incorporates new techniques for scaling AI capabilities while maintaining user privacy and safety standards. The company emphasized that this represents a significant milestone in their journey toward more sophisticated personal AI technologies.
Why it matters: Muse Spark signals Meta's ambitious vision for personal AI assistants that could rival or exceed current capabilities, potentially reshaping how users interact with AI in daily life. This development could accelerate the race toward more advanced personal AI systems across the industry.
The next phase of enterprise AI
OpenAI announced the next phase of enterprise AI, focusing on enabling agents company-wide for enterprise use. The company detailed how they're expanding AI capabilities beyond individual users to support broader organizational workflows. This phase emphasizes empowering teams and individuals with AI tools that can integrate into existing business processes. OpenAI highlighted that this expansion includes new agent frameworks and tools designed to work seamlessly across different departments and functions. The announcement suggests a strategic shift toward making AI more accessible and useful for enterprise customers.
Why it matters: This represents a major strategic move by OpenAI to expand AI adoption in enterprise environments, potentially driving widespread AI integration across businesses. The focus on company-wide agent deployment could fundamentally change how organizations approach AI implementation.
AI Tooling

Bugbot Learned Rules and MCP Support · Cursor
Cursor released updates to their AI-powered development tools, including Bugbot Learned Rules and MCP Support. The new features enhance Bugbot's ability to automatically identify and suggest fixes for code issues. MCP (Model Communication Protocol) support allows for better integration with various AI models and services. The updates aim to improve developer productivity by reducing manual debugging time and increasing code quality. These changes represent Cursor's ongoing effort to make AI more practical and accessible for software development workflows.
Why it matters: These updates demonstrate the continued evolution of AI-powered development tools toward more sophisticated automation capabilities. The integration of learned rules and MCP support could significantly improve developer workflows and code quality in AI-assisted development environments.
UI/UX Tools

Turning Prompts into Five Scalable Workflows with Figma Weave | Figma Blog
Figma introduced five scalable workflows for Figma Weave, an AI-powered design tool. The workflows are designed to help teams integrate AI into their design processes more effectively. Each workflow addresses specific design challenges, from rapid prototyping to design system maintenance. The company emphasized that these workflows are built to scale across different team sizes and project types. Figma Weave is positioned as a tool that can help designers and developers collaborate more efficiently using AI assistance.
Why it matters: This represents a significant step toward making AI tools more practical for real-world design teams. The scalable workflows could help democratize AI adoption in design processes, making advanced AI capabilities accessible to teams of varying sizes and expertise levels.
Research Papers
How Much LLM Does a Self-Revising Agent Actually Need?
arXiv: 2604.07236

This paper tackles a fundamental question in LLM agent design: how much of an agent's competence actually stems from the LLM versus explicit architectural components. The authors introduce a 'declared reflective runtime protocol' that externalizes key agent states such as belief tracking, confidence signals, and guarded actions, making otherwise latent behavior inspectable. This methodological innovation enables a granular analysis of agent performance across four distinct components: posterior belief tracking, explicit world-model planning, symbolic in-episode reflection, and sparse LLM-based revision.
The empirical evaluation on the noisy Collaborative Battleship game reveals that explicit world-model planning significantly outperforms a greedy posterior-following baseline, improving win rate by 24.1 percentage points and F1 score by 0.017. Symbolic reflection, while functioning as a real runtime mechanism, does not yet provide net-positive gains when aggregated. LLM-based revision, even when applied conditionally at only 4.3% of turns, yields only marginal improvements and even slightly reduces win rate. These findings suggest that while LLMs are valuable, explicit structures like planning and reflection play a more substantial role in agent performance than previously assumed.
The core contribution lies in the methodological framework rather than a leaderboard claim. By externalizing agent behavior, the study provides a way to isolate and evaluate the marginal impact of LLM interventions, offering a clearer understanding of where and how LLMs contribute to agent capabilities. This approach opens new avenues for designing more interpretable and efficient agent architectures by identifying which components can be explicitly engineered versus those that benefit from LLM-based flexibility.
Key insight: Externalizing agent behavior into inspectable runtime structures allows for precise decomposition of LLM vs. explicit structure contributions to agent performance.
Reason in Chains, Learn in Trees: Self-Rectification and Grafting for Multi-turn Agent Policy Optimization
arXiv: 2604.07165

T-STAR (Tree-structured Self-Taught Agent Rectification) introduces a novel approach to reinforcement learning for LLM agents in multi-step reasoning tasks. The framework addresses the challenge of sparse rewards by consolidating trajectories into a unified Cognitive Tree, identifying functionally similar steps and merging them to uncover latent reward correlations. This allows for a more nuanced credit assignment that accounts for critical steps that disproportionately influence outcomes.
The method incorporates two key innovations: Introspective Valuation, which back-propagates trajectory-level rewards through the tree to compute variance-reduced relative advantages at the step level, and In-Context Thought Grafting, which synthesizes corrective reasoning by contrasting successful and failed branches at critical divergence points. These mechanisms enable Surgical Policy Optimization, which focuses policy gradient updates on the most informative steps, leading to more effective learning.
Extensive experiments across diverse benchmarks show that T-STAR consistently outperforms strong baselines, with particularly notable gains on tasks requiring extended reasoning chains. This suggests that the framework's ability to identify and rectify critical reasoning steps is a powerful mechanism for improving agent performance in complex, multi-turn tasks. The approach demonstrates how structured reasoning and policy optimization can be combined to enhance LLM agents' decision-making capabilities.
Key insight: Multi-turn reasoning in LLM agents can be improved by identifying critical steps and using tree-structured policy optimization with corrective reasoning grafting.
EVGeoQA: Benchmarking LLMs on Dynamic, Multi-Objective Geo-Spatial Exploration
arXiv: 2604.07070
EVGeoQA introduces a novel benchmark for evaluating LLMs in dynamic geo-spatial environments, focusing on Electric Vehicle charging scenarios with dual objectives: charging necessity and co-located activity preferences. This design addresses a gap in existing GSQA benchmarks, which typically focus on static retrieval tasks and fail to capture the complexity of real-world planning involving dynamic user locations and compound constraints.
The benchmark is evaluated using GeoRover, a tool-augmented agent architecture that assesses LLMs' capacity for dynamic, multi-objective exploration. While LLMs successfully utilize tools to address sub-tasks, they struggle with long-range spatial exploration. However, an emergent capability is observed: LLMs can summarize historical exploration trajectories to enhance exploration efficiency, suggesting a form of memory-based reasoning that improves performance over time.
This work establishes EVGeoQA as a challenging testbed for geo-spatial intelligence, highlighting the need for LLMs to integrate real-time data, handle complex constraints, and perform long-range reasoning. The findings suggest that while current LLMs can manage sub-tasks effectively, they still lack robustness in complex, dynamic environments, pointing to future research directions in spatial reasoning and memory-augmented architectures.
Key insight: Dynamic, multi-objective geo-spatial exploration challenges LLMs to integrate real-time location data and complex constraints, revealing limitations in long-range spatial reasoning.
A-MBER: Affective Memory Benchmark for Emotion Recognition
arXiv: 2604.07017
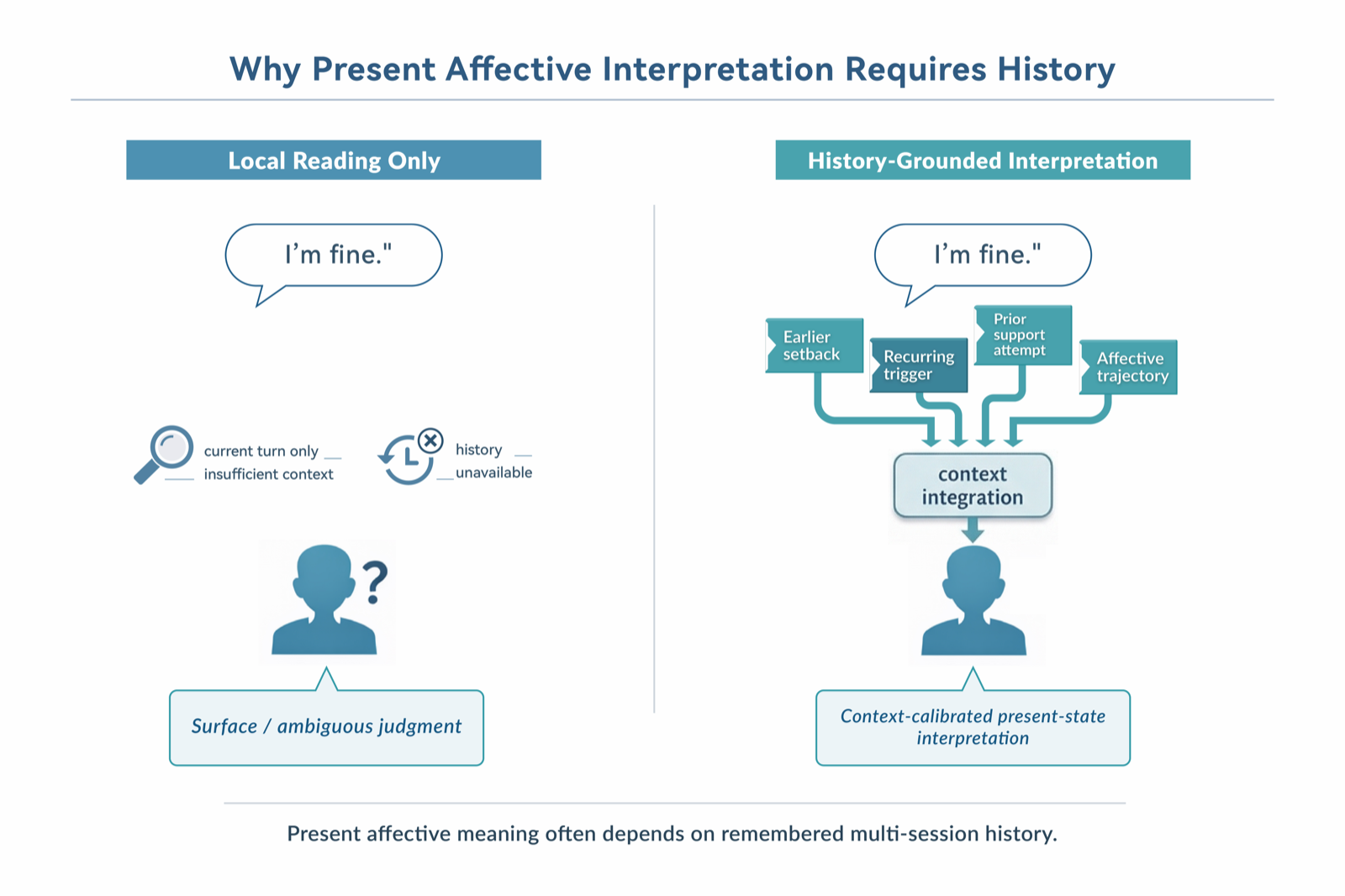
A-MBER addresses a critical gap in emotion recognition benchmarks by focusing on affective interpretation grounded in remembered multi-session interaction history. Unlike existing datasets that assess local or instantaneous affect, A-MBER evaluates how well models can use long-term memory to interpret a user's current emotional state, requiring models to identify historically relevant evidence and justify their interpretations.
The benchmark is constructed through a staged pipeline involving long-horizon planning, conversation generation, annotation, and question construction, supporting tasks such as judgment, retrieval, and explanation. Experiments across various conditions—local-context, long-context, retrieved-memory, structured-memory, and gold-evidence—reveal that A-MBER is especially discriminative on subsets designed to stress long-range implicit affect, high-dependency memory levels, and trajectory-based reasoning.
Results indicate that memory supports affective interpretation not merely by providing more history, but by enabling more selective, grounded, and context-sensitive use of past interactions. This suggests that effective emotion recognition in AI assistants requires not just memory, but the ability to retrieve and reason about relevant historical context in a nuanced way, pointing to the importance of memory architectures that support contextual relevance and selective attention.
Key insight: Affective memory benchmarks like A-MBER reveal that LLMs can interpret present emotional states using remembered interaction history, but only when memory is used selectively and contextually.
CAFP: A Post-Processing Framework for Group Fairness via Counterfactual Model Averaging
arXiv: 2604.07009
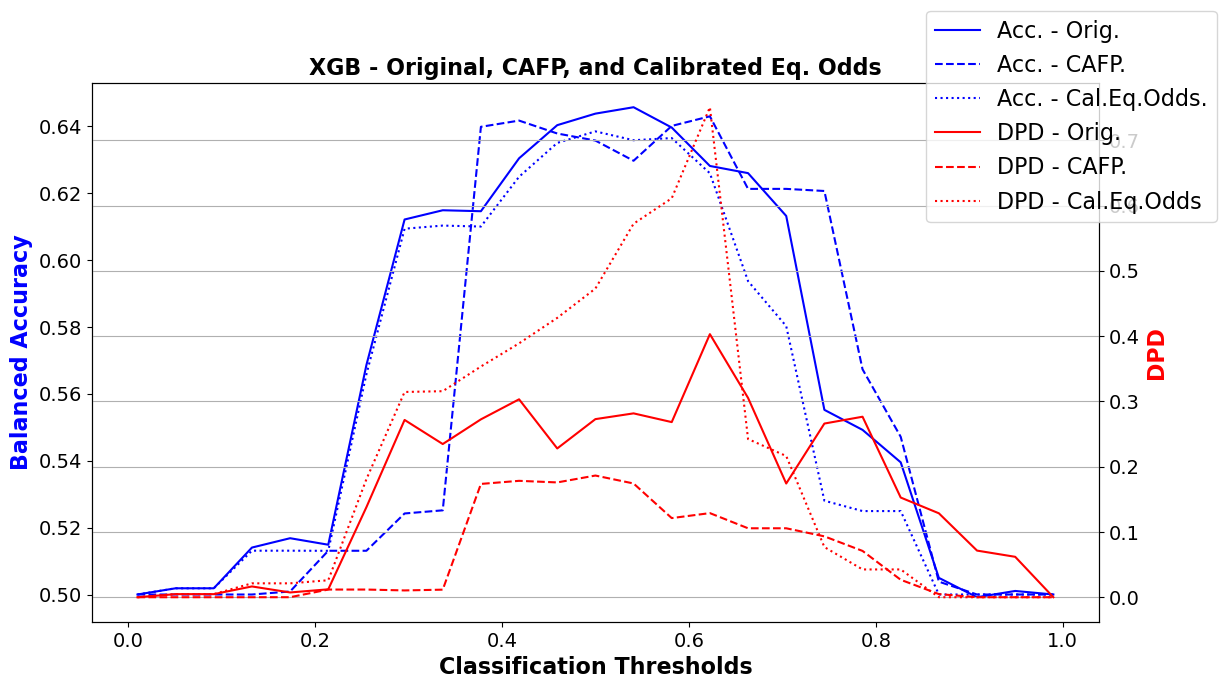
CAFP (Counterfactual Averaging for Fair Predictions) presents a novel post-processing approach to mitigate unfair influence from protected attributes in machine learning models. Unlike traditional fairness methods that require access to protected attributes during training or full control over model architecture, CAFP operates on the predictions of an existing classifier without retraining or modification.
The method works by generating counterfactual versions of inputs where the sensitive attribute is flipped, then averaging the model's predictions across factual and counterfactual instances. Theoretical analysis shows that CAFP eliminates direct dependence on the protected attribute, reduces mutual information between predictions and sensitive attributes, and provably bounds the distortion introduced relative to the original model.
Empirical results demonstrate that CAFP achieves perfect demographic parity and reduces the equalized odds gap by at least half the average counterfactual bias under mild assumptions. This makes CAFP a practical and effective solution for fairness in real-world deployments where model retraining or access to protected attributes is not feasible, offering a scalable approach to ensuring fair predictions in sensitive domains like healthcare and criminal justice.
Key insight: CAFP provides a model-agnostic post-processing method to achieve group fairness by generating counterfactual predictions and averaging them with factual ones.